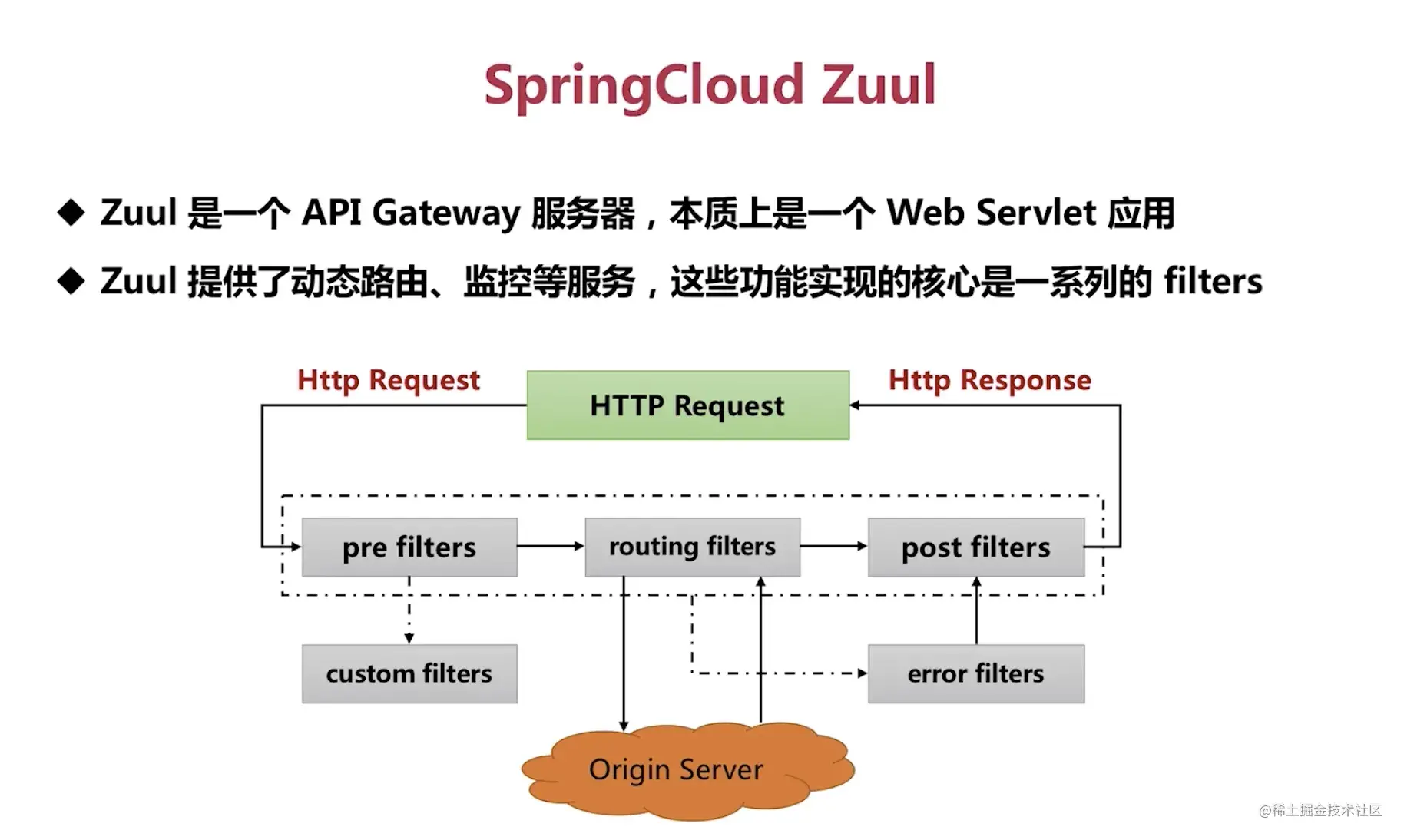
目录
- 前言
- 主机准备
- 配置主机名、关闭防火墙、关闭selinux
- 挂载磁盘
- 安装glusterfs服务端
- glusterfs的端口
- 分布式集群的结构
- 组成glusterfs集群
- 创建存储卷
- 启动卷
- k8s使用glusterfs作为后端存储(静态供给glusterfs存储)
- 恢复初始化环境
- 安装Heketi 服务(实现k8s动态供给glusterfs存储需要用到Heketi 服务)
- 创建hekti用户并配置免密登录
- 修改heketi配置文件
- 启动heketi服务
- 测试hekeit
- 配置hekeit-cli客户端工具的环境变量
- 设置hekeit的topology文件
- 创建卷
- k8s使用glusterfs作为后端存储(动态供给glusterfs存储)
- 总结
- 思考
前言
环境:centos7.9 、k8s 1.22.17
glusterfs的官网:https://docs.gluster.org/en/latest
glusterfs于 v1.25 弃用,具体可以查看https://kubernetes.io/zh-cn/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
注意注意了:k8s中可以使用静态、动态的方式供给glusterfs存储资源,但是两者的配置不相同,如果是静态,那么直接挂盘,创建lvm,创建文件系统,挂载,安装glusterfs集群,创建卷,k8s使用gluster即可。但是动态方式的话,需要结合heketi服务+glusterfs,由heketi服务管理、创建glusterfs集群,k8s中配置存储类指定heketi即可。heketi服务要求glusterfs服务器的磁盘必须是裸盘,不能是格式化的文件系统或lvm,这有点坑。所以这一点需要注意了。
主机准备
准备3台虚拟机或物理机,用于安装glusterfs文件系统作为storage服务器,并单独挂载一个磁盘用于存放数据,因为GlusterFS不建议共享根目录。
这里我使用的是3台虚拟机。
192.168.100.128
192.168.100.129
192.168.100.130
配置主机名、关闭防火墙、关闭selinux
略过,太简单了,自己做。
挂载磁盘
这里我们3台虚拟机都添加一块10G的磁盘。
在虚拟机页面添加磁盘后可以不用重启,使用下面的命令来在线扫描总线就能看到主机添加的磁盘了:
#在线识别磁盘
ls /sys/class/scsi_host/host*/scan #查看有几个设备
echo "- - -" > /sys/class/scsi_host/host0/scan
echo "- - -" > /sys/class/scsi_host/host1/scan
echo "- - -" > /sys/class/scsi_host/host2/scan
#创建lv,用于给glusterfs使用的,命令如下
pvcreate /dev/sdb #将新加的磁盘创建为pv
vgcreate GlusterFS /dev/sdb #创建vg卷组,名为GlusterFS
lvcreate -n GlusterFS -l +100%FREE GlusterFS #创建lv,名为GlusterFS,并分配卷组GlusterFS的100%空间给lv
mkfs.xfs /dev/GlusterFS/GlusterFS #将lv格式化为xfs格式的文件系统
mkdir /GlusterFS #创建挂载目录
