encoder 的 attention
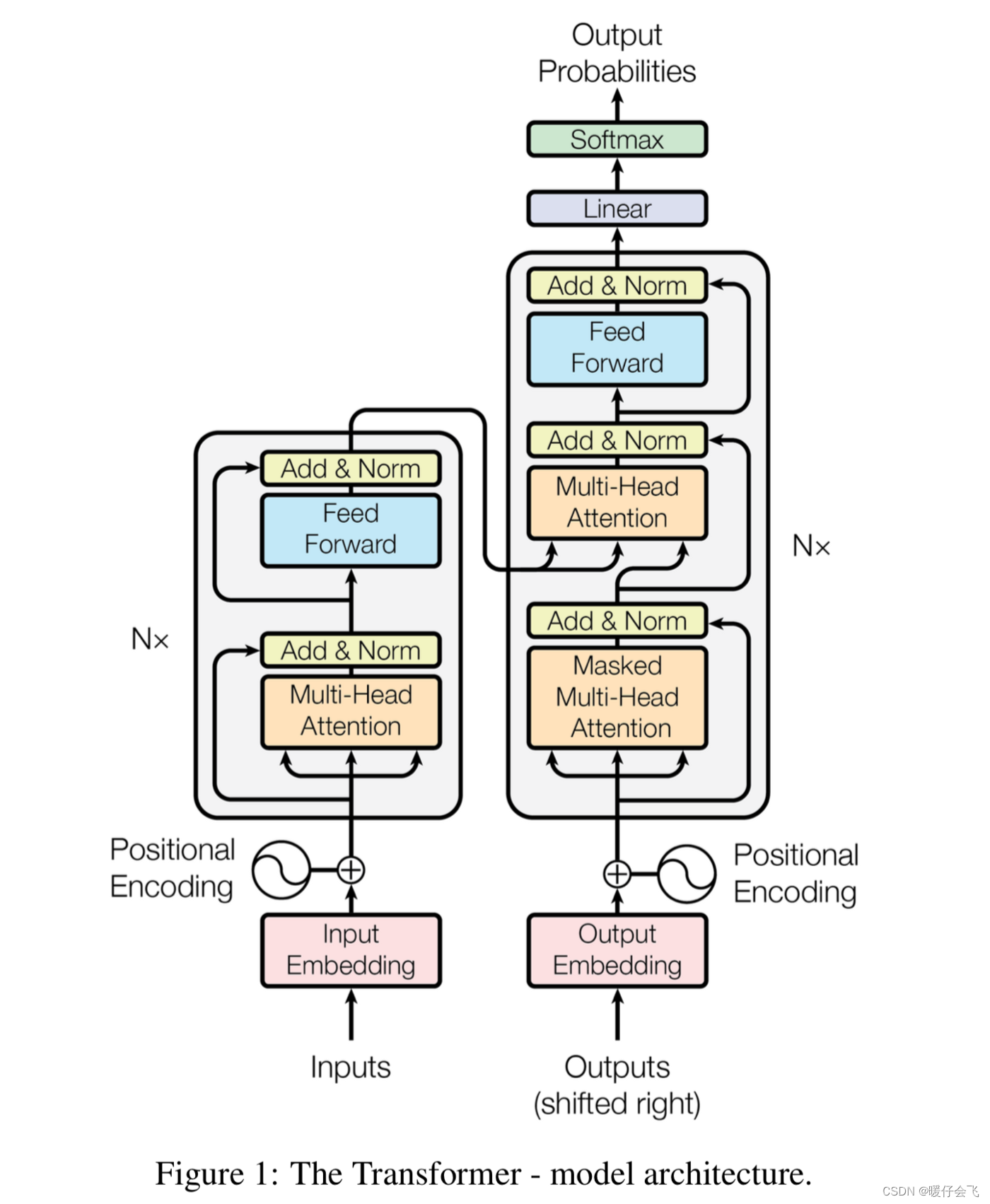
- 场景:现在要训练的内容是 I love my dog -> 我喜欢我的狗
- 那么在 encoder 端的输入是: I love my dog;
- 假设经过 embedding 和位置编码后,I love my dog 这句话肯定已经变成了一个向量,但是在这里方便起见,我们依然用 I love my dog 来表示经过了处理之后的向量表示,后面有机会我会将向量的维度拆解开再给大家讲一遍
- 接下来要进入 encoder 端的 attention 层了
attention 的动机
- 动机很简单:生成一个张量,张量表示了输入的每一个词向量和其他词向量之间的关系。
- 这个关系的表示,需要在一个给定维度的空间中完成(在另外一个空间中求相似度,后面会解释)。而在多少维度的空间中进行,就取决于我们在 attention 中指定的线性层的维度
如何衡量关系——相似度
- 我们初中就学过,衡量两个向量的相似度的方法就是向量点乘,数值越大越相似
- 而编码过的单词天生就是向量
如何构造两个相乘的向量
- 难道要用 III 向量和所有的 Love,my,dogLove, my, dogLove,my,dog 都相乘一遍得到相似度么?
