文章目录
- 一、概览
- 二、具体阐述
- 1. Introduction
- 2. 模型head介绍
- (1) Key points estimation--网络第一个head
- (2) Local geometry construction--网络第二个head
- 3. Network architecture
- 4. Decoder for global geometry
- (1) Greedy decoder(精度高,但是效率低)
- (2) Efficient decoder(可以并行,所以速度快,但是精度有损失)
- 5. Experiments
- 6. Conclusion and Future works
一、概览
论文:Focus on Local: Detecting Lane Marker from Bottom Up via Key Point
创新点: 提出一种新的车道线检测网络,FOLOLane,把车道线检测视作关键点评估+关联任务。降低计算成本的同时避免了Segmentation策略中噪声大、信息冗余的问题。最后FOLOLane在CULane和TuSimple数据集上均获得了SOTA的精度。
为什么: 主流的方法把车道线检测视作分割任务,但是这样一是计算量大,二是pixel-wise的输出存在信息的冗余、会带来大量的噪声干扰,导致后去post-processing过程聚类可能出错,影响精度。
怎么做: 通过轻量级的分割网络,输出两个分支,一个分支输出heatmap图表示像素是否是关键点,另一个分支输出offsets用于精准补偿关键点的位置。输出的网络通过关联算法完成局部到全局的曲线关联,形成多条完整的curve
核心: 主流的算法是直接建模车道线的整体结构,然后通过后处理求解曲线参数。复杂的车道线的形状需要CNN的高维输出,所以对模型能力和数据的要求都很高。 但是车道线的局部具有有限的几何变化和空间覆盖,所以建模局部的结构效率更高,对模型(可以使用很简单的模型)和数据(数据量要求很低)的要求也比较低。
出发点: 直接建模整条线的特征需要CNN的高维输出,对模型和数据的要求很高,但是建模局部信息比较简单。
第一次将车道线检测做成局部的几何建模。模型只需要在受限的空间范围内,关注于比较简单的任务,使估计出来的局部曲线非常精确。
输入一张图片,经过CNNs提取特征。把图片沿着高度等距离画线,距离为固定值,这样等分线和车道线曲线的交点就是关键点集合的子集。 CNN建模低复杂度的局部特征,使用了两个单独的head, 一个head用来预测key points,另一个head用来在局部范围内refine key point的位置(offset),并将在同一条线中的key points联系起来。
两个head 一共 逐像素的预测四个map:
- key points(heat map)
- 关键点 与 上一个交点关键点 在水平上的坐标偏差、
- 关键点 与 当前交点关键点 在水平上的坐标偏差、
- 关键点与下一个交点关键点在水平上的坐标偏差。
