文章目录
- 1. 理解需求
- 1.1 功能性需求
- 1.2 非功能性需求
- 2. 系统设计
- 3. Api设计
- 4. 数据模型设计
- 5. 高可用、高性能、可监控等
- 数据密集型应用设计
- 凤凰架构
重点:自己整理的非权威,不具代表性,自己去取舍哈。
1. 理解需求
1.1 功能性需求
-
解决什么问题,达到什么目的,有什么场景
为什么要搞这个功能,可能是无价值功能。
-
系统的输入和输出?
-
提供的服务或功能是什么?
-
界面和边界是什么?
-
有哪些角色,有哪些模块,有哪些功能,哪些角色使用哪些模块、功能。
可以用表格或者用例图来更好的阐述。
管理员
- 人员管理
- 新增员工
- 员工离职
- 请假管理
- 请假审批
- 发起请假
普通员工
- 请假管理
- 发起请假
用例图示例:
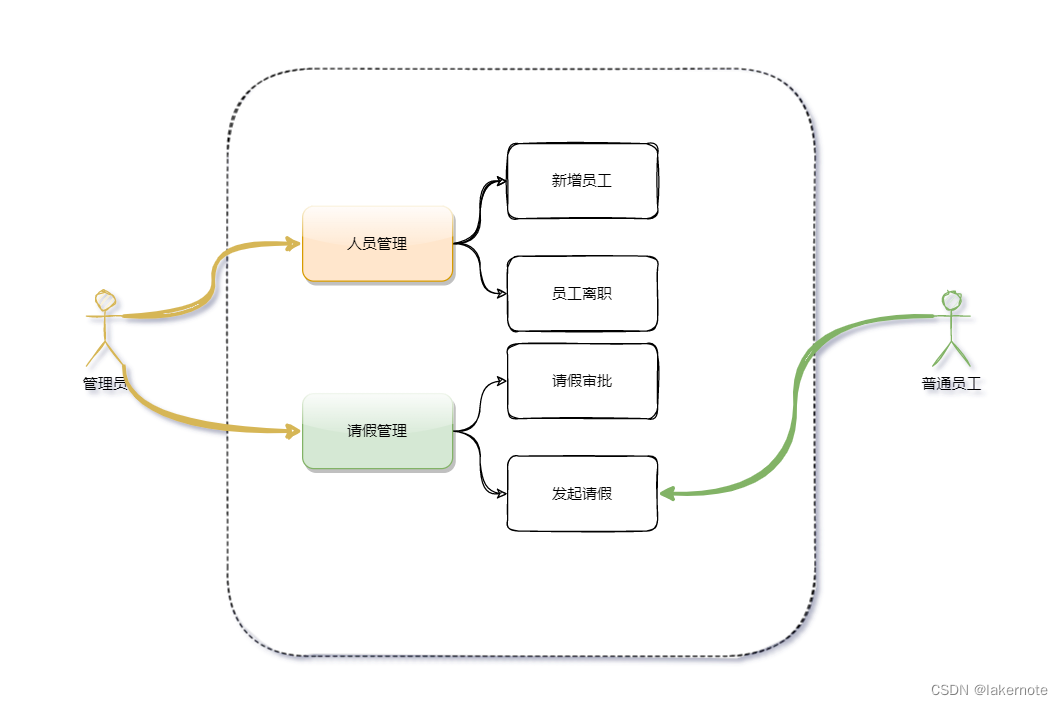
- 人员管理
1.2 非功能性需求
-
SLA - 可用性目标是什么?99%?99.999%?
-
总体用户数,多少活跃用户(DAU日活跃用户数)。
-
总PV数。
-
数据存储多久,数据保留策略,例如一般3年。
-
接口响应时长的要求。
网上看到过,一般是P99.99 1s,P95 200ms,具体要根据业务场景来定。
-
读写比例是多少。
根据日活跃用户数和总PV数能大概算出来系统的OPS和并发量。
原理:按二八定律来看,如果每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间 。
这里应该根据业务场景来定,例如这个时间 * 20%
针对一些政企机关单位这个时间不是 24h而是8h,应灵活运用。
- 峰值QPS:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
- 需要的机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
问:每天100w PV 的在单台机器上,这台机器峰值是多少QPS?
答:( 1000000 * 0.8 ) / (86400 * 0.2 ) = 46 (QPS)
问:如果一台机器的QPS是18,需要几台机器来支持?
