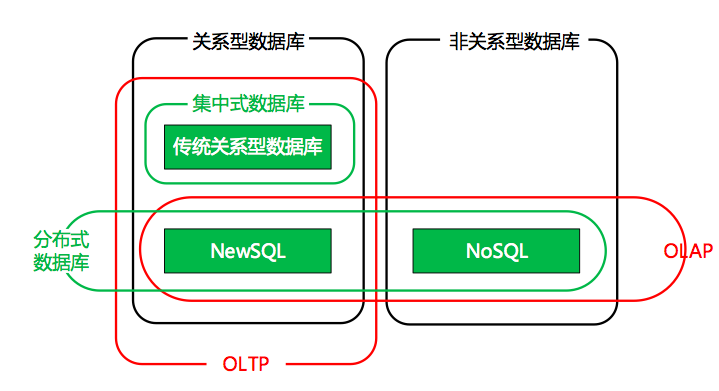
描述:
Python众所周知用来数据提取,通俗说用来抓数据,将拿到的数据进行数据清洗、加工,分析等等。而其中最重要的部分就是数据爬取、数据入库这两部分了,至于数据分析那就特别考察你的SQL能力,如果是自己设计页面,对于你本人的设计页面,思维,美观等等方面都有很多的提升窝
通过本章博文您可熟系运用Scrapy框架、获取数据、数据入库、以及开发过程中可能遇到的bug,处理bug的思路,还是那句话你不仅收获到解决问题的方式,也会收获到遇到问题的思路,然后一步步朝着思路至上,思路解决问题的大门走去!
全篇文章我想还是采用5个大标题,大标题下n个小标题,噗。
🏆一、项目简介
⭐️1.1、数据来源~
⭐️1.2、技术栈:
Python 3.8.5
MYSQL8.0
SQL Server2019
Oracle19C
XPath Helper1.0.13
⭐️1.3、工具使用:
Navicat15
IDEA2020
Google Chrome版本 107.0.5304.107
简介:
- 使用Scrapy框架获取读书网数据【技术开发书名,书图片】,将数据转储为json格式文件,进行初步数据核对校验
- 然后通过测试demo .py文件连接三大数据库,并运用到Scrapy框架中进行数据入库
- 三大数据库数据入库完毕,会再次通过SQL查询数据进行二次数据校验。
关于框架的基本思路这里先顺一下因为是博客文字描述问题,没有视频中那么直观,所以这边也是尽量尝试用文字将自己所学的知识进行一个清晰明了的输出;
⭐️1.4、scrapy工作原理 [这是一个面试题]
-
引擎像spiders要url
-
引擎将爬取的url给调度器
-
调度器会将url生成请求对象放到指定的队列中
-
从队列中出队一个请求
-
引擎将请求交给下载器进行处理
-
下载器发送请求获取互联网数据
-
下载器将数据返回给引擎
-
引擎将数据再次返回给到spiders
-
spiders通过xpath解析该数据,得到数据或者url
-
spiders将数据或url给到引擎
-
引擎判断该数据是url还是数据,是数据,交给管道(itempipeline) 处理,是url交给调度器处理

🏆二、项目实施
使用Scrapy框架首先需要先安装,这个之前也写过安装过程
Scrapy安装踩坑记录(全)_妙趣生花的博客-CSDN博客
那好,现在就直接进入正题
1.创建项目:scrapy startproject scrapy_readbook_101
2.跳转到spiders路径 cd scrapy_readbook_101\scrapy_readbook_101\spiders
3.创建爬虫类:scrapy genspider -t crawl read 计算机/网络 - 读书网|dushu.com
额,算了,我还是直接贴图吧,想要事无巨细的说明白整个代码,还真不是件小工程。

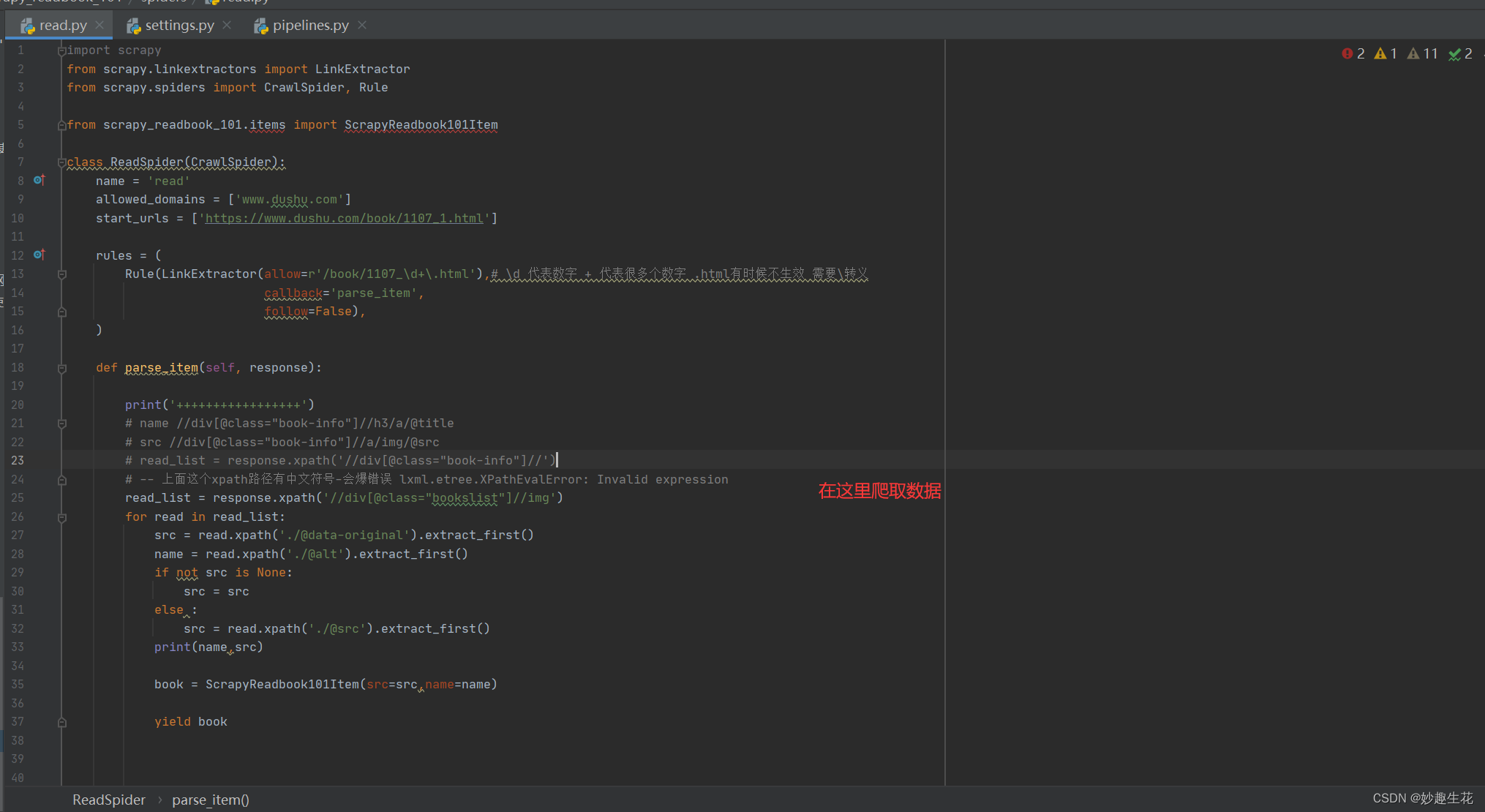
⭐️2.1、read.py
这段代码,自上而下的解释的话就是
allowed_domains = ['www.dushu.com'] #域名
start_urls = ['https://www.dushu.com/book/1107_1.html']# 目标网址
Rule(LinkExtractor(allow=r'/book/1107_\d+\.html'), # \d 代表数字 + 代表很多个数字 .html有时候不生效 需要\转义
follow=False # 这个目前不太清楚