mount /dev/GlusterFS/GlusterFS /GlusterFS
vim /etc/fstab
mount -a
df -Th
安装glusterfs服务端
在3个虚拟机上都要安装glusterfs服务端,具体可以参考https://blog.csdn.net/MssGuo/article/details/122182719,这里大概讲一下安装步骤:
#配置glusterfs的yum源
cat > /etc/yum.repos.d/glusterfs.repo <<EOF
[glusterfs]
name=glusterfs
baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-9/
enabled=1
gpgcheck=0
EOF#注意,官方有个https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-10/的yum源,
# 但是发现使用这个10的后yum install glusterfs-server的时候显示没有glusterfs-server可用包,,只有glusterfs等客端端的包
#所以这里还是使用9的yum源
#安装glusterfs-server
yum install glusterfs-server
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
glusterfs的端口
gluster守护进程端口24007,每创建一个逻辑卷,就会启动一个进程和端口,进程端口默认是49152,以此类推,第二个卷端口就是49153。
[root@node1 ~]# netstat -lntup | grep gluster
tcp 0 0 0.0.0.0:24007 0.0.0.0:* LISTEN 118886/glusterd #gluster守护进程的端口
分布式集群的结构
分布式集群一般有两种结构:
有中心节点:中心节点一般指管理节点;
无中心节点:所有节点又管理又做事;
这里我们主要使用的是中心节点的结构。
组成glusterfs集群
3台虚拟机都安装好glusterfs-server软件并启动之后,需要将这3节点组成集群,那么这3台storage服务器是如何组成一个集群的呢?我们只需要在其中1台storage服务器上通过1条命令来连接另外2台storage服务器即可,这样就可以让这3台storage服务器组成一个集群了。
#在任意一台服务器上执行以下命令来组成集群:
gluster peer probe 192.168.100.129 #第2台服务器的IP,当然也可以指定主机名
peer probe: success
gluster peer probe 192.168.100.130 #第3台服务器的IP,当然也可以指定主机名
peer probe: success
gluster peer status #查看已连接的主机状态
Number of Peers: 2 #这里看到有2个peers,但自己本身也是一个peerHostname: 192.168.100.129
Uuid: 40d1508f-f6b4-4059-8bd3-9334f6814f71
State: Peer in Cluster (Connected)Hostname: 192.168.100.130
Uuid: 6b4a0de8-8f13-4ecf-89e6-efea569edff8
State: Peer in Cluster (Connected)
创建存储卷
glusterfs集群创建完成之后,那么这个glusterfs集群是如何共享存储呢?
