论文地址:https://arxiv.org/pdf/2111.09883.pdf
代码地址: GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows".
Abstract
本篇论文主要致力于解决大型视觉模型的训练和应用中的三个主要问题,包括训练的不稳定性、训练前和微调之间的分辨率差距,以及transformer需要高数据量。 提出了三种主要方法: 1)结合余弦注意的残差连接后进行归一化提高训练稳定性;2)对数间隔连续位置偏差方法,有效地将低分辨率图像预训练的模型转移到具有高分辨率输入的下游任务中;3)自监督预训练方法SimMIM,以减少对大量数据的需求。通过这些方法,本文训练了一个30亿参数的Swin transformer V2模型,这是迄今为止最大的密集视觉模型,并使其能够用高达1536×1536分辨率的图像进行训练。
1. Introduction
为了成功地训练大型和通用的视觉模型,需要解决几个关键问题。首先,我们的大视觉模型实验揭示了训练中的一个不稳定性问题。我们发现,在大型模型中,跨层的激活振幅的差异显著增大。仔细观察原始架构就会发现,这是由直接添加到主分支的残差单元的输出造成的。结果表明,激活值是逐层积累,因此深层的振幅明显大于早期层。为了解决这个问题,我们提出了一种新的标准化配置,称为res-post-norm,它将LN层从每个残差单元的开始移动到后端,如图1所示。 我们发现这种新配置在网络层中产生更温和的激活值。我们还提出了一个缩放的余弦注意来取代以前的点积注意。缩放的余弦注意使得计算与块输入的振幅无关,并且注意值不太可能落入极端值。在我们的实验中,所提出的两种技术不仅使训练过程更加稳定,而且提高了精度,特别是对于更大的模型。
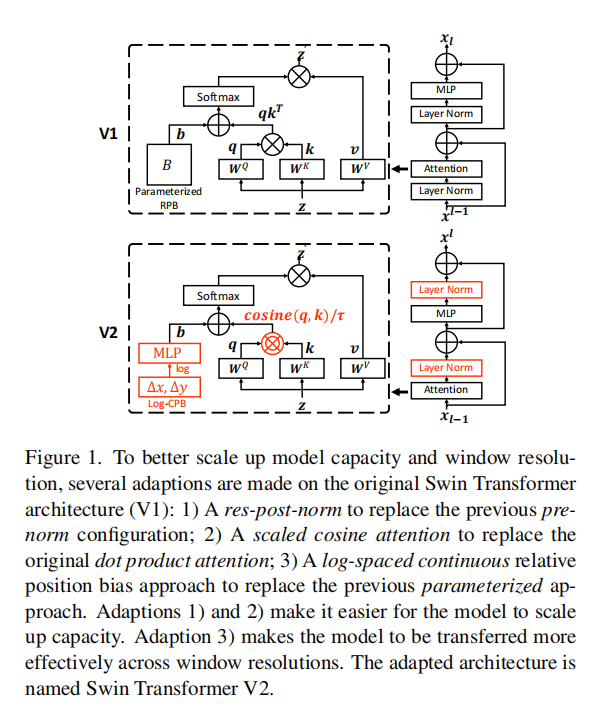
检测和语义分割需要高分辨率的输入图像或较大的注意窗口。低分辨率预训练和高分辨率微调之间的窗口大小变化可能相当大。目前常见的做法是对位置偏置映射[22,46]进行双三次插值。这个简单的修复是有些特别的,而且结果通常是次优的。我们引入了一个对数间隔的连续位置偏差(Log-CPB),它通过对对数间隔的坐标输入应用一个小的元网络来生成任意坐标范围的偏差值。由于元网络可以处理任何坐标,所以一个预先训练好的模型将能够通过共享元网络的权值来自由地跨窗口大小进行传输。我们的方法的一个关键设计是将坐标转换为对数空间,这样即使目标窗口大小明显大于训练前,外推比也可以很低。模型容量和分辨率的扩大也导致了现有视觉模型的高GPU内存消耗。为了解决内存问题,我们结合了几个重要的技术,包括zero-optimizer[54],activation checkpointing [12]和一个新的sequential self-attention computation
的实现。使用这些方法,大模型和分辨率的GPU内存消耗显著降低,而对训练速度的影响很小。
3. Swin Transformer V2
3.1. A Brief Review of Swin Transformer
在扩大模型容量和窗口分辨率方面存在的问题:
在扩大模型容量时出现的不稳定性问题。如图2所示,当我们将原始的Swin transformer模型从小尺寸扩展到大尺寸时,更深层的激活值显著增加。最高振幅和最低振幅层之间的差异达到了极值10^4。当我们进一步扩展到一个巨大的规模(6.58亿个参数)时,它无法完成训练,如图3所示。