答:46/ 18 = 3
2. 系统设计
这里把上面的需求整理出系统的概要设计。用C4模型来帮助梳理业务,架构软件。
-
C4模型
用4类图来阐述。
- 1.context 上下文 ,涉及系统边界【系统层面,涉及的所有系统】
- 梳理本系统与其他系统的关系,重点是大层面,系统间的关系。
- 用颜色区分 哪些已有系统和哪些 代建系统。
- 2.container 容器 显示组成该软件系统的容器(应用程序、中间件,数据存储、微服务等 【中间件层面,对上面进一步下钻放大 我们自己的服务】
- 梳理本系统内部的组件划分,组件将关系,聚焦系统内部组件。
- 3.component 组件 将单个容器放大,以显示其中的组件。这些组件映射到代码库中的真实抽象(例如一组代码)【代码层面 组件】
- 权限组件,通知组件,xx业务组件
- 4.Code 代码层面 约等于类图,一般不需要。
总结
一般画出以下几种图即可。
- 系统间上下文架构图。
- **系统内部容器(组件)**间关系图。
- 各内部组件时序图、流程图。
- 时序图,一般不要包含 if else 分支,否则会显得比较复杂。
- 流程图,针对复杂的逻辑,建议用流程图更容易理解。
- 1.context 上下文 ,涉及系统边界【系统层面,涉及的所有系统】
-
抽象 找出共同点和不同点,找出稳定点和变化点。
-
把大问题拆解成小问题。
-
聚焦核心业务,一口吃不成胖子。
3. Api设计
api设计和数据模型设计一起做,不分什么先后顺序。
符合Restful设计
-
REST 的做法是把不同业务需求抽象为对资源的增加、修改、删除等操作
-
使用 HTTP 协议的 Status Code,可以涵盖大多数资源操作可能出现的异常,而且 Status Code 可以自定义扩展,
-
依靠 HTTP Header 中携带的额外认证、授权信息
-
服务的 Endpoint 应该是一个名词而不是动词
-
每次请求中都应包含资源的 ID,所有操作均通过资源 ID 来进行
-
重复请求 425 Too Early
-
429 Too Many Requests
-
201 Created
-
409 Conflict 如果发生冲突。
| 方法 | 描述 | 幂等 |
|---|---|---|
| GET | 用于查询操作,对应于数据库的 select 操作 | ✔︎ |
| PUT | 用于所有的信息更新,对应于数据库的 update 操作 | ✔︎︎ |
| DELETE | 用于更新操作,对应于数据库的 delete 操作 | ✔︎︎ |
| POST | 用于新增操作,对应于数据库的 insert 操作 | ✘ |
| HEAD | 用于返回一个资源对象的“元数据”,或是用于探测API是否健康 | ✔︎ |
| PATCH | 用于局部信息的更新,对应于数据库的 update 操作 | ✘ |
| OPTIONS | 获取API的相关的信息。 | ✔︎ |
其中,PUT 和 PACTH 都是更新业务资源信息,如果资源对象不存在则可以新建一个,但他们两者的区别是,PUT 用于更新一个业务对象的所有完整信息,就像是我们通过表单提交所有的数据,而 PACTH 则对更为API化的数据更新操作,只需要更需要更新的字段(参看 RFC 5789 )。
不要机械地通过数据库的CRUD来对应这些动词,很多时候,还是要分析一下业务语义。
PATCH用于局部更新,比如,更新某个字段 cnt = cnt+1,明显不可能是幂等操作。
一般来说,对于查询类的API,主要就是要完成四种操作:排序,过滤,搜索,分页。下面是一些相关的规范。参考于两个我觉得写的最好的Restful API的规范文档,Microsoft REST API Guidelines,Paypal API Design Guidelines。
-
排序。对于结果集的排序,使用
sort关键字,以及{field_name}|{asc|desc},{field_name}|{asc|desc}的相关语法。比如,某API需要返回公司的列表,并按照某些字段排序,如:GET /admin/companies?sort=rank|asc或是GET /admin/companies?sort=rank|asc,zip_code|desc -
过滤。对于结果集的过滤,使用
filter关键字,以及{field_name} op{value}的语法。比如:GET /companies?category=banking&location=china。但是,有些时候,我们需要更为灵活的表达式,我们就需要在URL上构造我们的表达式。这里需要定义六个比较操作:=,<,>,<=,>=,以及三个逻辑操作:and,or,not。(表达式中的一些特殊字符需要做一定的转义,比如:>=转成ge)于是,我们就会有如下的查询表达式:GET /products?$filter=name eq 'Milk' and price lt 2.55查找所有的价柗小于2.55的牛奶。 -
搜索。对于相关的搜索,使用
search关键字,以及关键词。如:GET /books/search?description=algorithm或是直接就是全文搜索GET /books/search?key=algorithm。 -
分页。对于结果集进行分页处理,分页必需是一个默认行为,这样不会产生大量的返回数据。
- 使用
page和per_page代表页码和每页数据量,比如:GET /books?page=3&per_page=20。 - 可选。上面提到的
page方式为使用相对位置来获取数据,可能会存在两个问题:性能(大数据量)与数据偏差(高频更新)。此时可以使用绝对位置来获取数据:事先记录下当前已获取数据里最后一条数据的ID、时间等信息,以此获取 “该ID之前的数据” 或 “该时刻之前的数据”。示例:GET /news?max_id=23454345&per_page=20或GET /news?published_before=2011-01-01T00:00:00Z&per_page=20。
- 使用
-
要携带版本号和服务名属性
/xxxservice/api/v1/users
-
id不要携带业务属性
/xxxservice/api/v1/users/{id}
不要这样定义/xxxservice/api/v1/users/{userId}
因为冲path中已经知道是user可,不需要再用userId定义。
-
设计返回对象时,不建议直接是数组,因为不方便扩展,建议如下。
{
“total”: 10
“record” []
}
-
api设计聚合 和 拆解根据情况定