答:创建逻辑卷,简称卷,就是每台storage服务器都捐点存储空间出来组成一个卷,就好像小时候捐钱一样;我们知道glusterfs是文件型存储,那么共享捐出来的就是目录。
glusterfs的逻辑卷类型有很多种,详情可以参考官网:https://docs.gluster.org/en/latest/Administrator-Guide/Setting-Up-Volumes/#arbiter-configuration-for-replica-volumes。
这里为了最大化利用我的磁盘空间,创建的分布式卷,企业线上环境不能使用分布式逻辑卷,因为分布式类型卷没有高可用性,分布式卷把数据分散到各个服务器上,不具备副本,一旦有一个服务器数据丢失,整个卷的数据就崩了。
#创建分布式卷.不指定卷的类型,默认就是分布式卷
[root@master ~]# gluster volume create glusterfs-data 192.168.100.128:/GlusterFS 192.168.100.129:/GlusterFS 192.168.100.130:/GlusterFS
volume create: glusterfs-data: failed: The brick 192.168.100.128:/GlusterFS is a mount point. Please create a sub-directory under the mount point and use that as the brick directory. Or use 'force' at the end of the command if you want to override this behavior.
# 上面命令提示我的/GlusterFS是一个挂载点,建议使用子目录进行共享,可以加force强制创建。这里我的gluster就是供k8s使用的,所以干脆在/GlusterFS目录下创建要给k8s-data目录得了
mkdir /GlusterFS/k8s-data #在3台服务器上都创建k8s-data目录#继续创建分布式卷,成功
[root@master ~]# gluster volume create glusterfs-data 192.168.100.128:/GlusterFS/k8s-data 192.168.100.129:/GlusterFS/k8s-data 192.168.100.130:/GlusterFS/k8s-data
volume create: glusterfs-data: success: please start the volume to access data
启动卷
上面创建卷之后提示我们启动卷,我们先看下gluster volume的常用命令:
gluster volume help #查看帮助信息
gluster volume list #列出全部的卷
[root@master ~]# gluster volume info glusterfs-data #查看指定卷的信息
Volume Name: glusterfs-data
Type: Distribute
Volume ID: 8c29092d-e52b-4199-914e-f24d8c2e36eb
Status: Created #状态是创建
Snapshot Count: 0
Number of Bricks: 3 #Bricks数量
Transport-type: tcp
Bricks:
Brick1: 192.168.100.128:/GlusterFS/k8s-data #Bricks信息
Brick2: 192.168.100.129:/GlusterFS/k8s-data #Bricks信息
Brick3: 192.168.100.130:/GlusterFS/k8s-data #Bricks信息
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@master ~]# gluster volume start glusterfs-data #启动指定的卷
volume start: glusterfs-data: success
[root@master ~]#
[root@master ~]# gluster volume status all #查看全部卷的状态
Status of volume: glusterfs-data
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick 192.168.100.128:/GlusterFS/k8s-data 49152 0 Y 91414 #可以看到,glusterfs-data卷启动了49152端口
Brick 192.168.100.129:/GlusterFS/k8s-data 49152 0 Y 46123
Brick 192.168.100.130:/GlusterFS/k8s-data 49152 0 Y 96450Task Status of Volume glusterfs-data
------------------------------------------------------------------------------
There are no active volume tasks
[root@master ]# netstat -lntup | grep gluster #查看端口
tcp 0 0 0.0.0.0:49152 0.0.0.0:* LISTEN 91414/glusterfsd #卷的端口
tcp 0 0 0.0.0.0:24007 0.0.0.0:* LISTEN 88420/glusterd #守护进程端口
[root@master ]# ps -ef | grep gluster #查看进程
root 88420 1 0 12月22 ? 00:00:02 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
