1、有哪些深度神经网络模型?
目前经常使用的深度神经网络模型主要有卷积神经网络(CNN) 、递归神经网络(RNN)、深信度网络(DBN) 、深度自动编码器(AutoEncoder) 和生成对抗网络(GAN) 等。
递归神经网络实际.上包含了两种神经网络。一种是循环神经网络(Recurrent NeuralNetwork) ;另一种是结构递归神经网络(Recursive Neural Network),它使用相似的网络结构递归形成更加复杂的深度网络。RNN它们都可以处理有序列的问题,比如时间序列等且RNN有“记忆”能力,可以“模拟”数据间的依赖关系。卷积网络的精髓就是适合处理结构化数据。
关于深度神经网络模型的相关学习,推荐CDA数据师的相关课程,课程以项目调动学员数据挖掘实用能力的场景式教学为主,在讲师设计的业务场景下由讲师不断提出业务问题,再由学员循序渐进思考并操作解决问题的过程中,帮助学员掌握真正过硬的解决业务问题的数据挖掘能力。这种教学方式能够引发学员的独立思考及主观能动性,学员掌握的技能知识可以快速转化为自身能够灵活应用的技能,在面对不同场景时能够自由发挥。。
谷歌人工智能写作项目:小发猫

2、有哪些深度神经网络模型
目前经常使用的深度神经网络模型主要有卷积神经网络(CNN) 、递归神经网络(RNN)、深信度网络(DBN) 、深度自动编码器(AutoEncoder) 和生成对抗网络(GAN) 等神经网络输出模型结构。
递归神经网络实际.上包含了两种神经网络。一种是循环神经网络(Recurrent NeuralNetwork) ;另一种是结构递归神经网络(Recursive Neural Network),它使用相似的网络结构递归形成更加复杂的深度网络。RNN它们都可以处理有序列的问题,比如时间序列等且RNN有“记忆”能力,可以“模拟”数据间的依赖关系。卷积网络的精髓就是适合处理结构化数据。
关于深度神经网络模型的相关学习,推荐CDA数据师的相关课程,课程以项目调动学员数据挖掘实用能力的场景式教学为主,在讲师设计的业务场景下由讲师不断提出业务问题,再由学员循序渐进思考并操作解决问题的过程中,帮助学员掌握真正过硬的解决业务问题的数据挖掘能力。这种教学方式能够引发学员的独立思考及主观能动性,学员掌握的技能知识可以快速转化为自身能够灵活应用的技能,在面对不同场景时能够自由发挥。
3、神经网络BP模型
一、BP模型概述
误差逆传播(Error Back-Propagation)神经网络模型简称为BP(Back-Propagation)网络模型。
Pall Werbas博士于1974年在他的博士论文中提出了误差逆传播学习算法。完整提出并被广泛接受误差逆传播学习算法的是以Rumelhart和McCelland为首的科学家小组。他们在1986年出版“Parallel Distributed Processing,Explorations in the Microstructure of Cognition”(《并行分布信息处理》)一书中,对误差逆传播学习算法进行了详尽的分析与介绍,并对这一算法的潜在能力进行了深入探讨。
BP网络是一种具有3层或3层以上的阶层型神经网络。上、下层之间各神经元实现全连接,即下层的每一个神经元与上层的每一个神经元都实现权连接,而每一层各神经元之间无连接。网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,神经元的激活值从输入层经各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应。在这之后,按减小期望输出与实际输出的误差的方向,从输入层经各隐含层逐层修正各连接权,最后回到输入层,故得名“误差逆传播学习算法”。随着这种误差逆传播修正的不断进行,网络对输入模式响应的正确率也不断提高。
BP网络主要应用于以下几个方面:
1)函数逼近:用输入模式与相应的期望输出模式学习一个网络逼近一个函数;
2)模式识别:用一个特定的期望输出模式将它与输入模式联系起来;
3)分类:把输入模式以所定义的合适方式进行分类;
4)数据压缩:减少输出矢量的维数以便于传输或存储。
