文章目录
- 一、线程创建方法(以redis举例)
- 1)创建线程函数讲解
- 2)线程创建的标记
- 二、内核中对线程的数据结构表示
- 1)task_struct具体定义
- 2)线程与进程的区别
- 三、进程、线程创建过程及异同
- 1)进程创建(用到do_fork)
- 2)线程的创建(也是用到do_fork)
- 3)进程线程创建异同(传入do_fork的标记不一样)
- 四、揭秘 do_fork 系统调用
- 1)复制 task_struct 结构体
- 2)拷贝打开文件列表(创建进程就没有传入CLONE_FILES标记,进程不会共用file_struct)
- 3)拷贝文件目录信息
- 4)拷贝内存地址空间(创建线程带 CLONE_VM ,表示和当前线程共享一份地址空间mm_struct)
- 五 结论
- 1)线程
- 2)进程
- 3)线程和进程切换相差多少?
如是游戏工作者,请和 游戏思考10:游戏服务器的进程和线程简单谈谈一起食用
一、线程创建方法(以redis举例)
在 Redis 6.0 以上的版本里,也开始支持使用多线程来提供核心服务,我们就以它为例。在 Redis 主线程启动以后,会调用 initThreadedIO 函数来创建多个 io 线程。
- 主线程
//file:src/networking.c
void initThreadedIO(void) {//开始 io 线程的创建for (int i = 0; i < server.io_threads_num; i++) {pthread_t tid;pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i)io_threads[i] = tid;}
}
1)创建线程函数讲解
创建线程具体调用的是 pthread_create 函数,pthread_create 是在 glibc 库中实现的。在 glibc 库中,pthread_create 函数的实现调用路径是 __pthread_create_2_1 -> create_thread。其中 create_thread 这个函数比较重要,它设置了创建线程时使用的各种 flag 标记。
- 代码
//file:nptl/sysdeps/pthread/createthread.c
static int
create_thread (struct pthread *pd, ...)
{int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL| CLONE_SETTLS | CLONE_PARENT_SETTID| CLONE_CHILD_CLEARTID | CLONE_SYSVSEM| 0);int res = do_clone (pd, attr, clone_flags, start_thread,STACK_VARIABLES_ARGS, 1);...
}
在上面的代码中,传入参数中的各个 flag 标记是非常关键的。
2)线程创建的标记
CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子”CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umaskCLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchyCLONE_SIGHAND 子进程与父进程共享相同的信号处理(signal handler)表CLONE_PTRACE 若父进程被trace,子进程也被traceCLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源CLONE_VM 子进程与父进程运行于相同的内存空间CLONE_PID 子进程在创建时PID与父进程一致CLONE_THREAD Linux 2.4中增加以支持POSIX线程标准,子进程与父进程共享相同的线程群CLONE_VM 0x00000100 置起此标志在进程间共享地址空间
CLONE_FS 0x00000200 置起此标志在进程间共享文件系统信息
CLONE_FILES 0x00000400 置起此标志在进程间共享打开的文件
CLONE_SIGHAND 0x00000800 置起此标志在进程间共享信号处理程序
接下来的 do_clone 最终会调用一段汇编程序,在汇编里进入 clone 系统调用,之后会进入内核中进行处理。
//file:sysdeps/unix/sysv/linux/i386/clone.S
ENTRY (BP_SYM (__clone))...movl $SYS_ify(clone),%eax...
