熟话说的好:”纸上得来终觉浅,绝知此事要躬行“,所以现在我就以下的习题,来巩固 之前我学习的几个常见集合函数,加深理解。
目录
练习题 1:计算分组后的list 分别对应的长度,和累加值
练习题 2: 实现 wordcount
练习题 1:计算分组后的list 分别对应的长度,和累加值
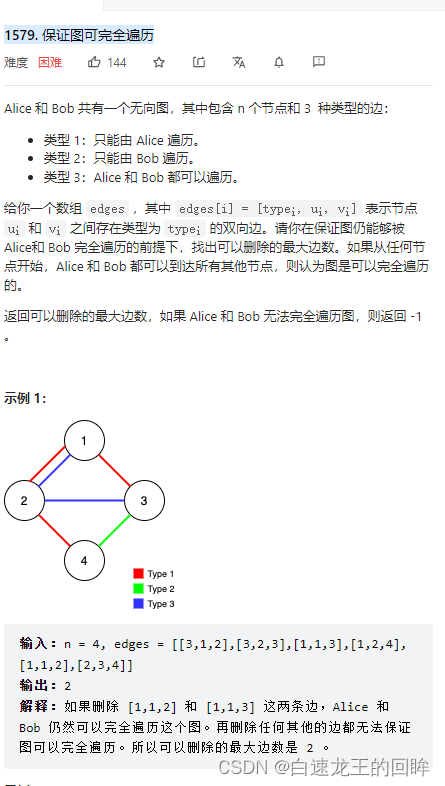
List(("a", 10), ("b", 2), ("a", 3))
OUT===>
Map(b -> (2,5), a -> (2,13))
解释:a的长度为2。b的长度为1。 a的累加值为13,b的累加值为2

