深度学习-第P1周——实现mnist手写数字识
- 深度学习-第P1周——实现mnist手写数字识
- 一、前言
- 二、我的环境
- 三、前期工作
- 1、导入依赖项并设置GPU
- 2、导入数据集
- 3、数据可视化
- 四、构建简单的CNN网络
- 五、训练模型
- 1、设置超参数
- 2、编写训练函数
- 3、编写测试函数
- 4、正式训练
- 六、结果可视化
- 七、总结
深度学习-第P1周——实现mnist手写数字识
一、前言
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
二、我的环境
- 电脑系统:Windows 10
- 语言环境:Python 3.8.5
- 编译器:colab在线编译
- 深度学习环境:Pytorch
三、前期工作
1、导入依赖项并设置GPU
所需库函数的介绍:
- numpy是Python科学计算的基本包。
- matplotlib 是在Python中常用的绘制图形的库。
- PyTorch是一个开源的深度学习框架,提供了各种张量操作并通过自动求导可以自动进行梯度计算,方便构建各种动态神经网络
- torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型
- torch.device代表将torch.Tensor分配到的设备的对象,其包含一个设备类型('cpu’或’cuda’设备类型)和可选的设备的序号。如果设备序号不存在,则为当前设备
导入依赖项:
1.#导入所需要的库
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvisiondevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")device

2、导入数据集
使用dataset下载MNIST数据集,并划分训练集和测试集
使用dataloader加载数据,并设置好基本的batch_size
torchvision.datasets.MNIST详解
torchvision.datasets.MNIST是pytorch自带的一个数据库,我们可以通过代码在线下载数据,这里使用的是torchvision.datasets中的MNIST数据集
函数原型:
torchvision.datasets.MNIST(root, train = True, transform = None, download = False)
参数说明:
- root(string): 数据地址
- train(string): True = 训练集, False = 测试集
- transform(callable, optional): 这里的参数选择一个你想要的数据转化函数,直接完成数据转化
- download(bool, optional):如果为True,从互联网上下载数据集,并把数据集放在root目录下
2.#加载数据集,并划分训练集和测试集
train_ds = torchvision.datasets.MNIST('data',train = True, transform = torchvision.transforms.ToTensor(), #将数据类型转化为Tensor类型download = True )
test_ds = torchvision.datasets.MNIST('data',train = False,transform = torchvision.transforms.ToTensor(),download = True)
torch.utils.data.DataLoader详解
- torch.utils.data.DataLoader是pytorch自带的一个数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据量
- 在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。
torch.utils.data.DataLoader(dataset, batch_size, shuffle)
参数说明:
- dataset: 加载的数据集
- batch_size:每批加载的样本大小,默认为1
- shuffle:如果为True,则打乱数据的顺序
- 如下第一个函数就是将训练集生成迭代数据,每次迭代的数据为32个,shuffle为洗牌操作,即打乱顺序。
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds, batch_size = batch_size, shuffle = True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size = batch_size)#取一个批次查看数据格式
#数据的shape为:[batch_size, channel, height, weight]
#其中batch_size是样本批次,channel, height, weight分别是图片的通道数,高度和宽度
#train_dl本质上是一个可迭代对象,可以使用iter()进行访问,采用iter(dataloader)返回的是一个迭代器,然后可以使用next()访问。
#也可以使用enumerate(dataloader)的形式访问。
imgs, labels = next(iter(train_dl)) #第一次使用next访问的是迭代器里的第一批数据,二次是第二批,以此类推img = imgs[0] #访问第一批数据里的第一个数据
print(imgs.shape, img.shape)