root 91414 1 0 13:40 ? 00:00:00 /usr/sbin/glusterfsd -s 192.168.100.128 --volfile-id glusterfs-data.192.168.100.128.GlusterFS-k8s-data -p /var/run/gluster/vols/glusterfs-data/192.168.100.128-GlusterFS-k8s-data.pid -S /var/run/gluster/ff6877b3973ae742.socket --brick-name /GlusterFS/k8s-data -l /var/log/glusterfs/bricks/GlusterFS-k8s-data.log --xlator-option *-posix.glusterd-uuid=0c8e4a79-7458-44f7-beef-ffe54938480f --process-name brick --brick-port 49152 --xlator-option glusterfs-data-server.listen-port=49152
root 101726 39323 0 13:54 pts/0 00:00:00 grep --color=auto gluster
k8s使用glusterfs作为后端存储(静态供给glusterfs存储)
官网使用glusterfs示例:https://github.com/kubernetes/examples/tree/master/volumes/glusterfs
在k8s所有节点上都安装glusterfs的客户端:
第一、先在k8s所有节点上都安装glusterfs的客户端(主要是为了有mount.glusterfs这个命令)
1、添加FUSE内核模块:
modprobe fuse
2、查看fuse是否已经加载:
dmesg | grep -i fuse
[ 0.611413] fuse init (API version 7.26)
3、安装依赖:
sudo yum -y install openssh-server wget fuse fuse-libs openib libibverbs
4、放行防火墙(这里我的虚拟机是关闭了防火墙,所以没有做这一步,请参考`https://docs.gluster.org/en/latest/Administrator-Guide/Setting-Up-Clients/#installing-on-red-hat-package-manager-rpm-distributions`)
5、 安装glusterfs客户端:
yum install glusterfs glusterfs-fuse glusterfs-rdma
第二、k8s创建资源对象使用glusterfs存储(下面创建的资源都默认在default默认命名空间)
1、创建glusterfs-endpoints
可以参考: https://github.com/kubernetes/examples/blob/master/volumes/glusterfs/glusterfs-endpoints.yaml
vim glusterfs-endpoints.yaml
apiVersion: v1
kind: Endpoints
metadata:name: glusterfs-cluster
subsets:
- addresses:- ip: 192.168.100.128 #填写glusterfs IP地址ports:- port: 49152 #填写卷的端口
- addresses:- ip: 192.168.100.129 #填写glusterfs IP地址ports:- port: 49152 #填写卷的端口
- addresses:- ip: 192.168.100.130 #填写glusterfs IP地址ports:- port: 49152 #填写卷的端口kubectl create -f glusterfs-endpoints.yaml
2、为这些端点创建一个service,以便它们能够持久,不需要标签选择器
vim glusterfs-service.yaml
apiVersion: v1
kind: Service
metadata:name: glusterfs-cluster #名字要与Endpoints名字一样才能进行管理
spec:ports:- port: 49152kubectl create -f glusterfs-service.yaml
3、创建pv,pvc,pv中定义glusterfs的信息
apiVersion: v1
kind: PersistentVolume
metadata:name: glusterfs-pv
spec:capacity:storage: 5GivolumeMode: FilesystemaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: RetainstorageClassName: ""glusterfs: #定义gluster的信息endpoints: glusterfs-cluster #指定glusterfs的endpointendpointsNamespace: default #指定glusterfs的endpoint的所属命名空间path: glusterfs-data #指定glusterfs的卷名称readOnly: false
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: glusterfs-pvc
spec:accessModes:- ReadWriteManyvolumeMode: Filesystemresources:requests:storage: 5GistorageClassName: ""
---
4、创建deployment、service
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginxname: nginxnamespace: default
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- image: nginximagePullPolicy: IfNotPresentname: nginxports:- name: nginx containerPort: 80volumeMounts:- name: pvc-volume mountPath: /var/log/nginx #持久化nginx的日志volumes:- name: pvc-volumepersistentVolumeClaim:claimName: glusterfs-pvc readOnly: false
---
apiVersion: v1
kind: Service
metadata:labels:app: nginxname: nginxnamespace: default
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: nginxsessionAffinity: Nonetype: ClusterIP