最后通过后处理连线。后处理有两种解码方式:efficiency-oriented decoding algorithm / a greedy one, 将局部信息整合为车道线的全局信息。在性能退化可忽略的情况下,实现了36%的加速。
二、具体阐述
1. Introduction
目前常用的方法是,使用语义分割或者目标检测算法解析车道线标记,加上后处理方法,将网络的输出转化为参数曲线。但是比较常用的框架无法推广到弯曲的车道线,因为车道线的检测需要同时精确表示局部位置和全局形状。
-
基于语义分割的算法。
将车道线预测为二值的mask,使用聚类算法将masked pixel分到不同的实例中,然后使用曲线拟合结果。
存在的问题:聚类使得训练和推理的过程复杂化;使用像素级输入来做曲线拟合通常是冗余和嘈杂的,这些像素都可能带来对正确率的负面影响。 -
基于目标检测的算法。
生成边界框作为输出(实际上使用的是anchor line,不是anchor box)。检测框往往覆盖了图片中的大部分区域,像素级的错误会严重影响检测的性能,原因可能是CNN学习到的feature是基于有限的感受野的,有限感受野使得特征不足以建模距离太远的content。(感受野比较小,没有覆盖整条曲线)
目前的算法大多数直接对全局几何进行建模,所以网络必须使用高维输出来描述曲线。不紧凑的输出增加了对数据和模型容量的需求,最终影响模型的泛化能力。
 (a)基于图像分割的方法,中间的图,聚类的结果错误,右侧的图,由于冗余和噪声像素所导致的车道线预测的位置偏差。(b)目标检测算法的感受野,右侧的小图中亮的区域为实际的感受野
(a)基于图像分割的方法,中间的图,聚类的结果错误,右侧的图,由于冗余和噪声像素所导致的车道线预测的位置偏差。(b)目标检测算法的感受野,右侧的小图中亮的区域为实际的感受野
尽管车道线的全局结构具有一定的复杂性,但是车道线的局部标记非常简单,并且车道线的全局信息可以通过局部线段的组合来近似。空间局部性更适合用CNN进行建模。根据这种直觉,作者提出了一种新的车道线检测算法,FOLOLane,该方法专注于对局部几何进行建模,并以自下而上的方式将它们集成到全局结果中。
具体来说,车道线的几何形状是通过其上的相邻关键点来预测的。在底层阶段,一个全卷积网络用两个独立的head捕获局部范围内的关键点。
- 第一个head给出 某一个pixel为关键点的概率,(类似centernet的 基于guass分布的heat map)
- 第二个给出 关键点 与 离它最近的局部车道线的距离,用来refine关键点的位置。
并且建立同一条线上的key points之间的联系。基于这些局部信息,使用两种具有不同偏好的decoder算法来预测车道线的全局几何形状。
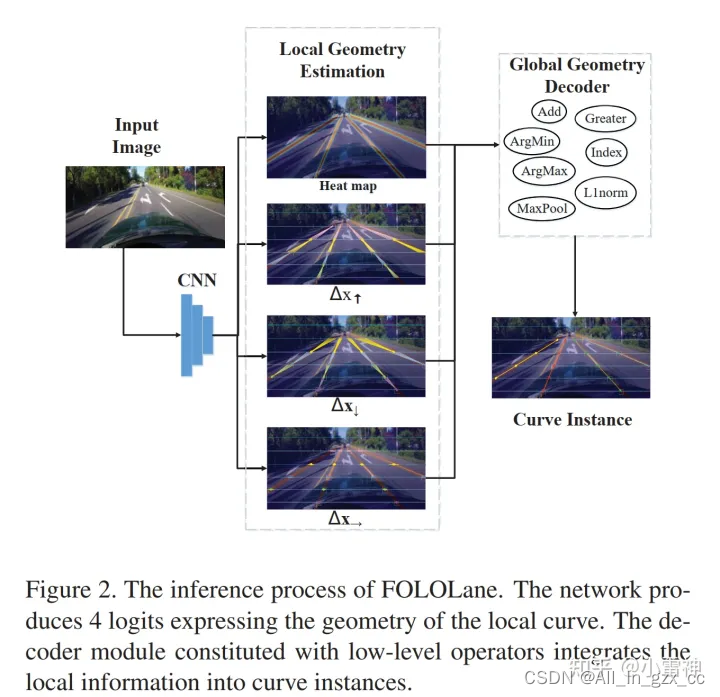
将CNN的能力集中在局部范围内,适用于CNN有限的FOV;显著降低任务的复杂性与输出的维度;紧凑的输出(低维输出)可以实现稳定高效的训练,而无需额外的网络架构设计和数据收集;decoder用来解决车道线的连续性问题。