- 这个思考方向是对的,但是存在一个问题,就是这样乘出的相似度没有意义,因为在当前的表示空间中,所有的词的向量表示都是固定的;
- 而我们想让那些彼此相乘的向量具有以下特点:
- 这些向量能够代表文本向量的信息,因为我们还是想要得到 III 到底和 LoveLoveLove 关系更近还是和 MyMyMy 关系更近
- 这些向量能够带有可学习的参数,通过神经网络的迭代自己学出来;这样可以保证在不同的场景下,权重可以自行改变,有时候 III 可以和 lovelovelove 的关系更近,而有些时候则和其他的单词的关系更近
- 所以这很自然有一个想法:
- 我直接以原文本的向量为基础,通过线性层对他的特征进行一次处理,这样得到的向量不就具有上述特点了么;
- 线性层的输入是原文本的向量,这样可以保证线性层的输出是原文本的一种表示,这相当于将原本的所有词向量映射到另外一个高维空间中的向量,而这个过程引入了可学习的参数,相当于那些被映射过去的向量之间的关系并未确定,而是需要根据 loss 和反向传播不断更新才能最终收敛,直到那时,词向量之间的关系才被最终确定。
-
这就是 Transformer 中总是提到的 q,k,vq, k, vq,k,v 向量和 Q,K,VQ,K,VQ,K,V 矩阵的作用了;我们先说 q,k,vq, k, vq,k,v 向量;后面很自然地会过渡到 Q,K,VQ, K, VQ,K,V 矩阵。
-
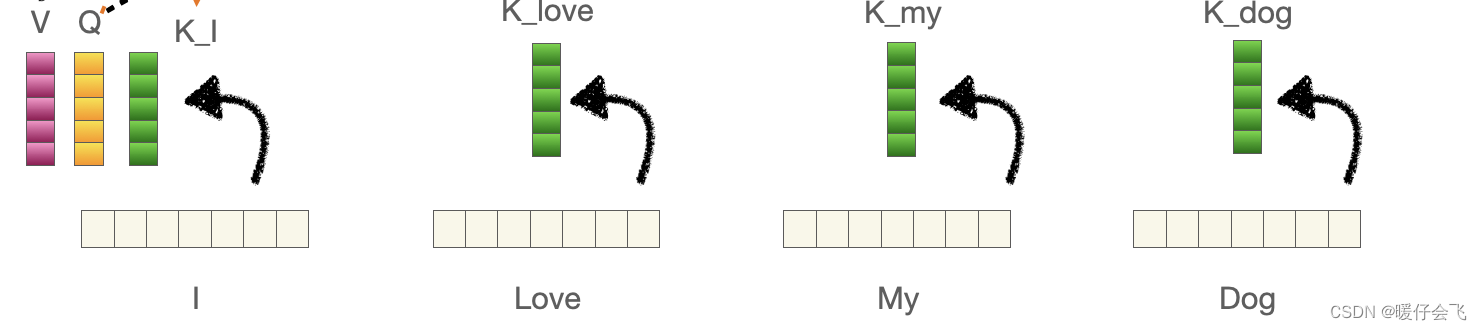
我们以 III 这个文本为例,对他采用线性层生成一个 qqq 向量,这个 qqq 向量包含了 III 向量原本的信息,然后对其他的所有文本也都通过线性层生成他们各自的 kkk 向量;这些 kkk 向量其实和 qqq 是完全一样的东西,都只是线性层的输出而已,但是为了进行后面的操作,我们人为地对这些向量进行区分
-
当然,除了III 之外的单词也会产生 qqq 向量,只是这里我们先看 III 这个单词,所以先将 III 当做主角,其他单词的 qqq 向量也是同样的作用,如法炮制