二、内核中对线程的数据结构表示
在开始介绍线程的创建过程之前,先给大家看看内核中表示线程的数据结构。开篇的时候我说了,进程和线程的相同点要远远大于不同点。主要依据就是在 Linux 中,无论进程还是线程,都是抽象成了 task 任务,在源码里都是用 task_struct 结构来实现的。
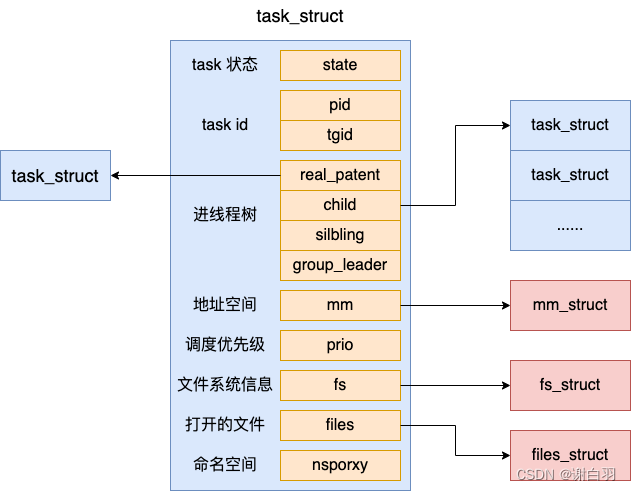
1)task_struct具体定义
我们来看 task_struct 具体的定义,它位于 include/linux/sched.h
//file:include/linux/sched.h
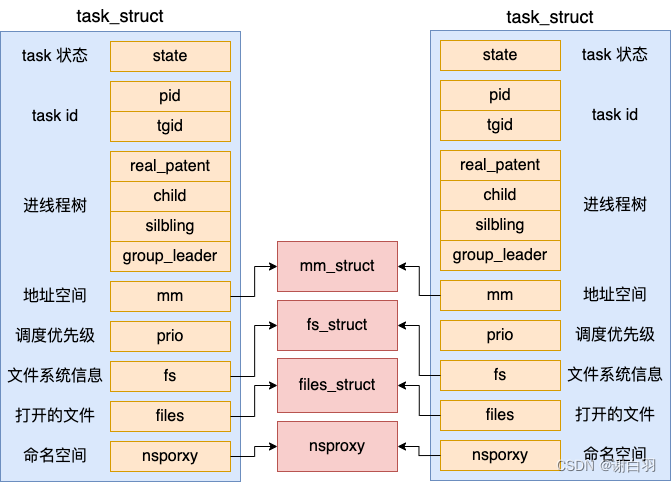
struct task_struct {//1.1 task状态 volatile long state;//1.2 进程线程的pidpid_t pid; //自己的进程IDpid_t tgid; //父进程的ID//1.3 task树关系:父进程、子进程、兄弟进程struct task_struct __rcu *parent;struct list_head children; struct list_head sibling;struct task_struct *group_leader; //1.4 task调度优先级int prio, static_prio, normal_prio;unsigned int rt_priority;//1.5 地址空间struct mm_struct *mm, *active_mm;//1.6 文件系统信息(当前目录等)struct fs_struct *fs;//1.7 打开的文件信息struct files_struct *files;//1.8 namespaces struct nsproxy *nsproxy;...
}
2)线程与进程的区别
-
相同点
1)对于线程来讲,所有的字段都是和进程一样的(本来就是一个结构体来表示的)。包括状态、pid、task 树关系、地址空间、文件系统信息、打开的文件信息等等字段,线程也都有。
2)进程和线程的相同点要远远大于不同点,本质上是同一个东西,都是一个 task_struct !正因为进程线程如此之相像,所以在 Linux 下的线程还有另外一个名字,叫轻量级进程。至于说轻量在哪儿,稍后我们再说。 -
不同点
1)pid 和 tgid 这两个字段。在 Linux 中,每一个 task_struct 都需要被唯一的标识,它的 pid 就是唯一标识号。对于进程来说,这个 pid 就是我们平时常说的进程 pid。对于线程来说,我们假如一个进程下创建了多个线程出来。那么每个线程的 pid 都是不同的。但是我们一般又需要记录线程是属于哪个进程的。这时候,tgid 就派上用场了,通过 tgid 字段来表示自己所归属的进程 ID。
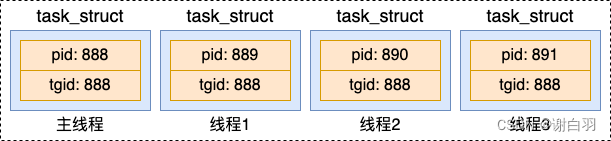
这样内核通过 tgid 可以知道线程属于哪个进程。
三、进程、线程创建过程及异同
1)进程创建(用到do_fork)
进程线程创建的时候,使用的函数看起来不一样。但实际在底层实现上,最终都是使用同一个函数do_fork()来实现的。

- fork传入参数就是执行了do_fork函数,注意参数是SIGCHLD,0,0,NULL,NULL
//file:kernel/fork.c
SYSCALL_DEFINE0(fork)
{return do_fork(SIGCHLD, 0, 0, NULL, NULL);
}
do_fork 函数又调用 copy_process 完成进程的创建。
//file:kernel/fork.c
long do_fork(...)