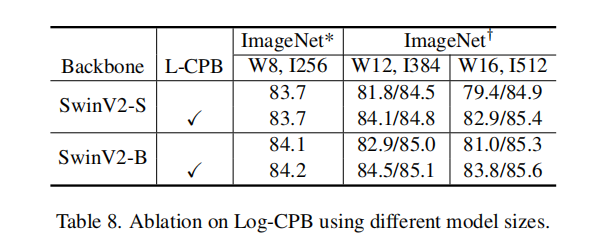
在跨窗口分辨率传输模型时,性能下降。如表1第一行所示,当我们通过双立方插值方法直接测试预先训练好的ImageNet-1K模型(256×256×,8×8窗口尺寸)在更大的图像分辨率和窗口尺寸下的精度时,精度显著下降。有必要重新研究相对位置偏差方法
3.2. Scaling Up Model Capacity
如第3.1节所述,原始的Swin变压器(和大多数视觉变压器)在每个块的开始都采用了一层规范层,继承了ViT。当我们扩大模型容量时,在更深的层次上观察到激活值的显著增加。实际上,在预归一化配置中,每个残差块的输出激活值直接合并到主分支,并且主分支的振幅在更深的层次上越来越大。不同层的振幅差异较大,导致训练不稳定。
Post normalization 为了缓解这个问题,我们建议在残差连接后进行标准化,如图1所示。在这种方法中,每个残差块的输出在合并回主分支之前被归一化,当层越深时,主分支的振幅不会累积。如图2所示,这种方法的激活振幅比原始的预归一化配置要温和得多。
在我们最大的模型训练中,我们每6个transformer块在主分支上引入一个额外的层归一化层,以进一步稳定训练。
Scaled cosine attention 在原始的自注意计算中,像素对的相似度项被计算为query和key向量的点积。我们发现,当这种方法用于大型视觉模型时,一些block和head的注意力经常被少数像素对所主导,特别是在res-post-norm配置中。为了缓解这个问题,我们提出了一种缩放余弦注意方法,通过缩放余弦函数计算像素对i和j的注意logit:

其中,是像素i和像素j之间的相对位置偏差;τ是一个可学习的标量,在头部和层之间不共享。τ被设置为大于0.01。余弦函数是自然归一化,因此可以有较温和的注意值。
3.3. Scaling Up Window Resolution
在本小节中,我们引入了一种对数间隔的连续位置偏差方法,以便相对位置偏差可以在窗口分辨率之间平滑地转移。
Continuous relative position bias 连续位置偏差方法没有直接优化参数化偏差,而是在相对坐标上采用了一个小的元网络:

其中G是一个小网络,例如,一个2层MLP,默认之间有一个ReLU激活。
元网络G为任意的相对坐标生成偏差值,因此可以自然地转移到具有任意变化的窗口大小的微调任务中。在推理中,可以预先计算每个相对位置的偏差值,并作为模型参数存储,使推理与原始参数化偏差方法相同。
Log-spaced coordinates 当跨很大程度上不同的窗口大小进行传输时,需要外推大部分相对坐标范围。为了缓解这个问题,我们建议使用对数间隔的坐标,而不是原来的线性间隔的坐标:

其中,∆x、∆y和∆cx、∆cy分别为线性尺度坐标和对数间隔坐标。通过使用对数间隔坐标,当我们在窗口分辨率之间转移相对位置偏差时,所需的外推比将比使用原始的线性间隔坐标要小得多。
3.4. Self-Supervised Pre-training
为了解决transformer对数据量的需求,我们利用了一种自监督的预训练方法,SimMIM [72],来缓解对标签数据的需求。
3.5. Implementation to Save GPU Memory
另一个问题是,当容量和分辨率都很大时,常规GPU无法支持其内存消耗。为了解决内存问题,我们采用了以下实现:
Zero-Redundancy Optimizer (ZeRO) [54]. 在优化器的一般数据并行实现中,模型参数和优化状态被广播到每个GPU。这种实现对GPU内存消耗非常不友好,例如,当使用AdamW优化器和fp32时,一个包含30亿个参数的模型将消耗48G GPU内存。使用ZeRO优化器,模型参数和相应的优化状态将被分割并分配到多个gpu中,这大大降低了内存消耗。我们采用了深度速度框架,并在实验中使用了在stage 1使用ZeRO。这种优化对训练速度的影响不大。
Activation check-pointing [12]. transformer层中的特征图也消耗了大量的GPU内存,当图像和窗口分辨率较高时,这可能会造成瓶颈。 Activation check-pointing [12].技术可以显著降低内存消耗,而训练速度要慢30%。
Sequential self-attention computation. 例如,为了在非常大的分辨率上训练大型模型,一个1536×1536分辨率的图像,窗口大小为32×32,常规的A100gpu(40GB内存)仍然负担不起,即使使用上述两种优化技术。我们发现,在这种情况下,自注意模块构成了一个瓶颈。为了缓解这一问题,我们按顺序实现了自注意计算,而不是使用之前的批处理计算方法。这种优化应用于前两个阶段的层,对整体训练速度的影响很小。
3.6. Model confifigurations


4. Experiments
4.2. Scaling Up Experiments
ImageNet-1K image classifification results

COCO object detection results

ADE20K semantic segmentation results

Kinetics-400 video action classifification results

4.3. Ablation Study
Ablation on res-post-norm and scaled cosine attention
post-norm和余弦注意力提升了模型的性能,更重要的是,他使模型稳定下来。

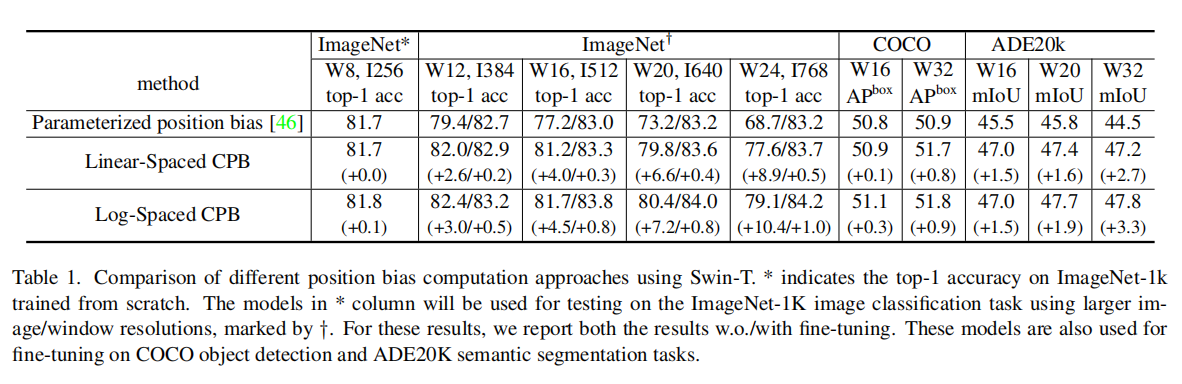
Scaling up window resolution by different approaches
1)不同的方法在训练前(81.7%-81.8%)中具有相似的准确性;2)当转移到下游任务时,两种连续位置偏差(CPB)方法的表现始终优于Swin transformer V1中使用的参数化位置偏差方法。与线性间隔方法相比,对数间隔版本略好一些;3)训练前和微调之间的分辨率变化越大,所提出的对数间隔CPB方法的好处就越大。






![F. Rats Rats(二分 or 预处理)[UTPC Contest 09-02-22 Div. 2 (Beginner)]](https://img-blog.csdnimg.cn/5a2fa1b3bf534b3e96f29aed3ba9f5b2.png)