import scala.collection.mutable.ListBuffer/*** @author:码到成龚* my motoo:"听闻少年二字,应与平庸相斥。"*/
object Test1_1 {def main(args: Array[String]) {// 本例代码中的变量命名:①无嵌套的数据结构:只使用单个单词②嵌套的数据结构:被嵌套的数据结构_嵌套的数据结构// 接收结果的变量命名:①包含的元素1_包含的元素2_变量类型_表达式中使用到的函数// 调用函数时的注释:①数据调用第一个函数输出的结果为OUT①,调用第二个函数的结果为OUT②....以此类推println("="*20+"初始的两个map集合"+"="*22)val tup2_list=List(("a",10),("b",2),("a",3),("b",3))val tup2_map_gb_mp=tup2_list.groupBy(f=>f._1).mapValues(list=>list.size)/*** OUT①Map(a-> ListBuffer(("a",10),("a",3)),b -> ("b",2))* OUT②Map(b -> 1, a -> 2)*/println(tup2_map_gb_mp)val tup2_map_gb_mp_rd_mp=tup2_list.groupBy(f=>f._1).mapValues(list=>list.reduce((a,b)=>("sum",a._2+b._2))).mapValues(f=>f._2)/*** OUT①Map(b -> ("b",2),a-> ListBuffer(("a",10),("a",3)))* OUT②Map(b -> ("b",2),* a-> ("sum",13))* OUT③Map(b -> 2,a-> 13)*/println(tup2_map_gb_mp_rd_mp)println("="*22+"取出值与和组成元组(方法一)"+"="*22)val string_int_map=tup2_list.groupBy(f=>f._1).mapValues(key=>(key.size,key.map(f=>f._2).sum) // 将原value的长度与其和组成元组,组成新的map集合的value)/***OUT①:groupBy=> Map(b -> ("b",2),a-> ListBuffer(("a",10),("a",3)))*OUT①:mapValues=> Map(b -> (2,5), a -> (2,13))*/println(string_int_map)练习题 2: 实现 wordcount
List("a b a a c d", "a d e s")
实现统计单词的个数
1 按照单词自然顺序升序
2 按照单词个数从大到小排序
OUT===>
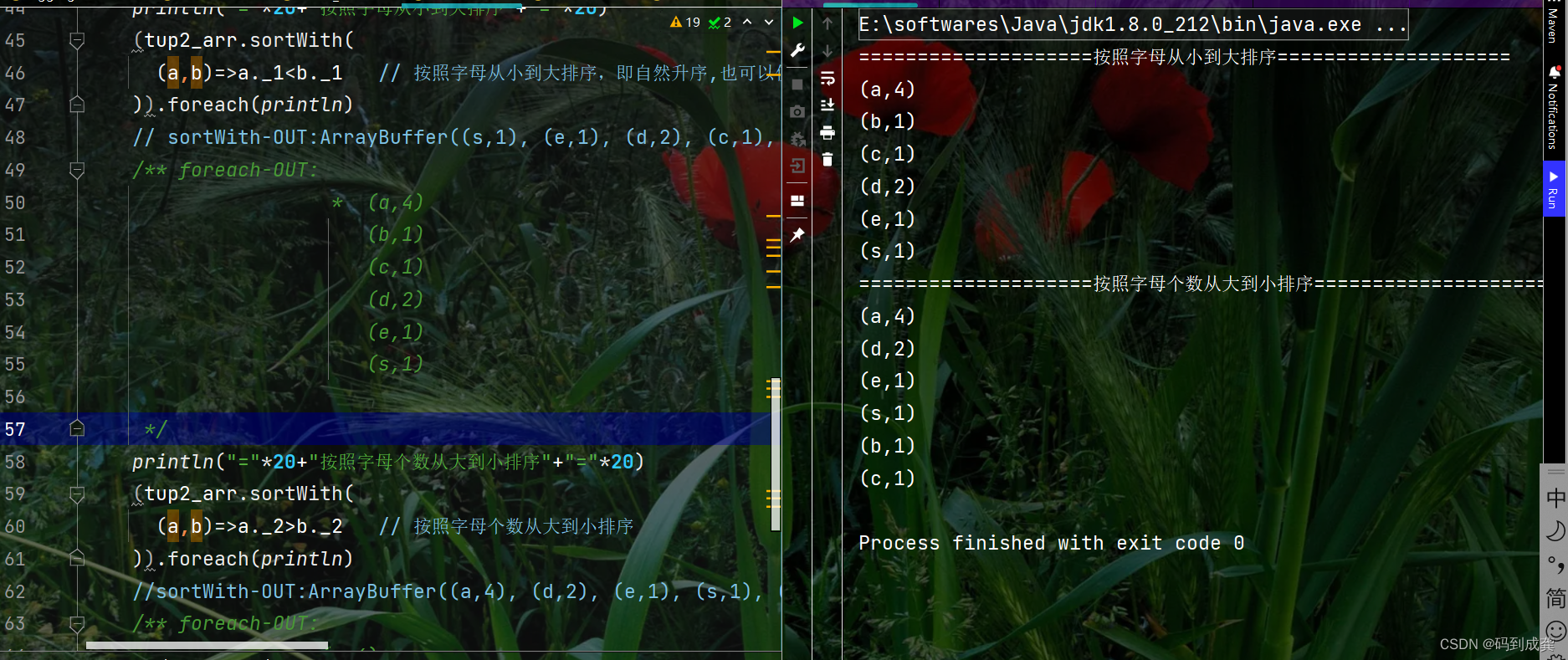
====================按照字母从小到大排序====================
(a,4)
(b,1)
(c,1)
(d,2)
(e,1)
(s,1)
====================按照字母个数从大到小排序====================
(a,4)
(d,2)
(e,1)
(s,1)
(b,1)
(c,1)
import scala.collection.mutable.{ArrayBuffer, ListBuffer}/*** @author:码到成龚* my motoo:"听闻少年二字,应与平庸相斥。"* 个人代码规范:* 1,原始数据的变量命名:①只使用单个单词即数据的类型:无嵌套的数据结构②被嵌套的数据结构类型_嵌套的数据结构类型:嵌套的数据结构* 2,接收结果的变量命名:①包含的数据类型1_包含的数据类型2_返回的变量类型_表达式中使用到的函数1_表达式中使用到的函数2* 3,调用函数时的注释:①数据调用第一个函数输出的结果为:函数名-OUT①;函数名-OUT②....以此类推**/
object Test2 {def main(args: Array[String]): Unit = {/*** 实现 wordcountList("a b a a c d", "a d e s")实现统计单词的个数1 按照单词自然顺序升序2 按照单词个数从大到小排序
OUT===>*/val string_list=List("a b a a c d", "a d e s").flatMap(f=>f.split(" ")) // flatmap直接将集合序列压平// 上面传入的参数f代表每一个字符串,使用split切割得到的为Array数组var tup2_arr=ArrayBuffer[(String,Int)]() // 可变数组val list_map_gb_mp_gb_mv=string_list.map(key=>(key,1)).groupBy(tup=>tup._1).mapValues(key=>key.size) /**map-OUT①:List((a,1), (b,1), (a,1), (a,1), (c,1), (d,1), (a,1), (d,1), (e,1), (s,1))groupBy-OUT②:Map(e -> List((e,1)), s -> List((s,1)), a -> List((a,1), (a,1), (a,1), (a,1)), b -> List((b,1)), c -> List((c,1)), d -> List((d,1), (d,1)))mapValues-OUT③:Map(e -> 1, s -> 1, a -> 4, b -> 1, c -> 1, d -> 2)*/for(i <- list_map_gb_mp_gb_mv.keys){tup2_arr.append((i,list_map_gb_mp_gb_mv(i)))}// array-OUT:ArrayBuffer((e,1), (s,1), (a,4), (b,1), (c,1), (d,2))println("="*20+"按照字母从小到大排序"+"="*20)(tup2_arr.sortWith((a,b)=>a._1<b._1 // 按照字母从小到大排序,即自然升序,也可以使用sorted函数)).foreach(println)// sortWith-OUT:ArrayBuffer((s,1), (e,1), (d,2), (c,1), (b,1), (a,4))/** foreach-OUT:* (a,4)(b,1)(c,1)(d,2)(e,1)(s,1)*/println("="*20+"按照字母个数从大到小排序"+"="*20)(tup2_arr.sortWith((a,b)=>a._2>b._2 // 按照字母个数从大到小排序)).foreach(println)//sortWith-OUT:ArrayBuffer((a,4), (d,2), (e,1), (s,1), (b,1), (c,1))/** foreach-OUT:* (a,4)(d,2)(e,1)(s,1)(b,1)(c,1)*/}
}
如果对以上的代码有任何问题的,请在评论区留言。
如果觉得代码有更优的解,也欢迎在评论区展示您的代码。
有兴趣可以继续阅读:Scala集合习题Ⅱ_码到成龚的博客-CSDN博客

![[附源码]Python计算机毕业设计Django二手书店设计论文](https://img-blog.csdnimg.cn/39c2e3a490b14be0b82e16b6e788c56c.png)

![[附源码]计算机毕业设计JAVA校园飞毛腿系统](https://img-blog.csdnimg.cn/47173add29db4886bc31516ee0944517.png)