一、Apache HBase API
Apache HBase也适用于多个外部API。有关更多信息,请参阅Apache HBase外部API(将在下一节的内容中介绍)。
有关使用本机HBase API的信息,请参阅User API Reference和HBase API章节。
示例:
使用Java创建、修改和删除表:
package com.example.hbase.admin;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;public class Example {private static final String TABLE_NAME = "MY_TABLE_NAME_TOO";private static final String CF_DEFAULT = "DEFAULT_COLUMN_FAMILY";public static void createOrOverwrite(Admin admin, HTableDescriptor table) throws IOException {if (admin.tableExists(table.getTableName())) {admin.disableTable(table.getTableName());admin.deleteTable(table.getTableName());}admin.createTable(table);}public static void createSchemaTables(Configuration config) throws IOException {try (Connection connection = ConnectionFactory.createConnection(config);Admin admin = connection.getAdmin()) {HTableDescriptor table = new HTableDescriptor(TableName.valueOf(TABLE_NAME));table.addFamily(new HColumnDescriptor(CF_DEFAULT).setCompressionType(Algorithm.NONE));System.out.print("Creating table. ");createOrOverwrite(admin, table);System.out.println(" Done.");}}public static void modifySchema (Configuration config) throws IOException {try (Connection connection = ConnectionFactory.createConnection(config);Admin admin = connection.getAdmin()) {TableName tableName = TableName.valueOf(TABLE_NAME);if (!admin.tableExists(tableName)) {System.out.println("Table does not exist.");System.exit(-1);}HTableDescriptor table = admin.getTableDescriptor(tableName);// Update existing tableHColumnDescriptor newColumn = new HColumnDescriptor("NEWCF");newColumn.setCompactionCompressionType(Algorithm.GZ);newColumn.setMaxVersions(HConstants.ALL_VERSIONS);admin.addColumn(tableName, newColumn);// Update existing column familyHColumnDescriptor existingColumn = new HColumnDescriptor(CF_DEFAULT);existingColumn.setCompactionCompressionType(Algorithm.GZ);existingColumn.setMaxVersions(HConstants.ALL_VERSIONS);table.modifyFamily(existingColumn);admin.modifyTable(tableName, table);// Disable an existing tableadmin.disableTable(tableName);// Delete an existing column familyadmin.deleteColumn(tableName, CF_DEFAULT.getBytes("UTF-8"));// Delete a table (Need to be disabled first)admin.deleteTable(tableName);}}public static void main(String... args) throws IOException {Configuration config = HBaseConfiguration.create();//Add any necessary configuration files (hbase-site.xml, core-site.xml)config.addResource(new Path(System.getenv("HBASE_CONF_DIR"), "hbase-site.xml"));config.addResource(new Path(System.getenv("HADOOP_CONF_DIR"), "core-site.xml"));createSchemaTables(config);modifySchema(config);}
}1、HBase:REST服务器
1)REST
REST代表状态转移,它于2000年在Roy Fielding的博士论文中引入,他是HTTP规范的主要作者之一。
REST本身超出了本文档的范围,但通常,REST允许通过与URL本身绑定的API进行客户端-服务器交互。本节讨论如何配置和运行HBase附带的REST服务器,该服务器将HBase表,行,单元和元数据作为URL指定的资源公开。
2)启动和停止REST服务器
包含的REST服务器可以作为守护程序运行,该守护程序启动嵌入式Jetty servlet容器并将servlet部署到其中。使用以下命令之一在前台或后台启动REST服务器。端口是可选的,默认为8080。
# Foreground
$ bin/hbase rest start -p <port># Background, logging to a file in $HBASE_LOGS_DIR
$ bin/hbase-daemon.sh start rest -p <port>要停止REST服务器,请在前台运行时使用Ctrl-C,如果在后台运行则使用以下命令。
$ bin/hbase-daemon.sh stop rest3)配置REST服务器和客户端
有关为SSL配置REST服务器和客户端以及为REST服务器配置doAs模拟的信息,请参阅配置Thrift网关以代表客户端进行身份验证以及Securing Apache HBase章节的其他部分。
使用REST端点
以下示例使用占位符服务器http://example.com:8000,并且可以使用curl或wget命令运行以下命令。您可以通过不为纯文本添加头信息来请求纯文本(默认),XML或JSON输出,或者为XML添加头信息“Accept:text / xml”,为JSON添加“Accept:application / json”或为协议缓冲区添加“Accept: application/x-protobuf”。
除非指定,否则使用GET请求进行查询,PUT或POST请求进行创建或修改,DELETE用于删除。
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /version/cluster | GET | 在此群集上运行的HBase版本 | curl -vi -X GET \-H "Accept: text/xml" \"http://example.com:8000/version/cluster" |
| /status/cluster | GET | 群集状态 | curl -vi -X GET \-H "Accept: text/xml" \"http://example.com:8000/status/cluster" |
| / | GET | 所有非系统表的列表 | |
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /namespaces | GET | 列出所有命名空间 | |
| /namespaces/namespace | GET | 描述特定的命名空间 | |
| /namespaces/namespace | POST | 创建一个新的命名空间 | |
| /namespaces/namespace/tables | GET | 列出特定命名空间中的所有表 | |
| /namespaces/namespace | PUT | 更改现有命名空间。目前尚未使用 | |
| /namespaces/namespace | DELETE | 删除命名空间。命名空间必须为空 | |
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /table/schema | GET | 描述指定表的架构 | |
| /table/schema | POST | 使用提供的架构片段更新现有表 | |
| /table/schema | PUT | 创建新表,或替换现有表的架构 | |
| /table/schema | DELETE | 删除表格。您必须使用端点/table/schema/,而不仅仅是table/ | |
| /table/regions | GET | 列出表区域 | |
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /table/row | GET | 获取单行的所有列。值为Base-64编码。这需要“Accept”请求标头,其类型可以包含多个列(如xml,json或protobuf)。 | |
| /table/row/column:qualifier/timestamp | GET | 获取单个列的值。值为Base-64编码。 | |
| /table/row/column:qualifier | GET | 获取单个列的值。值为Base-64编码。 | |
| /table/row/column:qualifier/?v=number_of_versions | GET | Multi-获取给定单元格的指定数量的版本。值为Base-64编码。 | |
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /table/scanner/ | PUT | 获取Scanner对象。所有其他扫描操作都需要。将批处理参数调整为扫描应在批处理中返回的行数。请参阅下一个向扫描仪添加过滤器的示例。扫描程序端点URL将作为HTTP响应中的Location返回。此表中的其他示例假定扫描程序端点为:http://example.com:8000/users/scanner/145869072824375522207。 | |
| /table/scanner/ | PUT | 要向扫描仪对象提供过滤器或以任何其他方式配置扫描仪,您可以创建文本文件并将过滤器添加到文件中。例如,要仅返回以<codeph> u123 </ codeph>开头并使用批量大小为100的行,过滤器文件将如下所示: [source,xml] ---- <Scanner batch =“100”> <filter> {“type”:“PrefixFilter”,“value”:“u123”} </ filter> </ Scanner> ---- 将文件传递给curl请求的-d参数。 | |