# 注释部分的代码是我自己踩过的坑,放出来,也是提醒自己以后注意
# name //div[@class="book-info"]//h3/a/@title
# src //div[@class="book-info"]//a/img/@src
# read_list = response.xpath('//div[@class="book-info"]//')
# -- 上面这个xpath路径有中文符号-会爆错误 lxml.etree.XPathEvalError: Invalid expression
read_list = response.xpath('//div[@class="bookslist"]//img') # 将响应数据通过xpath语法进行解析,这只是第一层的解析,如果需要获取到图书名称和图书图片需要在这个xpath解析的基础上在进行xpath解析,在python中这种xpath套娃的形式是允许的,而且开发中经常使用这种方式
for read in read_list: # 然后就是遍历
src = read.xpath('./@data-original').extract_first() # 套娃获取图书名称 .extract_first()是将返回的selector列表数据进行提取
name = read.xpath('./@alt').extract_first() # 同理
# 这个地方是做一个流程语句的判断 因为在源码数据中 图片的src链接处是有一个懒加载,怎么理解,就是#在源码中图书图片的链接的属性正常是src,但是如果有data-original属性的话,那就是图片进行懒加载 #处理了,我们xpath路径中@src是获取不到除了第一张图片的其他任何图片,所以这种第一张图片是src, #其他图片是data-original属性的情况,需要if-else单独判断,这段代码的意思就是,如果src属性获取 #不为空那就还是获取原来的src【src = read.xpath('./@data-original').extract_first() 】如果 #为空那就重新设置一个src即【src = read.xpath('./@src').extract_first()】if not src is None: src = src else:src = read.xpath('./@src').extract_first()
print(name, src) # 然后将获取的数据输出出来进行查看,查看是否有异常数据,即None,方便调试
运行Scrapy框架代码命令:scrapy crawl read
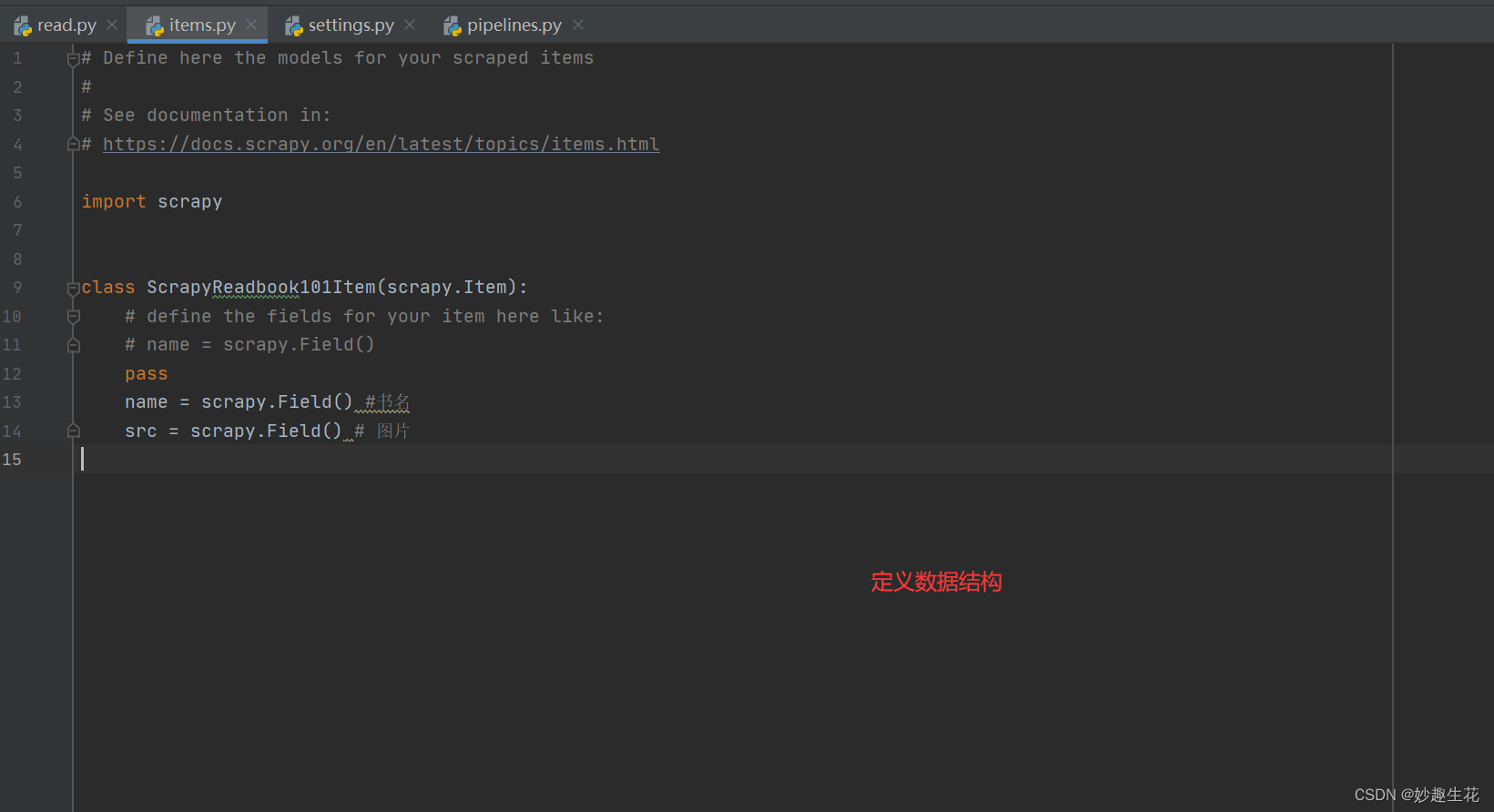
如果运行无问题,这个时候就应该去items.py文件定义数据结构了,因为前面已经获取到图书名称name和图书图片src这两个值,参考2.2、items.py
然后将值放到数据结构中,返回一个对象,这个时候该行代码会爆红,报错。是需要引入数据结构文件才可以。格式为项目名.items import 类名
from scrapy_readbook_101.items import ScrapyReadbook101Item
在将对象返回给管道,对象返回给管道的关键字是yield即
yield book
返回管道之后有两步:
1、开启管道 详细请参考图2-1-1
2、配置管道 详细请参考pipelines.py文件

然后scrapy crawl read 命令执行框架代码,这个时候我们的read.json文件就自动生成了
然后这个时候就可以进行二阶段升级了——数据入库
首先需要配置settings.py文件如图2-1-2
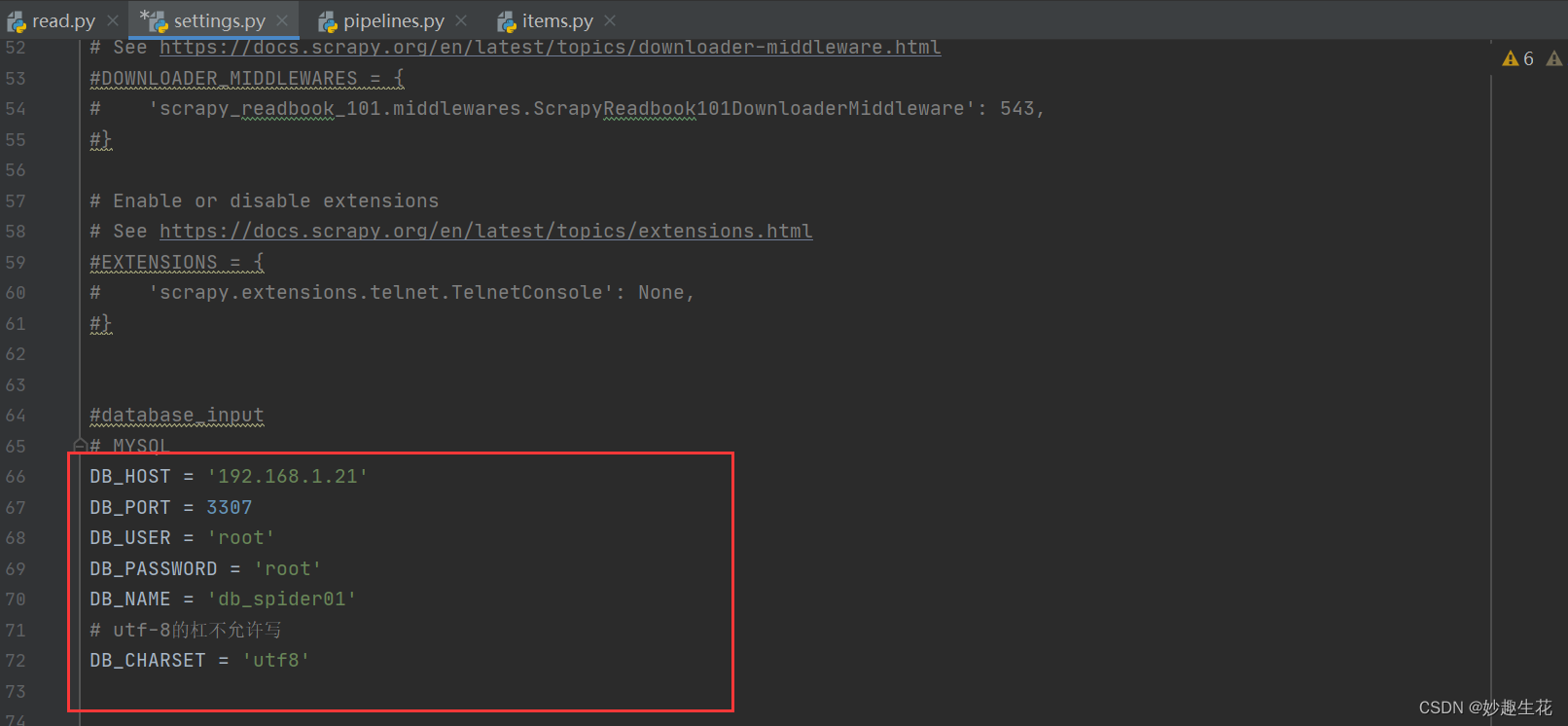
配置好以后,来到管道文件pipelines.py
自定义MysqlPipeline管道,然后记得settints文件中开启该管道,级别为301
