yolo后处理就是模型的输出进行处理,得到我们想要的坐标框的xywhxywhxywh以及confidenceconfidenceconfidence
学习笔记
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bdB1sYQ4-1670143551092)(https://gitee.com/lizheng0219/picgo_img/raw/master/img2/image-20221204163144547.png)]](https://img-blog.csdnimg.cn/121e826ed6de455ba9f06e8b222f7b70.png)
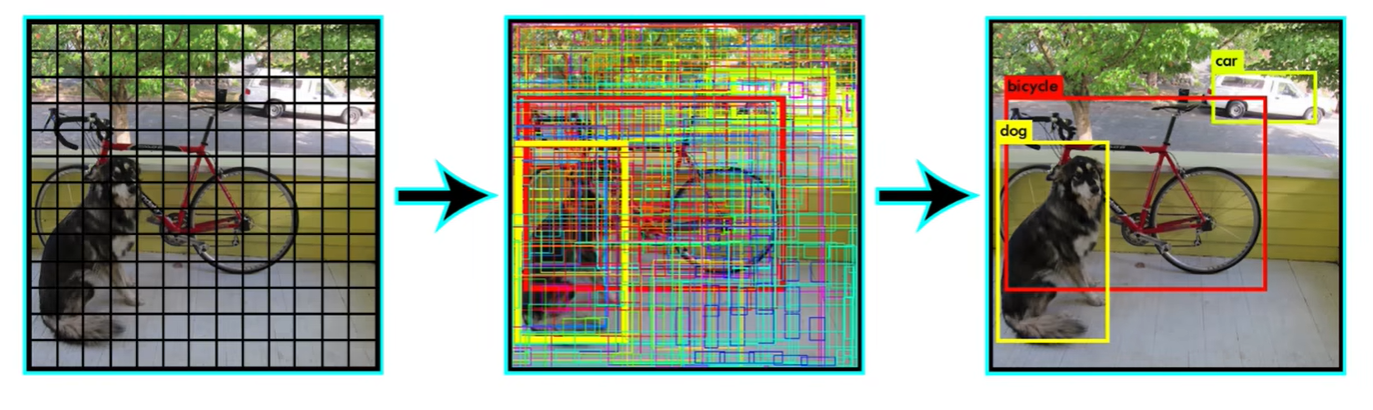
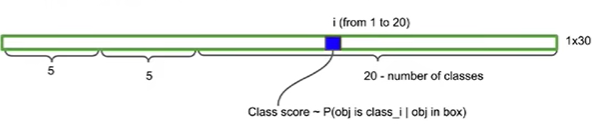
这是yolov1的模型,他将图像划分成了7x7个网格,每个网格负责预测两个边界框,每个边界框都有5个信息$x、y、w、h、confidence $ ,(这个confidence是该区域有目标框的概率),共预测20个类,每个类都有一个置信度信息(这个confidence是这个框是猫是狗的概率),所以最终输出为 7∗7∗307*7*307∗7∗30
然后每个边界框的confidence 乘以所有类别的confidence就是边界框的全概率
这样每个grid cell都能有两个20维向量,一共49个grid cell,所以共有98个向量
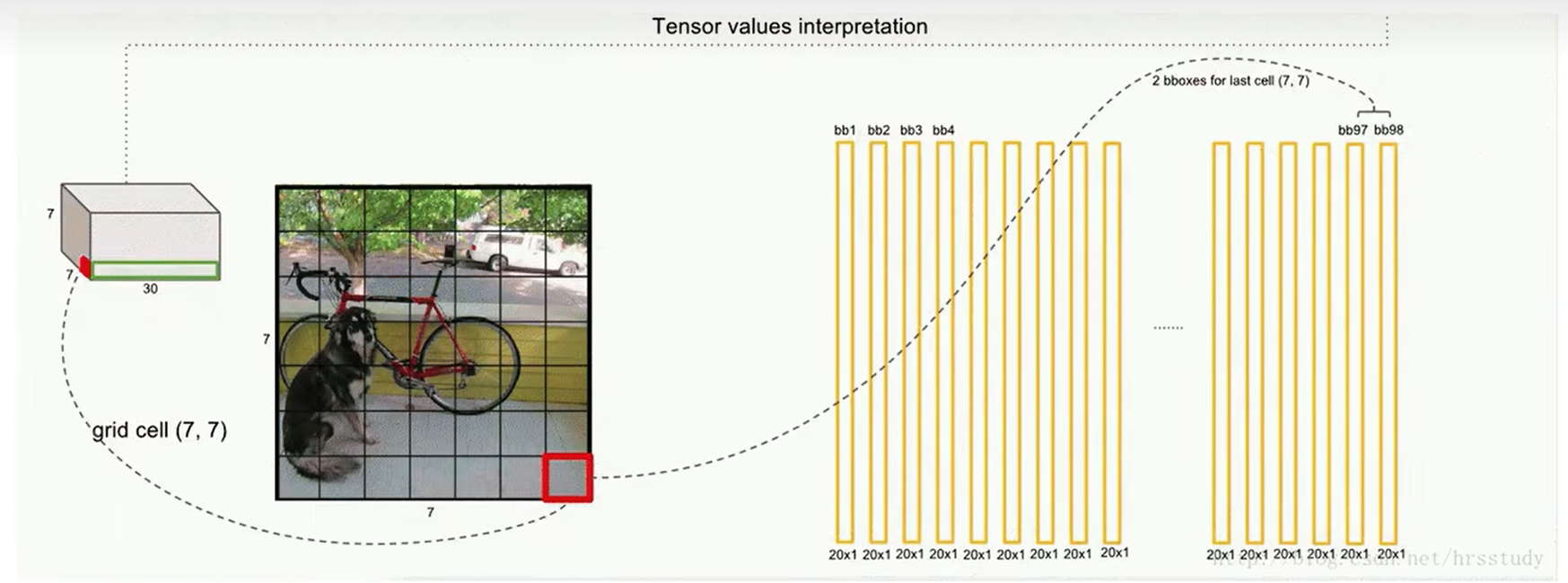
这些向量就组成如下的很多边界框

下一步就是筛选出真正的边界框
第一步:这张图片上并不是有20个类的,所以先有个阈值将大于这个阈值的类别筛选出来,比如筛选出了dog、bicycle、car
然后分别对这三个类处理,比如先对dog,从dog类的所有96个置信度进行从大到小排个序,设置一个阈值,confidence小于这个阈值的就被舍去了。
但确实还有真正包含某个物体的多个框,比如下面四个bbox的置信度都比较大,那怎么从这多个框中选择最合适的呢?