| /table/scanner/scanner-id | GET | 从扫描仪获取下一批。单元格值是字节编码的。如果扫描仪已耗尽,则返回HTTP状态204。 | |
| table/scanner/scanner-id | DELETE | 删除扫描仪并释放它使用的资源。 | |
| 端点 | HTTP动词 | 描述 | 示例 |
|---|---|---|---|
| /table/row_key | PUT | 在表中写一行。行、列限定符和值必须均为Base-64编码。要对字符串进行编码,请使用base64命令行实用程序。要解码字符串,请使用base64 -d。有效负载位于--data参数中,/users/fakerow值为占位符。通过将多行添加到<CellSet>元素中来插入多行。您还可以将要插入的数据保存到文件中,并使用-d @filename.txt语法将其传递给参数-d。 | |
4)REST XML架构
<schema xmlns="http://www.w3.org/2001/XMLSchema" xmlns:tns="RESTSchema"><element name="Version" type="tns:Version"></element><complexType name="Version"><attribute name="REST" type="string"></attribute><attribute name="JVM" type="string"></attribute><attribute name="OS" type="string"></attribute><attribute name="Server" type="string"></attribute><attribute name="Jersey" type="string"></attribute></complexType><element name="TableList" type="tns:TableList"></element><complexType name="TableList"><sequence><element name="table" type="tns:Table" maxOccurs="unbounded" minOccurs="1"></element></sequence></complexType><complexType name="Table"><sequence><element name="name" type="string"></element></sequence></complexType><element name="TableInfo" type="tns:TableInfo"></element><complexType name="TableInfo"><sequence><element name="region" type="tns:TableRegion" maxOccurs="unbounded" minOccurs="1"></element></sequence><attribute name="name" type="string"></attribute></complexType><complexType name="TableRegion"><attribute name="name" type="string"></attribute><attribute name="id" type="int"></attribute><attribute name="startKey" type="base64Binary"></attribute><attribute name="endKey" type="base64Binary"></attribute><attribute name="location" type="string"></attribute></complexType><element name="TableSchema" type="tns:TableSchema"></element><complexType name="TableSchema"><sequence><element name="column" type="tns:ColumnSchema" maxOccurs="unbounded" minOccurs="1"></element></sequence><attribute name="name" type="string"></attribute><anyAttribute></anyAttribute></complexType><complexType name="ColumnSchema"><attribute name="name" type="string"></attribute><anyAttribute></anyAttribute></complexType><element name="CellSet" type="tns:CellSet"></element><complexType name="CellSet"><sequence><element name="row" type="tns:Row" maxOccurs="unbounded" minOccurs="1"></element></sequence></complexType><element name="Row" type="tns:Row"></element><complexType name="Row"><sequence><element name="key" type="base64Binary"></element><element name="cell" type="tns:Cell" maxOccurs="unbounded" minOccurs="1"></element></sequence></complexType><element name="Cell" type="tns:Cell"></element><complexType name="Cell"><sequence><element name="value" maxOccurs="1" minOccurs="1"><simpleType><restriction base="base64Binary"></simpleType></element></sequence><attribute name="column" type="base64Binary" /><attribute name="timestamp" type="int" /></complexType><element name="Scanner" type="tns:Scanner"></element><complexType name="Scanner"><sequence><element name="column" type="base64Binary" minOccurs="0" maxOccurs="unbounded"></element></sequence><sequence><element name="filter" type="string" minOccurs="0" maxOccurs="1"></element></sequence><attribute name="startRow" type="base64Binary"></attribute><attribute name="endRow" type="base64Binary"></attribute><attribute name="batch" type="int"></attribute><attribute name="startTime" type="int"></attribute><attribute name="endTime" type="int"></attribute></complexType><element name="StorageClusterVersion" type="tns:StorageClusterVersion" /><complexType name="StorageClusterVersion"><attribute name="version" type="string"></attribute></complexType><element name="StorageClusterStatus"type="tns:StorageClusterStatus"></element><complexType name="StorageClusterStatus"><sequence><element name="liveNode" type="tns:Node"maxOccurs="unbounded" minOccurs="0"></element><element name="deadNode" type="string" maxOccurs="unbounded"minOccurs="0"></element></sequence><attribute name="regions" type="int"></attribute><attribute name="requests" type="int"></attribute><attribute name="averageLoad" type="float"></attribute></complexType><complexType name="Node"><sequence><element name="region" type="tns:Region"maxOccurs="unbounded" minOccurs="0"></element></sequence><attribute name="name" type="string"></attribute><attribute name="startCode" type="int"></attribute><attribute name="requests" type="int"></attribute><attribute name="heapSizeMB" type="int"></attribute><attribute name="maxHeapSizeMB" type="int"></attribute></complexType><complexType name="Region"><attribute name="name" type="base64Binary"></attribute><attribute name="stores" type="int"></attribute><attribute name="storefiles" type="int"></attribute><attribute name="storefileSizeMB" type="int"></attribute><attribute name="memstoreSizeMB" type="int"></attribute><attribute name="storefileIndexSizeMB" type="int"></attribute></complexType></schema>5)REST Protobufs架构
message Version {optional string restVersion = 1;optional string jvmVersion = 2;optional string osVersion = 3;optional string serverVersion = 4;optional string jerseyVersion = 5;