管道类中有三个方法分别是:
open_spider # 爬虫文件开启时
connect # 连接数据库
process_item # 数据入库
close_spider # 爬虫文件结束时
然后执行代码scrapy crawl read
即可看到数据入库了,截止到MySQL数据入库成功之后,后面才去摸索SQL SERVER、ORACLE的数据入库,因为日常项目用的最多的就是后面这两个数据库了。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rulefrom scrapy_readbook_101.items import ScrapyReadbook101Itemclass ReadSpider(CrawlSpider):name = 'read'allowed_domains = ['www.dushu.com']start_urls = ['https://www.dushu.com/book/1107_1.html']rules = (Rule(LinkExtractor(allow=r'/book/1107_\d+\.html'), # \d 代表数字 + 代表很多个数字 .html有时候不生效 需要\转义callback='parse_item',follow=False),)def parse_item(self, response):print('+++++++++++++++++')# name //div[@class="book-info"]//h3/a/@title# src //div[@class="book-info"]//a/img/@src# read_list = response.xpath('//div[@class="book-info"]//')# -- 上面这个xpath路径有中文符号-会爆错误 lxml.etree.XPathEvalError: Invalid expressionread_list = response.xpath('//div[@class="bookslist"]//img')for read in read_list:src = read.xpath('./@data-original').extract_first()name = read.xpath('./@alt').extract_first()if not src is None:src = srcelse:src = read.xpath('./@src').extract_first()print(name, src)book = ScrapyReadbook101Item(src=src, name=name)# print(len(book))yield book
⭐️2.2、items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapyReadbook101Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()passname = scrapy.Field() #书名src = scrapy.Field() # 图片
⭐️2.3、pipelines.py
ps:一阶段代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook101Pipeline:def open_spider(self, spider):self.fp = open('read.json', 'w', encoding='UTF-8')def process_item(self, item, spider):self.fp.write(str(item)) # TypeError: write() argument must be str, not ScrapyReadbook101Itemreturn itemdef close_spider(self, spider):self.fp.closedef close_spider(self, spider):self.cursor.close()self.conn.close()