本文首次将车道线检测的问题转化为多点估计和链接的问题–>收到自底向上的人体姿势估计问题的启发
基于局部范围的方法避免了基于检测的方法中出现的距离锚点较远的位置的预测不准确的问题。
关键点的稀疏性防止了基于分割的方法中出现的噪声和冗余的输出(降低了曲线拟合的精度并增加了延迟)
该方案不依赖于CNN架构,可以使用各种网络架构。一般是resnet+fpn的结构作为backbone,最后将特征图unsample到原图大小,再接head去处理。
2. 模型head介绍
-
predicted marker curve: 一组有序关键点(key points),y坐标具有均匀间隔
-
labelled marker curve: 一组有序关键点(key points),y坐标具有均匀间隔。
-
在
key points estimation的步骤, 训练的时候,对curve进行插值,连成一条线,作为label,这条线上的每一个像素都被认为是key point,ground truth值为1。对曲线的高斯核范围内的邻居点赋值0-1之间。 -
在
Local geometry construction的步骤, 训练的时候,key points就是单独的点,等距离间隔和车道线的交点。
预测的车道线被表示为一个有序的关键点集,这些关键点在相邻行之间有固定/预定义的垂直间隔Δy
曲线预测的任务被全卷积网络分为两个子任务(网络有两个头):
(1)关键点出现的可能性,解决了局部曲线是否存在的问题
(2)到最近的车道线的偏移量,描述了局部曲线的精确几何形状
(1) Key points estimation–网络第一个head
每一条预测的曲线都表示为点集(纵坐标固定);ground truth其实也是点集,但是在生成ground truth的时候,以插值方式连成了线,并使用了高斯模糊。(和centernet中心点的处理一模一样,从关键点往外,从1递减)但是只有ground truth为1的像素才是正样本,其他的都是负样本。
CNN第一个head的输出是一个和输入尺寸一致的feature map(heat map),代表每个像素点为车道线 key points的概率。
为了处理样本类别不均衡问题(key point是稀疏的,负样本远多于正样本),使用了带权重的loss函数—Focal Loss。

loss的前一项是,控制正负样本的惩罚,离正样本越远的负样本,惩罚越大;后一项是,控制难易样本,越难的样本,惩罚越大。
只有lane附近的pixel参与网络的训练,而非全图的pixel,简化网络训练同时减少噪声和冗余信息的干扰。
没有纯负样本。在该算法中,loss的计算只有部分像素,也就是ground truth 和ground truth的高斯核覆盖的范围,且距离positive的距离越远的负样本,惩罚系数越大,如图中所示的部分,最终计算得到的结果是车道线的中间部分的响应是最高的,周围的响应逐渐变弱,降低了噪声与冗余部分的影响,只关注对车道线检测最有益的部分像素。

(2) Local geometry construction–网络第二个head