}message StorageClusterStatus {message Region {required bytes name = 1;optional int32 stores = 2;optional int32 storefiles = 3;optional int32 storefileSizeMB = 4;optional int32 memstoreSizeMB = 5;optional int32 storefileIndexSizeMB = 6;}message Node {required string name = 1; // name:portoptional int64 startCode = 2;optional int32 requests = 3;optional int32 heapSizeMB = 4;optional int32 maxHeapSizeMB = 5;repeated Region regions = 6;}// node statusrepeated Node liveNodes = 1;repeated string deadNodes = 2;// summary statisticsoptional int32 regions = 3;optional int32 requests = 4;optional double averageLoad = 5;
}message TableList {repeated string name = 1;
}message TableInfo {required string name = 1;message Region {required string name = 1;optional bytes startKey = 2;optional bytes endKey = 3;optional int64 id = 4;optional string location = 5;}repeated Region regions = 2;
}message TableSchema {optional string name = 1;message Attribute {required string name = 1;required string value = 2;}repeated Attribute attrs = 2;repeated ColumnSchema columns = 3;// optional helpful encodings of commonly used attributesoptional bool inMemory = 4;optional bool readOnly = 5;
}message ColumnSchema {optional string name = 1;message Attribute {required string name = 1;required string value = 2;}repeated Attribute attrs = 2;// optional helpful encodings of commonly used attributesoptional int32 ttl = 3;optional int32 maxVersions = 4;optional string compression = 5;
}message Cell {optional bytes row = 1; // unused if Cell is in a CellSetoptional bytes column = 2;optional int64 timestamp = 3;optional bytes data = 4;
}message CellSet {message Row {required bytes key = 1;repeated Cell values = 2;}repeated Row rows = 1;
}message Scanner {optional bytes startRow = 1;optional bytes endRow = 2;repeated bytes columns = 3;optional int32 batch = 4;optional int64 startTime = 5;optional int64 endTime = 6;
}2、将Java数据对象(JDO)与HBase一起使用
Java数据对象(JDO)是一种访问数据库中持久数据的标准方法,使用普通的旧Java对象(POJO)来表示持久数据。
此代码示例具有以下依赖项:
- HBase 0.90.x或更高版本
- commons-beanutils.jar(https://commons.apache.org/)
- commons-pool-1.5.5.jar(https://commons.apache.org/)
- transactional-tableindexed for HBase 0.90(https://github.com/hbase-trx/hbase-transactional-tableindexed)
下载 hbase-jdo
从http://code.google.com/p/hbase-jdo/下载代码。
JDO示例
此示例使用JDO创建一个表和一个索引,在表中插入行,获取行,获取列值,执行查询以及执行一些其他HBase操作。
package com.apache.hadoop.hbase.client.jdo.examples;import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.Hashtable;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.tableindexed.IndexedTable;import com.apache.hadoop.hbase.client.jdo.AbstractHBaseDBO;
import com.apache.hadoop.hbase.client.jdo.HBaseBigFile;
import com.apache.hadoop.hbase.client.jdo.HBaseDBOImpl;
import com.apache.hadoop.hbase.client.jdo.query.DeleteQuery;
import com.apache.hadoop.hbase.client.jdo.query.HBaseOrder;
import com.apache.hadoop.hbase.client.jdo.query.HBaseParam;
import com.apache.hadoop.hbase.client.jdo.query.InsertQuery;
import com.apache.hadoop.hbase.client.jdo.query.QSearch;
import com.apache.hadoop.hbase.client.jdo.query.SelectQuery;
import com.apache.hadoop.hbase.client.jdo.query.UpdateQuery;/*** Hbase JDO Example.** dependency library.* - commons-beanutils.jar* - commons-pool-1.5.5.jar* - hbase0.90.0-transactionl.jar** you can expand Delete,Select,Update,Insert Query classes.**/
public class HBaseExample {public static void main(String[] args) throws Exception {AbstractHBaseDBO dbo = new HBaseDBOImpl();//*drop if table is already exist.*if(dbo.isTableExist("user")){dbo.deleteTable("user");}//*create table*dbo.createTableIfNotExist("user",HBaseOrder.DESC,"account");//dbo.createTableIfNotExist("user",HBaseOrder.ASC,"account");//create index.String[] cols={"id","name"};dbo.addIndexExistingTable("user","account",cols);//insertInsertQuery insert = dbo.createInsertQuery("user");UserBean bean = new UserBean();bean.setFamily("account");bean.setAge(20);bean.setEmail("ncanis@gmail.com");bean.setId("ncanis");bean.setName("ncanis");bean.setPassword("1111");insert.insert(bean);//select 1 rowSelectQuery select = dbo.createSelectQuery("user");UserBean resultBean = (UserBean)select.select(bean.getRow(),UserBean.class);// select column value.String value = (String)select.selectColumn(bean.getRow(),"account","id",String.class);// search with option (QSearch has EQUAL, NOT_EQUAL, LIKE)// select id,password,name,email from account where id='ncanis' limit startRow,20HBaseParam param = new HBaseParam();param.setPage(bean.getRow(),20);param.addColumn("id","password","name","email");param.addSearchOption("id","ncanis",QSearch.EQUAL);select.search("account", param, UserBean.class);// search column value is existing.boolean isExist = select.existColumnValue("account","id","ncanis".getBytes());// update password.UpdateQuery update = dbo.createUpdateQuery("user");Hashtable<String, byte[]> colsTable = new Hashtable<String, byte[]>();colsTable.put("password","2222".getBytes());update.update(bean.getRow(),"account",colsTable);//deleteDeleteQuery delete = dbo.createDeleteQuery("user");delete.deleteRow(resultBean.getRow());// etc// HTable pool with apache commons pool// borrow and release. HBasePoolManager(maxActive, minIdle etc..)IndexedTable table = dbo.getPool().borrow("user");dbo.getPool().release(table);// upload bigFile by hadoop directly.HBaseBigFile bigFile = new HBaseBigFile();File file = new File("doc/movie.avi");FileInputStream fis = new FileInputStream(file);Path rootPath = new Path("/files/");String filename = "movie.avi";bigFile.uploadFile(rootPath,filename,fis,true);// receive file stream from hadoop.Path p = new Path(rootPath,filename);InputStream is = bigFile.path2Stream(p,4096);}