{//复制一个 task_struct 出来struct task_struct *p;p = copy_process(clone_flags, ...);...
}
2)线程的创建(也是用到do_fork)
我们在本文第一小节里介绍到 lib 库函数 pthread_create 会调用到 clone 系统调用,为其传入了一组 flag
//file:nptl/sysdeps/pthread/createthread.c
static int
create_thread (struct pthread *pd, ...)
{int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL| CLONE_SETTLS | CLONE_PARENT_SETTID| CLONE_CHILD_CLEARTID | CLONE_SYSVSEM| 0);int res = do_clone (pd, attr, clone_flags, ...);...
}
好,我们找到 clone 系统调用的实现
SYSCALL_DEFINE5(clone, ......)
{return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}
同样,do_fork 函数还是会执行到 copy_process 来完成实际的创建。
3)进程线程创建异同(传入do_fork的标记不一样)
可见和创建进程时使用的 fork 系统调用相比,创建线程的 clone 系统调用几乎和 fork 差不多,也一样使用的是内核里的 do_fork 函数,最后走到 copy_process 来完整创建。
- 传入标记不一样
不过创建过程的区别是二者在调用 do_fork 时传入的 clone_flags 里的标记不一样!
1)创建进程时的 flag:仅有一个 SIGCHLD
2)创建线程时的 flag:包括 CLONE_VM、CLONE_FS、CLONE_FILES、CLONE_SIGNAL、
CLONE_SETTLS、CLONE_PARENT_SETTID、CLONE_CHILD_CLEARTID、
CLONE_SYSVSEM。
- 部分标记含义
关于这些 flag 的含义,我们选几个关键的做一个简单的介绍,后面介绍 do_fork 细节的时
候会再次涉及到。
CLONE_VM: 新 task 和父进程共享地址空间
CLONE_FS:新 task 和父进程共享文件系统信息
CLONE_FILES:新 task 和父进程共享文件描述符表
这些 flag 会对 task_struct 产生啥影响,我们接着看接下来的内容。
四、揭秘 do_fork 系统调用
在本节中我们以动态的视角来看一下线程的创建过程.
前面我们看到,进程和线程创建都是调用内核中的 do_fork 函数来执行的。在 do_fork 的实现中,核心是一个 copy_process 函数,它以拷贝父进程(线程)的方式来生成一个新的 task_struct 出来。
//file:kernel/fork.c
long do_fork(unsigned long clone_flags, ...)
{//复制一个 task_struct 出来struct task_struct *p;p = copy_process(clone_flags, stack_start, stack_size,child_tidptr, NULL, trace);//子任务加入到就绪队列中去,等待调度器调度wake_up_new_task(p);...
}
- 接下来根据标记看是否执行拷贝对应的数据
//file:kernel/fork.c
static struct task_struct *copy_process(...)
{//4.1 复制进程 task_struct 结构体struct task_struct *p;p = dup_task_struct(current);...//4.2 拷贝 files_structretval = copy_files(clone_flags, p);//4.3 拷贝 fs_structretval = copy_fs(clone_flags, p);//4.4 拷贝 mm_structretval = copy_mm(clone_flags, p);//4.5 拷贝进程的命名空间 nsproxyretval = copy_namespaces(clone_flags, p);//4.6 申请 pid && 设置进程号pid = alloc_pid(p->nsproxy->pid_ns);p->pid = pid_nr(pid);p->tgid = p->pid;if (clone_flags & CLONE_THREAD)p->tgid = current->tgid;......
}
可见,copy_process 先是复制了一个新的 task_struct 出来,然后调用 copy_xxx 系列的函数对 task_struct 中的各种核心对象进行拷贝处理,还申请了 pid 。接下来我们分小节来查看该函数的每一个细节。
1)复制 task_struct 结构体
- (1)整体入口
//file:kernel/fork.c
static struct task_struct *dup_task_struct(struct task_struct *orig)
{//1、申请 task_struct 内核对象(slab线程解析)tsk = alloc_task_struct_node(node);//2、复制 task_structerr = arch_dup_task_struct(tsk, orig);...