在人工神经网络的实际应用中,80%~90%的人工神经网络模型采用BP网络或它的变化形式,它也是前向网络的核心部分,体现了人工神经网络最精华的部分。
二、BP模型原理
下面以三层BP网络为例,说明学习和应用的原理。
1.数据定义
P对学习模式(xp,dp),p=1,2,…,P;
输入模式矩阵X[N][P]=(x1,x2,…,xP);
目标模式矩阵d[M][P]=(d1,d2,…,dP)。
三层BP网络结构
输入层神经元节点数S0=N,i=1,2,…,S0;
隐含层神经元节点数S1,j=1,2,…,S1;
神经元激活函数f1[S1];
权值矩阵W1[S1][S0];
偏差向量b1[S1]。
输出层神经元节点数S2=M,k=1,2,…,S2;
神经元激活函数f2[S2];
权值矩阵W2[S2][S1];
偏差向量b2[S2]。
学习参数
目标误差ϵ;
初始权更新值Δ0;
最大权更新值Δmax;
权更新值增大倍数η+;
权更新值减小倍数η-。
2.误差函数定义
对第p个输入模式的误差的计算公式为
中国矿产资源评价新技术与评价新模型
y2kp为BP网的计算输出。
3.BP网络学习公式推导
BP网络学习公式推导的指导思想是,对网络的权值W、偏差b修正,使误差函数沿负梯度方向下降,直到网络输出误差精度达到目标精度要求,学习结束。
各层输出计算公式
输入层
y0i=xi,i=1,2,…,S0;
隐含层
中国矿产资源评价新技术与评价新模型
y1j=f1(z1j),
j=1,2,…,S1;
输出层
中国矿产资源评价新技术与评价新模型
y2k=f2(z2k),
k=1,2,…,S2。
输出节点的误差公式
中国矿产资源评价新技术与评价新模型
对输出层节点的梯度公式推导
中国矿产资源评价新技术与评价新模型
E是多个y2m的函数,但只有一个y2k与wkj有关,各y2m间相互独立。
其中
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
设输出层节点误差为
δ2k=(dk-y2k)·f2′(z2k),
则
中国矿产资源评价新技术与评价新模型
同理可得
中国矿产资源评价新技术与评价新模型
对隐含层节点的梯度公式推导
中国矿产资源评价新技术与评价新模型
E是多个y2k的函数,针对某一个w1ji,对应一个y1j,它与所有的y2k有关。因此,上式只存在对k的求和,其中
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
设隐含层节点误差为
中国矿产资源评价新技术与评价新模型
则
中国矿产资源评价新技术与评价新模型
同理可得
中国矿产资源评价新技术与评价新模型
4.采用弹性BP算法(RPROP)计算权值W、偏差b的修正值ΔW,Δb
1993年德国 Martin Riedmiller和Heinrich Braun 在他们的论文“A Direct Adaptive Method for Faster Backpropagation Learning:The RPROP Algorithm”中,提出Resilient Backpropagation算法——弹性BP算法(RPROP)。这种方法试图消除梯度的大小对权步的有害影响,因此,只有梯度的符号被认为表示权更新的方向。
权改变的大小仅仅由权专门的“更新值”
确定
中国矿产资源评价新技术与评价新模型
其中
表示在模式集的所有模式(批学习)上求和的梯度信息,(t)表示t时刻或第t次学习。
权更新遵循规则:如果导数是正(增加误差),这个权由它的更新值减少。如果导数是负,更新值增加。
中国矿产资源评价新技术与评价新模型
RPROP算法是根据局部梯度信息实现权步的直接修改。对于每个权,我们引入它的
各自的更新值
,它独自确定权更新值的大小。这是基于符号相关的自适应过程,它基
于在误差函数E上的局部梯度信息,按照以下的学习规则更新
中国矿产资源评价新技术与评价新模型
其中0<η-<1<η+。
在每个时刻,如果目标函数的梯度改变它的符号,它表示最后的更新太大,更新值
应由权更新值减小倍数因子η-得到减少;如果目标函数的梯度保持它的符号,更新值应由权更新值增大倍数因子η+得到增大。
为了减少自由地可调参数的数目,增大倍数因子η+和减小倍数因子η–被设置到固定值