}3、HBase与Scala一起使用
1)Scala
设置类路径:
要将Scala与HBase一起使用,您的CLASSPATH必须包含HBase的类路径以及代码所需的Scala JAR。首先,在运行HBase RegionServer进程的服务器上使用以下命令,以获取HBase的类路径。
$ ps aux |grep regionserver| awk -F 'java.library.path=' {'print $2'} | awk {'print $1'}/usr/lib/hadoop/lib/native:/usr/lib/hbase/lib/native/Linux-amd64-64设置$CLASSPATH环境变量以包括您在上一步中找到的路径,以及项目所需的scala-library.jar路径和每个与Scala相关的其他JAR。
$ export CLASSPATH=$CLASSPATH:/usr/lib/hadoop/lib/native:/usr/lib/hbase/lib/native/Linux-amd64-64:/path/to/scala-library.jar2)Scala SBT文件
您的build.sbt文件需要以下解析程序和libraryDependencies才能与HBase一起使用。
resolvers += "Apache HBase" at "https://repository.apache.org/content/repositories/releases"resolvers += "Thrift" at "https://people.apache.org/~rawson/repo/"libraryDependencies ++= Seq("org.apache.hadoop" % "hadoop-core" % "0.20.2","org.apache.hbase" % "hbase" % "0.90.4"
)3)Scala代码示例
此示例列出HBase表,创建新表并向其添加行:
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Connection,ConnectionFactory,HBaseAdmin,HTable,Put,Get}
import org.apache.hadoop.hbase.util.Bytesval conf = new HBaseConfiguration()
val connection = ConnectionFactory.createConnection(conf);
val admin = connection.getAdmin();// list the tables
val listtables=admin.listTables()
listtables.foreach(println)// let's insert some data in 'mytable' and get the rowval table = new HTable(conf, "mytable")val theput= new Put(Bytes.toBytes("rowkey1"))theput.add(Bytes.toBytes("ids"),Bytes.toBytes("id1"),Bytes.toBytes("one"))
table.put(theput)val theget= new Get(Bytes.toBytes("rowkey1"))
val result=table.get(theget)
val value=result.value()
println(Bytes.toString(value))4、HBase与Jython一起使用
1)Jython
设置类路径
要将Jython与HBase 一起使用,您的 CLASSPATH 必须包含 HBase 的类路径以及代码所需的 Jython JAR。
将路径设置为包含 Jython .jar 的目录,以及每个项目需要的附加的 Jython 相关 JAR。然后导出指向$ JYTHON_HOME 环境变量的 HBASE_CLASSPATH。
$ export HBASE_CLASSPATH=/directory/jython.jar在类路径中使用 HBase 和 Hadoop JAR 启动 Jython shell:$ bin / hbase org.python.util.jython
2)Jython 代码示例
使用 Jython 创建表,填充,获取和删除表
以下 Jython 代码示例检查表,如果存在,则删除它然后创建它。然后,它使用数据填充表并获取数据。
import java.lang
from org.apache.hadoop.hbase import HBaseConfiguration, HTableDescriptor, HColumnDescriptor, TableName
from org.apache.hadoop.hbase.client import Admin, Connection, ConnectionFactory, Get, Put, Result, Table
from org.apache.hadoop.conf import Configuration# First get a conf object. This will read in the configuration
# that is out in your hbase-*.xml files such as location of the
# hbase master node.
conf = HBaseConfiguration.create()
connection = ConnectionFactory.createConnection(conf)
admin = connection.getAdmin()# Create a table named 'test' that has a column family
# named 'content'.
tableName = TableName.valueOf("test")
table = connection.getTable(tableName)desc = HTableDescriptor(tableName)
desc.addFamily(HColumnDescriptor("content"))# Drop and recreate if it exists
if admin.tableExists(tableName):admin.disableTable(tableName)admin.deleteTable(tableName)admin.createTable(desc)# Add content to 'column:' on a row named 'row_x'
row = 'row_x'
put = Put(row)
put.addColumn("content", "qual", "some content")
table.put(put)# Now fetch the content just added, returns a byte[]
get = Get(row)result = table.get(get)
data = java.lang.String(result.getValue("content", "qual"), "UTF8")print "The fetched row contains the value '%s'" % data3)使用 Jython 进行表扫描
此示例扫描表并返回与给定族限定符匹配的结果。
import java.lang
from org.apache.hadoop.hbase import TableName, HBaseConfiguration
from org.apache.hadoop.hbase.client import Connection, ConnectionFactory, Result, ResultScanner, Table, Admin
from org.apache.hadoop.conf import Configuration
conf = HBaseConfiguration.create()
connection = ConnectionFactory.createConnection(conf)
admin = connection.getAdmin()
tableName = TableName.valueOf('wiki')
table = connection.getTable(tableName)cf = "title"
attr = "attr"
scanner = table.getScanner(cf)
while 1:result = scanner.next()if not result:breakprint java.lang.String(result.row), java.lang.String(result.getValue(cf, attr))二、Thrift API和过滤器语言
1、Thrift API和过滤器语言简介
Apache Thrift是一个跨平台的跨语言开发框架。HBase包含Thrift API和过滤器语言。Thrift API依赖于客户端和服务器进程。
您可以在服务器端和客户端为安全身份验证配置Thrift,方法可以参照“用于安全操作的客户端配置:Thrift Gateway”以及“配置Thrift网关以代表客户端进行身份验证”两节的内容进行操作。
本章的其余部分讨论了Thrift API提供的过滤器语言。
过滤语言
在HBase 0.92中引入了Thrift Filter Language。它允许您在通过Thrift或HBase shell访问HBase时执行服务器端筛选。您可以使用shell中的scan help命令找到有关shell集成的更多信息。
您将过滤器指定为字符串,在服务器上解析该过滤器以构造过滤器。
2、HBase:常规过滤字符串语法
一个简单的过滤表达式表示为一个字符串,如下所示:
“FilterName (argument, argument,... , argument)”请记住以下语法准则:
- 指定过滤器的名称,后跟括号中以逗号分隔的参数列表。
- 如果参数表示字符串,则应将其括在单引号(')中。
- 表示布尔值,整数或比较运算符(例如:<,>或!=)的参数不应包含在引号中
- 过滤器名称必须是单个单词。除空格,单引号和括号外,允许使用所有ASCII字符。
- 过滤器的参数可以包含任何ASCII字符。如果参数中存在单引号,则必须通过附加的前一个单引号对其进行转义。
3、复合过滤器和运算符
二元运算符
AND
如果使用AND运算符,则键值必须满足两个过滤器。
OR
如果使用OR运算符,则键值必须满足至少一个过滤器。
一元运算符
SKIP
对于特定行,如果任何键值未通过过滤条件,则跳过整行。
WHILE
对于特定行,将发出键值,直到达到未通过过滤条件的键值。
示例-复合运算符
您可以组合多个运算符来创建过滤器层次结构,例如以下示例:
(Filter1 AND Filter2) OR (Filter3 AND Filter4)4、HBase:过滤器计算顺序
计算顺序:
- 括号具有最高优先级。
- 然后是一元运算符SKIP和WHILE,并具有相同的优先级。
- 接着是二元运算符,其中AND优先级最高,其次是OR。
优先级示例:
Filter1 AND Filter2 OR Filter
is evaluated as
(Filter1 AND Filter2) OR Filter3Filter1 AND SKIP Filter2 OR Filter3
is evaluated as
(Filter1 AND (SKIP Filter2)) OR Filter3您可以使用括号明确的控制计算顺序。
5、HBase:过滤器比较运算符
比较运算符:
在HBase中提供了以下的比较运算符:
- LESS(<)
- LESS_OR_EQUAL(⇐)
- EQUAL(=)
- NOT_EQUAL(!=)
- GREATER_OR_EQUAL(> =)
- GREATER(>)
- NO_OP(无操作)
客户端应使用符号(<,⇐,=,!=,>,> =)来表示比较运算符。
6、HBase比较器
HBase比较器可以是以下任何一种:
- BinaryComparator - 使用Bytes.compareTo(byte[], byte[])比较指定的字节数组
- BinaryPrefixComparator - 按字典顺序与指定的字节数组进行比较。它只比较该字节数组的长度。
- RegexStringComparator - 使用给定的正则表达式与指定的字节数组进行比较。只有EQUAL和NOT_EQUAL比较对此比较器有效
- SubStringComparator - 测试给定的子字符串是否出现在指定的字节数组中。比较不区分大小写。只有EQUAL和NOT_EQUAL比较对此比较器有效
比较器的一般语法是: ComparatorType:ComparatorValue
各种比较器的ComparatorType如下:
- BinaryComparator -二进制
- BinaryPrefixComparator - binaryprefix
- RegexStringComparator - regexstring
- SubStringComparator - substring
ComparatorValue可以是任何值。
示例-ComparatorValues
- binary:abc将匹配所以字典顺序大于“abc”的所有内容
- binaryprefix:abc将匹配前3个字符在词典上等于“abc”的所有内容
- regexstring:ab*yz将匹配所有不以“ab”开头并以“yz”结尾的内容
- substring:abc123将匹配以子串“abc123”开头的所有内容
7、HBase过滤器语言示例
使用过滤器语言的PHP客户端程序示例:
<?$_SERVER['PHP_ROOT'] = realpath(dirname(__FILE__).'/..');require_once $_SERVER['PHP_ROOT'].'/flib/__flib.php';flib_init(FLIB_CONTEXT_SCRIPT);require_module('storage/hbase');$hbase = new HBase('<server_name_running_thrift_server>', <port on which thrift server is running>);$hbase->open();$client = $hbase->getClient();$result = $client->scannerOpenWithFilterString('table_name', "(PrefixFilter ('row2') AND (QualifierFilter (>=, 'binary:xyz'))) AND (TimestampsFilter ( 123, 456))");$to_print = $client->scannerGetList($result,1);while ($to_print) {print_r($to_print);$to_print = $client->scannerGetList($result,1);}$client->scannerClose($result);
?>过滤器字符串示例:
- "PrefixFilter ('Row') AND PageFilter (1) AND FirstKeyOnlyFilter ()" 将返回符合以下条件的所有键值对:
- 包含键值的行应该有前缀Row;
- 键值必须位于表的第一行;
- 键值对必须是行中的第一个键值
- "(RowFilter (=, 'binary:Row 1') AND TimeStampsFilter (74689, 89734)) OR ColumnRangeFilter ('abc', true, 'xyz', false))"将返回符合以下两个条件的所有键值对:
- 键值位于具有行键Row 1的行中;
- 键值必须具有74689或89734的时间戳;
- 或者它必须符合以下条件:
- 键值对必须位于按字典顺序> = abc和<xyz排列的列中
- "SKIP ValueFilter (0)",如果行中的任何值不为0,则将跳过整行
8、HBase单个过滤器语法
- KeyOnlyFilter
此过滤器不带任何参数。它仅返回每个键值的关键组件。
- FirstKeyOnlyFilter
此过滤器不带任何参数。它仅返回每行的第一个键值。
- PrefixFilter
此过滤器采用一个参数 - 行键的前缀。它仅返回以指定行前缀开头的行中存在的键值
- ColumnPrefixFilter
此过滤器采用一个参数 - 列前缀。它仅返回以指定列前缀开头的列中存在的键值。列前缀的格式必须为:“qualifier”。
- MultipleColumnPrefixFilter
此过滤器采用列前缀列表。它返回以任何指定列前缀开头的列中存在的键值。每个列前缀必须采用以下形式:“qualifier”。
- ColumnCountGetFilter
此过滤器采用一个参数 - 一个限制。它返回表中的第一个限制列数。
- PageFilter
此过滤器采用一个参数 - 页面大小。它返回表中的页面大小行数。
- ColumnPaginationFilter
此过滤器有两个参数 - 限制和偏移。它返回偏移列数后的列数限制。它为所有行执行此操作。
- InclusiveStopFilter
此过滤器使用一个参数 - 要停止扫描的行键。它返回行中存在的所有键值,包括指定的行。
- TimeStampsFilter
此过滤器采用时间戳列表。它返回时间戳与任何指定时间戳匹配的键值。
- RowFilter
该过滤器采用比较运算符和比较器。它使用compare运算符将每个行键与比较器进行比较,如果比较返回true,则返回该行中的所有键值。
- 家庭过滤器
该过滤器采用比较运算符和比较器。它使用比较运算符将每个列族名称与比较器进行比较,如果比较返回true,则返回该列族中的所有单元格。
- QualifierFilter
该过滤器采用比较运算符和比较器。它使用compare运算符将每个限定符名称与比较器进行比较,如果比较返回true,则返回该列中的所有键值。
- ValueFilter
该过滤器采用比较运算符和比较器。它使用比较运算符将每个值与比较器进行比较,如果比较返回true,则返回该键值。
- DependentColumnFilter
此过滤器有两个参数 - 族和限定符。它尝试在每一行中找到此列,并返回该行中具有相同时间戳的所有键值。如果该行不包含指定的列 - 将返回该行中的任何键值。
- SingleColumnValueFilter
该过滤器采用列族,限定符,比较运算符和比较器。如果未找到指定的列 - 将发出该行的所有列。如果找到该列并且与比较器的比较返回true,则将发出该行的所有列。如果条件失败,则不会发出该行。
- SingleColumnValueExcludeFilter
此过滤器采用相同的参数,其行为与SingleColumnValueFilter相同 - 但是,如果找到该列并且条件通过,则除了测试的列值之外,将发出该行的所有列。
- ColumnRangeFilter
此过滤器仅用于选择列在minColumn和maxColumn之间的键。它还需要两个布尔变量来指示是否包含minColumn和maxColumn。
三、HBase备份与还原
1、HBase备份与还原概述
备份和还原是许多数据库提供的标准操作。有效的备份和还原策略有助于确保用户可以在发生意外故障时恢复数据。HBase备份和还原功能有助于确保使用HBase作为规范数据存储库的企业可以从灾难性故障中恢复。另一个重要功能是能够将数据库还原到特定时间点,通常称为快照。
HBase备份和还原功能可以在HBase集群中的表上创建完整备份和增量备份。完整备份是应用增量备份以构建迭代快照的基础。可以按计划运行增量备份以捕获一段时间内的更改,例如通过使用Cron任务。增量备份比完全备份更具成本效益,因为它们仅捕获自上次备份以来的更改,并且还使管理员能够将数据库还原到任何先前的增量备份。此外,如果您不想还原备份的整个数据集,则实用程序还可以启用表级数据备份和还原。
备份和还原功能是对HBase Replication(复制)功能的补充。虽然HBase复制非常适合创建数据的“hot”副本(复制数据可立即用于查询),但备份和恢复功能非常适合创建“cold”数据副本(必须采取手动步骤来恢复系统)。以前,用户只能通过ExportSnapshot功能创建完整备份。增量备份实现是对ExportSnapshot提供的先前“art”的新颖改进。
术语:
备份和还原功能引入了新术语,可用于了解控制如何在系统中流动。
- 备份(A backup):数据和元数据的逻辑单元,可以将表还原到特定时间点的状态。
- 完全备份(Full backup):一种备份类型,它在某个时间点完全封装表的内容。
- 增量备份(Incremental backup):一种备份类型,包含自完整备份以来表中的更改。
- 备份集(Backup set):用户定义的名称,用于引用可在其上执行备份的一个或多个表。
- 备份ID(Backup ID):唯一的名称,用于标识其余备份,例如,backupId_1467823988425
2、HBase备份与还原策略
1)策略
有一些常用策略可用于在您的环境中实现备份和还原。以下部分显示了如何实施这些策略并确定每种策略的潜在权衡。
此备份和还原工具尚未在启用透明数据加密(TDE)的HDFS群集上进行测试。这与开放式问题HBASE-16178有关。
2)在群集内备份
此策略将备份存储在与执行备份的位置相同的群集上。这种方法仅适用于测试,因为它不会在软件本身提供的内容之外提供任何额外的安全性。

3)使用专用群集进行备份
该策略提供了更高的容错能力,并为灾难恢复提供了途径。在此设置中,您将备份存储在单独的HDFS群集上,方法是将备份目标群集的HDFS URL提供给备份实用程序。您应该考虑备份到不同的物理位置,例如不同的数据中心。
通常,备份专用HDFS群集使用更经济的硬件配置文件来节省资金。

4)备份到云或存储供应商设备
保护HBase增量备份的另一种方法是将数据存储在属于第三方供应商且位于站点外的配置的安全服务器上。供应商可以是公共云提供商或使用Hadoop兼容文件系统(例如S3和其他与HDFS兼容的目标)的存储供应商。

HBase备份实用程序不支持备份到多个目标,解决方法是从HDFS或S3手动创建备份文件的副本。
3、HBase备份与还原的首次配置
1)首次配置步骤
本节包含为使用备份和还原功能而必须进行的必要配置更改。由于此功能大量使用YARN的MapReduce框架来并行化这些I/O重载操作,因此配置更改不仅仅局限于此hbase-site.xml。
允许YARN中的“hbase”系统用户
YARN container-executor.cfg配置文件必须具有以下属性设置:allowed.system.users = hbase。此配置文件的条目中不允许有空格。
执行第一个备份任务时,跳过此步骤将导致运行时错误。
用于备份和还原的有效container-executor.cfg文件的示例:
yarn.nodemanager.log-dirs=/var/log/hadoop/mapred
yarn.nodemanager.linux-container-executor.group=yarn
banned.users=hdfs,yarn,mapred,bin
allowed.system.users=hbase
min.user.id=500HBase特定的变化
将以下属性添加到hbase-site.xml并重新启动HBase(如果它已在运行)。
“,...”是省略号,意味着这是一个以逗号分隔的值列表,而不是应该添加到hbase-site.xml的文字文本。
<property><name>hbase.backup.enable</name><value>true</value>
</property>