---
经验证,静态glusterfs供给正常,查看glusterfs节点上/GlusterFS/k8s-data目录:
[root@node2 ~]# ll /GlusterFS/k8s-data/
总用量 8
-rw-r--r-- 2 root root 6310 12月 23 14:48 error.log
恢复初始化环境
k8s动态供给glusterfs存储,需要结合Heketi 服务来使用,Heketi 服务就是用于管理glusterfs集群的,可以创建gluster集群、创建管理卷等,但是Heketi 服务需要使用裸盘,而不是文件系统,所以这里需要恢复下我的环境。
#停止卷
gluster volume stop glusterfs-data
#删除卷
gluster volume delete glusterfs-data#删除peers
gluster peer detach 192.168.100.129
gluster peer detach 192.168.100.130#卸载lv,删除lv
umount /dev/GlusterFS/GlusterFS
lvremove /dev/GlusterFS/GlusterFS
vgremove GlusterFS
pvremove /dev/sdb
#删除挂载信息
vim /etc/fstab #靠,后面发现还是不行,白做了,后面Heketi初始化的时候报错了,说磁盘初始化过了,看来只能删除磁盘,重新挂一块裸盘了
#删除/dev/sdb,重新添加磁盘了。
安装Heketi 服务(实现k8s动态供给glusterfs存储需要用到Heketi 服务)
heketi是为glusterfs集群提供RESTFUL API的,通过restful风格对glusterfs集群进行管理控制。
在k8s官方文档中写到,要使用glusterfs作为后端动态供给存储,在存储类中要配置heketi的接口,并不是直接配置glusterfs的,所以我们需要安装Heketi 服务。
Heketi 服务的安装方式分为3种,OpenShift集群安装、Standalone独立单机安装、Kubernetes安装 ,我们采用Standalone独立单机安装方式。https://github.com/heketi/heketi/blob/master/docs/admin/readme.md、https://github.com/heketi/heketi/blob/master/docs/admin/install-standalone.md
#在线yum安装heketi服务端和客户端工具,heketi 也是在glusterfs源里面的,如果没有glusterfs源,参考上面的配置glusterfs的yum源
yum install heketi heketi-client#离线安装。参考官方网站https://github.com/heketi/heketi/releases,下载heketi二进制包并将服务配置为systemd管理启动即可
创建hekti用户并配置免密登录
创建免密登录的用户,因为官网要求heketi主机要能免密登录到glusterfs的主机上,这里我不在创建一个heketi用户,直接使用root用户,如果是非root用户,需要有sudo权限。
#使用root用户做免密登录
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.100.128
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.100.129
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.100.130#如果使用的是heketi用户,需要在每个gluste节点上创建hekti用户
#给heketisudo权限echo "heketi ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
#在heketi主机上安装heketi后默认就有heketi用户,但是这个用户没有home目录,也没有shell,
#所以可以先删除heketi用户在创建heketi用户,同时还需要修改文件的权限,如/etc/heketi/heketi.json属主权限等等因为默认是root权限,不修改等下启动有问题
修改heketi配置文件
通过`systemctl status heketi.service;cat /usr/lib/systemd/system/heketi.service` 可以知道,heketi配置文件为/etc/heketi/heketi.json
#修改配置文件
官方文档`https://github.com/heketi/heketi/blob/master/docs/admin/server.md`
vim /etc/heketi/heketi.json
{"_port_comment": "Heketi Server Port Number","port": "7890", #Heketi服务端口,默认是8080,可以自定义"_use_auth": "Enable JWT authorization. Please enable for deployment","use_auth": true, #是否使用JWT authorization,设置为true"_jwt": "Private keys for access","jwt": {"_admin": "Admin has access to all APIs","admin": {"key": "admin123456" #配置admin的密码},"_user": "User only has access to /volumes endpoint","user": {"key": "admin123456" #配置普通账号的密码}},"_glusterfs_comment": "GlusterFS Configuration","glusterfs": {"_executor_comment": [ #这个是注释说明而已,解释了3中命令执行器,不用改"Execute plugin. Possible choices: mock, ssh","mock: This setting is used for testing and development."," It will not send commands to any node.","ssh: This setting will notify Heketi to ssh to the nodes."," It