-
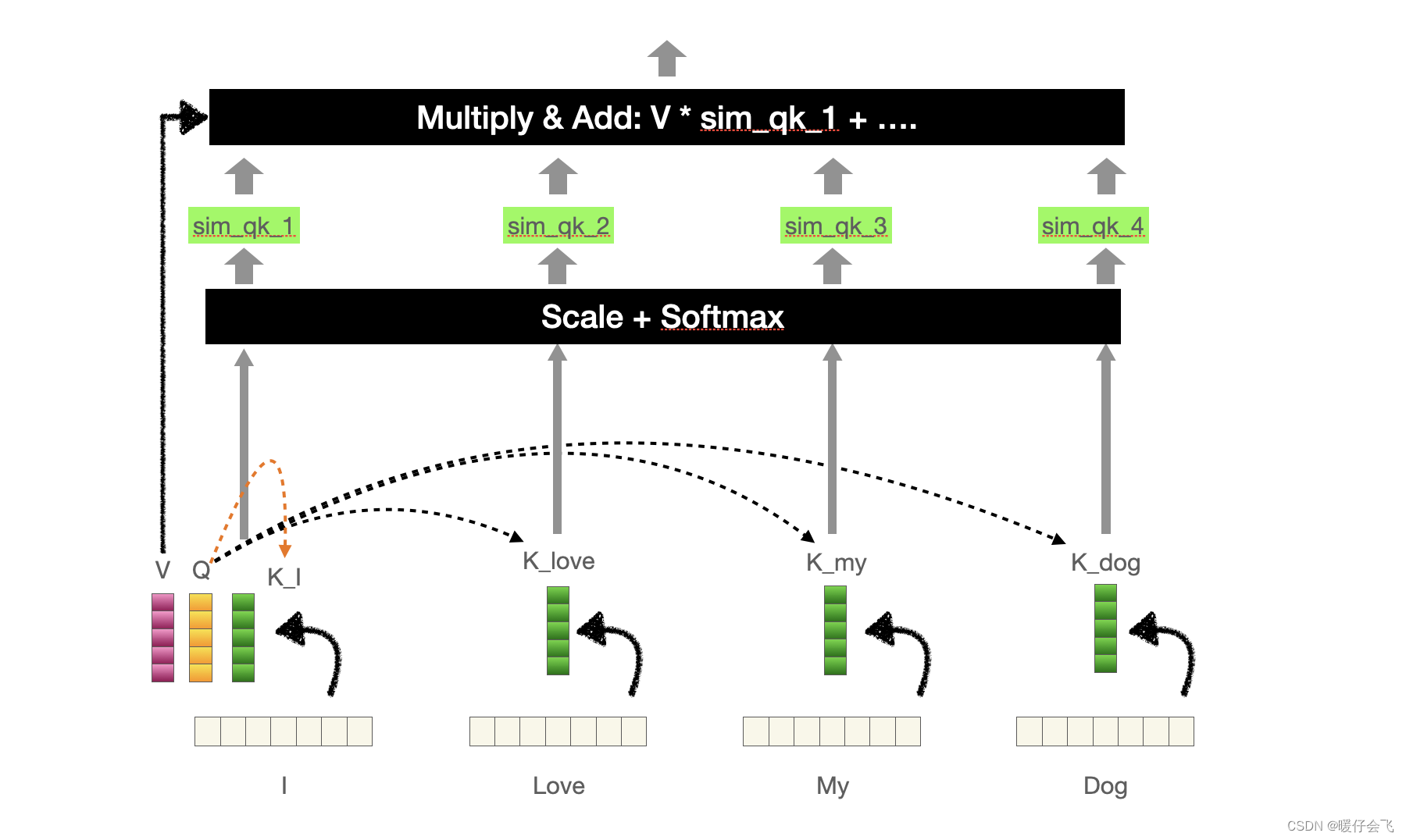
得到 III 的 qqq 向量之后,让这个 qqq 向量和其他所有单词产生的 kkk 向量 klove,kmy,kdogk_{love}, k_{my}, k_{dog}klove,kmy,kdog 进行点乘,是不是就可以获得 I 对其他所有单词的值(有几个单词就产生几个值)但是这些值还不能叫做权重,因为相似度计算出的值范围根本不确定;因此我们对这些值共同算一个 softmax 就可以得到权重值了。
-
举个🌰,假设 III 的 qqq 向量和每个 kkk 计算得到的值分别为 [a,b,c,d][a, b, c, d][a,b,c,d];这些值要进行放缩之后再 softmaxsoftmaxsoftmax 才能得到最终的权重值。
-
再强调一遍,这个权重值会根据训练的不同阶段而不断更新,但是我们知道,通过这个步骤,III 建立了它对所有单词的关系,这些关系其实就只是在另外一个高维空间中的相似度数值而已。
-
最终还要再用 v 向量再去和每一个生成的相似度权重 sim_qk_nsim\_{qk}\_nsim_qk_n (每一个都是标量)相乘之后相加,得到一个最终的向量。这个最终的向量编码了 I 和其他词向量的关系
-
同样的,对于 Love,my,dogLove, my, dogLove,my,dog 这些词向量,也通过相同的方式获得了他们各自的最终和其他词向量在高维空间中的关系表示
-
我们用向量的维度来具体的,更加深入理解一下这个过程:
- 假设 I,love,my,dogI,love,my,dogI,love,my,dog 都已经被 embeddingembeddingembedding 成维度为 6 的向量,即,(1,6)(1,6)(1,6)
- 线性层选的神经元个数都是 5,即,(1,5)(1, 5)(1,5) 代表我们想在一个 5 维的空间中构建这些词之间的关系
- 那么 q,k,vq, k, vq,k,v 也都是 (1,5)(1, 5)(1,5) 的向量