- 为了性能可以拆。
- 为了业务或者前端不能太多的call(太多call会导致请求排队) 可以聚合。
-
幂等性
GET/ PUT/ DELETE 一定要保证幂等
- PATCH 对资源执行部分更新。 请求正文包含要应用到资源的一组更改。
POST尽量保证幂等
-
接口是否有并发问题
- 同时多种例如 insert delete update
-
认证鉴权
- 每个接口都要认证 鉴权,什么接口 什么角色能调用,什么数据 什么人能查询 能删 能改。
-
安全
- 动态查询 动态排序要主要防止sql注入问题
动态排序 利用枚举字段限定。
用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定,防止 SQL 注入,禁止字 符串拼接 SQL 访问数据库。
-
PII UGC 要加密传输,输入 和输出都是密文
-
用户请求传入的任何参数必须做有效性验证。
页面 page size 过大导致内存溢出
恶意 order by 导致数据库慢查询
-
限流规则
处理 429 错误
如果您的应用程序达到 API 速率限制,Webex API 网关将返回429 Too Many Requests响应。响应包含一个Retry-After标头,指示您的应用程序在向同一端点发出另一个请求之前必须等待多长时间。例如,以下是一个 429 响应示例,指示应用程序在重试请求之前应等待 3600 秒。
HTTP/1.1 429 Too Many Requests\
Content-Type: text/html\
Retry-After: 3600
- 注意 是否有并发事务安全问题。(并发事务 操作多对象)
- 幂等 insert insert
- insert update delete
4. 数据模型设计
-
对应核心数据的增删改,尤其是改,要有DB log表 方便追踪。
-
数据库设计
-
表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示 是,0 表示否)。 注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在设置从 is_xxx 到 Xxx 的映射关 系。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的命名方式是为了明确其取值含义与取值范围。 说明:任何字段如果为非负数,必须是 unsigned。 正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
-
表名不使用复数名词。
-
禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
-
主键索引名为 pk_字段名;唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。 说明:pk_即 primary key;uk_即 unique key;idx_即 index 的简称。
-
varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此 值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引率。
-
表必备三字段:id,create_time,update_time。 说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。create_time,update_time 的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
-
在数据库中不能使用物理删除操作,要使用逻辑删除。 说明:逻辑删除在数据删除后可以追溯到行为操作。不过会使得一些情况下的唯一主键变得不唯一,需要根据情况来酌情解决。
可以有个删除表跟原始表结构一模一样,删除后把数据迁移到删除表,例如order,order_delete.
-
表的命名最好是遵循“业务名称_表的作用”。 正例:alipay_task / force_project / trade_config / tes_question
-
库名与应用名称尽量一致
-
字段允许适当冗余,以提高查询性能,但必须考虑数据一致。冗余字段应遵循:
- 1)不是频繁修改的字段。
- 2)不是唯一索引的字段。
- 3)不是 varchar 超长字段,更不能是 text 字段。
-
超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联 的字段需要有索引
-
业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
-
在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区 分度决定索引长度。
-
页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
-
如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部 分,并且放在索引组合顺序的最后,避免出现 filesort 的情况,影响查询性能。 where a = ? and b = ? order by c;索引:a_b_c
-
利用覆盖索引来进行查询操作,避免回表。
-
代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
-
数据订正(特别是删除或修改记录操作)时,要先 select,避免出现误删除的情况,确认无误才 能执行更新语句。
-
in 操作能避免则避免,若实在避免不了,需要仔细评估 in 后边的集合元素数量,控制在 1000 个之内。
-
更新数据表记录时,必须同时更新记录对应的 update_time 字段值为当前时间。
-
@Transactional 事务不要滥用。事务会影响数据库的 QPS,另外使用事务的地方需要考虑各 方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正,第三方回滚等。
-
5. 高可用、高性能、可监控等
- 超时控制
- 重试控制
- 降级策略
- 熔断策略
- 负载均衡
- LMA





![[整型/浮点型二分算法详解]二分查找算法真的很简单吗](https://img-blog.csdnimg.cn/8bb2be1a46e94d09bceeded959a45a59.png)