ps:二阶段代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook101Pipeline:def open_spider(self, spider):self.fp = open('read.json', 'w', encoding='UTF-8')def process_item(self, item, spider):self.fp.write(str(item)) # TypeError: write() argument must be str, not ScrapyReadbook101Itemreturn itemdef close_spider(self, spider):self.fp.close# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql # mysql 驱动# import pymssql # SQL server 驱动class MysqlPipeline():def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,database=self.name,charset=self.charset# autocommit=True)# if self.conn:# print("连接成功!")# return self.connself.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into books (name,src) values("{}","{}")'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
⭐️2.4、pipelines.py
# MYSQL参数配置
需要先pip安装
pip install pymysql -i https://pypi.douban.com/simple
#database_input # MYSQL # DB_HOST = '192.168.1.21' # DB_PORT = 3307 # DB_USER = 'root' # DB_PASSWORD = '*******' # DB_NAME = 'db_spider01' # # utf-8的杠不允许写 # DB_CHARSET = 'utf8'
# SQL SERVER参数配置
pip安装
pip install pymssql -i https://pypi.douban.com/simple
# SQL SERVER DB_HOST = '192.168.1.21' DB_PORT = 1433 DB_USER = 'sa' DB_PASSWORD = '*********' DB_NAME = 'DB_ETL_DW' # utf-8的杠不允许写 DB_CHARSET = 'utf8'
字符集必须指定,不然数据入库会是这个样子的
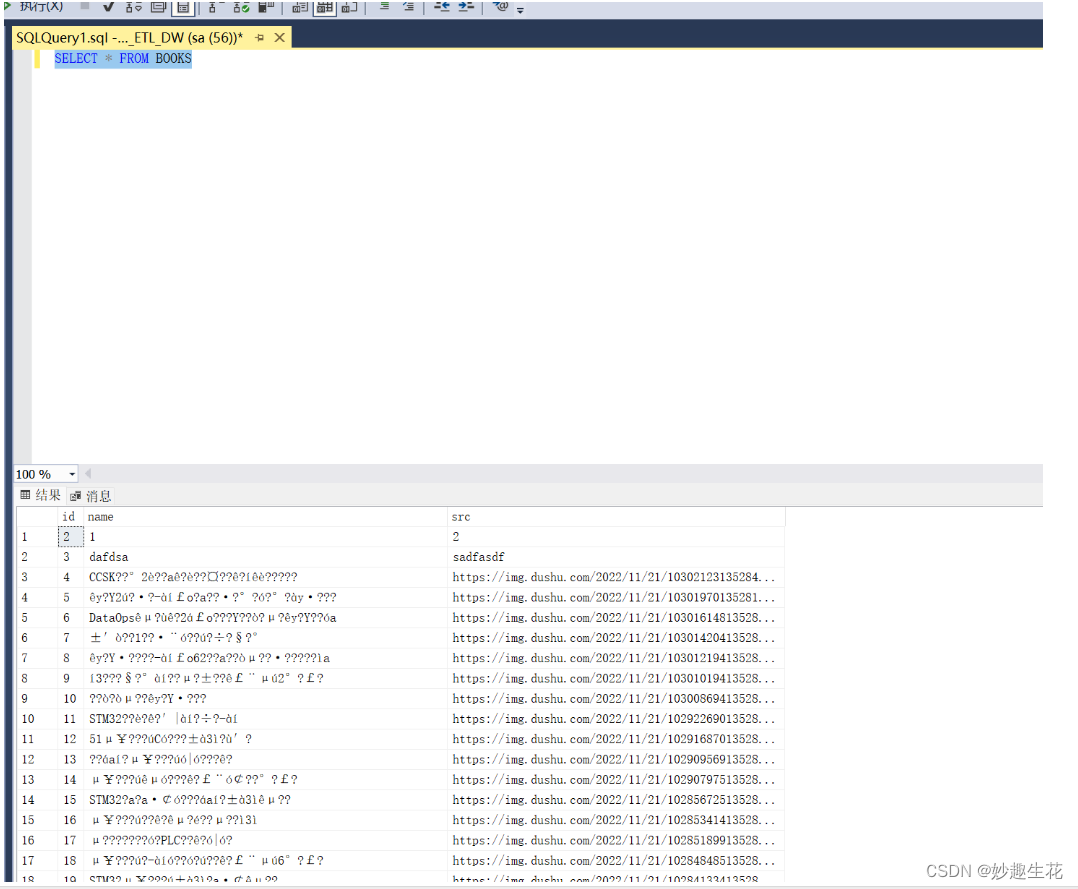
# ORACLE参数配置
pip安装
E:\Python\workload\Scripts>pip install cx_Oracle -i https://pypi.douban.com/simple