- 当 III 的 qiq_iqi(1,5) 与这四个 kkk 点乘之后,可以得到 4 个标量,
- 将这 4 个标量分别与 vi:(1,5)v_i: (1,5)vi:(1,5) 相乘(标量乘)并相加,得到的最终还是一个向量 vi′:(1,5)v_i^{'}: (1, 5)vi′:(1,5),这个 vi′v_i^{'}vi′ 编码了 qiq_iqi 和其他词向量在 5 维空间中的相关关系。
- 这个过程中的 qiq_iqi 和多个 kkk 进行运算的步骤可以转成向量和矩阵的乘法, qiq_iqi,和 4 个 k 组成的张量 K:(4,5)K: (4, 5)K:(4,5) 进行相乘,(注意,这里要将 KKK 进行转置),得到 qKTq K^TqKT 维度是 (1,5)∗(5,4)=(1,4)(1, 5)* (5, 4)= (1, 4)(1,5)∗(5,4)=(1,4)就是那四个标量值组成的向量
- 这只是一个对 qiq_iqi 求算 attentionattentionattention 的整体步骤,而我们刚好要对所有单词生成的 q 都进行这个过程,所以我们可以也把 qqq 做成 QQQ,也就是将所有的 4 个单词的 qqq 直接拼起来组成的 Q:(4,5)Q: (4, 5)Q:(4,5), 与刚才的 KT:(5,4)K^T: (5,4)KT:(5,4) 得到 权重矩阵 QKT:(4,4)QK^{T}: (4, 4)QKT:(4,4)
- 然后将所有单词的 v 向量也拼起来,组成 V:(4,5)V: (4, 5)V:(4,5) 与权重矩阵 (4,4)(4, 4)(4,4) 最终得到 attentionattentionattention 的矩阵 QKTV(4,5)QK^{T} V (4,5)QKTV(4,5)这其中的 4 代表的是这 4 个单词与其他单词的 attentionattentionattention 关系的编码, 5 则代表这些 attentionattentionattention 关系被编码的空间是一个维度为 5 的空间。5 个数值来共同表示这些关系。