记一次系统重构设计
- 背景介绍
- 设计步骤
- 架构图介绍
- 架构设计注意点
- 总结
背景介绍
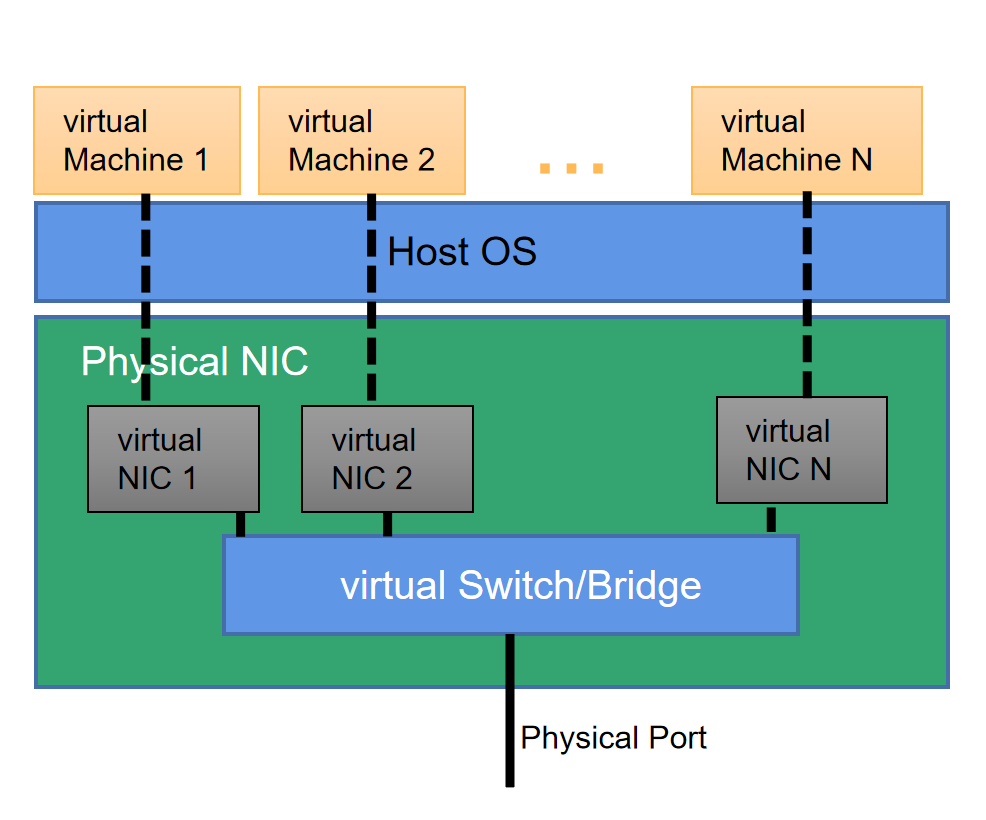
搜索链路主要部分

搜索引擎链路都包含这三部分,数据源、搜索引擎服务、搜索业务。
是不是很简单,感觉搜索也没那么难?
搜索链路确实都包括这三部分,但没我说的那么简单,每两个部分之间链路很长,业务非常复杂,举例说下数据源到搜索引擎服务的链路。
首先数据源不是单一数据源、比如说个电商场景的数据源,主要有商家商品数据、用户数据、爬虫数据等多种数据源。
我这次要做的链路是从数据源到搜索引擎服务这一段,简单点就是数据源提供的数据,需要结构化之后入到搜索引擎,这样搜索引擎才能提供搜索服务。
可这数据源真的是五花八门,提供数据的方式也是五花八门的。
设计步骤
背景基本就介绍到这里了,接下来就说说设计一个系统的步骤,说实话,毕竟是第一次做系统设计,当时真的是无从下手,不过帅气的米豆有法宝啊,多请教,多思考,多查资料。
在方案评审之前我已经做了很多方案设计图,这部分的努力主要是为了通过方案评审,这非常重要,通不过评审,老板不会让你做,就没有资源可以用,这项目就搁浅了。
主要发力点:
旧系统摸底:找出旧系统的所有不支持当前业务场景的点,有哪些是对当前业务影响较大的,哪些是对未来业务影响较大的,这些都要细细整理出来。不过这块我做起来还算轻松,旧系统在设计架构上就被我找到很多问题。
可能真的是由于历史原因吧,以前搜索是一个BU,现在只是大数据里的一个组了,这中间经历了多少改朝换代啊,历史包袱重的无法背负了,只能选择抛弃他了。

从上面的架构图可以很清晰的看出来这个系统有三个严重问题:
第一个:
业务层数据到达队列完全依赖于业务方上报。这本来是件无可厚非的事,你要用搜索引擎,那就得上报数据来。就好比你用数据库,你总得把数据存进去吧。
但这事在公司行不通,历史包袱太沉重。业务方完全不想上报数据,虽然勉强上报,经常增量数据丢失。这一丢失数据导致搜索出不来。最终…
总结下,就是业务方不想上报数据、上报数据总是丢失,锅还得搜索来背。
第二个:
数据处理完成直接交付给数据应用,这个问题蛮严重的。数据处理其实意味着会消耗大量的计算资源和时间,而一旦数据应用层服务挂掉或者崩溃,将会导致服务短时间无法恢复。
比如1000w的数据处理需要一个24core机器处理12小时,一旦下游的solr或者RS集群崩溃,把一份全量数据恢复回来,需要数据处理系统重新计算12小时,这恢复时间谁顶的住啊?