# ORACLE的参数不配置在这里,经测试需要配置在pipelines.py管道文件中
如下图2-4-1

🏆三、数据库准备
⭐️3.1、MYSQL
主键设置自增
create table books(
id int primary key auto_increment,
name varchar(128),
src varchar(128)
)
⭐️3.2、SQL SERVER
主键设置自增
create table books(
id int identity(1,1) not null,
name varchar(128) not null,
src varchar(128) not null
)
⭐️3.3、ORACLE
这是没有创建序列时候的报错日志
oracle创建数据库主键id自增这个自己是创建了序列,但是后面测试数据的时候,感觉序列有点太友好,因为每次测试完数据,序列的值是不断往上叠加的,想要重新开始计算,每次要删除序列,创建测试这样,然后索性,就不要序列了,后面改用
使用序列测试后未删除序列只是truncate table后暴露的问题
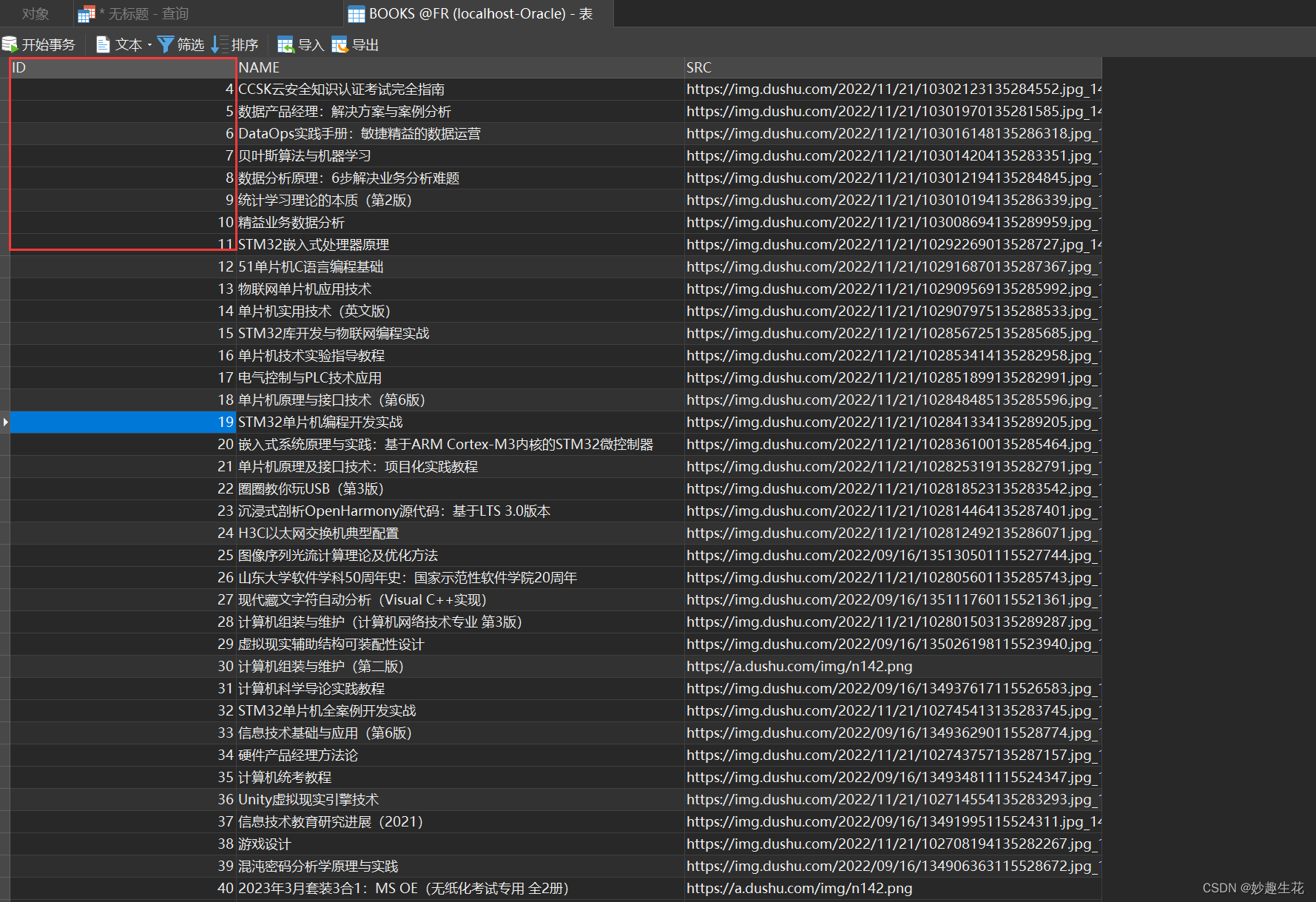
select ROW_NUMBER() over(order by src ),name,src from books 这种方式去显示序号
--设 置自增序列,名称为"seq_userinfo",名字任意命名
create sequence seq_userinfo
increment by 1 --每次+1
start with 1 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
--创建userinfo表
CREATE TABLE BOOKS (
id number(11) DEFAULT seq_userinfo.nextval, --"seq_userinfo"为自增序列名称
name varchar2(200) ,
SRC varchar2(200)
);--删除自增序列,"seq_userinfo"为自增序列的名称
drop sequence seq_userinfo
--删除触发器,"userinfo_TRIGGER"为触发器名称
drop trigger userinfo_TRIGGERselect ROW_NUMBER() over(order by src ),name,src from books
🏆四、BUG解决
先来看代码


错误日志如下,情景这是测试MYSQL数据入库通过后,替换参数SQL SERVER 出现的一个错误
大概意思就是检查出来有语法错误
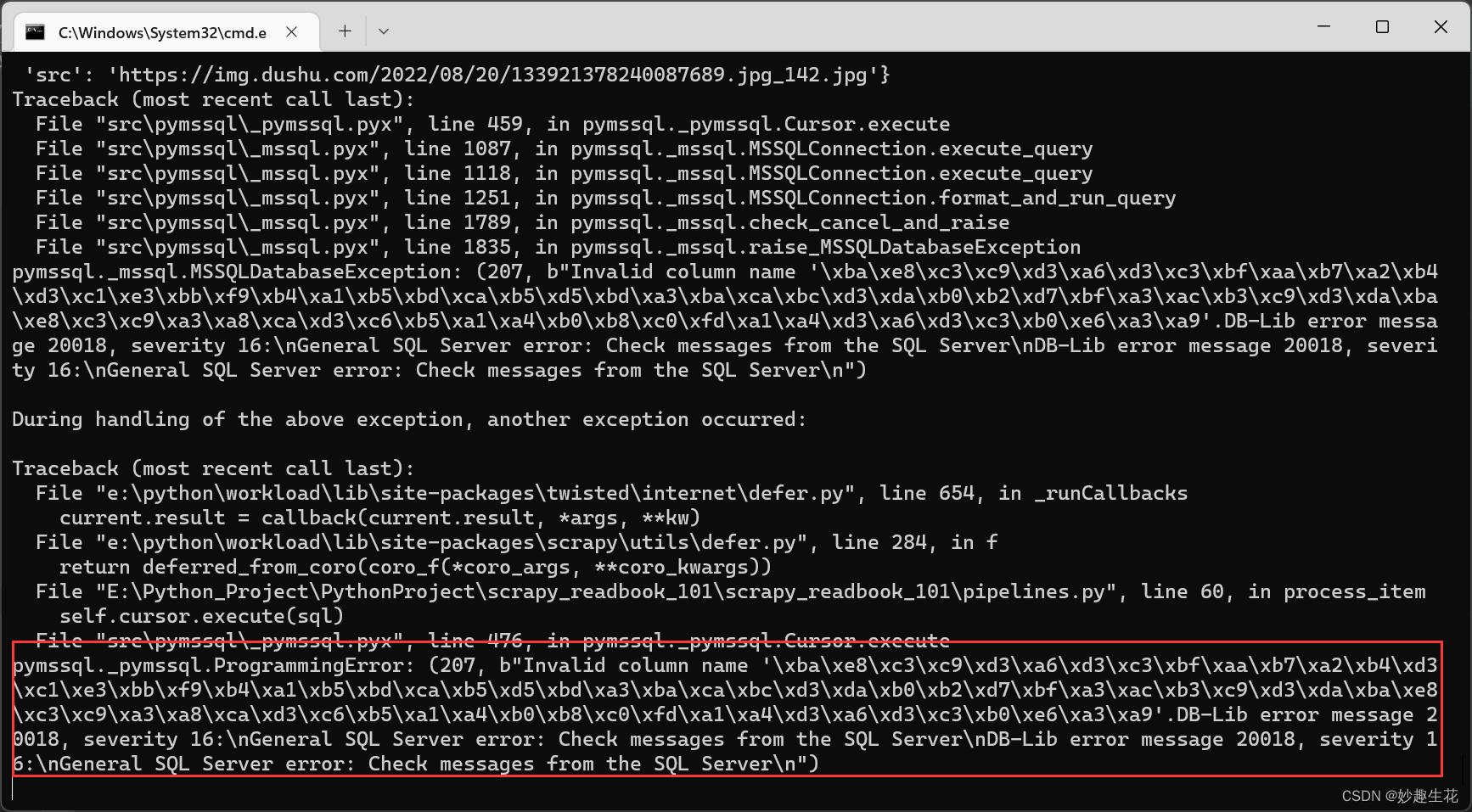
然后当时自己的解决思路第一时间是复制错误日志拿到百度上对照,部分博主说是因为insert语句的列名拼写错误和数据库中列名不一致导致的,但是自己明显不是这个问题,怎么整呢,用demo文件测试吧,先看下自己的数据库连接是否正常、再看下数据库连接成功后自己的insert语句是否插入成功,刚开始还怀疑自己的item['name'] 这个元组的取值取出来的数据有问题,好了看下测试demo吧。
⭐️4.1、元组测试
a = {'name': 'Java Web应用开发','src': 'https://img.dushu.com/2022/09/16/111346896115523468.jpg_142.jpg'}
print(a['name'])
print(a['src'])
⭐️4.2、MYSQL测试