3、数据可视化
3.#数据可视化
import numpy as np#指定图片大小,图片大小为20宽,5高的绘图(单位为英寸)
plt.figure(figsize = (20, 5))
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
for i, imgs in enumerate(imgs[:20]): #维度缩减,把维度为1的去掉 如:[32, 1, 28,28]->[32, 28, 28]npimg = np.squeeze(imgs.numpy())#将整个figure分成2行10列,绘制第i + 1个子图plt.subplot(2, 10, i + 1)# imshow()函数格式为:#matplotlib.pyplot.imshow(X, cmap=None)#X: 要绘制的图像或数组。#cmap: 颜色图谱(colormap), 默认绘制为RGB(A)颜色空间。plt.imshow(npimg, cmap = plt.cm.binary)plt.axis('off')
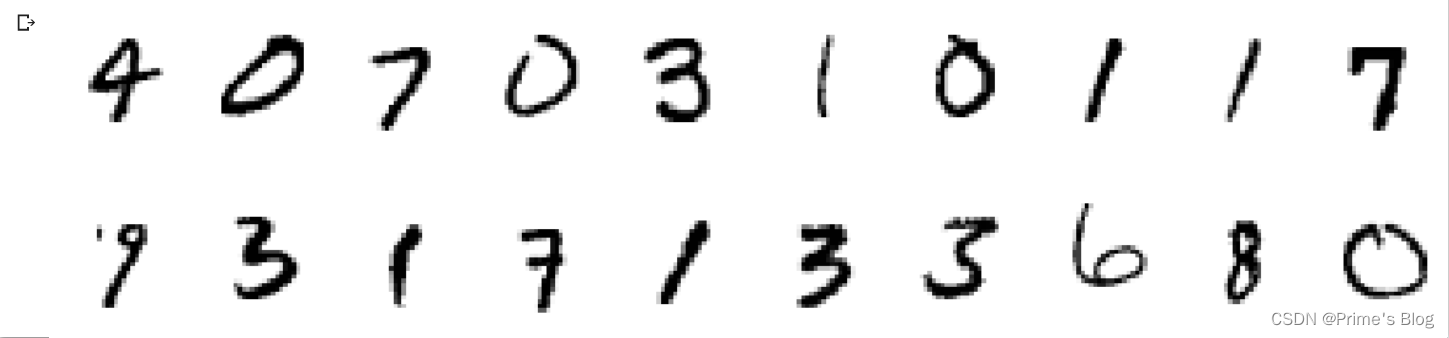
四、构建简单的CNN网络
对于一般的CNN网络来说,都是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
- nn.Conv2d为卷积层,用于提取图片的特征,传入参数为输入channel,输出channel,池化核大小
- nn.MaxPool2d为池化层,进行下采样,用更高层的抽象表示图像特征,传入参数为池化核大小
- nn.ReLU为激活函数,使模型可以拟合非线性数据
- nn.Linear为全连接层,可以起到特征提取器的作用,最后一层的全连接层也可以认为是输出层,传入参数为输入特征数和输出特征数(输入特征数由特征提取网络计算得到,如果不会计算可以直接运行网络,报错中会提示输入特征数的大小,下方网络中第一个全连接层的输入特征数为1600)
- nn.Sequential可以按构造顺序连接网络,在初始化阶段就设定好网络结构,不需要在前向传播中重新写一遍
下方代码各函数参数详解:
nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding) 二维卷积
- in_channels: 输入张量的channels数
- out_channels:期望输出张量的channels数
- kernel_size:卷积核的大小
- stride:步长,即卷积核在图像窗口上每次平移的间隔
- padding:图像的填充数
nn.MaxPool2d(kernel_size)
- kernel_size: 最大池化的窗口大小
nn.Linear(in_features,out_features,bias = Ture)
- in_features:输入的神经元个数
- out_features:输出的神经元个数
- bias:是否包含偏置
#二、构建简单的CNN网络
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
import torch.nn.functional as F
num_classes = 10
class Model(nn.Module):def __init__(self):super().__init__()#特征提取网络self.conv1 = nn.Conv2d(1, 32, kernel_size = 3) # 第一层卷积,卷积核大小为3*3self.pool1 = nn.MaxPool2d(2) #设置池化层,池化核大小为2*2 self.conv2 = nn.Conv2d(32, 64, kernel_size = 3) #第二层卷积,卷积核大小为3*3self.pool2 = nn.MaxPool2d(2)#分类网络self.fc1 = nn.Linear(1600, 64)self.fc2 = nn.Linear(64, num_classes)#前向传播def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = torch.flatten(x, start_dim = 1) #Flatten层,连接卷积层与全连接层x = F.relu(self.fc1(x))x = self.fc2(x)return x加载并打印模型:
#加载并打印模型
from torchinfo import summarymodel = Model().to(device)
summary(model)