will need the values in sshexec to be configured.","kubernetes: Communicate with GlusterFS containers over"," Kubernetes exec api."],"executor": "ssh", #命令执行器配置为ssh"_sshexec_comment": "SSH username and private key file information","sshexec": { #命令执行器为ssh方式,改下面这段"keyfile": "/root/.ssh/id_rsa", #ssh的密钥"user": "root", #ssh的用户,我使用的是root用户"port": "22", #ssh的端口"fstab": "/etc/fstab" #存储挂载点的fstab文件,保持默认即可},"_kubeexec_comment": "Kubernetes configuration","kubeexec": { #命令执行器没有用到kubernetes,不用改"host" :"https://kubernetes.host:8443","cert" : "/path/to/crt.file","insecure": false,"user": "kubernetes username","password": "password for kubernetes user","namespace": "OpenShift project or Kubernetes namespace","fstab": "Optional: Specify fstab file on node. Default is /etc/fstab"},"_db_comment": "Database file name","db": "/var/lib/heketi/heketi.db", #heketi数据库文件,保持默认"_loglevel_comment": ["Set log level. Choices are:"," none, critical, error, warning, info, debug","Default is warning"],"loglevel" : "warning" #定义日志几级别}
}
启动heketi服务
#修改运行heketi服务的用户,默认是heketi用户,yum安装的时候默认创建了heketi用户,
#但是我们使用ssh的是root用户,所以需要修改一下运行heketi服务的用户
vim /usr/lib/systemd/system/heketi.service
User=root #改为root#启动heketi
systemctl daemon-reload
systemctl start heketi
systemctl enable heketi
systemctl status heketi
lsof -i:7890
测试hekeit
curl http://192.168.100.128:7890/hello
Hello from Heketi
配置hekeit-cli客户端工具的环境变量
echo 'export HEKETI_CLI_SERVER=http://192.168.100.128:7890' >> ~/.bash_profile #永久设置环境变量
echo 'export HEKETI_CLI_USER=admin' >> ~/.bash_profile #永久设置环境变量
echo 'export HEKETI_CLI_KEY=admin123456' >> ~/.bash_profile #永久设置环境变量
source ~/.bash_profile #立即生效
设置hekeit的topology文件
官网说必须向Heketi提供关于系统拓扑结构的信息。这允许Heketi决定使用哪些节点、磁盘和集群。
https://github.com/heketi/heketi/blob/master/docs/admin/topology.md
可以使用命令行客户端创建一个集群,然后向该集群添加节点,然后向每个节点添加磁盘。如果使用命令行,这个过程可能相当乏味。因此,命令行客户端支持使用拓扑文件将这些信息加载到Heketi,该拓扑文件描述集群、集群节点和每个节点上的磁盘信息。
#使用topology文件示例
heketi-cli topology load --json=<topology>
#编写topology文件,这个拓扑文件是一个JSON格式的文件,描述要添加到Heketi的集群、节点和磁盘
官网示例:https://github.com/heketi/heketi/blob/master/client/cli/go/topology-sample.json
#手动编写一个拓扑文件
vim /etc/heketi/topology.json
{"clusters": [{"nodes": [{"node": { #配置glusterfs节点1的信息,包括IP地址,磁盘设备"hostnames": {"manage": ["192.168.100.128" ],"storage": ["192.168.100.128"]},"zone": 1},"devices": [{"name": "/dev/sdb", #磁盘设备,必须是裸盘"destroydata": false}]},{"node": {"hostnames": {"manage": ["192.168.100.129"],"storage": ["192.168.100.129"]},"zone": 1},"devices": [{"name": "/dev/sdb","destroydata": false}]},{"node": {"hostnames": {"manage": ["192.168.100.130"],"storage": ["192.168.100.130"]},"zone": 1},"devices": [{"name": "/dev/sdb","destroydata": false}]}]}]
}#通过拓扑文件加载glusterfs节点到Heketi