import pymysqlconn = pymysql.connect(host="192.168.1.21",port=3307,user="root",password="123235423",database="db_spider01",charset="utf8")
cursor = conn.cursor()
sql = "SELECT * from books;"
cursor.execute(sql)
# ret = cursor.fetchone()
results = cursor.fetchall() #获取所有记录列表
print(results)
''' 错误代码
for result in results :result = list(results ) #元组转化为列表for res in range(len(result )):if isinstance(result[res],str):result[res] = result[res].replace(' ','')# 解决空格问题result = tuple(result)print('处理后: ',end="")print(result)
'''cursor.close()
conn.close()#https://blog.csdn.net/qysh123/article/details/112183676⭐️4.3、MYSQL远程授权
pymysql.err.OperationalError: (1130, "wang' is not allowed to connect to this MySQL server") 不允许连接到MYSQL服务器

直接登录
mysql -hlocalhost -P3307 -uroot -proot1234
密码登录
mysql -h localhost -P 3307 -u root -p-h:host 主机名/IP地址
-P:port端口号
-u:user 用户名
-p:password密码使用pycharm调取本地mysql,没有任何问题,当连接ecs上的mysql,将数据库连接中的 localhost 换成 ip 地址后,报错:
1130-host ... is not allowed to connect to this MySql server
这个问题是因为在数据库服务器中的mysql数据库中的user的表中没有权限(也可以说没有用户),下面将记录我遇到问题的过程及解决的方法。
遇到这个问题首先到mysql所在的服务器上用连接进行处理
1、连接服务器: mysql -h localhost -P 3307 -u root -p 【我这里是MYSQL8.0端口号3307】
mysql -u root -p2、看当前所有数据库:show databases;
3、进入mysql数据库:use mysql;
4、查看mysql数据库中所有的表:show tables;
5、查看user表中的数据:select Host, User from user;
6、修改user表中的Host:update user set Host='%' where User='root';
7、最后刷新一下:flush privileges;
注意,第7步必须执行,否则不能pycharm连接依然会报错(pymysql.err.OperationalError)

⭐️4.4、SQL SERVER测试
尤其是这个地方,当时卡了有段时间吧,后面到这里测试insert语句有问题,才想到用转义符的
import pymssqlconn = pymssql.connect(host="localhost", port=1433, user="sa", password="*********", database="DB_ETL_DW", charset="utf8")
if conn:print('连接数据库成功!')