五、训练模型
1、设置超参数
- torch.optim是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法。
- 为了使用torch.optim,你需要构建一个optimizer对象。这个对象能够保持当前参数状态并基于计算得到的梯度进行参数更新。
- 其中的SGD是optim中的一个算法(优化器):随机梯度下降算法
- 动手学深度学习-多层感知机中:updater = torch.optim.SGD(params, lr=lr)。其中的updater就是一个optimizer对象。“”"
loss_fn = nn.CrossEntropyLoss() #创建损失函数
learning_rate = 1e-2
opt = torch.optim.SGD(model.parameters(), lr = learning_rate) #待优化参数的iterable(w和b的迭代), 学习率
2、编写训练函数
- .item():求出张量具体位置的元素值的高精度值
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) #训练集的大小, 一共60000张照片num_batches = len(dataloader) #批次数目,1875(60000/32)train_loss, train_acc = 0, 0 #初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) #网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算两者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归0loss.backward() # 反向传播optimizer.step() # 每一步自动更新#记录acc和 losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
3、编写测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) #测试集的大小,一共10000张照片
num_batches = len(dataloader) #批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc =0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)#计算Losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= size
test_loss /= num_batchesreturn test_acc, test_loss
4、正式训练
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')

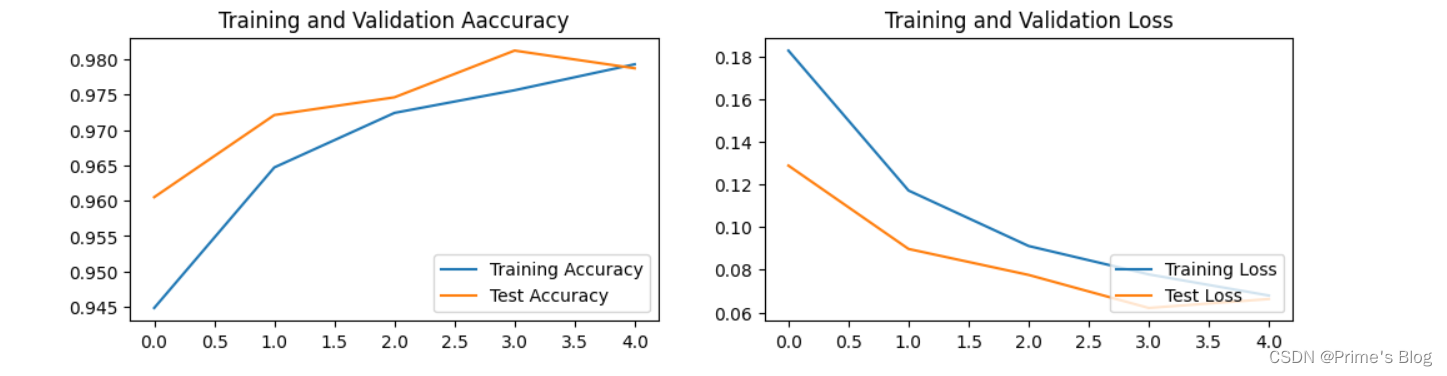
六、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽视警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示正负号
plt.rcParams['figure.dpi'] = 100 # 分辨率epochs_range = range(epochs)plt.figure(figsize = (12, 3))plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label = 'Training Accuracy')
plt.plot(epochs_range, test_acc, label = 'Test Accuracy')
plt.legend(loc = 'lower right')
plt.title('Training and Validation Aaccuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label = 'Training Loss')
plt.plot(epochs_range, test_loss, label = 'Test Loss')
plt.legend(loc = 'lower right')
plt.title('Training and Validation Loss')plt.show()
七、总结
该项目花了整整一天的时间,自己能理解的部分为目录一到四和七,从构建CNN网络开始就略有乏力,训练模型就完全看不懂了,自己也是尽最大程度的把各函数及其参数搜索并记忆。从结果来看,还是自身基本知识掌握的不到位,连CNN网络的概念都不清楚,下一步的计划是把吴恩达深度学习的视频和课后作业刷完,至少要明白卷积,池化,全连接层的定义和输出的结果以及这些层在背后的意义。


![[附源码]Python计算机毕业设计Django校园订餐系统](https://img-blog.csdnimg.cn/fb183291893647f988f0ab9c95bef7be.png)

![Matplotlib入门[04]——处理图像](https://img-blog.csdnimg.cn/1f9d779af5574b1897f69defdf703b97.png)