衡量 像素点 与 真实车道线的交点 偏移量offset(原图输入在提特征缩小时,坐标不一定能整除)
这个head里 提取出上面提到的 4个feature map 里剩下三个:

我们通过对人工标注的关键点插值,可以得到一条连续的曲线,曲线宽度为一个像素左右,曲线上的像素点就是key-points集合。把图片沿着高度等距离划线,距离为固定值Δy。这样等分线和车道线的交点就是关键点集合的子集,可以成为交点关键点。
对于一个等分线上的像素p,
- Δx↑ 是它与上一个交点关键点在水平上的坐标偏差;
- Δx→ 是它与当前交点关键点在水平上的坐标偏差;
- Δx↓ 是它与下一个交点关键点在水平上的坐标偏差;
已知p的坐标和三个预测值,则其上中下三个交点关键点的坐标可以确定:
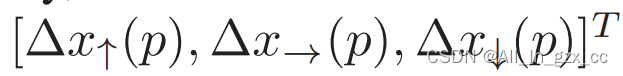
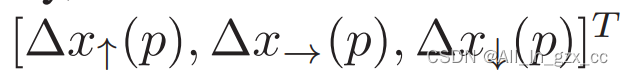
该向量描述像素p到离其最近的curve的偏移。描述的是p到附近的3个key points的偏移,分别是与其同一个y值的,向上偏移Δy,向下偏移Δy。
训练设置:训练时等分线不是固定的,而是根据 采样点p 以及 超参Δy 自适应的选取。key-points全集合的像素点的近邻像素都可以是采样点。

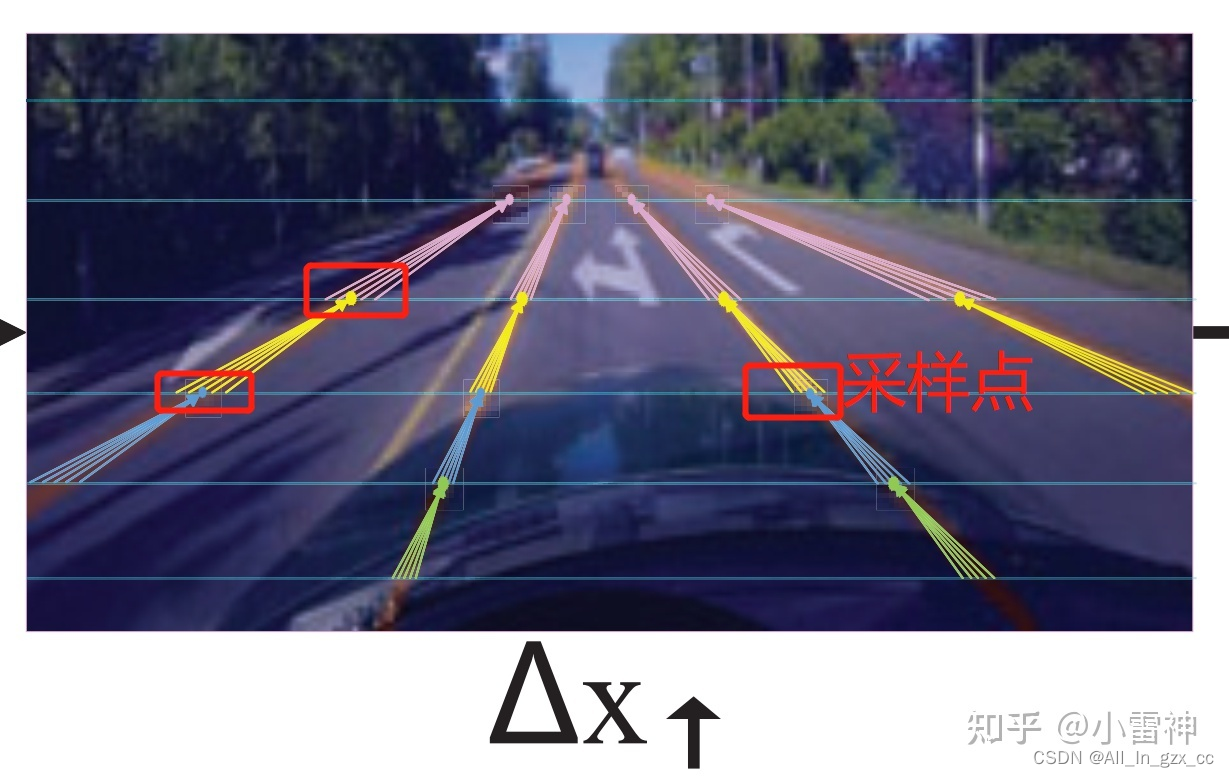
p是采样点,所以前一项的x坐标是不同的,是预测的坐标,后一项的x坐标是固定的
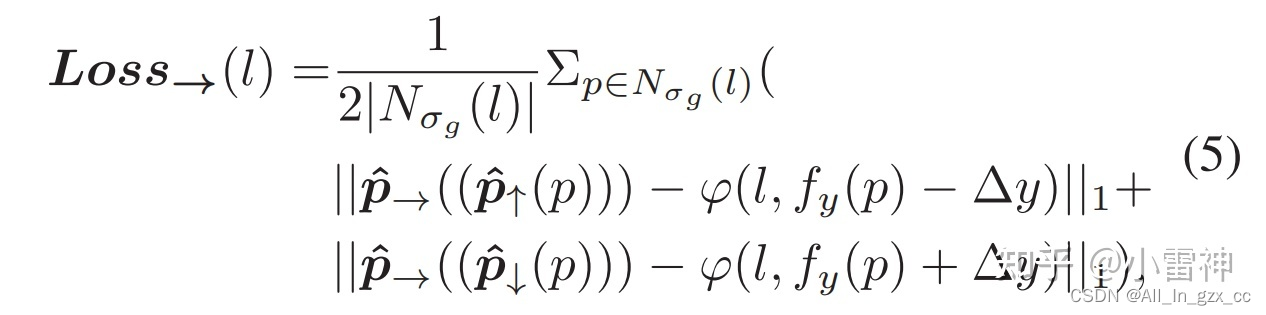
对于 Δx→ 的训练没有使用p点本身,二是使用上面预测的下方点 p↓§ 和上方点 p↑§ 作为采样点,继续优化x的偏差。即coarse-to-fine策略。
3. Network architecture
使用轻量级的网络架构就可以,4张特征图都是网络的decoder的输出生成的。

4. Decoder for global geometry
CNN的输出是一个pixel-wise heatmap 和keypoints的偏移量。
-
heatmap来确定曲线的出现和消失。
-
偏移量用来将一条线内的keypoints联系起来,并且refine坐标信息。
两个decoder分别解决两个问题:accuracy 和 efficiency
(1) Greedy decoder(精度高,但是效率低)
step1. 在heatmap上寻找具有最大相应的点的个数最多的行(数量最多,目的是找全所有的车道线),作为 starting line, 这些点作为key points。一个像素点构成一个曲线。
step2. refine这些点的位置,使用 Δx→ 来refine。
step3. 寻找这些point在垂直方向上的邻居点,这些点是利用 Δx↑ 和 Δx↓ 计算的。
step4. 判断垂直方向上扩张的点,heatmap上对应的值是否大于阈值。若大于阈值,那么这些点作为新的key point,若小于阈值,那么停止搜索,所有起点相同的点相连称为一条线。(具有遮挡的那些线怎么办???中间断掉的线???)