η+=1.2,
η-=0.5,
这两个值在大量的实践中得到了很好的效果。
RPROP算法采用了两个参数:初始权更新值Δ0和最大权更新值Δmax
当学习开始时,所有的更新值被设置为初始值Δ0,因为它直接确定了前面权步的大小,它应该按照权自身的初值进行选择,例如,Δ0=0.1(默认设置)。
为了使权不至于变得太大,设置最大权更新值限制Δmax,默认上界设置为
Δmax=50.0。
在很多实验中,发现通过设置最大权更新值Δmax到相当小的值,例如
Δmax=1.0。
我们可能达到误差减小的平滑性能。
5.计算修正权值W、偏差b
第t次学习,权值W、偏差b的的修正公式
W(t)=W(t-1)+ΔW(t),
b(t)=b(t-1)+Δb(t),
其中,t为学习次数。
6.BP网络学习成功结束条件每次学习累积误差平方和
中国矿产资源评价新技术与评价新模型
每次学习平均误差
中国矿产资源评价新技术与评价新模型
当平均误差MSE<ε,BP网络学习成功结束。
7.BP网络应用预测
在应用BP网络时,提供网络输入给输入层,应用给定的BP网络及BP网络学习得到的权值W、偏差b,网络输入经过从输入层经各隐含层向输出层的“顺传播”过程,计算出BP网的预测输出。
8.神经元激活函数f
线性函数
f(x)=x,
f′(x)=1,
f(x)的输入范围(-∞,+∞),输出范围(-∞,+∞)。
一般用于输出层,可使网络输出任何值。
S型函数S(x)
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围(0,1)。
f′(x)=f(x)[1-f(x)],
f′(x)的输入范围(-∞,+∞),输出范围(0,
]。
一般用于隐含层,可使范围(-∞,+∞)的输入,变成(0,1)的网络输出,对较大的输入,放大系数较小;而对较小的输入,放大系数较大,所以可用来处理和逼近非线性的输入/输出关系。
在用于模式识别时,可用于输出层,产生逼近于0或1的二值输出。
双曲正切S型函数
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围(-1,1)。
f′(x)=1-f(x)·f(x),
f′(x)的输入范围(-∞,+∞),输出范围(0,1]。
一般用于隐含层,可使范围(-∞,+∞)的输入,变成(-1,1)的网络输出,对较大的输入,放大系数较小;而对较小的输入,放大系数较大,所以可用来处理和逼近非线性的输入/输出关系。
阶梯函数
类型1
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围{0,1}。
f′(x)=0。
类型2
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围{-1,1}。
f′(x)=0。
斜坡函数
类型1
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围[0,1]。
中国矿产资源评价新技术与评价新模型
f′(x)的输入范围(-∞,+∞),输出范围{0,1}。
类型2
中国矿产资源评价新技术与评价新模型
f(x)的输入范围(-∞,+∞),输出范围[-1,1]。
中国矿产资源评价新技术与评价新模型
f′(x)的输入范围(-∞,+∞),输出范围{0,1}。
三、总体算法
1.三层BP网络(含输入层,隐含层,输出层)权值W、偏差b初始化总体算法
(1)输入参数X[N][P],S0,S1,f1[S1],S2,f2[S2];
(2)计算输入模式X[N][P]各个变量的最大值,最小值矩阵 Xmax[N],Xmin[N];
(3)隐含层的权值W1,偏差b1初始化。
情形1:隐含层激活函数f( )都是双曲正切S型函数
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9))输出W1[S1][S0],b1[S1]。
情形2:隐含层激活函数f( )都是S型函数
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9)输出W1[S1][S0],b1[S1]。
