MapReduce定义
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件组合成一个完整的分布式运算程序,并发运行在hadoop集群上
MapReduce的优缺点
优点
- 易于编程:用户只关心业务逻辑代码
- 扩展性:可以动态增加服务器,解决计算资源不足问题
- 高容错性:任何一台挂掉,可以将任务转移到其他节点
- 适合海量数据的计算(TB/PB级别)
缺点
- 不擅长实时计算
- 不擅长流式计算
- 不擅长DAG有向无环图计算
编写一个MapReduce程序
pom
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency></dependencies>Map
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @ClassName WordCountMapper* @Description TODO* @Date 2022/10/25 9:39* @Version 1.0* KEYIN, 输入偏移量作为key* VALUEIN,内容作为value* KEYOUT, 值作为key* VALUEOUT 次数作为value,每次都是1*/
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {private Text outK = new Text();private IntWritable outV = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String word : words) {outK.set(word);context.write(outK,outV);}}
}
reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @ClassName WordCountReducer* @Description TODO* @Date 2022/10/25 9:40* @Version 1.0* KEYIN, text* VALUEIN,* KEYOUT,* VALUEOUT*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private IntWritable outV = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for (IntWritable value : values) {count+=value.get();}outV.set(count);context.write(key,outV);}
}
driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @ClassName WordCountDriver* @Description TODO* @Date 2022/10/25 9:40* @Version 1.0*/
public class WordCountDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1 获取jobConfiguration configuration = new Configuration();Job job = Job.getInstance(configuration);//2 设置jar包路径job.setJarByClass(WordCountDriver.class);//3 关联mapper的reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);//4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//5 设置最终输出的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\centos\\hadinput"));FileOutputFormat.setOutputPath(job, new Path("D:\\centos\\hadout"));//7 踢几脚jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
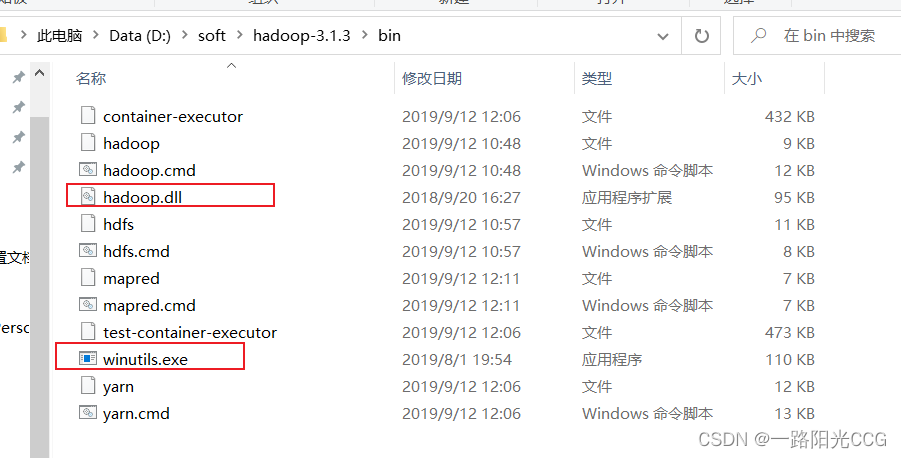
会报错,因为本地hadoop环境变量没配置,这里我使用的是3.1.3版本,因此需要下载hadoop3.1.3,
配置完成之后打开cmd

然后找到两个配置文件放入hadoop的bin目录下