<property><name>hbase.master.logcleaner.plugins</name><value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner,...</value>
</property>
<property><name>hbase.procedure.master.classes</name><value>org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager,...</value>
</property>
<property><name>hbase.procedure.regionserver.classes</name><value>org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager,...</value>
</property>
<property><name>hbase.coprocessor.region.classes</name><value>org.apache.hadoop.hbase.backup.BackupObserver,...</value>
</property>
<property><name>hbase.master.hfilecleaner.plugins</name><value>org.apache.hadoop.hbase.backup.BackupHFileCleaner,...</value>
</property>4、HBase备份和还原命令
这部分的内容包括管理员用于创建,还原和合并备份的命令行实用程序。有关检查特定备份会话详细信息的工具将在“备份映像管理”中介绍。
运行该hbase backup help <command>命令以访问联机帮助,该联机帮助提供有关命令及其选项的基本信息。以下信息将在此帮助消息中针对每个命令进行捕获。
1)创建备份映像
对于也使用Apache Phoenix的HBase群集: 包括备份中的SQL系统目录表。在需要还原HBase备份的情况下,对系统目录表的访问可以帮助您恢复Phoenix与还原的数据的互操作性。
运行备份和还原实用程序的第一步是执行完整备份,并将数据存储在与源不同的映像中。至少,您必须执行此操作才能获得基准,然后才能依赖增量备份。
以HBase超级用户身份运行以下命令:
hbase backup create <type> <backup_path>命令完成运行后,控制台将显示SUCCESS或FAILURE状态消息。SUCCESS消息包括备份ID,备份ID是HBase主机从客户端收到备份请求的Unix时间(也称为Epoch时间)。
记录在成功备份结束时出现的备份ID。如果源群集出现故障,并且您需要使用还原操作恢复数据集,则具有可用的备份ID可以节省时间。
位置命令行参数
type
要执行的备份类型:完整备份或增量备份。提醒一下,增量备份需要已完全备份。
BACKUP_PATH
该BACKUP_PATH参数指定来存储备份映像文件系统的完整URI的地方。有效的前缀是hdfs:,webhdfs:,gpfs:和s3fs :
命名命令行参数
-t <table_name [,table_name]>
要备份的以逗号分隔的表列表。如果未指定表,则备份所有表。不存在正则表达式或通配符支持; 必须明确列出所有表名。有关对表集合执行操作的详细信息,请参阅备份集(这将在之后的章节中进行介绍)。与-s选项互斥;其中一个命名选项是必需的。
-s <backup_set_name>
根据备份集确定要备份的表。有关备份集的用途和用法,请参阅使用备份集。与-t选项互斥。
-w <number_workers>
(可选)指定将数据复制到备份目标的并行工作器数。备份当前由MapReduce作业执行,因此该值对应于作业将生成的Mapper数。
-b <bandwidth_per_worker>
(可选)指定每个工作线程的带宽,以MB/秒为单位。
-d
(可选)启用“DEBUG”模式,该模式打印有关备份创建的其他日志记录。
-q <name>
(可选)允许指定应在其中执行创建备份的MapReduce作业的YARN队列的名称。此选项有助于防止备份任务从其他高重要性MapReduce作业中窃取资源。
用法示例
$ hbase backup create full hdfs://host5:8020/data/backup -t SALES2,SALES3 -w 3此命令在HDFS实例中创建两个表SALES2和SALES3的完整备份映像,这两个表在路径/data/backup中的NameNode为host5:8020。w选项指定不超过三个并行工作完成操作。
2)HBase恢复备份映像
以HBase超级用户身份运行以下命令。您只能在正在运行的HBase集群上还原备份,因为必须将数据重新分发到RegionServers才能成功完成操作。
hbase restore <backup_path> <backup_id>位置命令行参数
BACKUP_PATH
该BACKUP_PATH参数指定的地方用来存储备份映像文件系统的完整URI。有效的前缀是hdfs:,webhdfs:,gpfs:和s3fs :
备份ID
唯一标识要还原的备份映像的备份ID。
命名命令行参数
-t <table_name [,table_name]>
要还原的以逗号分隔的表列表。有关对表集合执行操作的详细信息,请参阅备份集。与-s选项互斥;其中一个命名选项是必需的。
-s <backup_set_name>
根据备份集确定要备份的表。有关备份集的用途和用法,请参阅使用备份集。与-t选项互斥。
-q <name>
(可选)允许指定应在其中执行创建备份的MapReduce作业的YARN队列的名称。此选项有助于防止备份任务从其他高重要性MapReduce作业中窃取资源。
-C
(可选)执行还原的干运行(dry-run)。会检查操作,但不执行。
-m <target_tables>
(可选)要还原到的以逗号分隔的表列表。如果未提供此选项,则使用原始表名。提供此选项时,必须提供与-t选项中相同数量的条目。
-o
(可选)如果表已存在,则覆盖还原的目标表。
用法示例
hbase backup restore /tmp/backup_incremental backupId_1467823988425 -t mytable1,mytable2此命令还原增量备份映像的两个表。在此示例中: · tmp/backup_incremental 是包含备份映像的目录的路径。· backupId_1467823988425 是备份 ID。· mytable1 和 mytable2 是要还原的备份映像中的表的名称。
此命令将恢复增量备份映像的两个表。在此示例中:
- /tmp/backup_incremental是包含备份映像的目录的路径。
- backupId_1467823988425是备份ID。
- mytable1和mytable2是要还原的备份映像中的表的名称。
3)HBase合并增量备份映像
此命令可用于将两个或多个增量备份映像合并为单个增量备份映像。这可用于将多个小型增量备份映像合并为一个较大的增量备份映像。此命令可用于将每小时增量备份合并到每日增量备份映像中,或将每日增量备份合并到每周增量备份中。
$ hbase backup merge <backup_ids>位置命令行参数
backup_ids
以逗号分隔的增量备份映像ID列表,它们将组合到单个映像中。
命名命令行参数
没有。
用法示例
$ hbase backup merge backupId_1467823988425,backupId_14678275884254)HBase使用备份集
使用备份集
备份集可以通过减少表名重复输入的数量来简化HBase数据备份和还原的管理。您可以使用该hbase backup set add命令将表分组到命名备份集中。然后,您可以使用-set选项在hbase backup create或hbase backup restore中调用备份集的名称,而不是单独列出组中的每个表。您可以拥有多个备份集。
请注意hbase backup set add命令和-set选项之间的区别:必须先运行该hbase backup set add命令,然后才能在其他命令中使用该-set选项,因为在将备份集用作快捷方式之前,必须先命名并定义备份集。
如果运行该hbase backup set add命令并指定系统上尚不存在的备份集名称,则会创建一个新集。如果使用现有备份集名称的名称的命令,则指定的表将添加到该集合中。
在此命令中,备份集名称区分大小写。
备份集的元数据存储在HBase中。如果您无法访问具有备份集元数据的原始HBase群集,则必须指定单个表名以还原数据。
要创建备份集,请以HBase超级用户身份运行以下命令:
$ hbase backup set <subcommand> <backup_set_name> <tables>备份集子命令
以下列表详细介绍了hbase backup set命令的子命令。
在hbase backup set设置完成操作后,必须输入以下子命令中的一个(且不超过一个)。此外,备份集名称在命令行实用程序中区分大小写。
add
将表[s]添加到备份集。在此参数后面指定backup_set_name值以创建备份集。
remove
从集中删除表。在tables参数中指定要删除的表。
list
列出所有备份集。
describe
显示备份集的描述。该信息包括该集是否具有完整备份或增量备份,备份的开始和结束时间以及集合中的表列表。此子命令必须位于backup_set_name值的有效值之前。
delete
删除备份集。在命令后直接输入backup_set_name选项的值hbase backup set delete。
位置命令行参数
backup_set_name
用于分配或调用备份集名称。备份集名称必须仅包含可打印字符,并且不能包含任何空格。
tables
要包含在备份集中的表(或单个表)的列表。输入表名作为逗号分隔列表。如果未指定表,则所有表都包含在集中。
在单独或远程群集的备份策略中维护区分大小写的备份集名称的日志或其他记录以及每个集合中的相应表。此信息可以帮助您在主群集失败的情况下进行。
用法示例
$ hbase backup set add Q1Data TEAM3,TEAM_4根据不同的环境,在此命令导致一个以下操作:
- 如果Q1Data备份集不存在,则创建包含表TEAM_3和TEAM_4的备份集。
- 如果Q1Data备份集已经存在,表TEAM_3和TEAM_4添加到Q1Data备份集。
5、HBase备份图像管理
该hbase backup命令有几个子命令,可帮助管理备份映像的累积。大多数生产环境都需要重复备份,因此必须使用实用程序来帮助管理备份存储库的数据。通过某些子命令,您可以查找有助于识别与搜索特定数据相关的备份的信息。您也可以删除备份映像。
本章内容详细介绍了可以帮助管理备份的hbase backup subcommand,以HBase超级用户身份运行完整的command-subcommand行。
1)HBase管理备份进度
您可以通过运行hbase backup progress命令并将备份ID指定为参数来监视另一个终端会话中正在运行的备份。
例如,以hbase超级用户身份运行以下命令以查看备份进度:
$ hbase backup progress <backup_id>位置命令行参数
backup_id
通过查看进度信息指定要监视的备份,backupId需要区分大小写。
命名命令行参数
没有。
用法示例
hbase backup progress backupId_14678239884252)HBase管理备份历史记录
此命令显示备份会话日志。每个会话的信息包括备份ID、类型(完整或增量),备份中的表、状态以及开始和结束时间。使用可选的-n参数指定要显示的备份会话数。
$ hbase backup history <backup_id>位置命令行参数
backup_id
通过查看进度信息指定要监视的备份,backupId要区分大小写。
命名命令行参数
-n <num_records>
(可选)最大备份记录数(默认值:10)。
-p <backup_root_path>
存储备份映像的完整文件系统URI。
-s <backup_set_name>
要获取其历史记录的备份集的名称。与-t选项互斥。
-t <table_name>
获取历史记录的表的名称。与-s选项互斥。
用法示例
$ hbase backup history
$ hbase backup history -n 20
$ hbase backup history -t WebIndexRecords3)HBase描述备份映像
此命令可用于获取有关特定备份映像的信息。
$ hbase backup describe <backup_id>位置命令行参数
backup_id
要描述的备份映像的ID。
命名命令行参数
没有。
用法示例
$ hbase backup describe backupId_14678239884254)HBase删除备份映像
此命令可用于删除不再需要的备份映像。
$ hbase backup delete <backup_id>位置命令行参数
backup_id
应该删除备份映像的ID。
命名命令行参数
没有。
用法示例
$ hbase backup delete backupId_14678239884255)HBase备份修复命令
此命令尝试更正由于软件错误或未处理的失败方案而存在的持久备份元数据中的任何不一致之处。虽然备份实现尝试自行更正所有错误,但在系统无法自动恢复的情况下,此工具可能是必需的。
$ hbase backup repair位置命令行参数
没有。
命名命令行参数
没有。
用法示例
$ hbase backup repair6)HBase配置密钥
备份和还原功能包括必需的和可选的配置密钥。
必需的属性
hbase.backup.enable:控制是否启用该功能,默认值为false,将此值设置为true。
hbase.master.logcleaner.plugins:清除HBase Master中的日志时调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.master.BackupLogCleaner或将其附加到当前值。
hbase.procedure.master.classes:使用Master中的Procedure框架调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager或将其附加到当前值。
hbase.procedure.regionserver.classes:使用RegionServer中的Procedure框架调用的逗号分隔的类列表。将此值设置为org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager或将其附加到当前值。
hbase.coprocessor.region.classes:在表上部署的以逗号分隔的RegionObservers列表。将此值设置为org.apache.hadoop.hbase.backup.BackupObserver或将其附加到当前值。
hbase.master.hfilecleaner.plugins:在Master上部署的以逗号分隔的HFileCleaners列表。将此值设置为org.apache.hadoop.hbase.backup.BackupHFileCleaner或将其附加到当前值。
可选属性
hbase.backup.system.ttl:hbase:backup表中数据的生存时间(默认值:forever)。此属性仅在创建hbase:backup表之前相关。当此表已存在时,使用HBase shell中的“alter”命令修改TTL。
hbase.backup.attempts.max:获取hbase表快照时执行的尝试次数(默认值:10)。
hbase.backup.attempts.pause.ms:失败的快照尝试之间等待的时间(以毫秒为单位)(默认值:10000)。
hbase.backup.logroll.timeout.millis:等待RegionServers在Master的过程框架中执行WAL滚动的时间(以毫秒为单位)(默认值:30000)。
7)HBase备份与还原的最佳做法
制定恢复策略并对其进行测试
在依赖生产环境的备份和还原策略之前,请确定必须如何执行备份,更重要的是要确定必须如何执行还原。测试计划以确保它是可行的。至少,从不同群集或服务器上的生产群集存储备份数据。要进一步保护数据,请使用位于不同物理位置的备份位置。
如果由于计算机系统问题导致主生产群集上的数据丢失不可恢复,则可以从同一站点的其他群集或服务器还原数据。但是,破坏整个站点的灾难使本地存储的备份变得毫无用处。考虑存储备份数据和必要资源(计算能力和操作员专业技能),以便在远离生产站点的站点上还原数据。如果在整个主要站点(fire,earthquake等)发生灾难的情况下,远程备份站点可能非常有价值。
首先保护完整备份映像
作为基准,您必须至少完成一次HBase数据的完整备份,然后才能依赖增量备份。完整备份应存储在源群集之外。要确保完整的数据集恢复,您必须运行恢复实用程序,并提供恢复基准完全备份的选项。完整备份是数据集的基础。在还原操作期间,增量备份数据应用于完整备份之上,以使您返回上次执行备份的时间点。
定义和使用作为整个数据集的逻辑子集的表组和备份集
您可以将表分组到称为备份集的对象中。当您拥有一组您希望重复备份或还原的特定表组时,备份集可以节省时间。
创建备份集时,可以键入要包括在组中的表名。备份集不仅包括相关表组,还保留HBase备份元数据。之后,您可以调用备份集名称来指示哪些表适用于命令执行,而不是单独输入所有表名。
记录备份和还原策略,最好记录有关每个备份的信息
记录整个过程,以便知识库可以在员工离职后转移给新的管理员。作为额外的安全预防措施,还要记录每个备份的数据的日历日期、时间以及其他相关详细信息。在源群集发生故障或主站点灾难的情况下,此元数据可能有助于查找特定数据集。维护所有文档的重复副本:一个副本位于生产集群站点,另一个副本位于备份位置,或者任何管理员可以从生产集群远程访问的地方。
8)HBase方案:在Amazon S3上保护应用程序数据集
方案:在Amazon S3上保护应用程序数据集
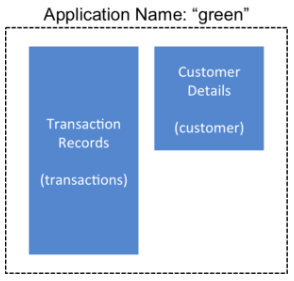
此HBase方案描述了假设的零售业务如何使用备份来保护应用程序数据, 然后在失败后还原数据集。
HBase 管理团队使用备份集来存储一组表中的数据, 它们具有一个名为绿色的应用程序的相关信息。在此示例中, 一个表包含交易记录, 另一张包含客户详细信息。需要备份这两个表并作为一个组进行恢复。
管理团队还希望确保自动进行每日备份。
以下是用于备份绿色应用程序的数据并稍后恢复数据的命令的步骤和示例的概述。以HBase超级用户身份登录时,将运行所有命令。
- 创建名为green_set的备份集作为transactions表和customer表的别名。备份集可用于所有操作,以避免键入每个表名。备份集名称区分大小写,应仅使用可打印字符且和不带空格的格式生成。
$ hbase backup set add green_set transactions $ hbase backup set add green_set customer - green_set数据的第一个备份必须是完整备份。以下命令示例显示如何将凭据传递到Amazon S3并使用s3a:前缀指定文件系统。
$ ACCESS_KEY=ABCDEFGHIJKLMNOPQRST $ SECRET_KEY=123456789abcdefghijklmnopqrstuvwxyzABCD $ sudo -u hbase hbase backup create full\s3a://$ACCESS_KEY:SECRET_KEY@prodhbasebackups/backups -s green_set - 应根据计划运行增量备份,以确保在发生灾难时进行必要的数据恢复。在这家零售公司,HBase管理团队决定自动每日备份以充分保护数据。团队决定他们可以通过修改在/etc/crontab中定义的现有Cron作业来实现此目的。因此,IT通过添加以下行来修改Cron作业:
@daily hbase hbase backup create incremental s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups -s green_set - 失败性IT事件会禁用绿色应用程序使用的生产群集。备份群集的HBase系统管理员必须将green_set数据集还原到最接近恢复目标的时间点。
如果备份HBase群集的管理员具有可访问记录中具有相关详细信息的备份ID,则可以绕过以下使用该hdfs dfs -ls命令搜索和手动扫描备份ID列表的搜索。请考虑在环境中的生产群集外部持续维护和保护备份ID的详细日志。
管理员在存储备份的目录上运行以下命令,以在控制台上打印成功备份ID的列表: -
`hdfs dfs -ls -t /prodhbasebackups/backups` - 管理员扫描列表以查看在最接近恢复目标的日期和时间创建的备份。为此,管理员将恢复时间点的日历时间戳转换为Unix时间,因为备份ID是用Unix时间唯一标识的。备份ID按反向时间顺序列出,这意味着最先出现的最新成功备份。管理员注意到命令输出中的以下行与需要还原的green_set备份相对应:
/prodhbasebackups/backups/backup_1467823988425`
管理员恢复green_set调用备份ID和-overwrite选项。-overwrite选项截断目标中的所有现有数据,并使用备份数据集中的数据填充表。如果没有此标志,备份数据将附加到目标中的现有数据。在这种情况下,管理员决定覆盖数据,因为它已损坏。
$ sudo -u hbase hbase restore -s green_set \s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups backup_1467823988425 \ -overwrite9)HBase备份数据的安全性
使用此功能可以将数据复制到远程位置,需要花点时间清楚地说明数据安全性存在的程序问题。与HBase复制功能一样,备份和还原提供了将数据从公司边界内部自动复制到该边界之外的某个系统的构造。在存储具有备份和还原功能的敏感数据时(更不用说从HBase中提取数据的任何功能),发送数据的位置都经过安全审核以确保只有经过身份验证的用户才能访问数据。
例如,对于上一节中将数据备份到S3的示例,最重要的是将适当的权限分配给S3存储桶以确保仅允许最小的一组授权用户访问该数据。由于不再通过HBase访问数据及其身份验证和授权控制,因此我们必须确保存储该数据的文件系统提供相当级别的安全性。这是用户必须自己实施的手动步骤。
10)HBase增量备份和还原的技术细节
与以前尝试使用串行备份和还原解决方案(例如仅使用HBase导出和导入API的方法)相比,HBase增量备份可以更有效地捕获HBase表映像。增量备份使用“预写日志(WAL)”来捕获自上次备份创建以来的数据更改。在所有RegionServers上执行WAL roll(创建新的WAL)以跟踪需要在备份中的WAL。
创建增量备份映像后,源备份文件通常与数据源位于同一节点上。类似于DistCp(分布式副本)工具的过程用于将源备份文件移动到目标文件系统。当表还原操作启动时,启动两个步骤的进程。首先,从完整备份映像恢复完整备份。其次,来自上次完全备份和正在恢复的增量备份之间的增量备份的所有WAL文件都将转换为HFiles,HBase批量加载实用程序会自动将其导入为表中的已还原数据。
您只能在实时的HBase群集上进行还原,因为必须重新分发数据才能成功完成还原操作。
11)HBase关于文件系统增长的警告
需要提醒的是,增量备份是通过保留HBase主要用于数据持久性的预写日志来实现的。因此,为确保需要包含在备份中的所有数据在系统中仍然可用,HBase备份和还原功能将保留自上次备份以来的所有预写日志,直到执行下一个增量备份。
与HBase快照一样,对于高容量表,这可能对HBase的HDFS使用产生预期的巨大影响。注意启用和使用备份和还原功能,尤其要注意在未主动使用备份会话时删除备份会话。