(2) Efficient decoder(可以并行,所以速度快,但是精度有损失)
step1. heatmap以相同的间距划分为不同的行,每行选取最大响应的点(多个点,估计是给了个阈值)作为 keypoints。(每行具有最高响应的点构成current key-points)
step2. 每个keypoint计算3个相关的点,使用 Δx→ ,Δx↑ 和 Δx↓
step3. 建立不同行之间的联系,对于一个点p,它要和相邻行的点联系(距离p⬆和p⬇最近的点)
Step4. 从具有最多局部极值点(current key-point)的行开始,该行的点作为keypoint,按照第3步的要求,为每一个keypoint,相关的点放到一个group中,每个group中的点连成一条线。使用 Δx→ 来refine曲线的位置。
5. Experiments
数据集:

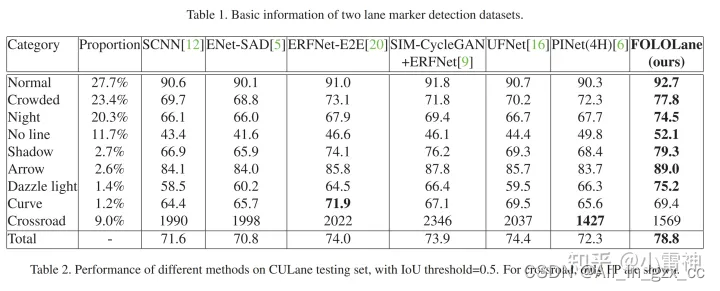
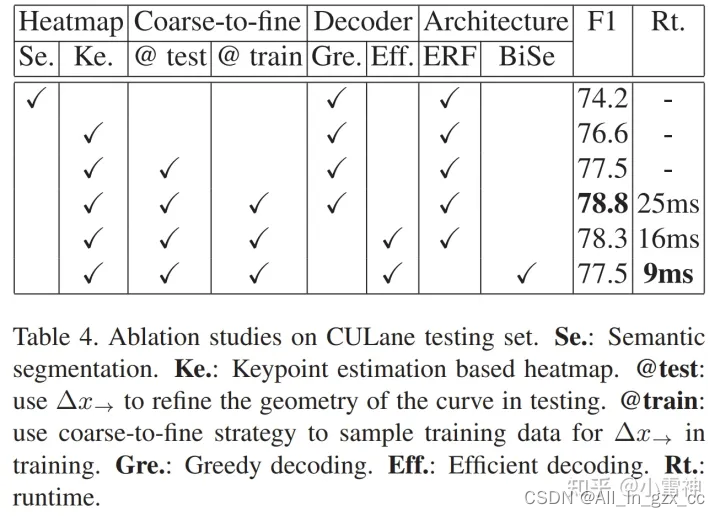
6. Conclusion and Future works
Experimental results show the keypoint estimation and the coarse-to-fine refinement strategy circumvent the influence from ambiguous and noisy pixels, effectively improves the accuracy of curve geometry.
future work:
FOLOLane+self-attention / FOLOLane+MindSpore
参考链接:
https://zhuanlan.zhihu.com/p/520258828
https://zhuanlan.zhihu.com/p/516367912
https://zhuanlan.zhihu.com/p/390521498