[root@master heketi]# heketi-cli topology load --json=/etc/heketi/topology.json --server=http://192.168.100.128:7890 --user=admin --secret=admin123456Found node 192.168.100.128 on cluster f5dca07fd4e2edbe2e0b0ce5161a1cf7Adding device /dev/sdb ... OKFound node 192.168.100.129 on cluster f5dca07fd4e2edbe2e0b0ce5161a1cf7Adding device /dev/sdb ... OKFound node 192.168.100.130 on cluster f5dca07fd4e2edbe2e0b0ce5161a1cf7Found device /dev/sdb
[root@master heketi]# #查看信息,因为前面在/root/.bash_profile文件加了heketi-cli 客户端工具的环境变量,所以这里不用在写--server等参数
heketi-cli topology info
创建卷
发现好像不用创建卷,k8s可以直接使用。这里不创建卷。
k8s使用glusterfs作为后端存储(动态供给glusterfs存储)
上面,我们手动创建pv的形式实现了使用glusterfs作为后端存储,可是每次都要管理员手动创建pv很不现实,所以我们要实现采用动态供应存储的方式来实现k8s使用glusterfs存储:
1、创建一个srecrt,用户保存heketi服务的用户的密码,仅密码而已;
2、创建存储类;
3、一个制备器(Provisioner),k8s内置了glusterfs类型的Provisioner驱动,所以这里不用自己单独创建了;
4、创建pvc;
5、创建deployment,pod使用pvc进行数据持久化;
参考官网链接来创建:https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/
查看官方文档得知,k8s虽然内置了glusterfs的Provisioner(目前k8s说明会于1.25版本弃用glusterfs),但是创建存储类中的参数使用到了Heketi 服务,由Heketi 服务提供glusterfs。
1、创建secret,仅存储密码
vim heketi-secret.yaml #创建secret,主要用于保存heketi服务的admin用户密码
apiVersion: v1
kind: Secret
metadata:name: heketi-secretnamespace: default
data:# base64 encoded password. E.g.: echo -n "admin23456" | base64key: YWRtaW4xMjM0NTY= #这个是heketi服务的admin用户密码admin123456,仅密码而已
type: kubernetes.io/glusterfs#创建成功
kubectl apply -f heketi-secret.yaml
2、创建存储类
官网参考文档:https://kubernetes.io/zh-cn/docs/concepts/storage/storage-classes/#glusterfs
vim glusterfs-storageclass.yaml #创建存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: glusterfs-storageclass #存储名称
provisioner: kubernetes.io/glusterfs #指定存储类的provisioner,这个provisioner是k8s内置的驱动程序
reclaimPolicy: Retain #pvc删除,pv采用何种方式处理,这里是保留
volumeBindingMode: Immediate #卷的绑定模式,表示创建pvc立即绑定pv
allowVolumeExpansion: true #是否运行卷的扩容,配置为true才能实现扩容pvc
parameters: #glusterfs的配置参数resturl: "http://192.168.118.140:7890" #heketi服务的地址和端口clusterid: "0cb591249e2542d0a73c6a9c8351baa2" #集群id,在heketi服务其上执行heketi-cli cluster list能看到restauthenabled: "true" #Gluster REST服务身份验证布尔值,用于启用对 REST 服务器的身份验证restuser: "admin" #heketi的用户adminsecretNamespace: "default" #secret所属的密码空间secretName: "heketi-secret" #secret,使用secret存储了heketi的用户admin的登陆密码volumetype: "none" #卷的类型,none表示分布式卷,还有其他类型的卷,详见官网参考文档#创建成功
kubectl apply -f glusterfs-storageclass.yaml
4、创建pvc
vim glusterfs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:labels:pvc: glusterfsname: glusterfs-pvcnamespace: default
spec:accessModes:- ReadWriteManyresources:requests:storage: 600Mi #申请容量大小为600MstorageClassName: glusterfs-storageclass #指定使用的存储类#创建成功
kubectl apply -f glusterfs-pvc.yaml
#查看是否自动创建了pv,已经自动创建了pv,但是发现pvc、pv都变成了1Gi,这点不清楚为什么会这样,pvc明明定义的是600Mi,暂且不纠结这个问题
kubectl get pvc -l pvc=glusterfs
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
glusterfs-pvc Bound pvc-ca9f6b42-0db5-4ff2-b58d-0141575deb10 1Gi RWX glusterfs-storageclass 41s
kubectl get pv pvc-ca9f6b42-0db5-4ff2-b58d-0141575deb10
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-ca9f6b42-0db5-4ff2-b58d-0141575deb10 1Gi RWX Retain Bound default/glusterfs-pvc glusterfs-storageclass 56s
5、创建deployment,使用pvc进行数据持久化
vim glusterfs-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: nginxname: nginxnamespace: default
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- image: nginximagePullPolicy: IfNotPresentname: nginxports:- name: nginx containerPort: 80volumeMounts:- name: pvc-volume mountPath: /var/log/nginx #持久化nginx的日志volumes:- name: pvc-volumepersistentVolumeClaim:claimName: glusterfs-pvc readOnly: false
---
apiVersion: v1
kind: Service
metadata:labels:app: nginxname: nginxnamespace: default
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: nginxsessionAffinity: Nonetype: NodePort
---
#创建deployment资源
kubectl apply -f glusterfs-deployment.yaml
网页访问nginx,模拟产生nginx日志。
6、探究日志数据落盘到哪里了
在任意一个节点执行lsblk我们发现如下情况:
[root@matser ~]# cat /etc/fstab #自动挂载了

[root@node2 brick]# lsblk #多了很多分区
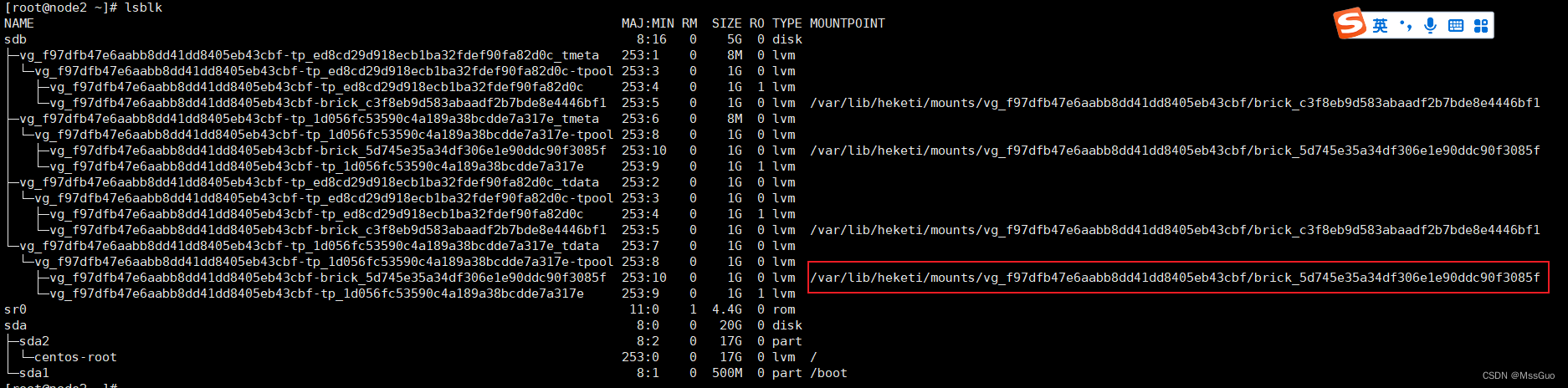
/dev/sdb原本是一个没有格式化过的裸盘,现在却出现了挂载点,进入挂载点查看:
[root@node2 ~]# cd /var/lib/heketi/mounts/vg_f97dfb47e6aabb8dd41dd8405eb43cbf/brick_5d745e35a34df306e1e90ddc90f3085f
[root@node2 brick_5d745e35a34df306e1e90ddc90f3085f]# ls
brick
[root@node2 brick_5d745e35a34df306e1e90ddc90f3085f]# cd brick/
[root@node2 brick]# ls
access.log error.log
[root@node2 brick]# echo "TEST" >> access.log #测试使用
#从上面我们看到,数据已经持久化到磁盘上了。
#下面来测试,删除deploymnet全部的pod,重新创建一个pod,查看pod能否读到之前的日志
[root@matser ~]# kubectl scale deployments.apps nginx --replicas=0
[root@matser ~]# kubectl get deployments.apps nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 0/0 0 0 29m
[root@matser ~]# kubectl scale deployments.apps nginx --replicas=2
[root@matser ~]# kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-78d9766679-cht5f 1/1 Running 0 53s
nginx-78d9766679-s7pft 1/1 Running 0 53s
[root@matser ~]#
#直接进入pod查看日志,我们发现日志还是之前的日志,有TEST字样,说明日志持久化成功了
[root@matser ~]# kubectl exec -it nginx-78d9766679-cht5f -- cat /var/log/nginx/access.log
.............
10.244.219.64 - - [23/Dec/2022:14:50:13 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36" "-"
10.244.219.64 - - [23/Dec/2022:14:50:13 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36" "-"
TEST
社区上有个项目可以实现在k8s集群上安装Heketi和glusterfs: https://github.com/gluster/gluster-kubernetes
总结
1、glusterfs文件系统创建和使用;
2、k8s中可以使用静态供给glusterfs存储和动态供给glusterfs存储两种方式来使用glusterfs,但是这两种方式配置差别很大,
3、k8s静态供给glusterfs存储:正常创建lvm,挂载磁盘,创建挂载点,安装glusterfs文件系统,创建卷,k8s通过创建endpoint,endpoint中定义glusterfs的ip和卷端口,pv中配置endpoint来使用gluster的卷,创建pvc,创建pod挂载pvc使用数据持久化;
4、k8s动态供给glusterfs存储:不需要创建lvm,只能是裸盘,没有格式化过,没有分区,没有创建过文件系统的裸盘,安装glusterfs文件系统,不需创建peers,不需要创建卷,安装heketi服务,由heketi服务管理、创建glusterfs集群,不需要heketi创建卷,创建好gluster集群即可,k8s创建存储类,配置存储类指定heketi相关信息,创建pvc,pvc指定存储类,存储类会自动创建pv,创建pod挂载pvc使用数据持久化;
思考
k8s于 v1.25 版本启用glusterfs,glusterfs是否还受欢迎;
pvc申请的容量大小明明是600Mi,怎么创建出来的却是1Gi呢;
k8s动态供给glusterfs存储时,heketi要求硬盘必须是裸盘,既然是裸盘,那就不需要我们参加创建文件系统,那文件随机挂载的吗?数据在落盘是背后的glusterfs逻辑是什么?
heketi要求硬盘必须是裸盘,那一块被格式化过的硬盘就真的没有办法使用了吗,这样岂不是很浪费硬件资源。