下面就是非极大抑制NMS
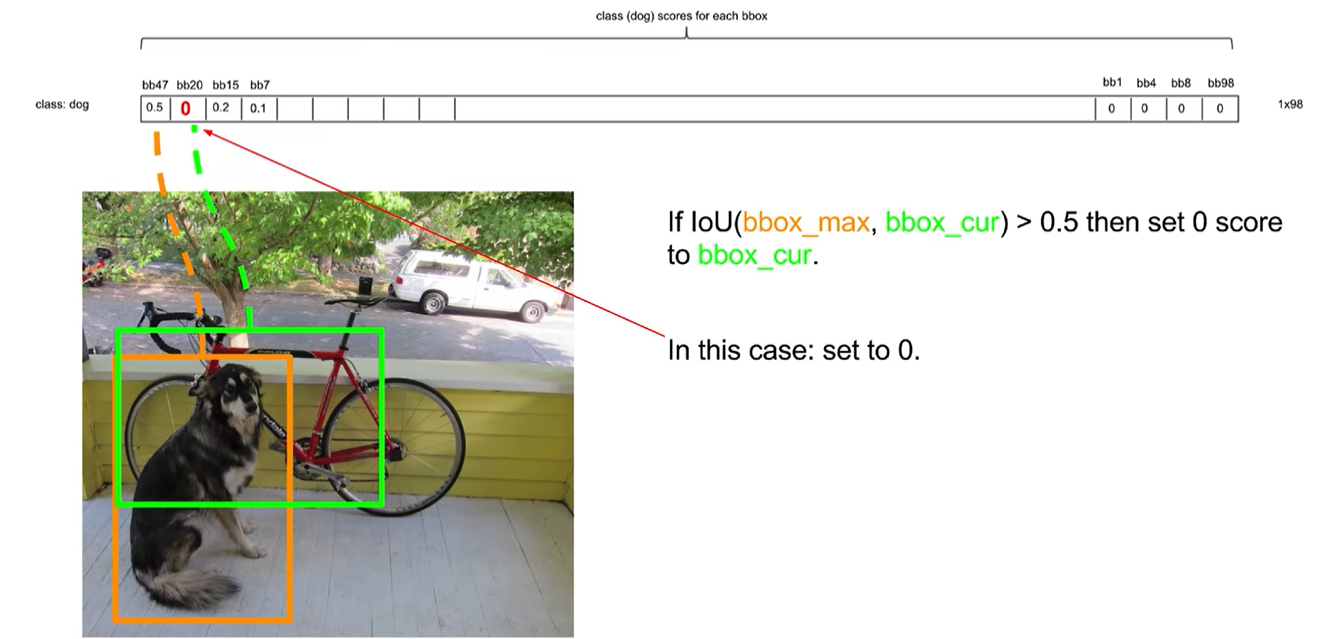
应该先将置信度最大的拿出来,然后后面的每一个都与第一个最大的作比较,如果IOU大于某个阈值,则认为两个识别了同一个物体,则把低置信度的那个抑制掉。比如bbox20和bbox47重合度较大,所以认为两个是同一物体。
如果IOU小于这个阈值,就说明两个框不是识别的同一个物体,保留。bb15和bb7与bb47的重合度较小,所以认为两个box不是同一个物体。
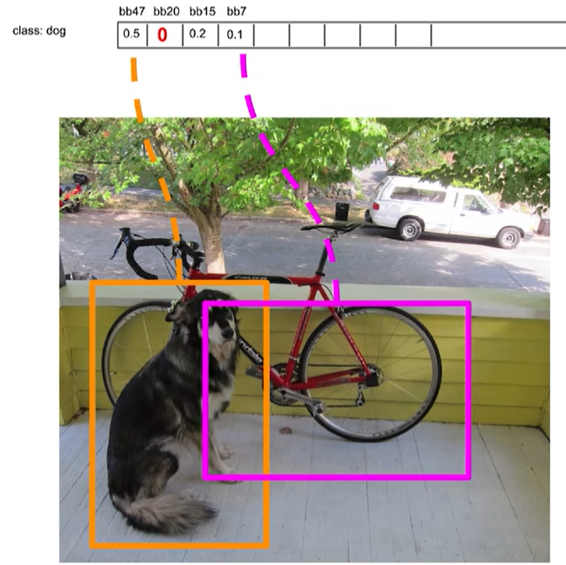
然后选取剩下的第二大置信度作为基box,其他框再与这个框比较,比如bb7和bb15重合度较大,认为这两个box内是同一个物体。

合适的阈值下可能只留下一个框,当然某些阈值下可能会保留更多的框,阈值的设置应该是根据目标任务设置的,越高的阈值(越不容易置零,即越宽容)会检测出越多的目标。
对其他类别也是同样操作,就得到了所有的目标框。
当然注意,在训练阶段是不需要剔除框的,所有框对我们反向传播参数更新都是有用的,只是在推理阶段需要这样做。