cursor = conn.cursor()
sql = 'insert into books (name,src) values(\'dafdsa\',\'sadfasdf\')'
cursor.execute(sql)
conn.commit()conn.close()⭐️4.5、ORACLE 测试
测试示例图

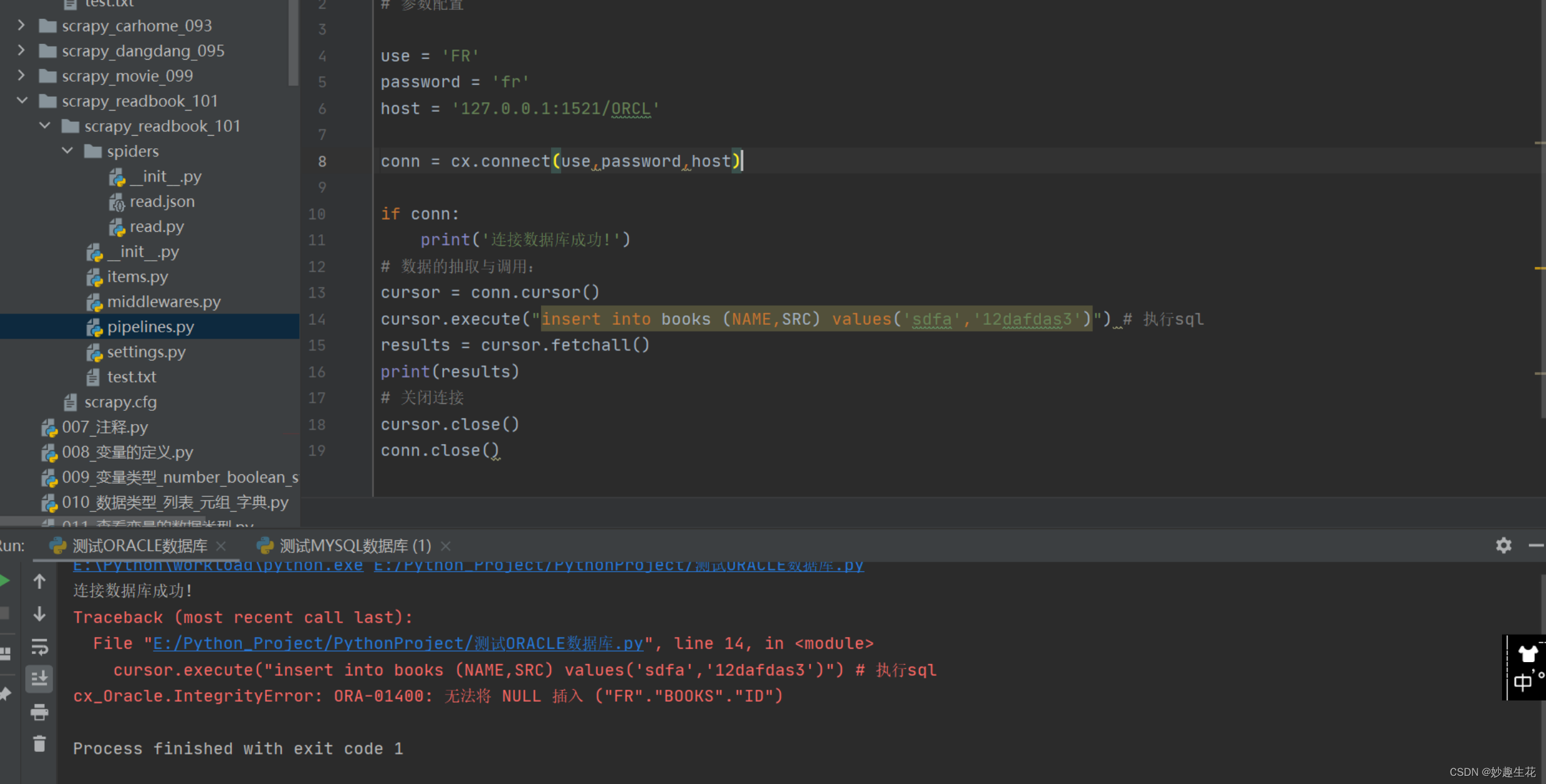
import cx_Oracle as cx
# 参数配置use = 'FR'
password = 'fr'
host = '127.0.0.1:1521/ORCL'conn = cx.connect(use,password,host)if conn:print('连接数据库成功!')
# 数据的抽取与调用:
cursor = conn.cursor()
cursor.execute("insert into books (NAME,SRC) values('sdfa','12dafdas3')") # 执行sql
# results = cursor.fetchall()
# print(results)
# 关闭连接
if cursor:print('数据插入成功!')
conn.commit()
cursor.close()
conn.close()⭐️4.6、其他bug

原因是因为settings中的参数配置有一个utf-8 不允许写-
pymssql._pymssql.OperationalError: (18456, b"\xe7\x94\xa8\xe6\x88\xb7 'sa' \xe7\x99\xbb\xe5\xbd\x95\xe5\xa4\xb1\xe8\xb4\xa5\xe3\x80\x82DB-Lib error message 20018, severity 14:\nGeneral SQL Server error: Check messages from the SQL Server\nDB-Lib error message 20002, severity 9:\nAdaptive Server connection failed (localhost)\nDB-Lib error message 20002, severity 9:\nAdaptive Server connection failed (localhost)\n")

原因是因为 有中文[] 这里是直接从数据库那边复制过来的 去掉就可以了

🏆五、项目总结
现在就好了
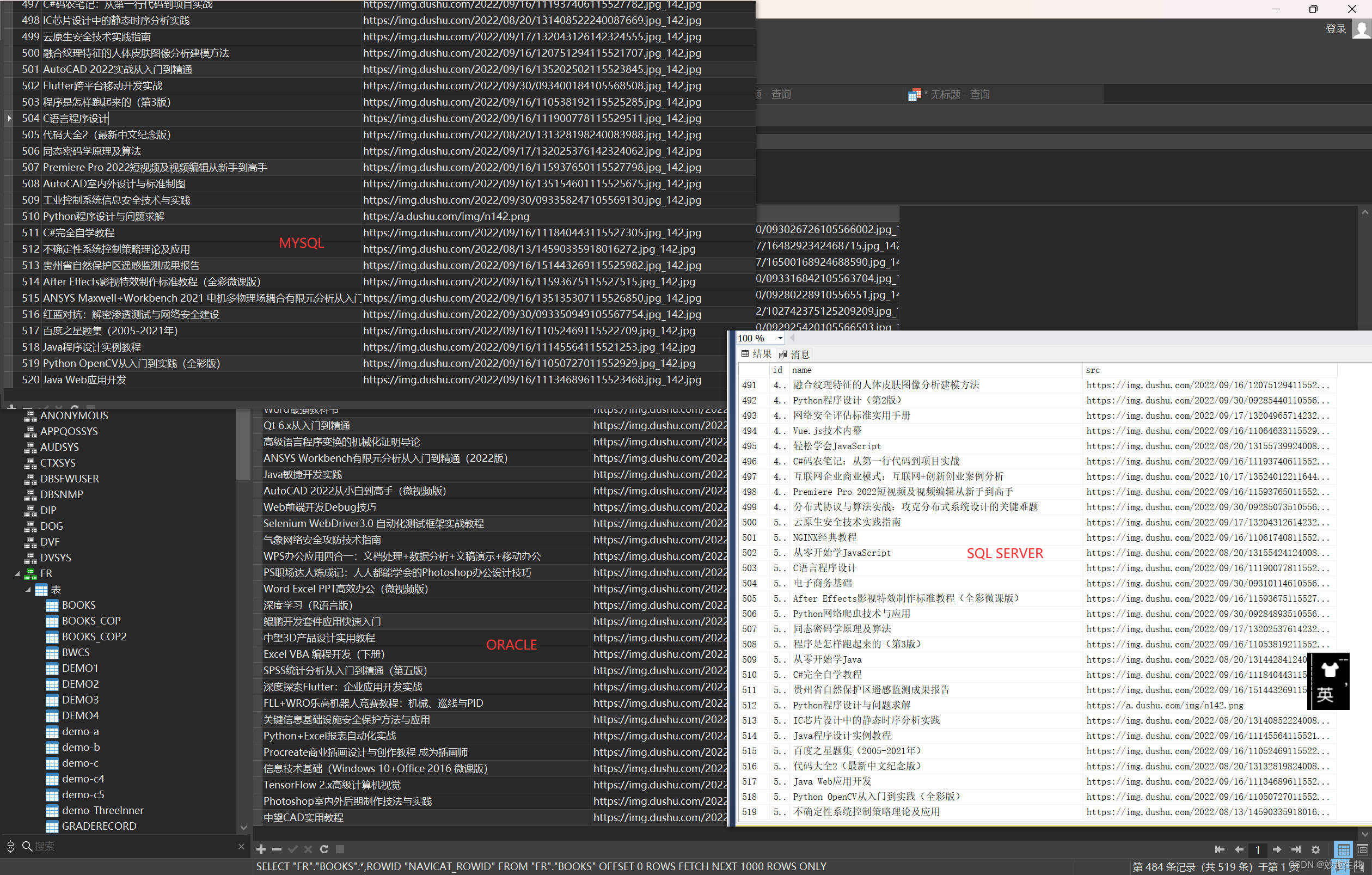
1、数据爬取
这里最重要的就是xpath语法要注意
还有反爬手段如header设置等等,只是这个网站没有做反爬手段而已
2、数据入库
三个数据库自己测试的MYSQL、SQL SERVER是在settings中配置参数
然后在pipelines.py文件中更改import驱动,还有insert语句,ORACLE是直接在
pipelines.py文件中配置的,没有用到settings,可能自己才疏学浅,理论上settings中能适用所有的数据库厂商驱动的。
然后最后再把pipelines.py文件单独贴一下
⭐️5.1、MYSQL
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook101Pipeline:def open_spider(self, spider):self.fp = open('read.json', 'w', encoding='UTF-8')def process_item(self, item, spider):self.fp.write(str(item)) # TypeError: write() argument must be str, not ScrapyReadbook101Itemreturn itemdef close_spider(self, spider):self.fp.close# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql # mysql 驱动# import pymssql # SQL server 驱动class MysqlPipeline():def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.password,database=self.name,charset=self.charset# autocommit=True)# if self.conn:# print("连接成功!")# return self.connself.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into books (name,src) values("{}","{}")'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
⭐️5.2、SQL SERVER
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook101Pipeline:def open_spider(self, spider):self.fp = open('read.json', 'w', encoding='UTF-8')def process_item(self, item, spider):self.fp.write(str(item)) # TypeError: write() argument must be str, not ScrapyReadbook101Itemreturn itemdef close_spider(self, spider):self.fp.close# 加载settings文件