情形3:隐含层激活函数f( )为其他函数的情形
1)计算输入模式X[N][P]的每个变量的范围向量Xrng[N];
2)计算输入模式X的每个变量的范围均值向量Xmid[N];
3)计算W,b的幅度因子Wmag;
4)产生[-1,1]之间均匀分布的S0×1维随机数矩阵Rand[S1];
5)产生均值为0,方差为1的正态分布的S1×S0维随机数矩阵Randnr[S1][S0],随机数范围大致在[-1,1];
6)计算W[S1][S0],b[S1];
7)计算隐含层的初始化权值W1[S1][S0];
8)计算隐含层的初始化偏差b1[S1];
9)输出W1[S1][S0],b1[S1]。
(4)输出层的权值W2,偏差b2初始化
1)产生[-1,1]之间均匀分布的S2×S1维随机数矩阵W2[S2][S1];
2)产生[-1,1]之间均匀分布的S2×1维随机数矩阵b2[S2];
3)输出W2[S2][S1],b2[S2]。
2.应用弹性BP算法(RPROP)学习三层BP网络(含输入层,隐含层,输出层)权值W、偏差b总体算法
函数:Train3BP_RPROP(S0,X,P,S1,W1,b1,f1,S2,W2,b2,f2,d,TP)
(1)输入参数
P对模式(xp,dp),p=1,2,…,P;
三层BP网络结构;
学习参数。
(2)学习初始化
1)
;
2)各层W,b的梯度值
,
初始化为零矩阵。
(3)由输入模式X求第一次学习各层输出y0,y1,y2及第一次学习平均误差MSE
(4)进入学习循环
epoch=1
(5)判断每次学习误差是否达到目标误差要求
如果MSE<ϵ,
则,跳出epoch循环,
转到(12)。
(6)保存第epoch-1次学习产生的各层W,b的梯度值
,
(7)求第epoch次学习各层W,b的梯度值
,
1)求各层误差反向传播值δ;
2)求第p次各层W,b的梯度值
,
;
3)求p=1,2,…,P次模式产生的W,b的梯度值
,
的累加。
(8)如果epoch=1,则将第epoch-1次学习的各层W,b的梯度值
,
设为第epoch次学习产生的各层W,b的梯度值
,
。
(9)求各层W,b的更新
1)求权更新值Δij更新;
2)求W,b的权更新值
,
;
3)求第epoch次学习修正后的各层W,b。
(10)用修正后各层W、b,由X求第epoch次学习各层输出y0,y1,y2及第epoch次学习误差MSE
(11)epoch=epoch+1,
如果epoch≤MAX_EPOCH,转到(5);
否则,转到(12)。
(12)输出处理
1)如果MSE<ε,
则学习达到目标误差要求,输出W1,b1,W2,b2。
2)如果MSE≥ε,
则学习没有达到目标误差要求,再次学习。
(13)结束
3.三层BP网络(含输入层,隐含层,输出层)预测总体算法
首先应用Train3lBP_RPROP( )学习三层BP网络(含输入层,隐含层,输出层)权值W、偏差b,然后应用三层BP网络(含输入层,隐含层,输出层)预测。
函数:Simu3lBP( )。
1)输入参数:
P个需预测的输入数据向量xp,p=1,2,…,P;
三层BP网络结构;
学习得到的各层权值W、偏差b。
2)计算P个需预测的输入数据向量xp(p=1,2,…,P)的网络输出 y2[S2][P],输出预测结果y2[S2][P]。
四、总体算法流程图
BP网络总体算法流程图见附图2。
五、数据流图
BP网数据流图见附图1。
六、实例
实例一 全国铜矿化探异常数据BP 模型分类
1.全国铜矿化探异常数据准备
在全国铜矿化探数据上用稳健统计学方法选取铜异常下限值33.1,生成全国铜矿化探异常数据。
2.模型数据准备
根据全国铜矿化探异常数据,选取7类33个矿点的化探数据作为模型数据。这7类分别是岩浆岩型铜矿、斑岩型铜矿、矽卡岩型、海相火山型铜矿、陆相火山型铜矿、受变质型铜矿、海相沉积型铜矿,另添加了一类没有铜异常的模型(表8-1)。
3.测试数据准备
全国化探数据作为测试数据集。
4.BP网络结构
隐层数2,输入层到输出层向量维数分别为14,9、5、1。学习率设置为0.9,系统误差1e-5。没有动量项。
表8-1 模型数据表
续表
5.计算结果图