由于第一个问题存在,也就是数据上报容易丢失,所以必须依靠全量数据来恢复丢失的增量,我们的近200个业务基本每天都会做一次全量,这可是大把的计算资源浪费啊。
资源浪费一点倒也还好,但是这异常情况下的数据恢复时间确实是个大问题,用户可等不及这么长时间啊。
总结下,就是计算资源浪费,数据应用层服务无法做到无状态,恢复成本高昂。
第三个:
数据处理系统耦合度太高,系统太复杂,维护困难。数据处理一般包括数据清洗和业务组装,数据清洗可以算作是业务变化较少的,但是业务组装规则是灵活多变的,这部分经常会由于业务方的变动而产生开发的需求。
业务变动频繁、业务繁多导致系统变得复杂,系统复杂耦合度还很高,导致这个系统维护和开发成本很大,日常需求开发已经成为难题了。
业务场景调查。搜索有很多场景,比如电商场景,内容场景,直播场景。场景很多,公司业务形态上也是都有这些,但不是所有的场景都使用了我们的搜索服务。
要去摸底一下那些没有使用的为啥没用,没用肯定是我们做的不好,摸底的主要目标的就是搞清楚到底哪点不好。深入到业务上去了解,才能更好的设计系统。
新系统设计:前两步骤已经找到了旧系统缺陷和业务问题,新的系统首先要解决之前的问题,其次就是做一些前瞻性的设计。
新系统设计这块包括以下几个步骤:
业务梳理 :这块其实在旧系统摸底和业务调查的时候已经做的差不多了,只需要在精细化的梳理下。
业务抽象 :业务抽象指的是一系列的业务问题,抽象为一种通用的解决方案。这块蛮复杂的,在这块需要花费大量时间。
技术调研 :每一种技术都有他的适用场景。举个例子,使用搜索引擎,到底是用solr还是用es、还是自研呢?这就需要你对技术方案有了解,知道这些技术方案的优缺点,最终才能找出适合业务发展的技术方案。
方案探讨: 好的设计不是一蹴而就的,也不是某个人的智慧象征。好的设计是一群人智慧的结晶,是一个不断迭代的产品,所以需要多讨论。
方案确定 :前面的问题解决了,基本方案差不多也该定下来了。为保证方案不会出现返工情况,你需要再拉上leader开个最终的项目方案评审会加上确定项目排期。
架构图介绍
说了那么多好像还没说到我的设计到底在哪里,接下里就来说说我的设计。
在整个设计中我也做了好几版的设计图,草稿就不放出来了,直接放最终的一版设计方案来说,中间解释的时候会说那些演进的点。
首先我设计这个系统目标有如下:
- 零上报 指的是数据不依赖业务方上报,有数据变更立刻感知到
- 准实时 数据变更之后实时进入引擎,提供搜索服务
- 高吞吐
- 高容错
- 低耦合
- 易维护
这几个目标已经完全解决了之前系统存在的问题,比如上报数据问题,资源浪费问题,紧急恢复时间长的问题。

整体上我采用了分层设计方案结合微服务的思想,把复杂的问题分层抽象,各层次之间功能单一且分明,耦合度低,维护方便。
当然这样的设计会导致数据链路变得略长,会有多余的网络传输延时。现在的网卡已经够大了,网络传输在这个项目中不是不足为虑。
自上而下,沿着数据流动的方向,逐层解释下为何这么设计:
第一层:
业务数据层:这是不变的,一致存在的。目前我们共有快200个业务场景,每个业务方的数据源是不同的,同时也有交叉的,比如商品数据在类目搜索、内容搜索、订单搜索、商品推荐上都使用,他们确是不同的业务场景,数据有交叉也有不同。
但其实这里我们不必太关心业务方的数据来源,不管是何种来源最终都会有一个存储介质,只需要关心数据实际存储在哪里的。
把多种存储介质抽象出来,用一个服务去监听这些介质的数据变更行为,这就是接下来的数据监听层。
第二层:
数据监听层:主要负责监听变更的业务数据,把变更的数据获取到,用规定的格式输出到下游队列即可。
第三层:
数据缓冲层:数据缓冲一般用在系统与系统之间,通常情况下不要让系统与系统之间直接传递数据,这样的数据传递会有很高的风险,得依赖接收端系统的稳定性。
有了数据缓冲,系统之间就不直接交互数据了,系统之间没什么依赖关系,也不会互相影响。
第四层:
数据处理层:这一层最终需要把零散的、不规则的数据处理为一个搜索可用的DOC数据。这块任务蛮艰巨的,当时在讨论这一层的时候,花费了很多时间。
数据处理包括两部分,一部分是一些通用型处理,比如去html标签、数据格式int转string等等处理逻辑;
另一部分是一些变化较多的业务部分,比如一个doc有十五个字段,其中有三个来自A业务,三个来自B业务,而这些来自都是需要实时去业务方拿结果的。
再比如对DOC中的字段会进行一些计算操作,具体计算规则根据业务而定的。
这些操作都很依赖于业务方,变化之多,很难把控。所以这块在设计上需要很灵活。
根据抽取出的这两部分特性,把不变的通用性较强的那部分定义为数据清理,用一个单独服务处理,这里采用spark stream流去实时做数据清洗,处理完成之后输出到kafka队列。
灵活变化的部分用一个单独服务处理,业务变更采用脚本方式动态发布,修改灵活、即时生效。
第五层:
数据存储层。故名思义就是做一个存储,前面已经计算好了一个完整的DOC数据。整个计算过程已经耗费了计算资源和时间,所以必须存储起来。一旦数据应用层服务数据异常,可以很及时用这里的数据做恢复。
不需要计算,直接拿过去用,恢复起来成本够低了吧。
有了存储层,既可以保证下游服务可以完全无状态,还可以保证快速恢复,同时还可以用作全量数据。
一边写到存储层,也会一边写到kafka队列,数据应用层需要获取kakka队列数据做增量索引。
整个分层的设计架构就是这样了,中间的业务细节就不一一讲解了。
懂搜索的朋友肯定会说了,这里的整个系统说的都是增量,那全量怎么更新。
这就到点上了,全量我采用了主动触发的方式,可以想一想那些场景需要做一次全量。
- 业务发生了字段级别的变更,比如增加了一个字段,或者某个字段的全部值发生了变化。
- 第一次接进来的业务,但已经有很大一部分原始数据。
- 有大批增量丢失,导致无法通过容错机制恢复,而且不是很确定丢失那些增量。
- 存储层有脏数据。
- 数据应用层有脏数据或者异常了。
两种方式做全量,一种是需要计算的,通过增量链路计算做一份全量。另一种是直接通过hbase全量数据来做全量。
hbase有脏数据的情况下只能重新计算,或者清理脏数据。
架构设计注意点
整体的系统架构主要由我完成,系统开发那可是集结了全组的功力。总共用时一个Q出了第一版,目前线上已经跑了好几个业务,最高qps能达到100k,截了一个线上运行的7天业务指标图。

说下一些注意点,希望对大家有用。
设计前
- 对业务一定要非常熟悉,这样设计出的系统才能更好的服务业务
- 多做技术方案调查,只有见的多了你才会思考的多了,思考的多了才会有所见解
- 多沟通,很多问题自己一个人想着可能很完美,但很可能这时你钻到思维的牛角尖了,沟通能减少这样的错误
设计中
- 多画架构图,画出来便于你更多的思考,图画更具有渲染和说服力,图片的表达能力比文字强
- 细节地方一定要画流程图,流程图画得好写代码才能轻松
- 多做项目评审会,项目评审就是一个产品迭代,只是还没做出产品就已经有迭代了
- 更多的倾听业务,系统设计是为了解决业务问题,是为业务服务的。你的系统可以不是完美的,但对于业务和用户一定是价值最大的
开发中
- 线上系统异常处理要完善
- 测试要完善,功能测试、性能测试都得做
- 系统监控一定要完善,这个非常重要,没有监控和日志,出了问题就是两眼一抹黑
- 项目排期一定要做好,一般项目开发都是多人协同开发,不能影响整体排期
- 有风险及时暴露,这点很重要,很多人在项目中遇到问题或者风险点不敢暴露出来,害怕暴漏出来大家怀疑自己的能力,老板会给低绩效等。想着自己能很快解决,一般遇到风险都很难自己独自解决,不然也不会构成风险。暴露出来,大家群策群力,也不会拖延到项目排期。
上线后
- 及时关注自己的服务监控指标,一般上线前都会经过测试、压测等,很多人就上线关注一会觉得没问题,就去庆功去了,别把庆功酒喝错了味道。业务是实时变化的,你要根据业务变化确定你的观察时机,正确观察几个周期无误后,才可以确定无误,以防年终奖没了。敏感业务都必须灰度很长时间做观测。
- 听取反馈意见,收集反馈意见及时迭代自己的产品。
- 挖掘潜在业务需求,提前布局迭代。
总结
两个重要的点
- 想清楚在做,想清楚就是指前期需要花费大量的时间去做系统架构调研、讨论,细节构思清楚。我的这个系统设计花在调研、探讨、设计上的时间占据总时间的五分之二。构思和测试的时间是最长的,开发的时间是最短的。前期想的越清楚,开发难度越小。更有甚者,开发到中途发现设计不通,再开始返工。
- 小步快跑,试错迭代,借用Pony老师的总结。现在互联网公司的项目都是要求很快速上线的,所以在开发上我们需要快速出产品,然后再不断迭代。不能一开始就做一个完美产品,这样用户是等不住的。
事实上不存在一开始做出来就是完美的产品,只有手机大量用户意见,不断迭代、不断改进、不断创新的产品才有可能是好产品。