对于保留的用于备份和恢复的预写日志,惟一的自动上限是基于hbase:backup system表的TTL,在撰写本文档时,这是无限的(备份表项永远不会自动删除)。这要求管理员按照计划执行备份,该计划的频率相对于HDFS上的可用空间量(例如,较少的可用HDFS空间需要更积极的备份合并和删除)。提醒一下,可以使用HBase shell中的alter命令在hbase:backup表上更改TTL 。在系统表存在后修改hbase-site.xml中的配置属性hbase.backup.system.ttl是无效的。
12)HBase容量规划
在设计分布式系统部署时,必须执行一些基本的数学严谨性,以确保在给定系统的数据和软件要求的情况下有足够的计算能力。对于此功能,在估计某些备份和还原实施的性能时,网络容量的可用性是最大的瓶颈。第二个最昂贵的功能是可以读/写数据的速度。
完全备份
要估计完整备份的持续时间,我们必须了解调用的一般操作:
- 每个 RegionServer 上的预写日志滚动:每个 RegionServer 并行运行几十秒。相对于每个 RegionServer 的负载。
- 获取表格的HBase快照:几十秒。相对于构成表的区域和文件的数量。
- 将快照导出到目标:请参阅下文。相对于数据的大小和到到目标的网络带宽。
为了估计最后一步将花费多长时间,我们必须对硬件做出一些假设。请注意,这些对您的系统来说并不准确 - 这些是您或您的管理员为您的系统所知的数字。假设在单个节点上从 HDFS 读取数据的速度上限为 80MB / s(在该主机上运行的所有 Mapper 上),现代网络接口控制器( NIC )支持 10Gb / s,架顶式交换机可以处理 40Gb / s,集群之间的 WAN 为 10Gb / s。这意味着您只能以 1.25GB / s的速度将数据发送到远程控制器 - 这意味着参与 ExportSnapshot 的16个节点(1.25 * 1024 / 80 = 16)应该能够完全饱和集群之间的链接。由于群集中有更多节点,我们仍然可以使网络饱和,但对任何一个节点的影响较小,这有助于确保本地 SLA。如果快照的大小是 10TB,这将完全备份将花费2.5小时(10 * 1024 / 1.25 / (60 * 60) = 2.23hrs)
作为一般性声明,本地群集与远程存储之间的WAN带宽很可能是完全备份速度的最大瓶颈。
当考虑将备份的计算影响限制为“生产系统”时,可以使用可选的命令行参数对 hbase backup create: -b、-w、-q 进行重用。该 -b 选项定义每个 worker(Mapper)写入数据的带宽。该 -w 参数限制了在 DistCp 作业中生成的工作者数量。该 -q 允许指定的 YARN 队列可以可以限制生成 worker 的特定节点——这可以隔离备份工人执行复制到一组非关键节点。将 -b 和 -w 选项与前面的公式关联起来:-b 用于限制每个节点读取 80MB/s 的数据,-w 用于限制作业产生 16个worker 任务。
增量备份
就像我们为完整备份所做的那样,我们必须了解增量备份过程,以估计其运行时间和成本。
- 识别自上次完全备份或增量备份以来的新预写日志:可忽略不计。来自备份系统表的 Apriori 知识。
- 读取,过滤和写入“最小化”HFile 相当于 WAL:以写入数据的速度为主。相对于 HDFS 的写入速度。
- 将 HFiles 分配到目的地:见上文。
对于第二步,该操作的主要成本是重写数据(假设 WAL 中的大部分数据被保留)。在这种情况下,我们可以假设每个节点的聚合写入速度为 30MB / s。继续我们的 16 节点集群示例,这将需要大约 15 分钟来执行 50GB 数据(50 * 1024/60/60 = 14.2)的此步骤。启动 DistCp MapReduce 作业的时间可能会占据复制数据所需的实际时间(50 / 1.25 = 40秒)并且可以忽略。
安全备份脚本
#!/bin/bash
mydate=`date +%A`
yestoday_begin_time=`date -d $yestoday" 00:00:00" +%s`
echo $yestoday_begin_time
yestoday_end_time=`date -d $yestoday" 23:59:59" +%s`
#yestoday_end_time='1568614500'
echo $yestoday_end_time
function backup_tables
{#check if dir exist or not/do1cloud/hadoop-3.0.3/bin/hdfs dfs -ls /do1cloud/real_backup/${1}_${mydate} > /dev/null 2>&1olddir_check=$(echo $?)#if dir exist then remove the dir and mkdir new dirif [[ $olddir_check -eq 0 ]] ; thenecho ${1}_${mydate}/do1cloud/hadoop-3.0.3/bin/hdfs dfs -rm /do1cloud/real_backup/${1}_$mydate/*/do1cloud/hadoop-3.0.3/bin/hdfs dfs -rmdir /do1cloud/real_backup/${1}_${mydate}/do1cloud/hbase-2.0.5/bin/hbase org.apache.hadoop.hbase.mapreduce.Export $1 /do1cloud/real_backup/${1}_${mydate}else/do1cloud/hbase-2.0.5/bin/hbase org.apache.hadoop.hbase.mapreduce.Export $1 /do1cloud/real_backup/${1}_${mydate} 1 $yestoday_end_timefi/do1cloud/hadoop-3.0.3/bin/hdfs dfs -get /do1cloud/real_backup/${1}_${mydate} /do1cloud/do14export/fortar/${1}_${mydate}_$yestoday_end_time
}for table in `cat /opt/prodtables.txt`
dobackup_tables $table
done
echo $?"result"
nowtime=`date +'%Y-%m-%d-%H-%M-%S'`
tar -zcf /do1cloud/do14export/fortar/tables_${nowtime}.tar.gz /do1cloud/do14export/fortar/*_${mydate}*/
find /do1cloud/do14export/fortar/ -mtime +5 -exec rm -rf {} \;增量备份脚本
#!/bin/bash
mydate=`date +%A`
yestoday=`date -d "1 day ago" +"%Y-%m-%d" `
#begin tome format 2019-09-11 00:00:00
yestoday_begin_time=`date -d $yestoday" 00:00:00" +%s`
#yestoday_begin_time="1568627040"
echo $yestoday_begin_time
yestoday_end_time=`date -d $yestoday" 23:59:59" +%s`
#yestoday_end_time="1568627520"
echo $yestoday_end_time
function backup02_tables
{#check if dir exist or not/do1cloud/hadoop-3.0.3/bin/hdfs dfs -ls /do1cloud/real_backup02/${1}_${mydate} > /dev/null 2>&1olddir_check=$(echo $?)#if dir exist then remove the dir and mkdir new dirif [[ $olddir_check -eq 0 ]] ; thenecho ${1}_${mydate}/do1cloud/hadoop-3.0.3/bin/hdfs dfs -rm /do1cloud/real_backup02/${1}_$mydate/*/do1cloud/hadoop-3.0.3/bin/hdfs dfs -rmdir /do1cloud/real_backup02/${1}_${mydate}/do1cloud/hbase-2.0.5/bin/hbase org.apache.hadoop.hbase.mapreduce.Export $1 /do1cloud/real_backup02/${1}_${mydate} $yestoday_begin_time $yestoday_end_timeelse/do1cloud/hbase-2.0.5/bin/hbase org.apache.hadoop.hbase.mapreduce.Export $1 /do1cloud/real_backup02/${1}_${mydate} $yestoday_begin_time $yestoday_end_timefi/do2cloud/hadoop-3.0.3/bin/hdfs dfs -get /do5cloud/real_backup02/${1}_${mydate} /do3cloud/do24export/fortar/${1}_${mydate}_$yestoday_end_time
}for table in `cat /opt/prodtables.txt`
dobackup02_tables $table
donenowtime=`date +'%Y-%m-%d-%H-%M-%S'`
tar -zcf /do6cloud/do14export/fortar/tables_${nowtime}.tar.gz /do0cloud/do94export/fortar/*_${mydate}*/
find /do1cloud/do14export/fortar/ -mtime +5 -exec rm -rf {} \;13)HBase备份和还原实用程序的限制
串行备份操作
备份操作不能同时运行。操作包括创建,删除,还原和合并等操作。仅支持一个活动备份会话。HBASE-16391 将引入多备份会话支持。
无法取消备份
备份和还原操作都无法取消。(HBASE-15997,HBASE-15998)。取消备份的解决方法是终止客户端备份命令(control-C),确保已退出所有相关的MapReduce作业,然后运行该hbase backup repair命令以确保系统备份元数据一致。
备份只能保存到单个位置
将备份信息复制到多个位置是留给用户的练习。HBASE-15476将引入本质上指定多备份目标的功能。
需要HBase超级用户访问权限
只允许HBase超级用户(例如hbase)可以执行备份/恢复,这可能会对共享HBase安装造成问题。当前的缓解措施需要与系统管理员协调,以构建和部署备份和还原策略(HBASE-14138)。
备份还原是一种在线操作
要从备份执行还原,它需要HBase集群在线作为当前实现(HBASE-16573)的警告。
某些操作可能会失败并需要重新运行
HBase备份功能主要由客户端驱动。虽然HBase连接中内置了标准的HBase重试逻辑,但执行操作中的持久性错误可能会传播回客户端(例如,由于区域拆分导致的快照失败)。应将备份实现从客户端移到将来的ProcedureV2框架中,这将为瞬态/可重试故障提供额外的稳健性。该hbase backup repair命令用于纠正系统无法自动检测和恢复的状态。
避免公开API的声明
虽然存在与此功能交互的Java API,并且它的实现与接口分离,但没有足够的严格性来确定它是否正是我们要向用户运送的。因此,它被标记为一个Private受众,期望随着用户开始尝试该功能,将有必要修改兼容性(HBASE-17517)。
缺乏备份和还原的全局指标
单独的备份和还原操作包含有关操作所包含的工作量的指标,但没有集中位置(例如主用户界面),它提供信息用于消费(HBASE-16565)。