}
- (2)分配内存
其中 alloc_task_struct_node 用于在 slab 内核内存管理区中申请一块内存出来。关于 slab 机制请参考- 内核内存管理
//file:kernel/fork.c
static struct kmem_cache *task_struct_cachep;
static inline struct task_struct *alloc_task_struct_node(int node)
{return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
- (3)对分配内存后的struct进行内存拷贝
//file:kernel/fork.c
int arch_dup_task_struct(struct task_struct *dst,struct task_struct *src)
{*dst = *src;return 0;
}
2)拷贝打开文件列表(创建进程就没有传入CLONE_FILES标记,进程不会共用file_struct)
创建线程调用 clone 系统调用的时候,传入了一堆的 flag,其中有一个就是 CLONE_FILES。如果传入了 CLONE_FILES 标记,就会复用当前进程的打开文件列表 - files 成员。

对于创建进程来讲,没有传入这个标志,就会新创建一个 files 成员出来
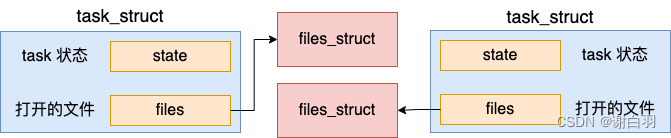
好了,我们继续看 copy_files 具体实现。
//file:kernel/fork.c
static int copy_files(unsigned long clone_flags, struct task_struct *tsk)
{struct files_struct *oldf, *newf;oldf = current->files;if (clone_flags & CLONE_FILES) {atomic_inc(&oldf->count);goto out;}newf = dup_fd(oldf, &error);tsk->files = newf;...
}
从代码看出,如果指定了 CLONE_FILES(创建线程的时候),只是在原有的 files_struct 里面 +1 就算是完事了,指针不变,仍然是复用创建它的进程的 files_struct 对象
- 重要点
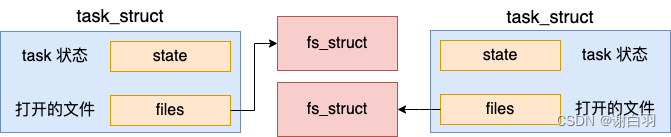
这就是进程和线程的其中一个区别,对于进程来讲,每一个进程都需要独立的 files_struct。但是对于线程来讲,它是和创建它的线程复用 files_struct的。
3)拷贝文件目录信息
再回忆一下创建线程的时候,传入的 flag 里也包括 CLONE_FS。如果指定了这个标志,就会复用当前进程的文件目录 - fs 成员。

对于创建进程来讲,没有传入这个标志,就会新创建一个 fs 出来。
好,我们继续看 copy_fs 的实现。
//file:kernel/fork.c
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{struct fs_struct *fs = current->fs;if (clone_flags & CLONE_FS) {fs->users++;return 0;}tsk->fs = copy_fs_struct(fs);return 0;
}
和 copy_files 函数类似,在 copy_fs 中如果指定了 CLONE_FS(创建线程的时候),并没有真正申请独立的 fs_struct 出来,近几年只是在原有的 fs 里的 users +1 就算是完事。
- 这里进程和线程的区别
而在创建进程的时候,由于没有传递这个标志,会进入到 copy_fs_struct 函数中申请新的 fs_struct 并进行赋值拷贝。
4)拷贝内存地址空间(创建线程带 CLONE_VM ,表示和当前线程共享一份地址空间mm_struct)
创建线程的时候带了 CLONE_VM 标志,而创建进程的时候没带。接下来在 copy_mm 函数 中会根据是否有这个标志来决定是该和当前线程共享一份地址空间 mm_struct,还是创建一份新的。
//file:kernel/fork.c
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{struct mm_struct *mm, *oldmm;oldmm = current->mm;if (clone_flags & CLONE_VM) {atomic_inc(&oldmm->mm_users);mm = oldmm;goto good_mm;}mm = dup_mm(tsk);
good_mm:return 0;
}
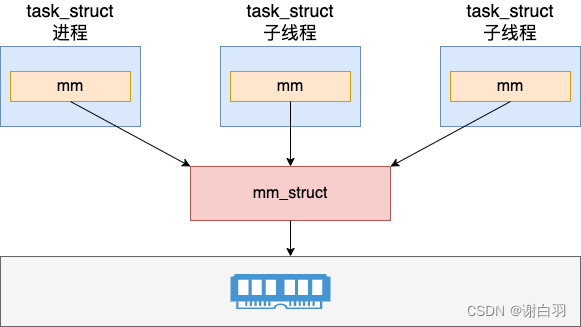
对于线程来讲,由于传入了 CLONE_VM 标记,所以不会申请新的 mm_struct 出来,而是共享其父进程的。

- 线程共享父进程地址地址空间
多线程程序中的所有线程都会共享其父进程的地址空间。
-
而对于多进程程序来说,每一个进程都有独立的 mm_struct(地址空间)
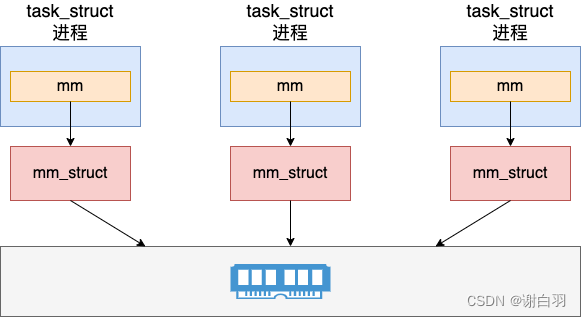
因为在内核中线程和进程都是用 task_struct 来表示,只不过线程和进程的区别是会和创建它的父进程共享打开文件列表、目录信息、虚拟地址空间等数据结构,会更轻量一些。所以在 Linux 下的线程也叫轻量级进程。 -
线程与进程区别
在打开文件列表、目录信息、内存虚拟地址空间中,内存虚拟地址空间是最重要的。因此区分一个 Task 任务该叫线程还是该叫进程,一般习惯上就看它是否有独立的地址空间。如果有,就叫做进程,没有,就叫做线程。
(这里展开多说一句,对于内核任务来说,无论有多少个任务,其使用地址空间都是同一个。所以一般都叫内核线程,而不是内核进程。)
五 结论
1)线程
- 对于线程:地址空间、目录信息、打开文件fd列表和父进程共享
(创建线程的整个过程我们就介绍完了。回头总结一下,对于线程来讲,其地址空间 mm_struct、目录信息 fs_struct、打开文件列表 files_struct 都是和创建它的任务共享的。)
2)进程
- 对于进程:地址空间、目录信息、打开文件fd列表都是独立需要额外内存初始化的
(对于进程来讲,地址空间 mm_struct、挂载点 fs_struct、打开文件列表 files_struct 都要是独立拥有的,都需要去申请内存并初始化它们。)
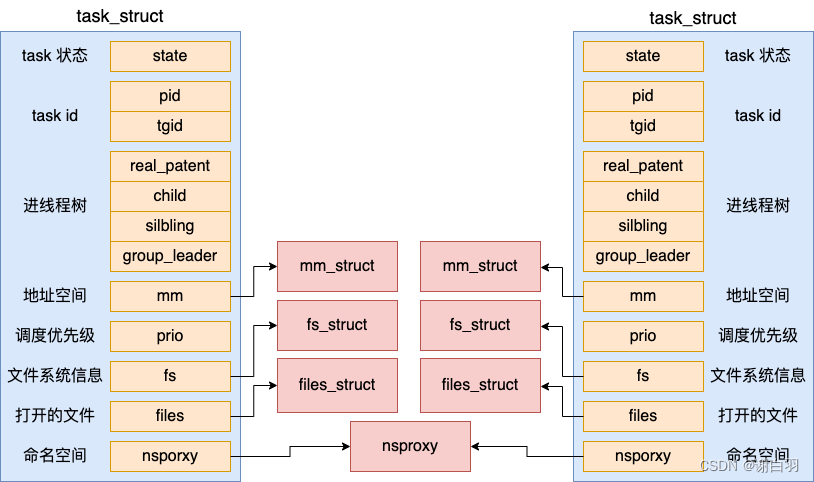
总之,在 Linux 内核中并没有对线程做特殊处理,还是由 task_struct 来管理。从内核的角度看,用户态的线程本质上还是一个进程。只不过和普通进程比,稍微“轻量”了那么一些。
3)线程和进程切换相差多少?
- 线程和进程切换相差多少?
那么线程具体能轻量多少呢?我之前曾经做过一个进程和线程的上下文切换开销测试。进程的测试结果是一次上下文切换平均 2.7 - 5.48 us 之间。线程上下文切换是 3.8 us左右。总的来说,进程线程切换还是没差太多。参见《进程/线程切换究竟需要多少开销?》