from scrapy.utils.project import get_project_settingsimport pymssql # SQL server 驱动class MysqlPipeline():def open_spider(self, spider):settings = get_project_settings()self.host = settings['DB_HOST']self.port = settings['DB_PORT']self.user = settings['DB_USER']self.password = settings['DB_PASSWORD']self.name = settings['DB_NAME']self.charset = settings['DB_CHARSET']self.connect()def connect(self):self.conn = pymssql.connect(host=self.host,port=self.port,user=self.user,password=self.password,database=self.name,charset=self.charset# autocommit=True)self.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into books (name,src) values(\'{}\',\'{}\')'.format(item['name'], item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()
⭐️5.3、ORACLE
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass ScrapyReadbook101Pipeline:def open_spider(self, spider):self.fp = open('read.json', 'w', encoding='UTF-8')def process_item(self, item, spider):self.fp.write(str(item)) # TypeError: write() argument must be str, not ScrapyReadbook101Itemreturn itemdef close_spider(self, spider):self.fp.close# 加载settings文件
from scrapy.utils.project import get_project_settings
# import pymysql # mysql 驱动
# import pymssql # SQL server 驱动
import cx_Oracle as cx # oracle驱动class MysqlPipeline():def open_spider(self, spider):settings = get_project_settings()# self.host = settings['DB_HOST']# self.port = settings['DB_PORT']# self.user = settings['DB_USER']# self.password = settings['DB_PASSWORD']# self.name = settings['DB_NAME']# self.charset = settings['DB_CHARSET']self.use = 'FR'self.password = 'fr'self.host = '127.0.0.1:1521/ORCL'self.conn = cx.connect(self.use, self.password , self.host )# def connect(self):# self.conn = cx.connect(# # host=self.host,# # port=self.port,# # user=self.user,# # password=self.password,# # database=self.name,# # charset=self.charset# # autocommit=True# user=self.user,# password=self.password,# host=self.host,# charset=self.charset# )# if self.conn:# print("连接成功!")# return self.connself.cursor = self.conn.cursor()def process_item(self, item, spider):sql = 'insert into books (name,src) values(\'{}\',\'{}\')'.format(item['name'],item['src'])# 执行sql语句self.cursor.execute(sql)# 提交self.conn.commit()return itemdef close_spider(self, spider):self.cursor.close()self.conn.close()