如图8-2、图8-3。
图8-2
图8-3 全国铜矿矿床类型BP模型分类示意图
实例二 全国金矿矿石量品位数据BP 模型分类
1.模型数据准备
根据全国金矿储量品位数据,选取4类34个矿床数据作为模型数据,这4类分别是绿岩型金矿、与中酸性浸入岩有关的热液型金矿、微细浸染型型金矿、火山热液型金矿(表8-2)。
2.测试数据准备
模型样本点和部分金矿点金属量、矿石量、品位数据作为测试数据集。
3.BP网络结构
输入层为三维,隐层1层,隐层为三维,输出层为四维,学习率设置为0.8,系统误差1e-4,迭代次数5000。
表8-2 模型数据
4.计算结果
结果见表8-3、8-4。
表8-3 训练学习结果
表8-4 预测结果(部分)
续表
4、简述人工神经网络的结构形式
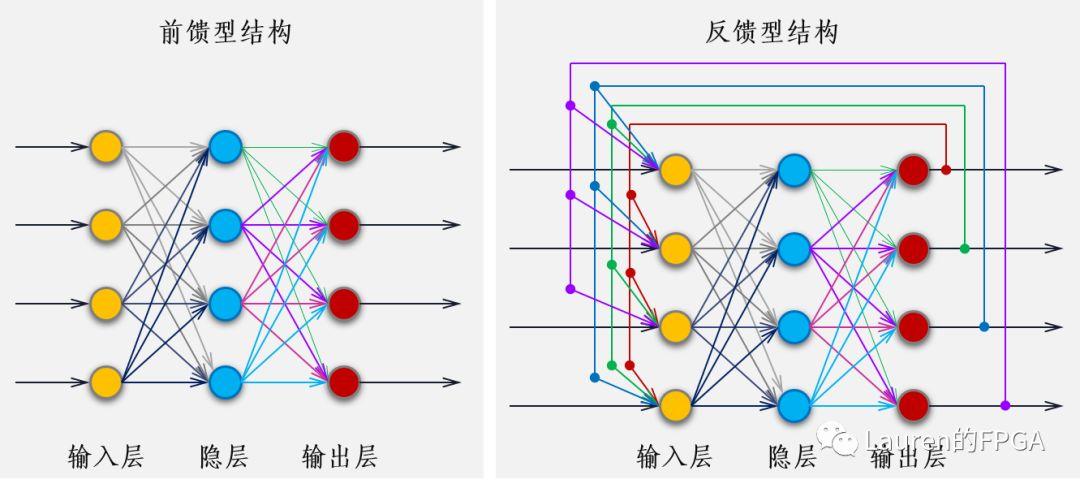
神经网络有多种分类方式,例如,按网络性能可分为连续型与离散型网络,确定型与随机型网络:按网络拓扑结构可分为前向神经网络与反馈神经网络。本章土要简介前向神经网络、反馈神经网络和自组织特征映射神经网络。
前向神经网络是数据挖掘中广为应用的一种网络,其原理或算法也是很多神经网络模型的基础。径向基函数神经网络就是一种前向型神经网络。
Hopfield神经网络是反馈网络的代表。Hvpfi}ld网络的原型是一个非线性动力学系统,目前,已经在联想记忆和优化计算中得到成功应用。
模拟退火算法是为解决优化计算中局部极小问题提出的。Baltzmann机是具有随机输出值单元的随机神经网络,串行的Baltzmann机可以看作是对二次组合优化问题的模拟退火算法的具体实现,同时它还可以模拟外界的概率分布,实现概率意义上的联想记忆。
自组织竞争型神经网络的特点是能识别环境的特征并自动聚类。自组织竟争型神经网络已成功应用于特征抽取和大规模数据处理。
5、神经网络模型有几种分类方法,试给出一种分类
神经网络模型的分类人工神经网络的模型很多,可以按照不同的方法进行分类。其中,常见的两种分类方法是,按照网络连接的拓朴结构分类和按照网络内部的信息流向分类。1 按照网络拓朴结构分类网络的拓朴结构,即神经元之间的连接方式。按此划分,可将神经网络结构分为两大类:层次型结构和互联型结构。层次型结构的神经网络将神经元按功能和顺序的不同分为输出层、中间层(隐层)、输出层。输出层各神经元负责接收来自外界的输入信息,并传给中间各隐层神经元;隐层是神经网络的内部信息处理层,负责信息变换。根据需要可设计为一层或多层;最后一个隐层将信息传递给输出层神经元经进一步处理后向外界输出信息处理结果。 而互连型网络结构中,任意两个节点之间都可能存在连接路径,因此可以根据网络中节点的连接程度将互连型网络细分为三种情况:全互连型、局部互连型和稀疏连接型2 按照网络信息流向分类从神经网络内部信息传递方向来看,可以分为两种类型:前馈型网络和反馈型网络。单纯前馈网络的结构与分层网络结构相同,前馈是因网络信息处理的方向是从输入层到各隐层再到输出层逐层进行而得名的。前馈型网络中前一层的输出是下一层的输入,信息的处理具有逐层传递进行的方向性,一般不存在反馈环路。因此这类网络很容易串联起来建立多层前馈网络。反馈型网络的结构与单层全互连结构网络相同。在反馈型网络中的所有节点都具有信息处理功能,而且每个节点既可以从外界接受输入,同时又可以向外界输出。
6、bp神经网络对输入数据和输出数据有什么要求
p神经网络的输入数据越多越好,输出数据需要反映网络的联想记忆和预测能力。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。BP网络具有高度非线性和较强的泛化能力,但也存在收敛速度慢、迭代步数多、易于陷入局部极小和全局搜索能力差等缺点。
扩展资料:
BP算法主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。
1、初始化,随机给定各连接权及阀值。
2、由给定的输入输出模式对计算隐层、输出层各单元输出
3、计算新的连接权及阀值,计算公式如下:
4、选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
参考资料来源: