目录
介绍
简单整合
简单模式
定义
代码示例
work模式
定义
代码示例
pubsub模式
定义
代码示例
routing模式
定义
代码示例
top模式
定义
代码
下单付款加积分示例
介绍
代码
可靠性投递示例
介绍
代码
交换机投递确认回调
队列投递确认回调
延迟消息场景示例
介绍
代码示例
图形化创建绑定交换机队列
纯代码创建
消息过期
队列过期
单个消息过期
消息时间过期
消息溢出
编辑
消息被拒
死信队列踩坑
源码
介绍
RabbitMQ是一种开源的消息队列软件,它实现了高级消息队列协议(AMQP),提供了可靠的消息传递机制以及支持分布式应用程序之间的通信。RabbitMQ支持多种编程语言,如Java、Python、Ruby、PHP等等,并且可以在不同的操作系统上运行,如Windows、Linux、Mac OS等。
RabbitMQ的核心理念是分离应用程序之间的通信,允许开发人员将其应用程序解耦,从而使它们更加容易理解、扩展和维护。在使用RabbitMQ时,开发人员可以将消息发布到队列中,当消费者连接到队列时,RabbitMQ会自动将消息传递给消费者。此外,RabbitMQ还提供了一些高级功能,如重试机制、消息优先级、发布/订阅模式等等,使得开发人员可以更加灵活地控制消息队列的行为。
rabbitmq的初始安装步骤可以查看博主之前的文章进行安装
rabbitmq安装图文保姆级教程
简单整合
简单模式
定义
简单模式(Simple mode):也称为点对点模式,是最简单的模式。生产者将消息发送到队列中,消费者从队列中读取消息并处理。这种模式只有一个生产者和一个消费者,消息被传递一次并且只被一个消费者接收,生产者和消费者之间的关系是一对一的
代码示例
新建父级项目,再在父级项目中新建consumer和producter两个子模块
两个子级添加必须依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId><version>2.6.13</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>添加mq配置
添加生产者生产消息接口
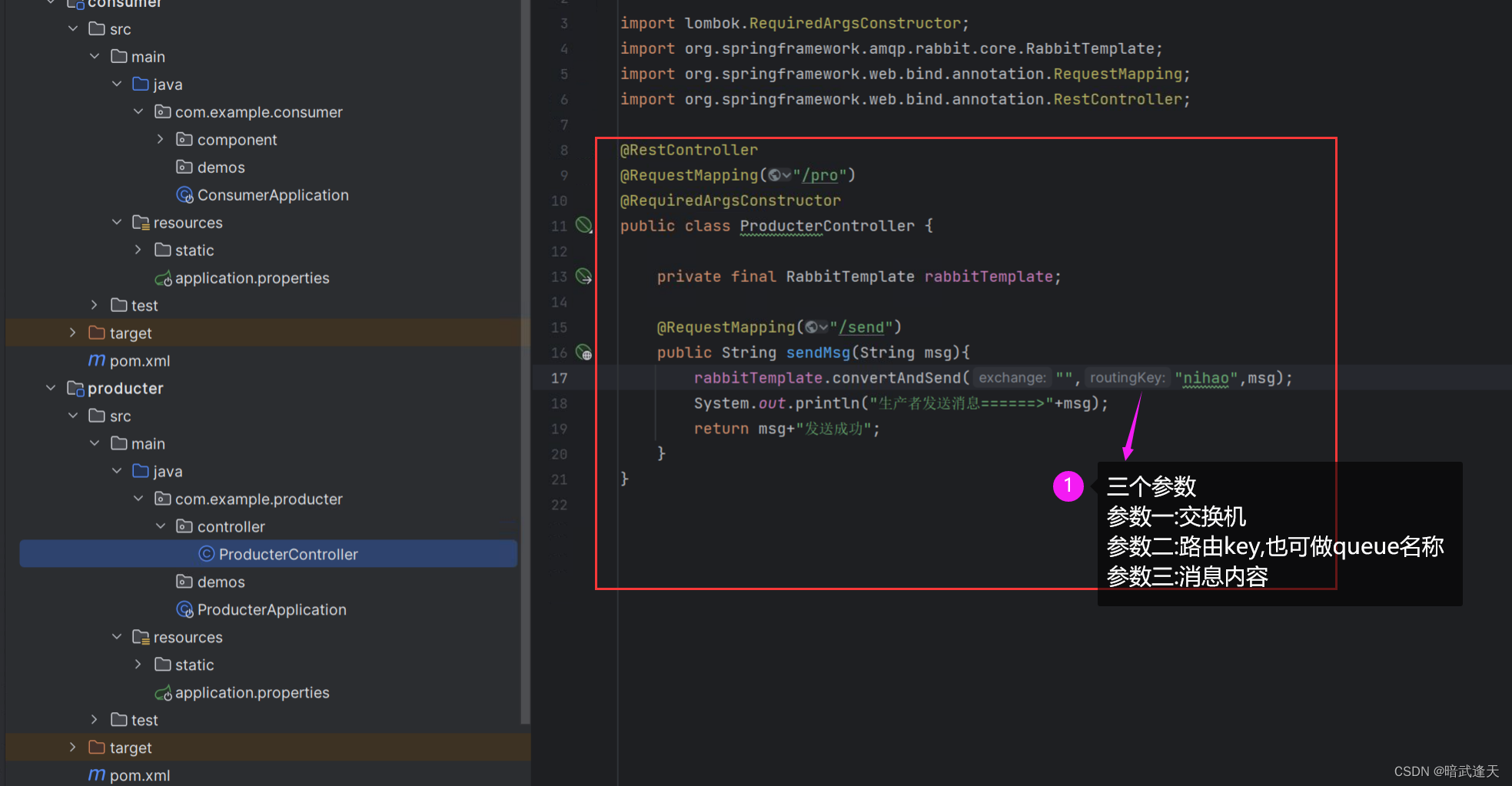
添加消费者监听消费消息
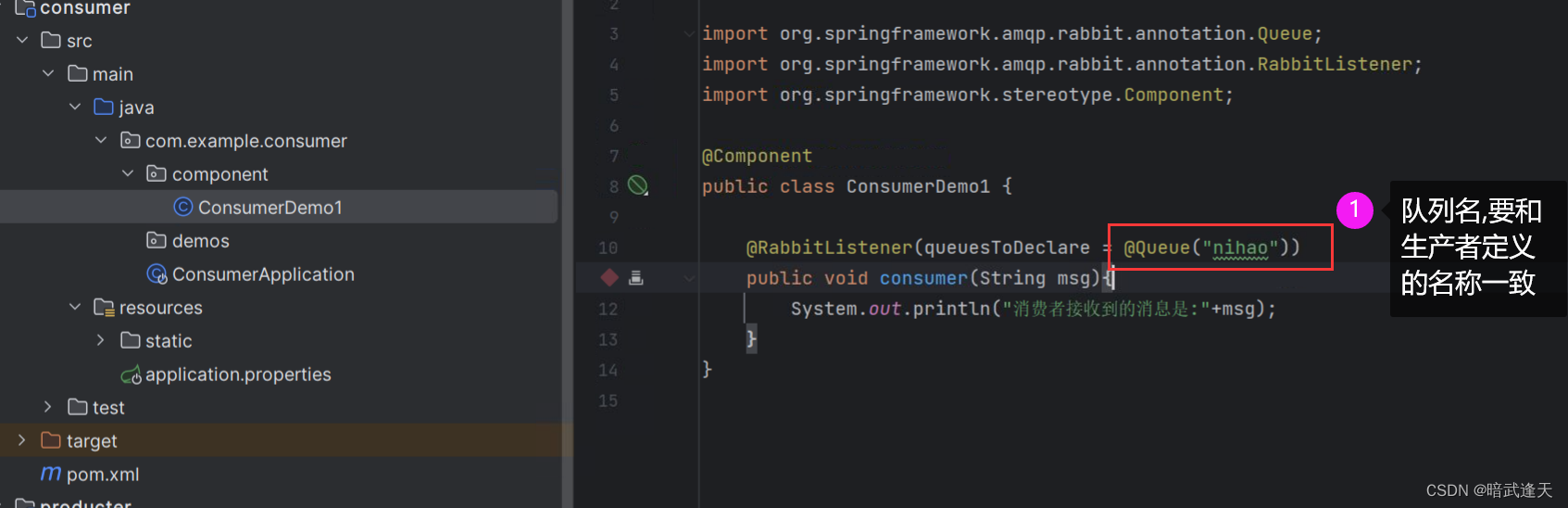
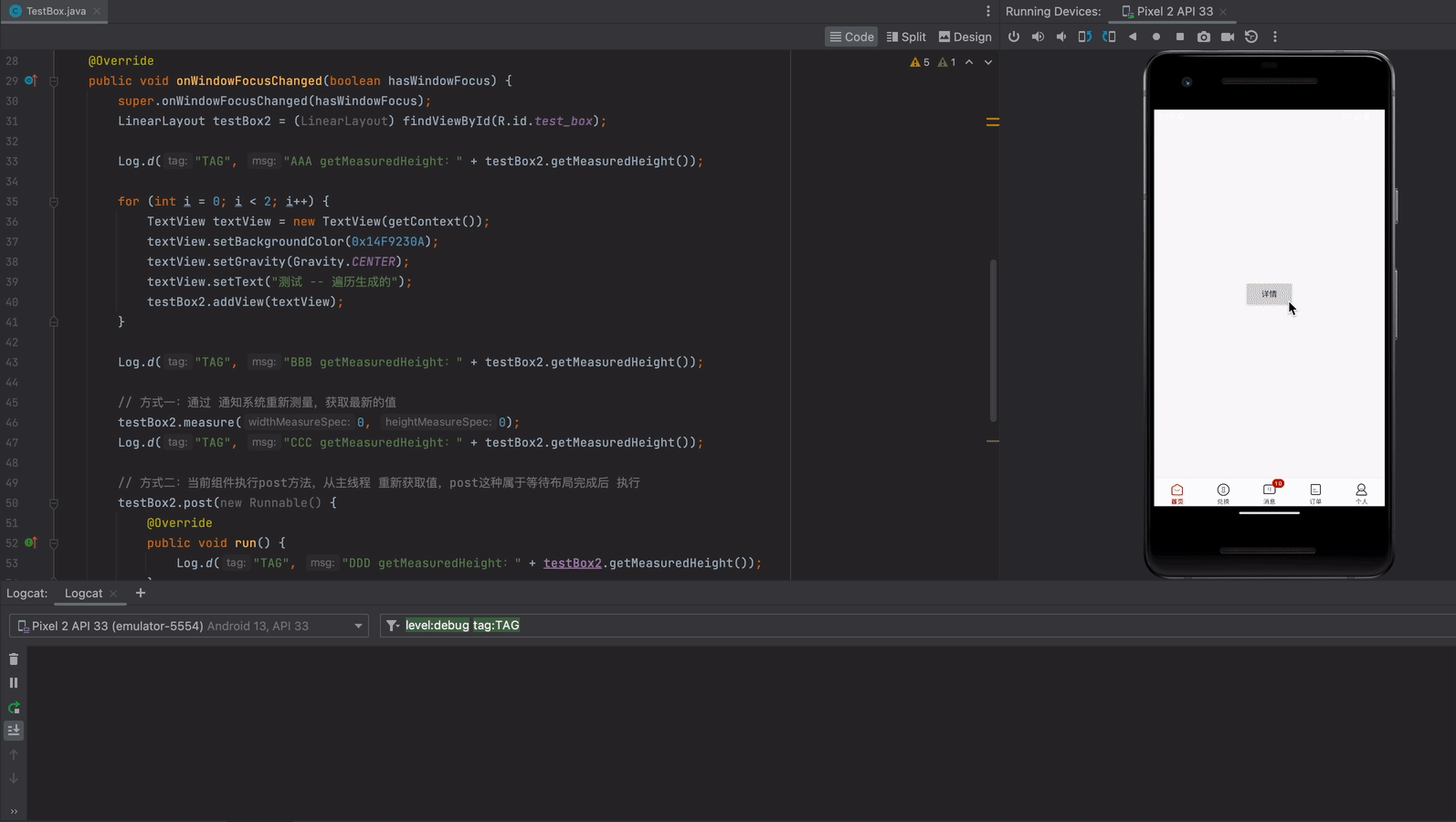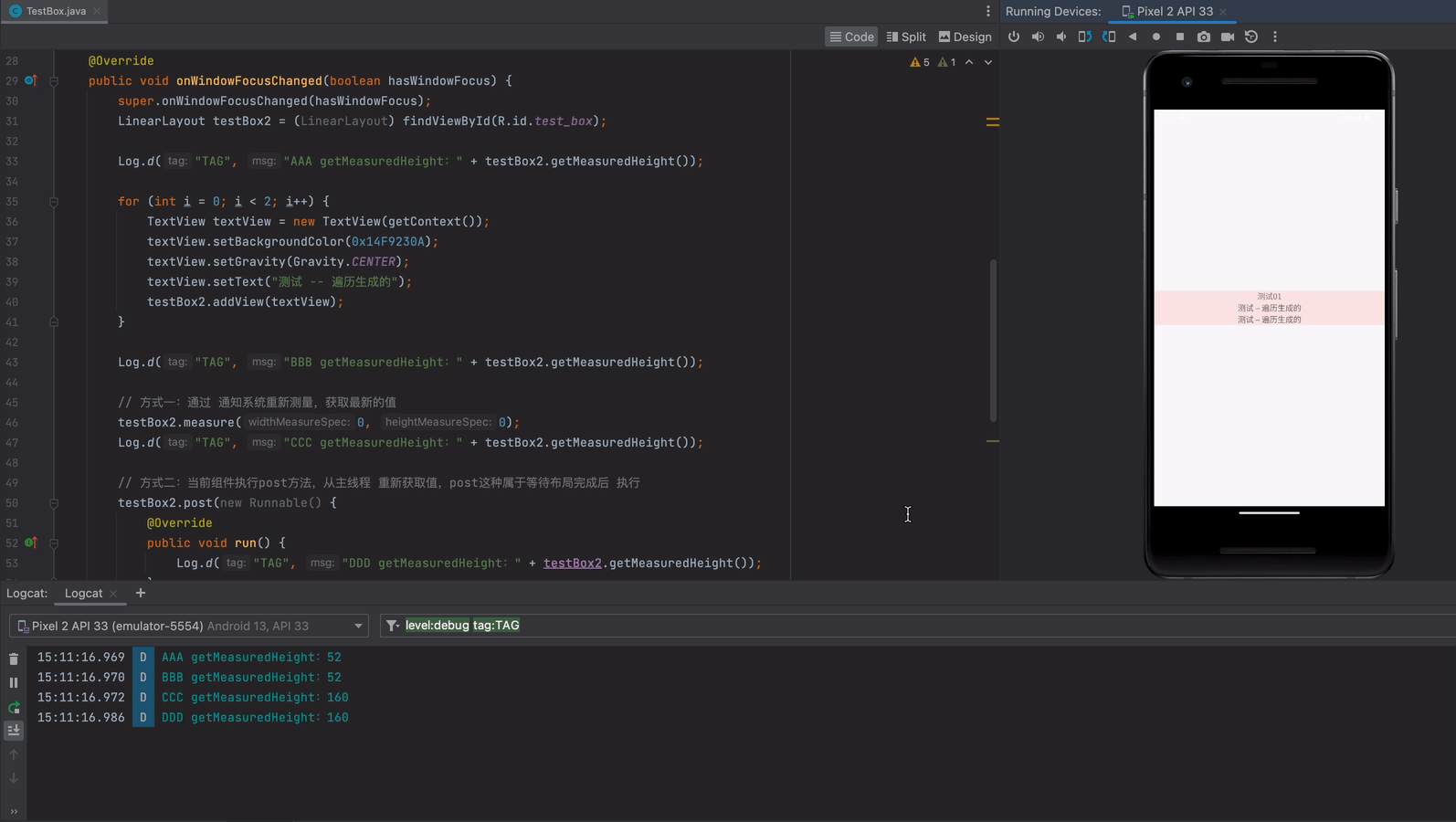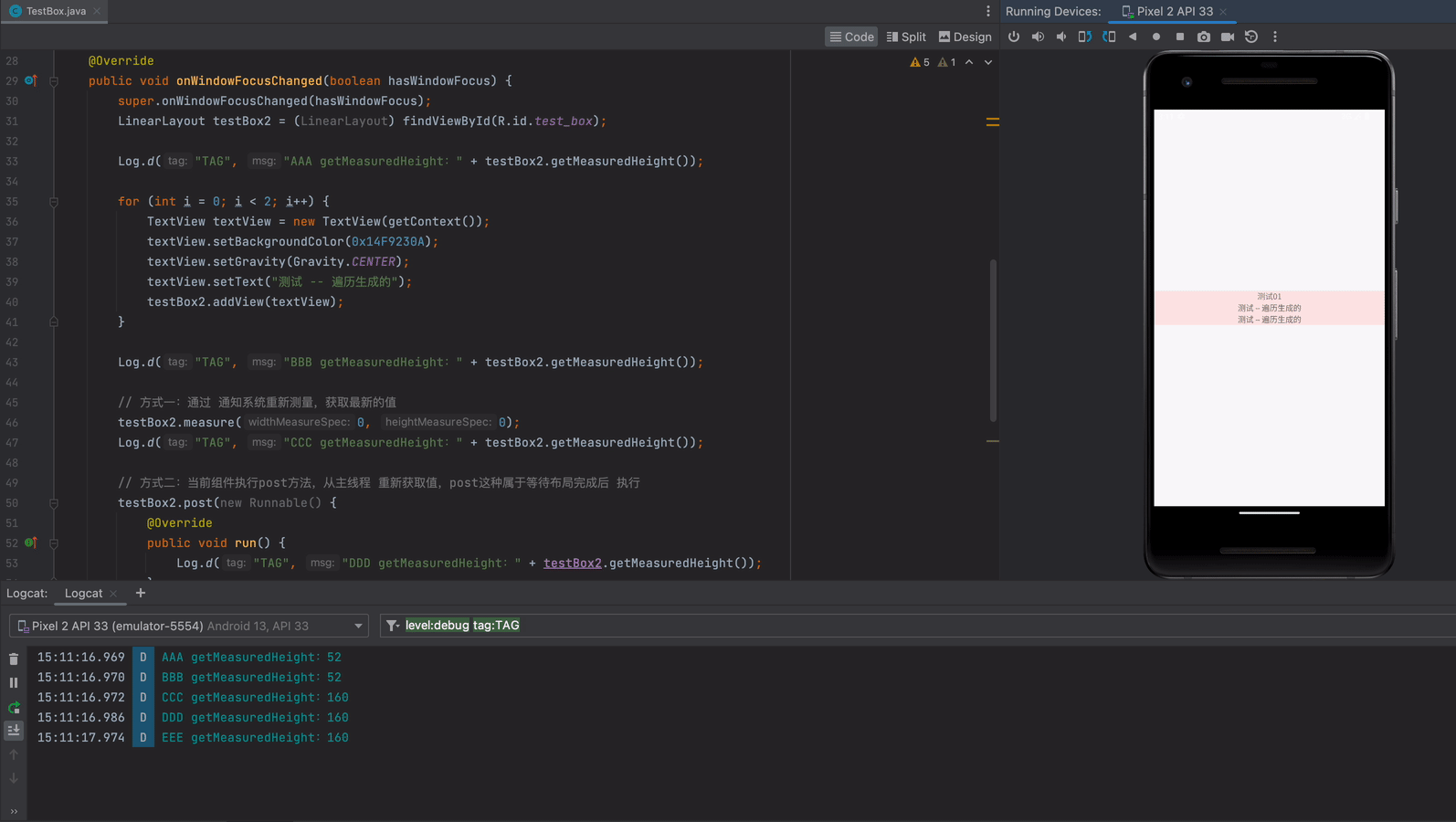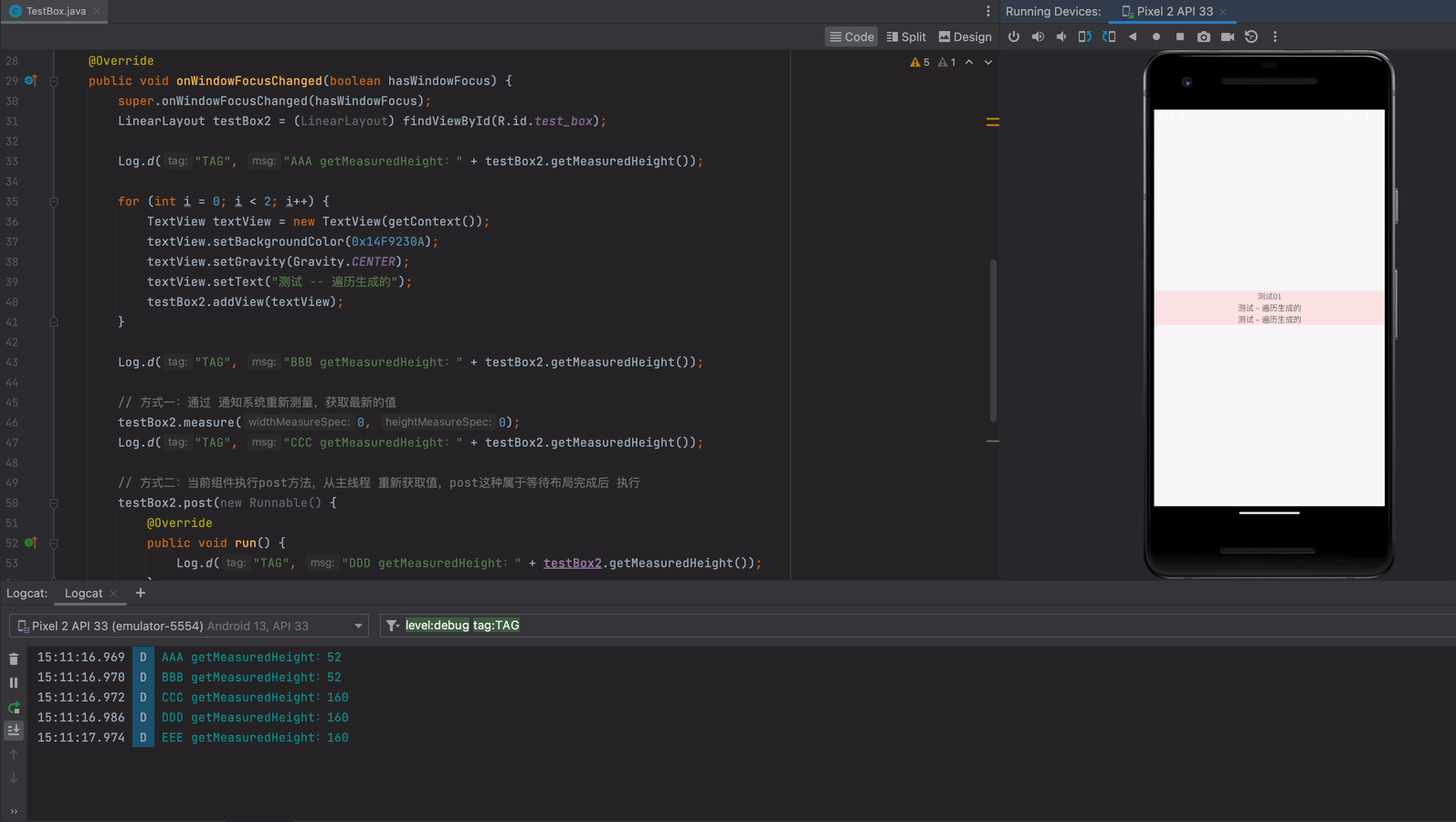
启动生产者和消费者进行测试
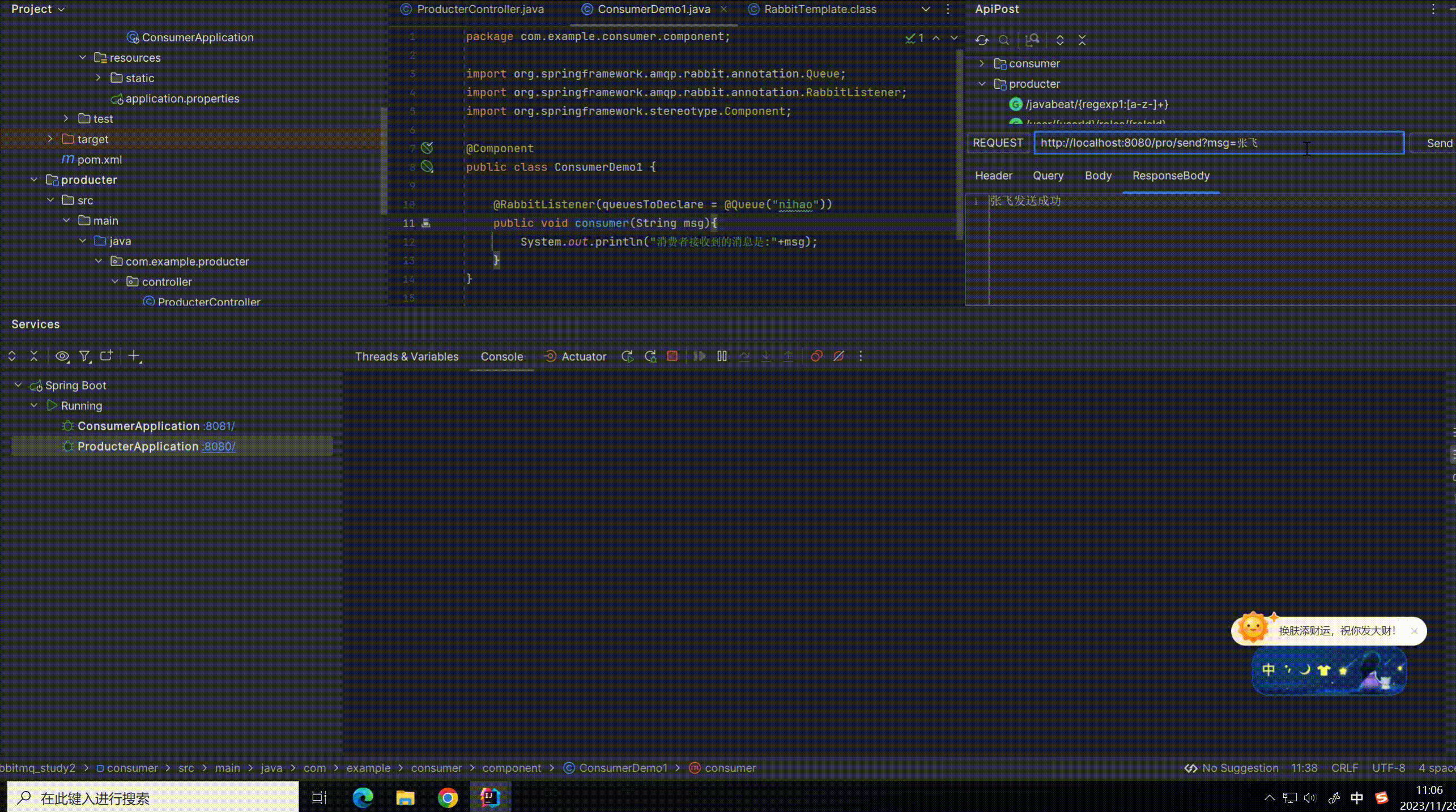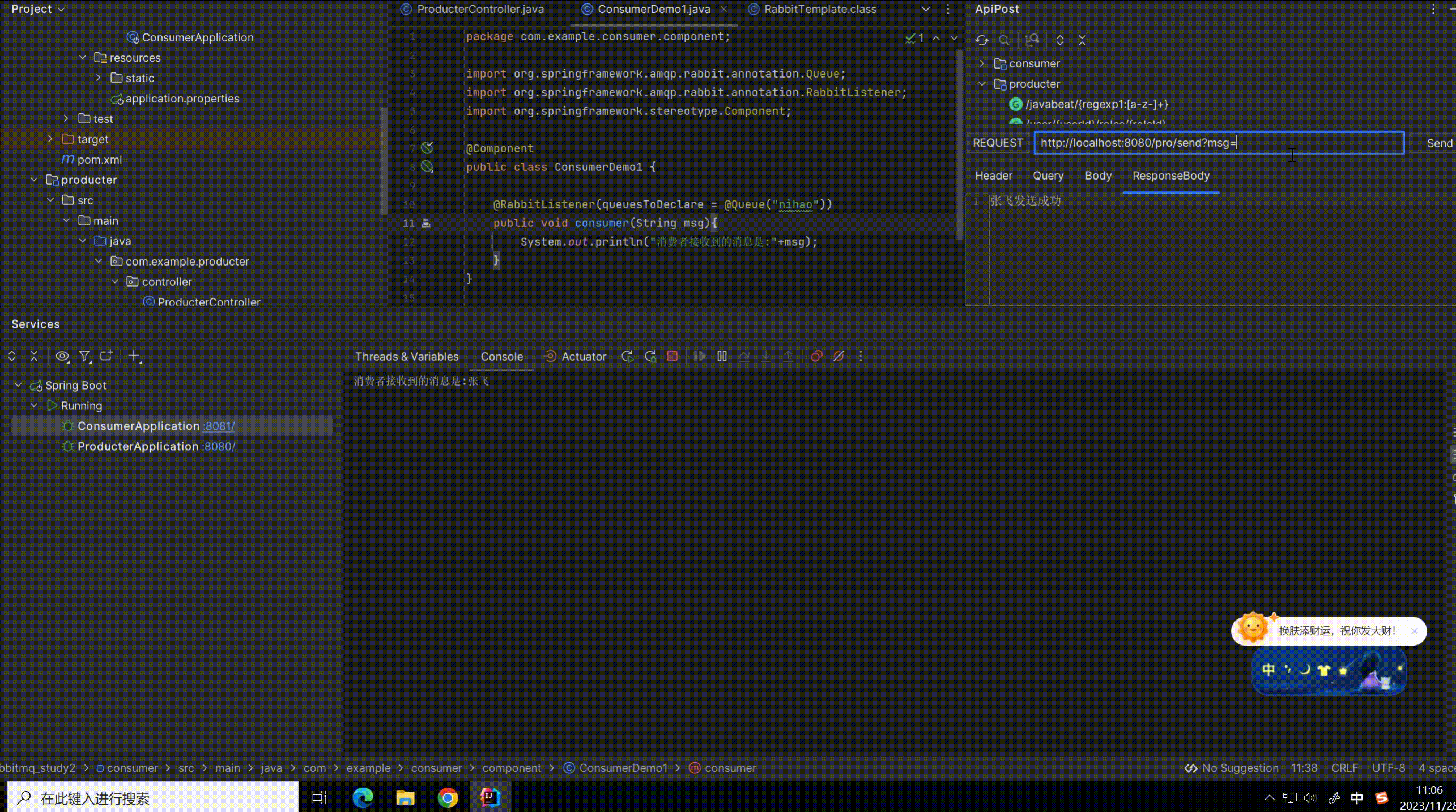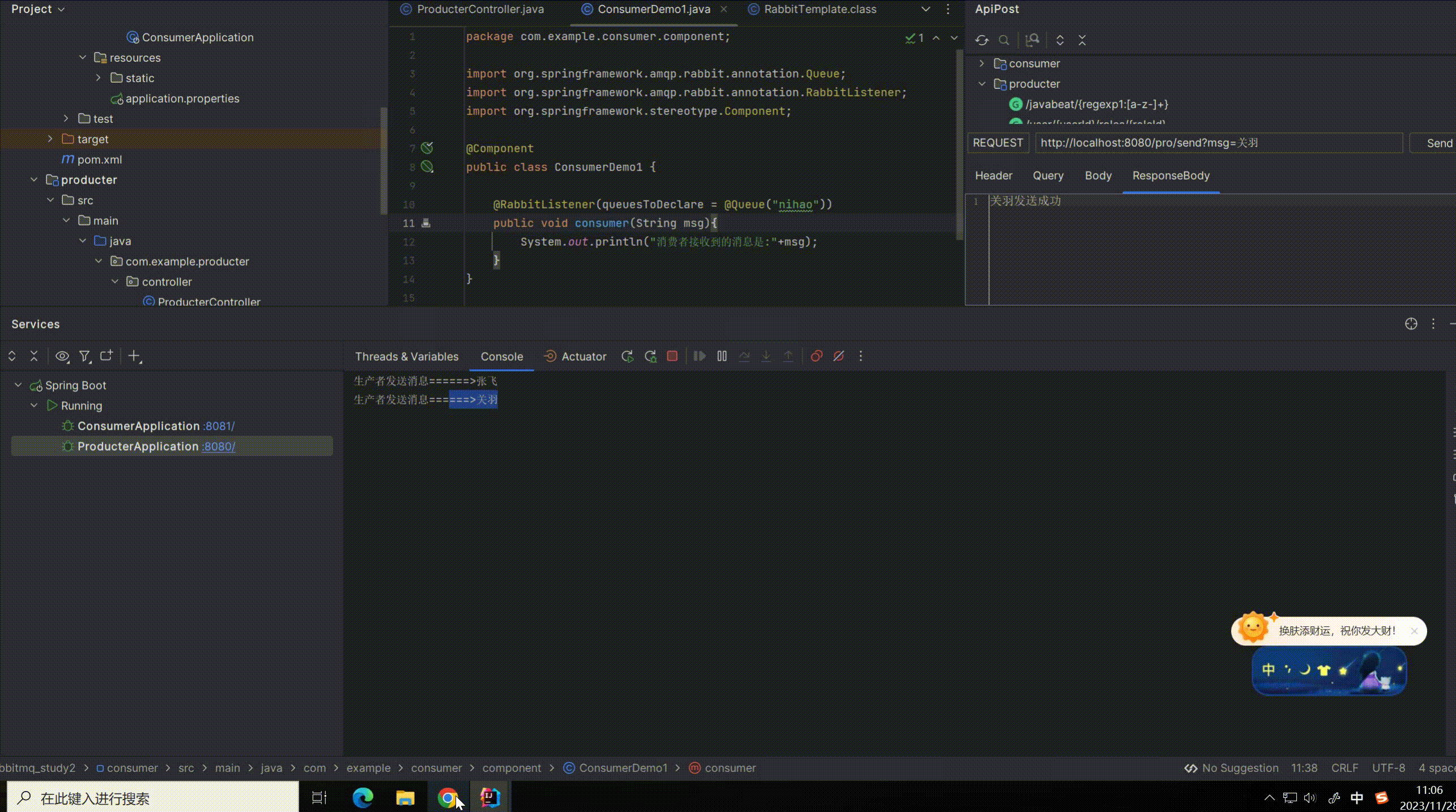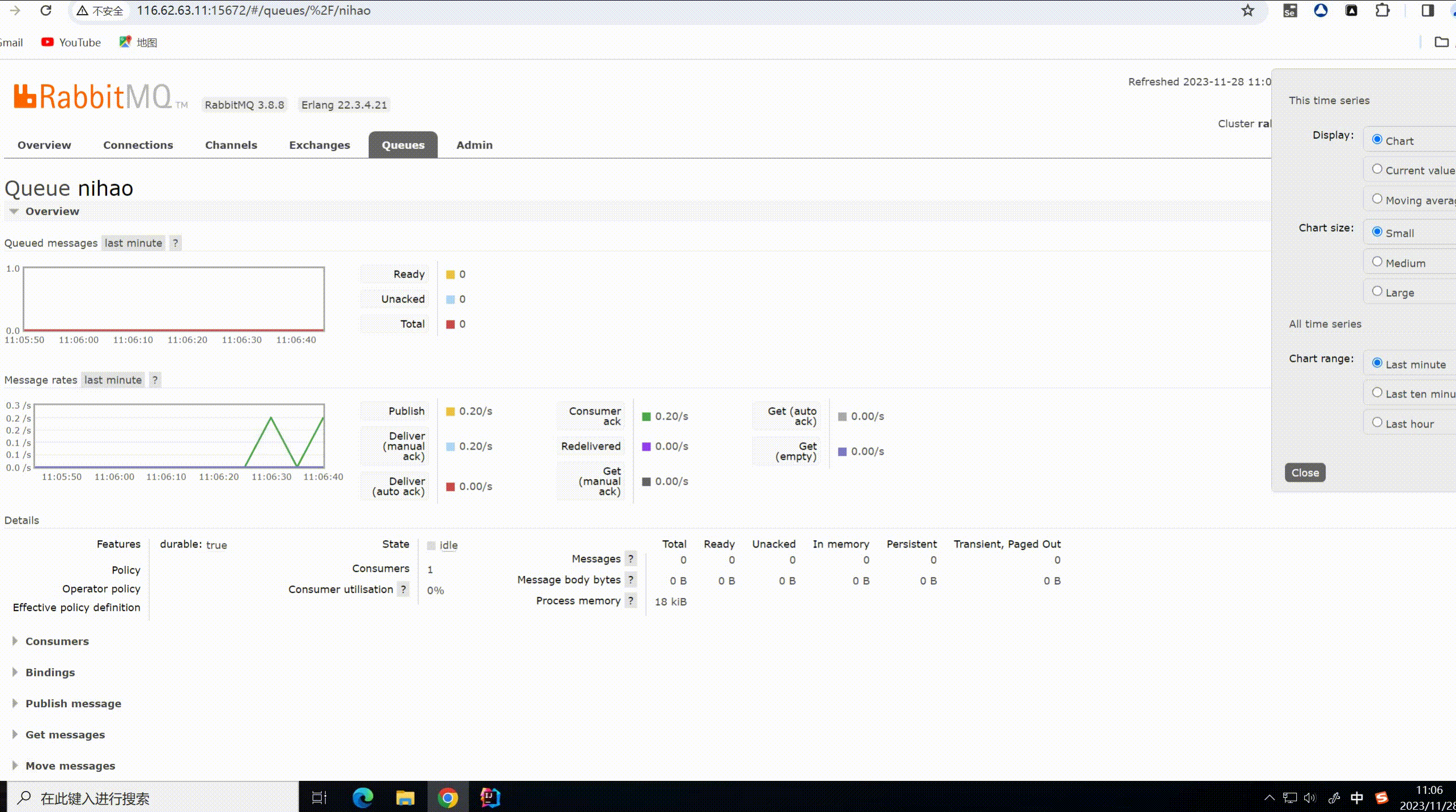
可以看到生产者每生产一条消息,消费者都可以监听到消息并且进行消费
work模式
定义
工作模式(Work mode):也称为竞争消费者模式,多个消费者同时订阅同一个队列中的消息,但是只有一个消费者可以消费每个消息。这种模式用于负载均衡,其中每个消费者处理的消息数量相等(或者最接近相等),并且每个消息只被处理一次。
代码示例
我们这里用生产者发送20条消息,建立两个消费者来进行消息的监听,且消费者1每次消费消息前设置睡眠1秒,消费者2每次设置睡眠2秒,然后观察消费者的消费情况
work生产者:
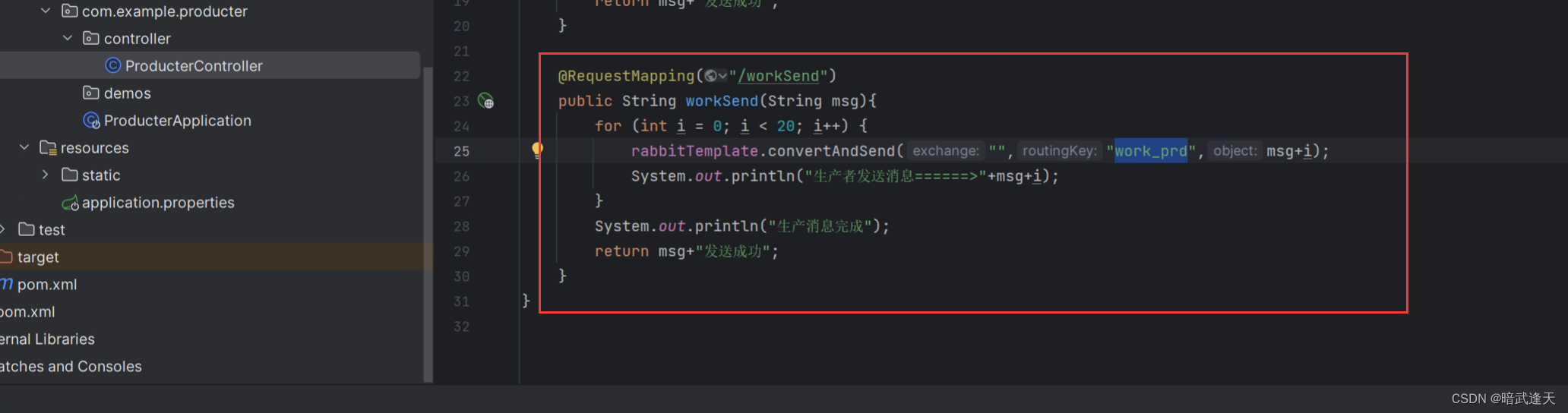
work消费者
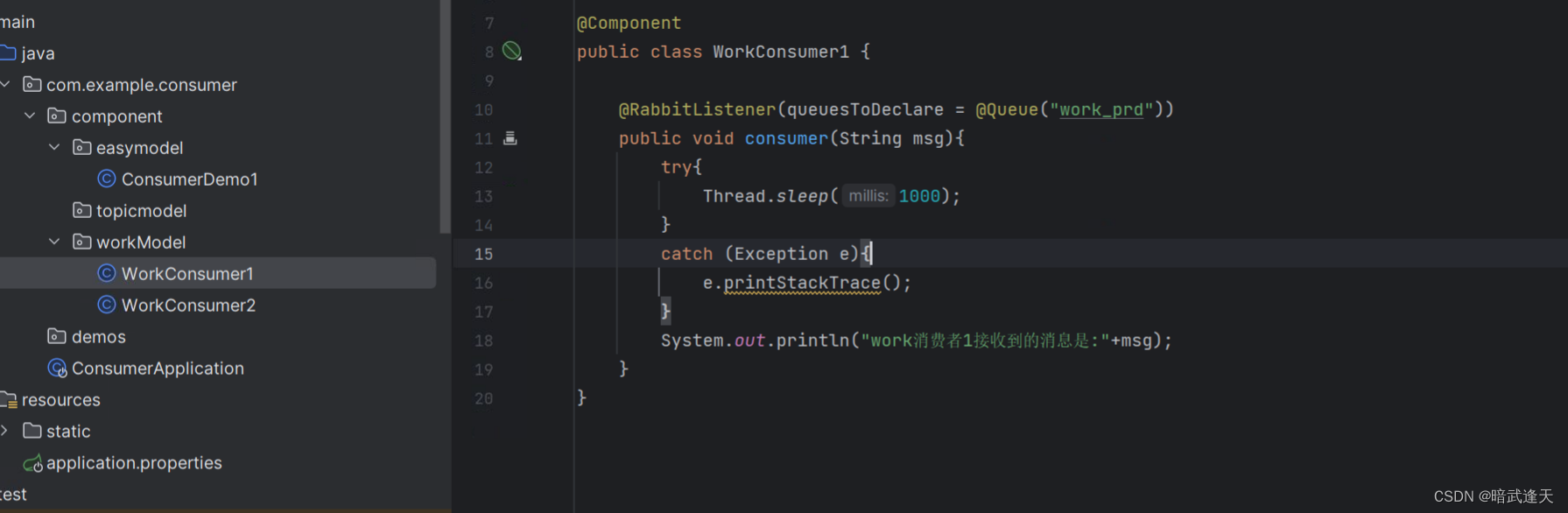
 启动测试观察消费者消费情况
启动测试观察消费者消费情况
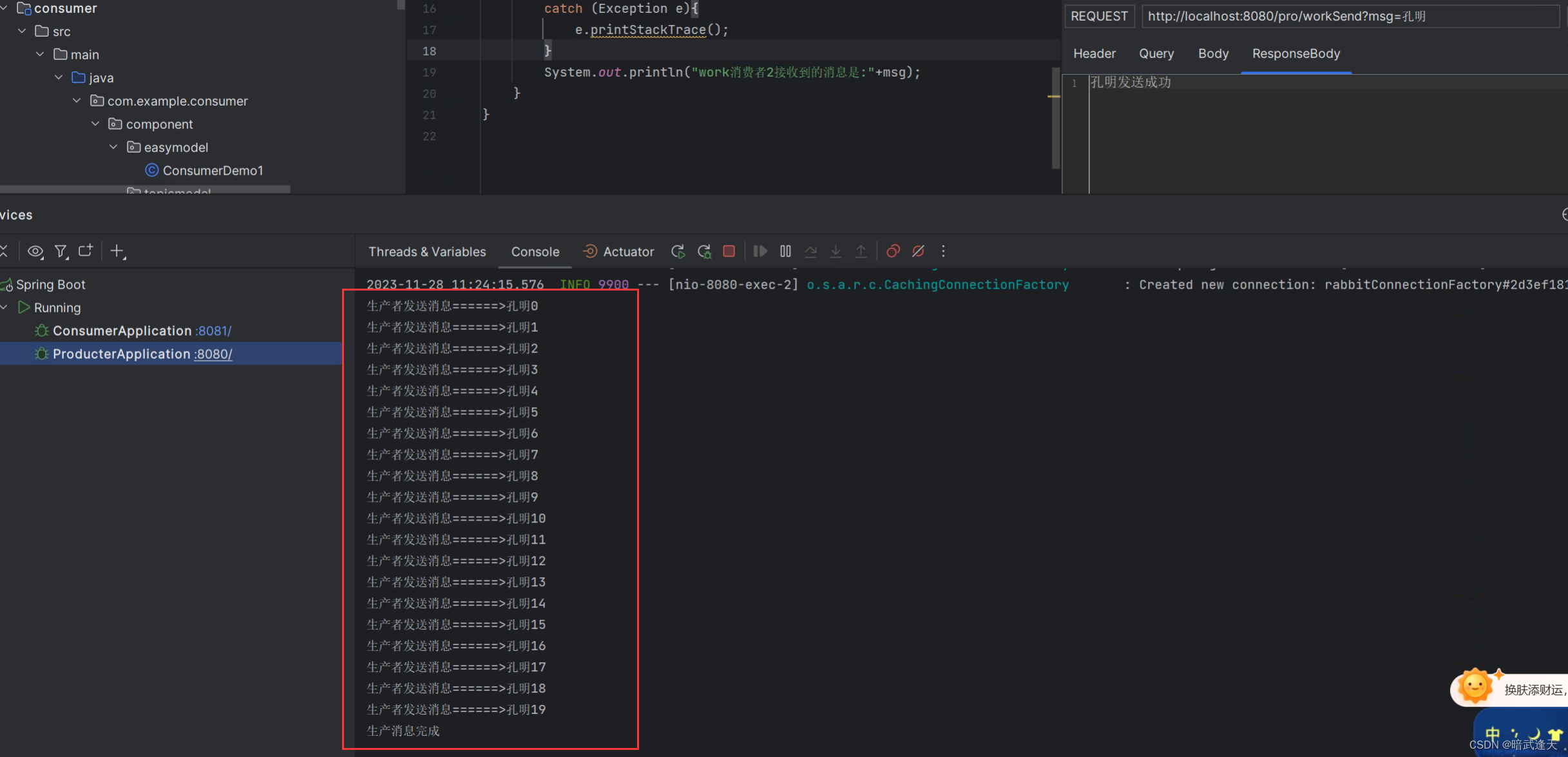

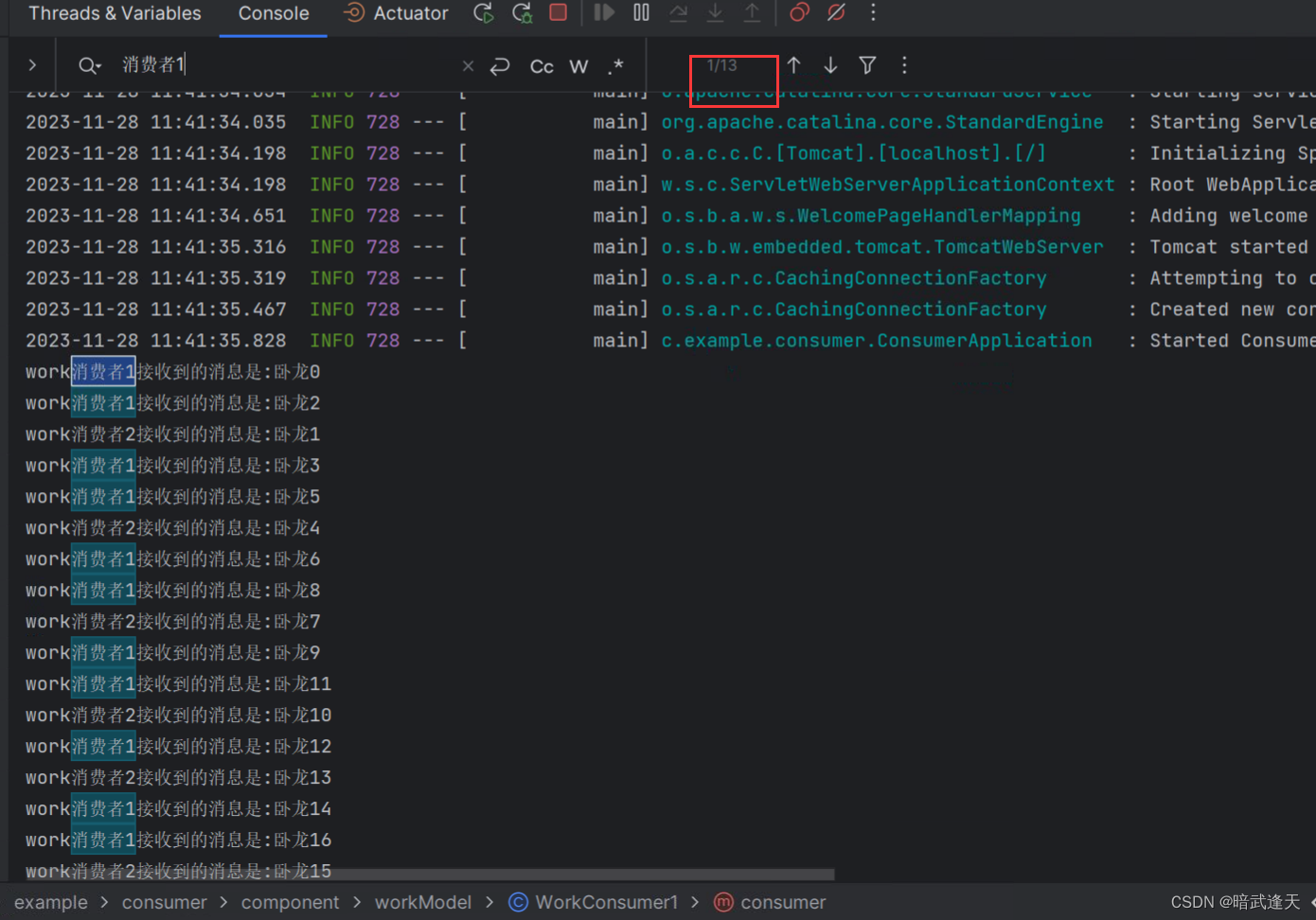
可以看到消费者1和消费者2都是消费了10条消息,也就是说无论消费者1和消费者2谁消费消息的速度快慢,mq默认都是平均分配的,这样很明显不太符合能者多劳的情况
要想实现能者多劳的分配可以进行一些配置
添加消费者配置
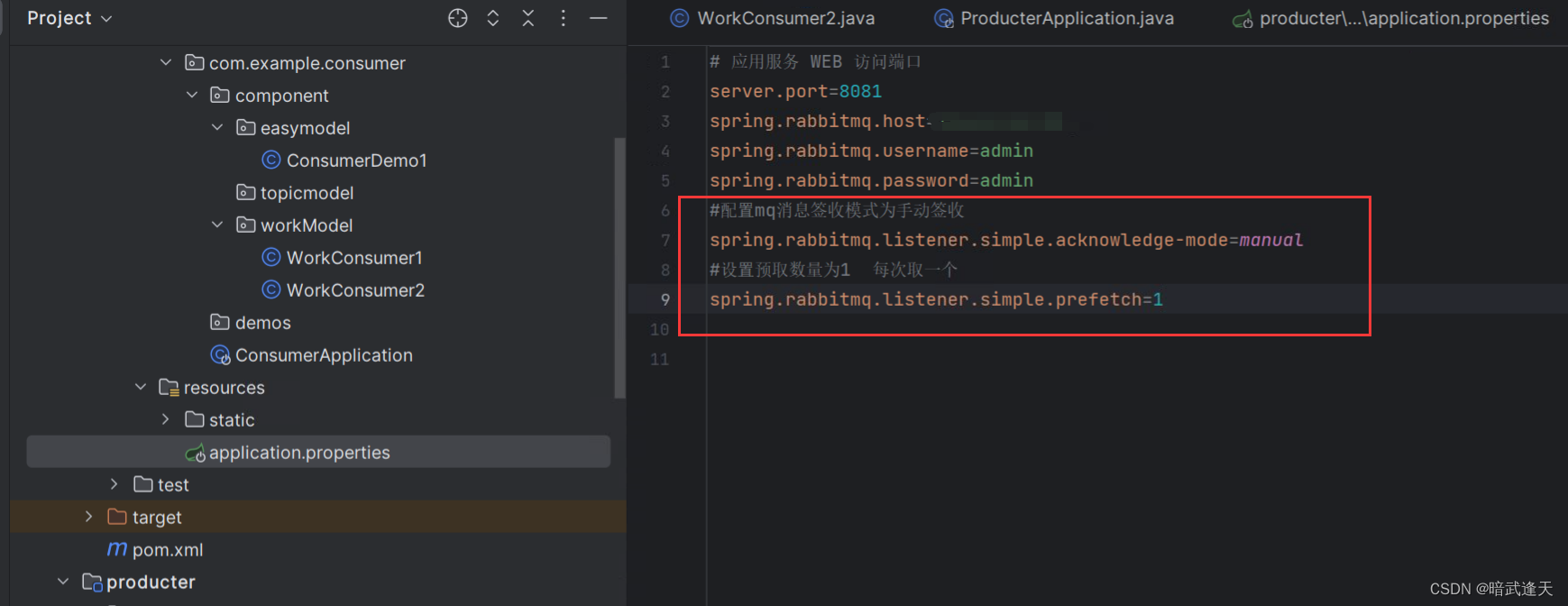
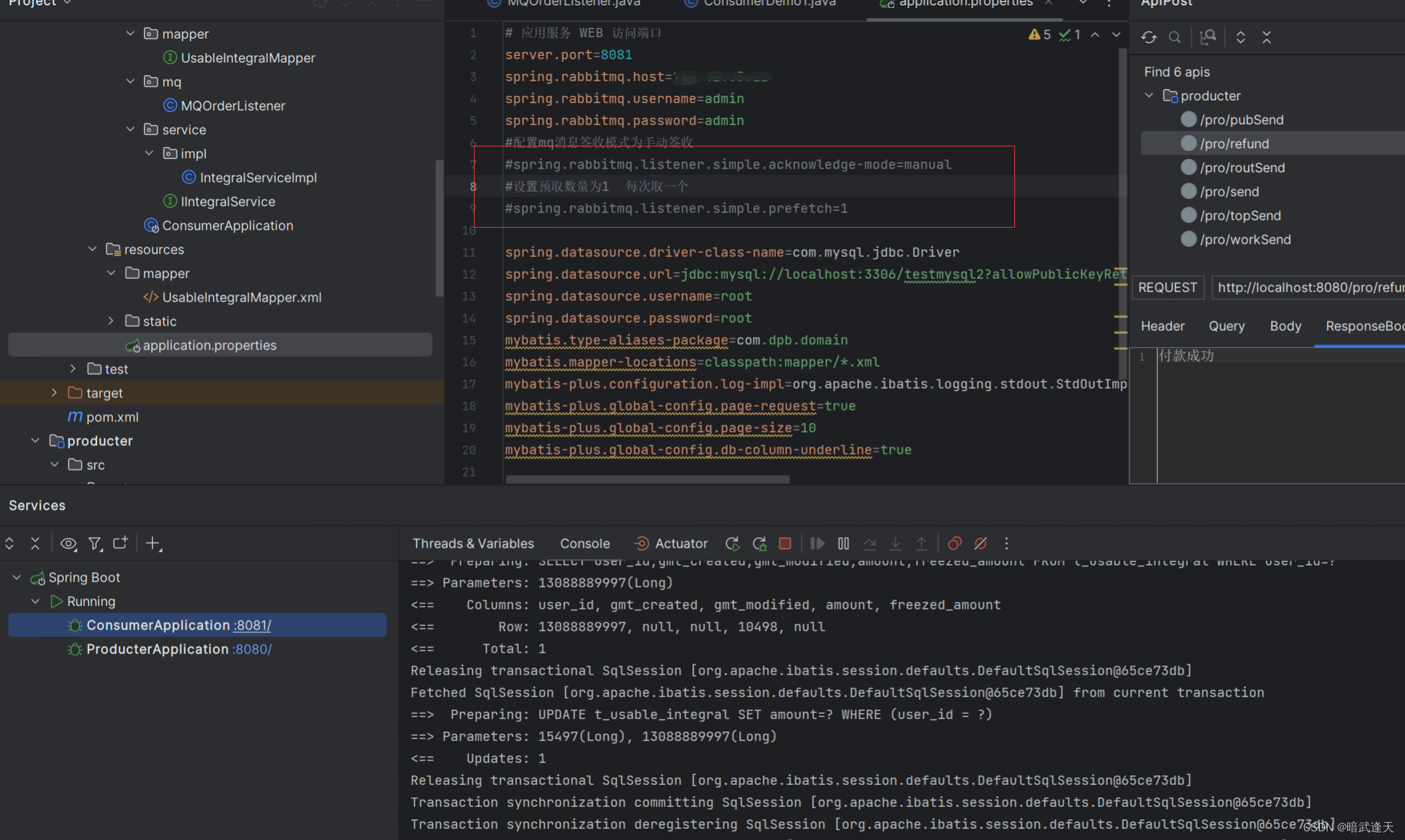
#配置mq消息签收模式为手动签收
spring.rabbitmq.listener.simple.acknowledge-mode=manual
#设置预取数量为1 每次取一个
spring.rabbitmq.listener.simple.prefetch=1调整两个消费者配置,此处两个消费者配置调整都一样
重启测试:
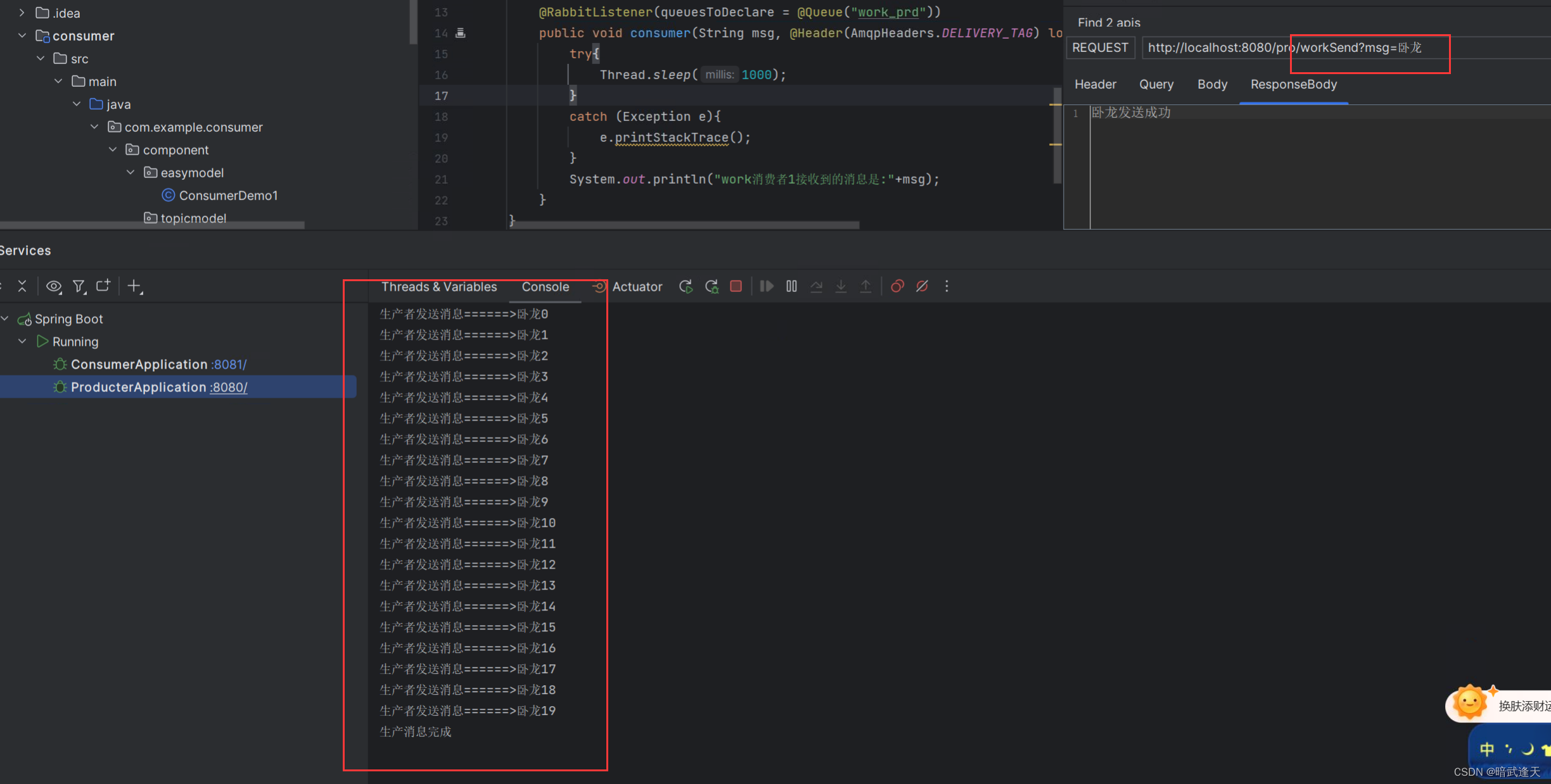
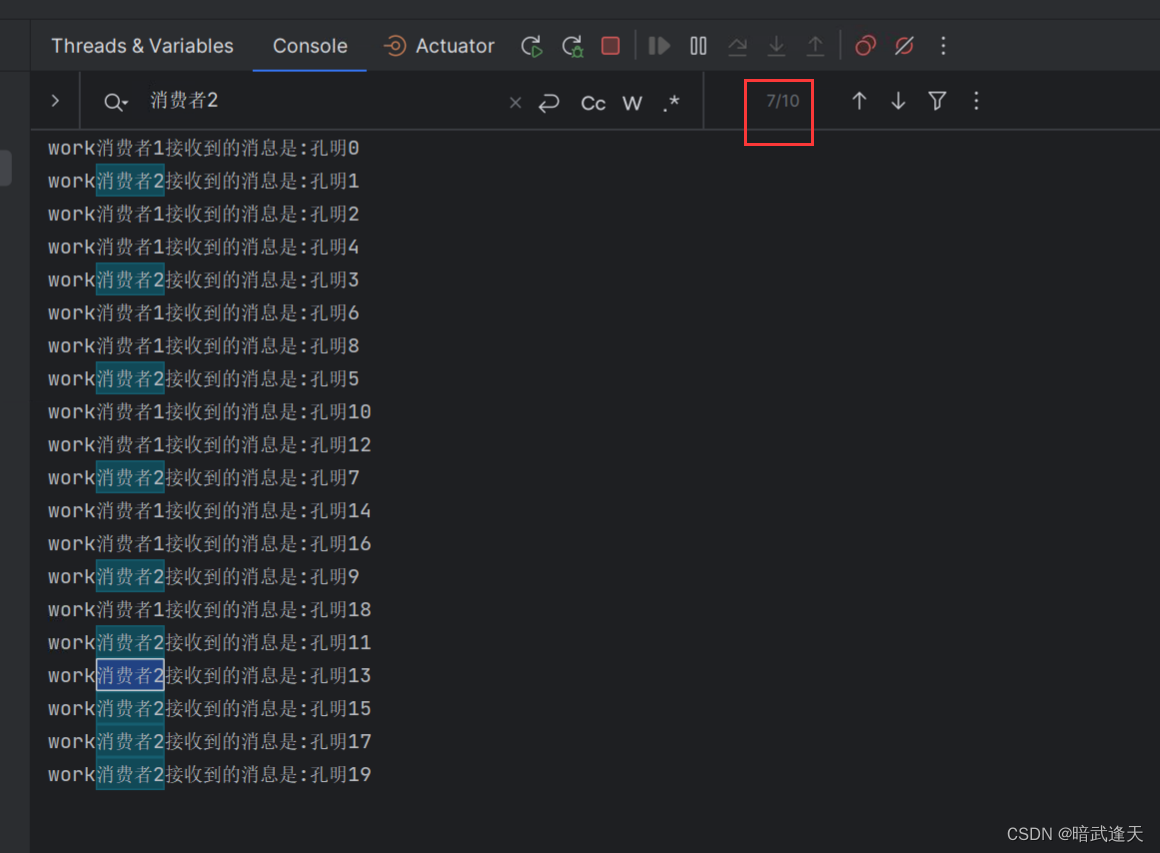
 此时可以明显看到速度更快的消费者1消费了13条,消费者2只消费了7条,已经达到了能者多劳的预期
此时可以明显看到速度更快的消费者1消费了13条,消费者2只消费了7条,已经达到了能者多劳的预期
pubsub模式
定义
发布/订阅模式(Publish/Subscribe mode):一个生产者将消息发送到交换机(Exchange)中,该交换机将消息传递给多个队列,所有与这些队列绑定的消费者都会接收到该消息。这种模式用于广播消息。
代码示例
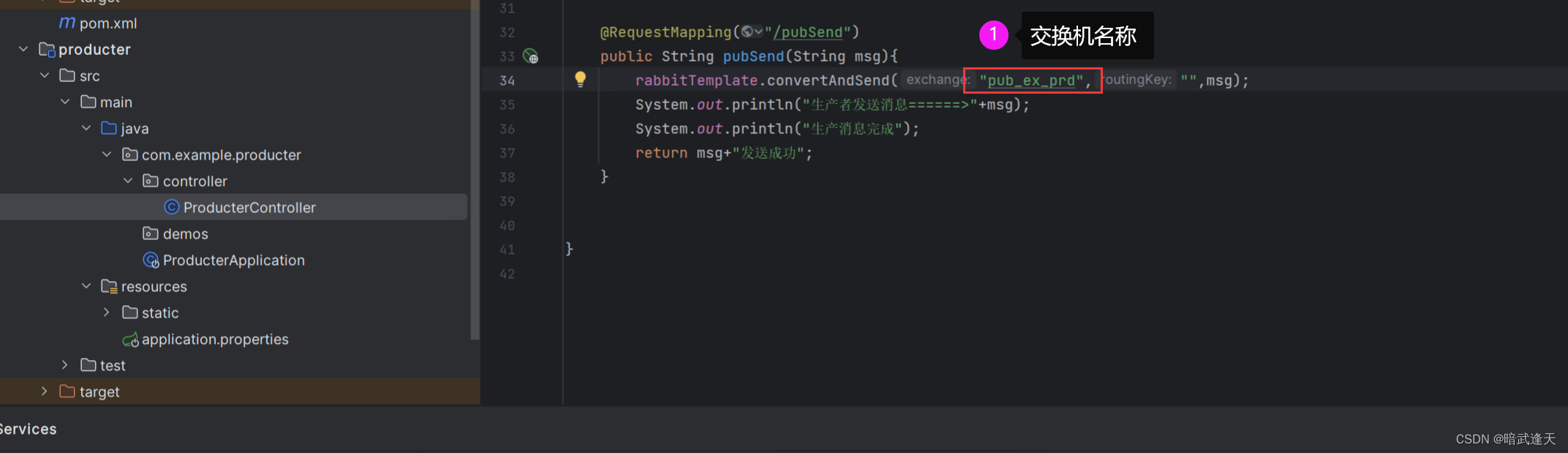
生产者接口
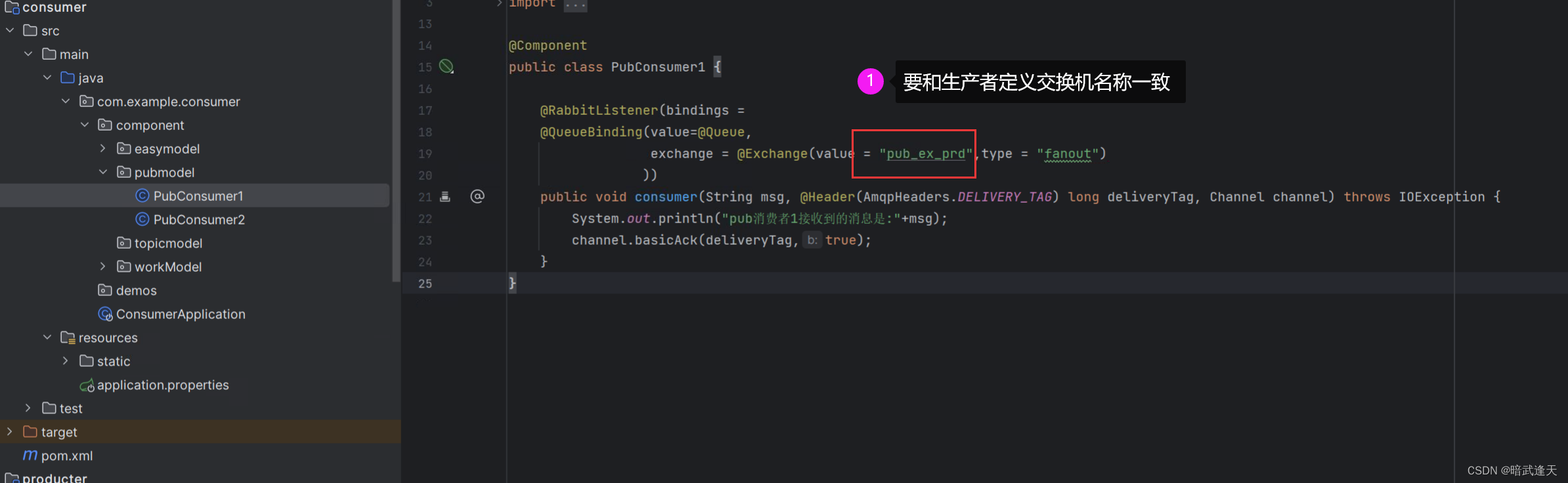
消费者1
 消费者2
消费者2

启动测试:
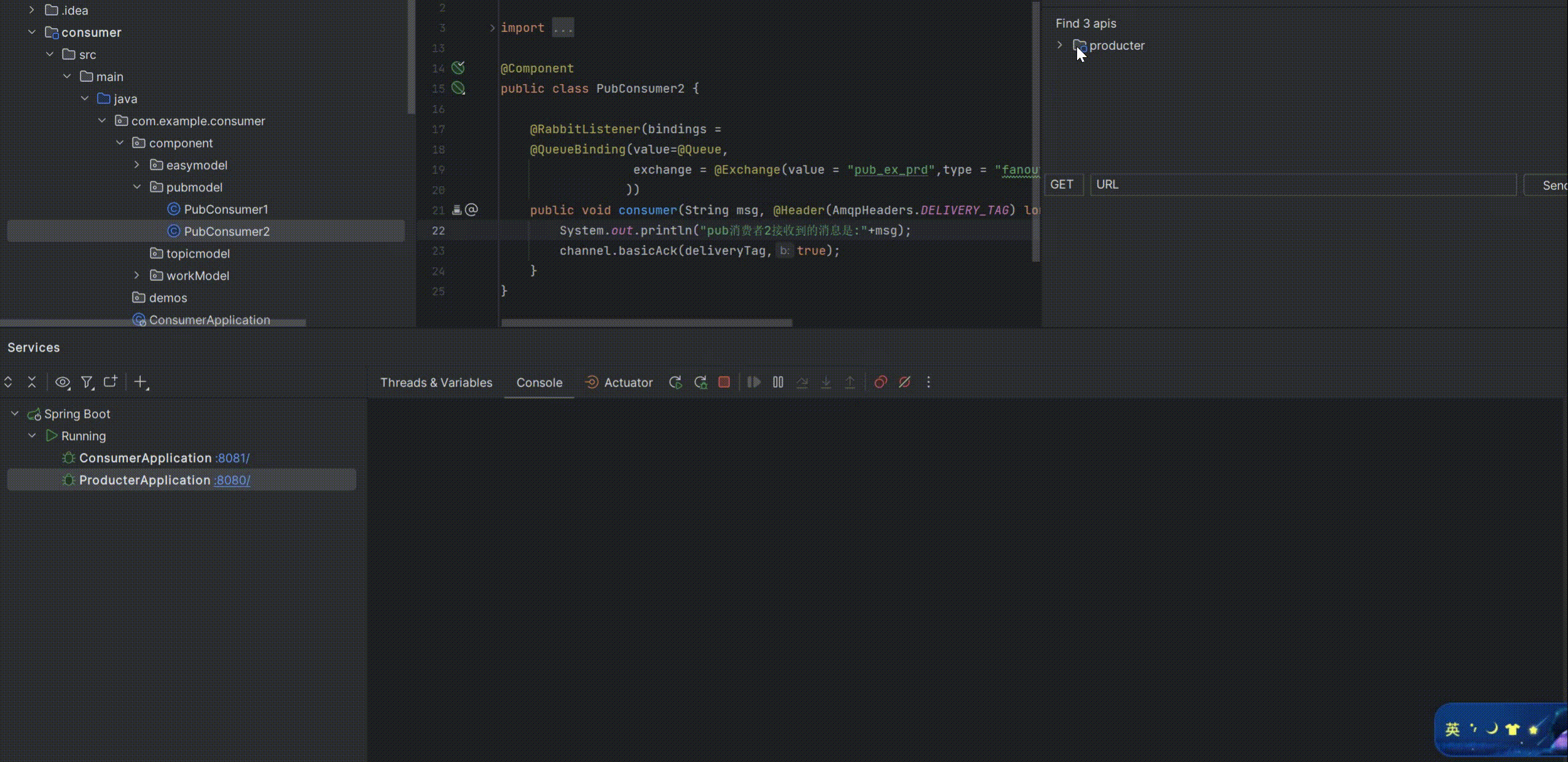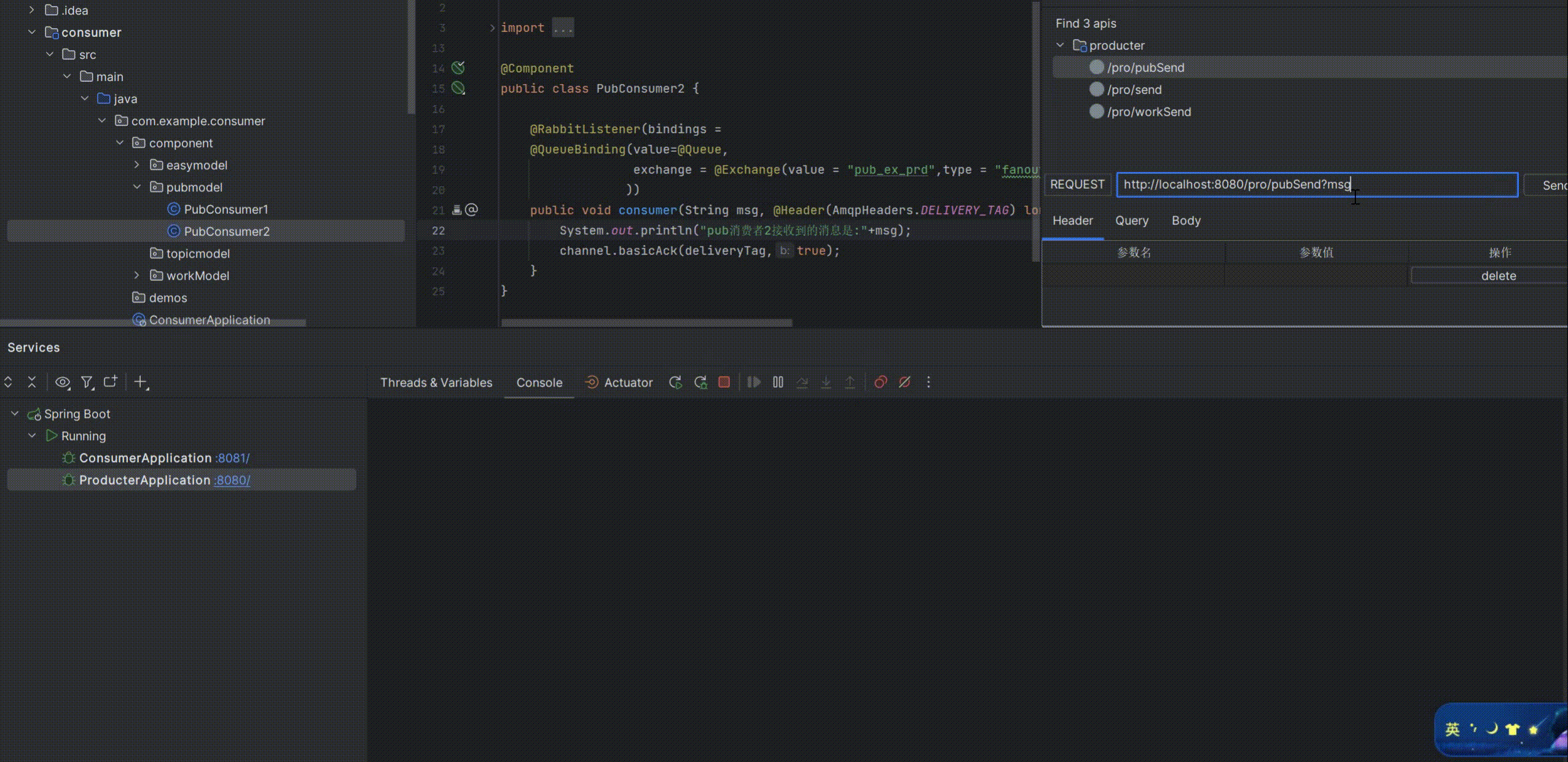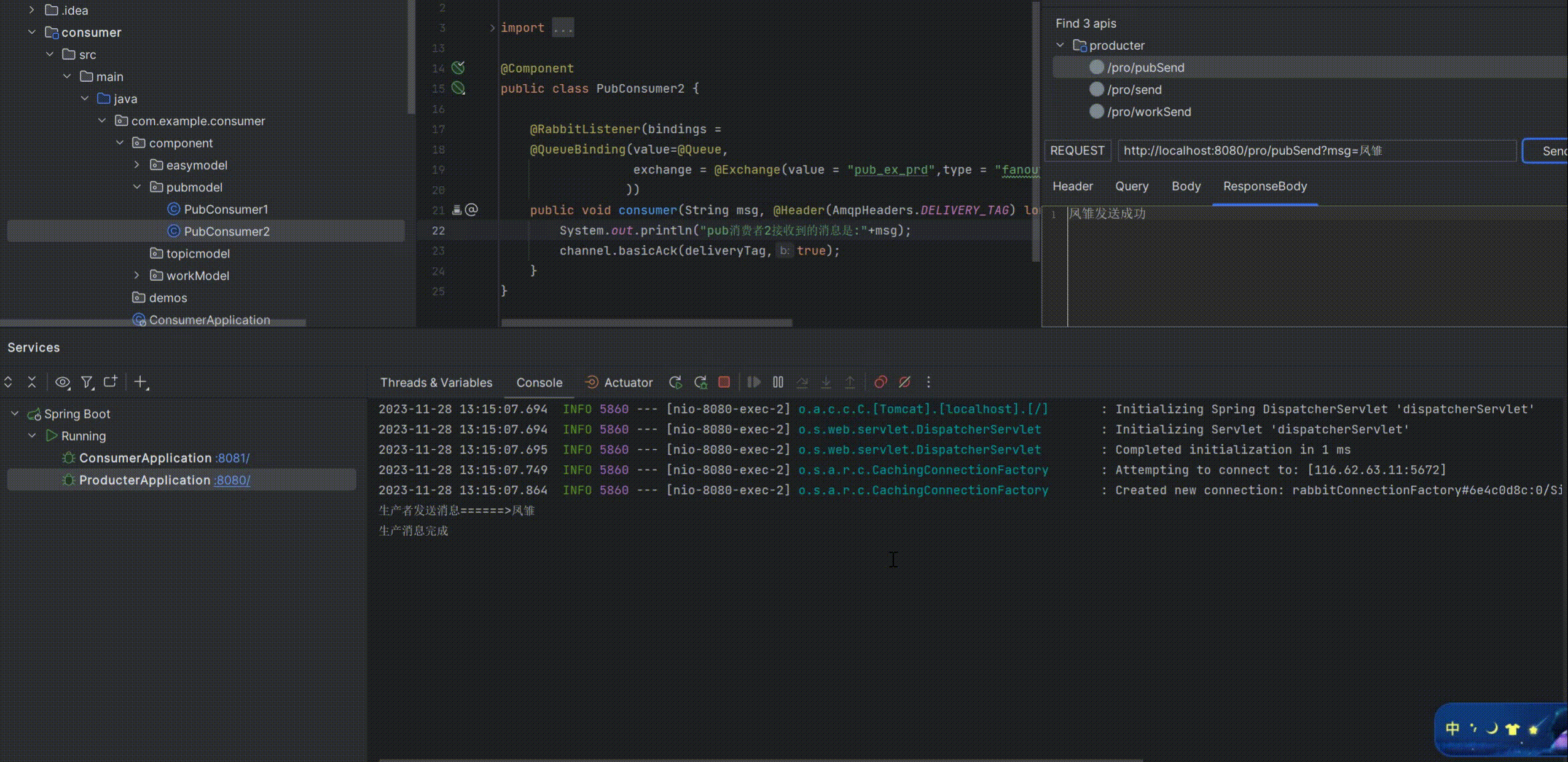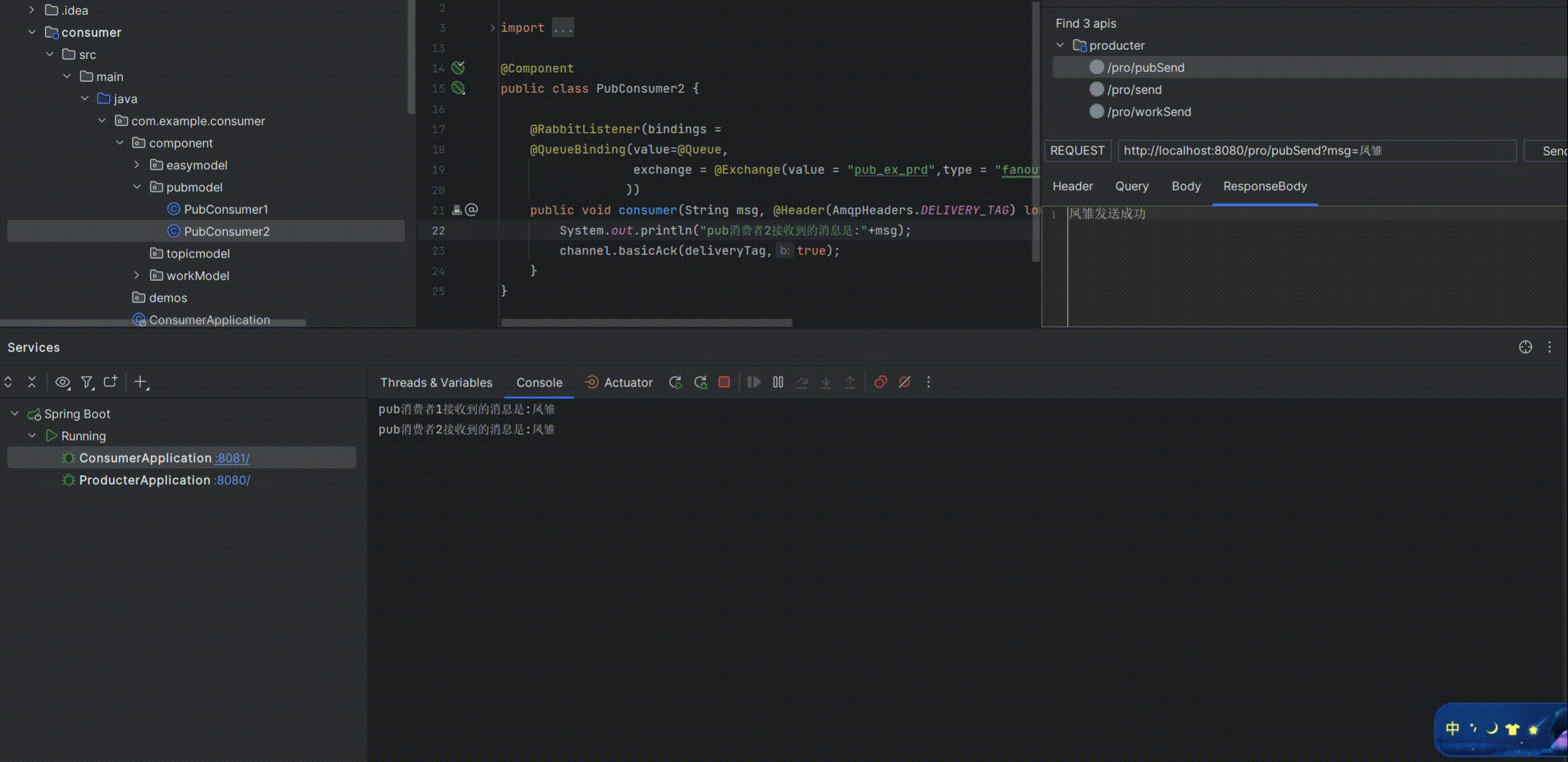
可以看到消费者1和消费者2同时消费了生产者生产的消息
routing模式
定义
路由模式(Routing mode):生产者将消息发送到交换机中,并将消息标记为一个特定的路由键(Routing Key)。交换机将消息传递给绑定到该交换机的与该路由键匹配的队列。这种模式用于将消息路由到特定的队列中。
代码示例
生产者
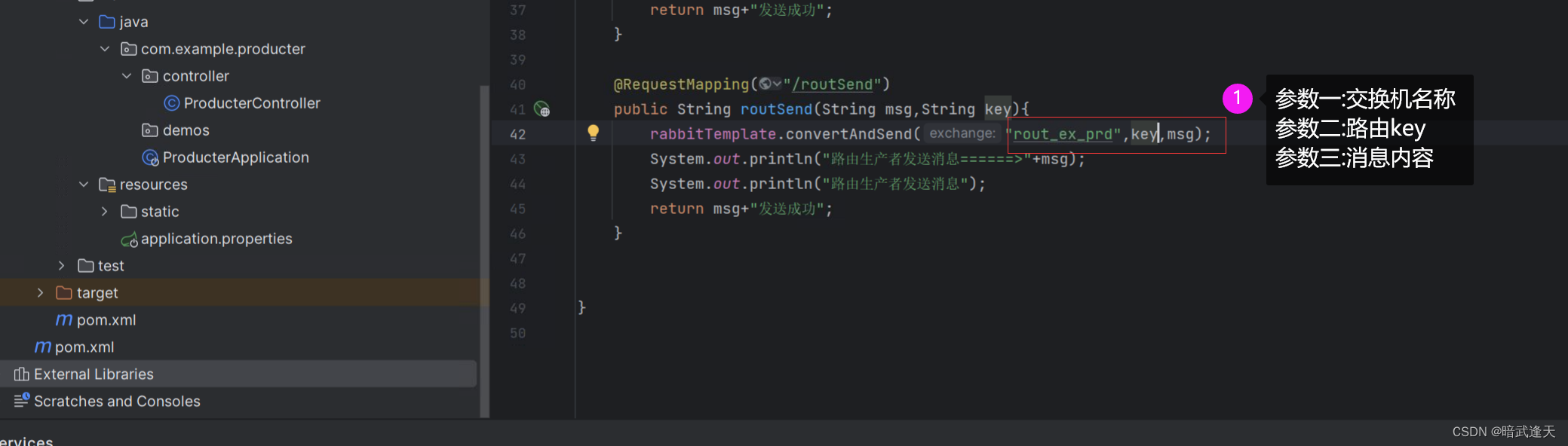
消费者1
 消费者2
消费者2
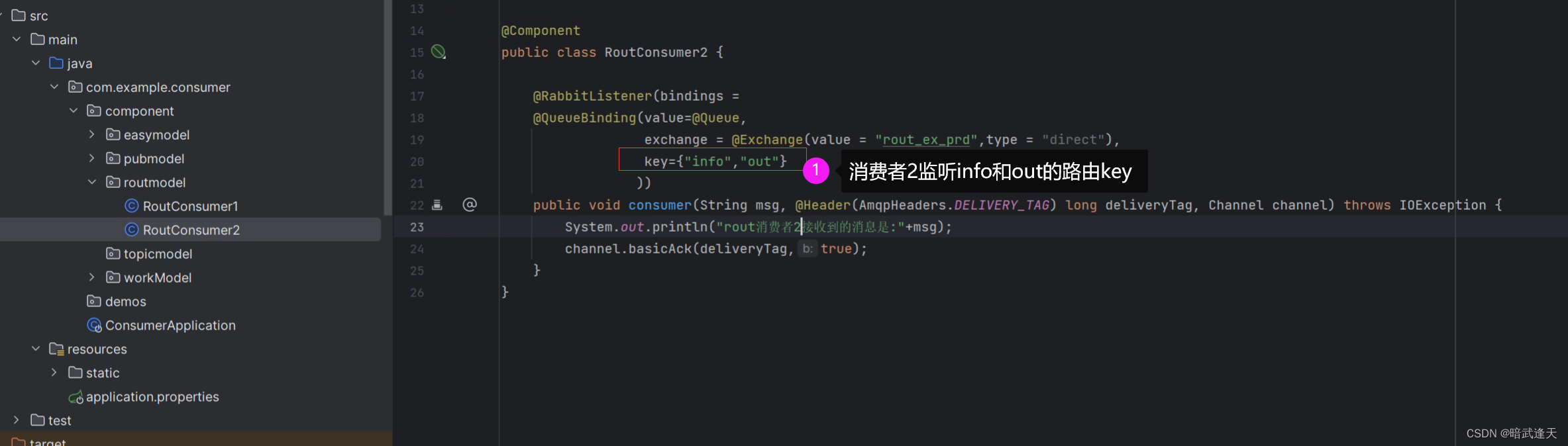
启动测试
top模式
定义
主题模式(Topic mode):也称为通配符模式,它是路由模式的升级版。生产者将消息发送到交换机中,并将消息标记为一个主题(Topic),交换机将消息传递给绑定到该交换机的与该主题匹配的队列。这种模式与路由模式类似,但是主题模式的主题可以使用通配符,允许复杂的路由规则。
代码
生产者

消费者1
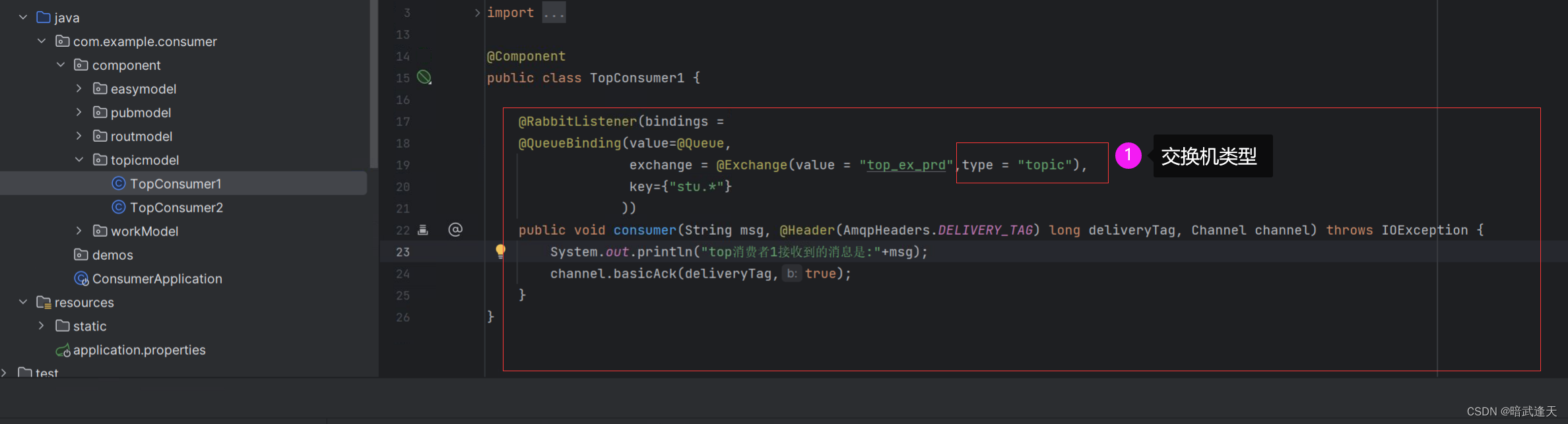
消费者2

启动测试:

下单付款加积分示例
介绍
下面以用户在下单付款后系统为用户添加积分的案例为例来对mq进行场景使用
代码
先建两张数据库表,一张订单表,一张用户积分表
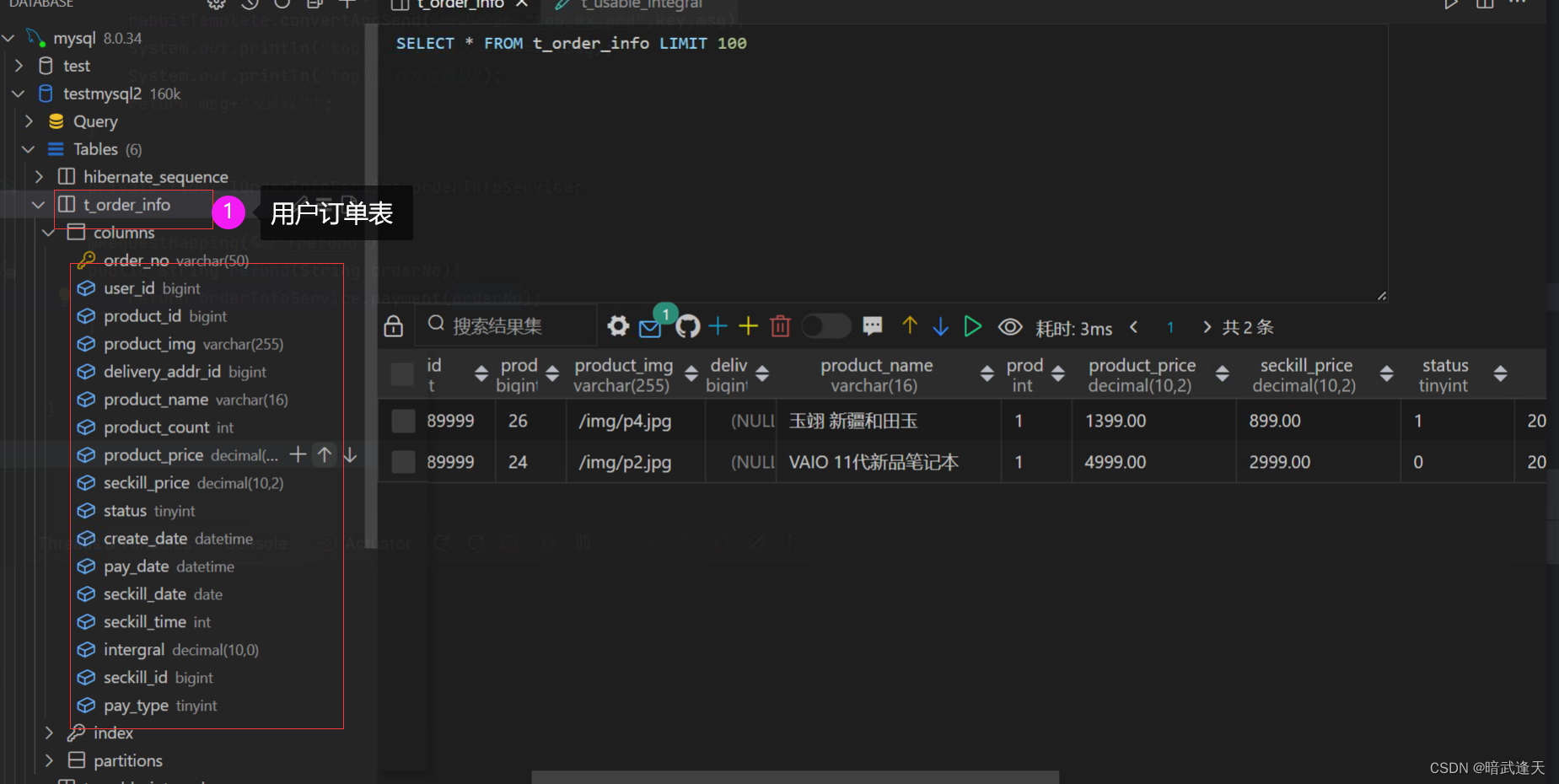
用户积分表

业务场景:
通过orderNo进行订单付款,生产者生成付款消息,付款后用户订单状态调整为已付款状态,消费者消费该消息并且为用户积分表添加在原有积分基础上添加该订单所奖励的积分,积分值这里直接取订单表中的productPrice字段数据
初始化数据库表

付款订单号为1336557511364313088订单,status付款状态初始化为0(未付款),1是付款状态
该订单目前积分为
生产者接口:
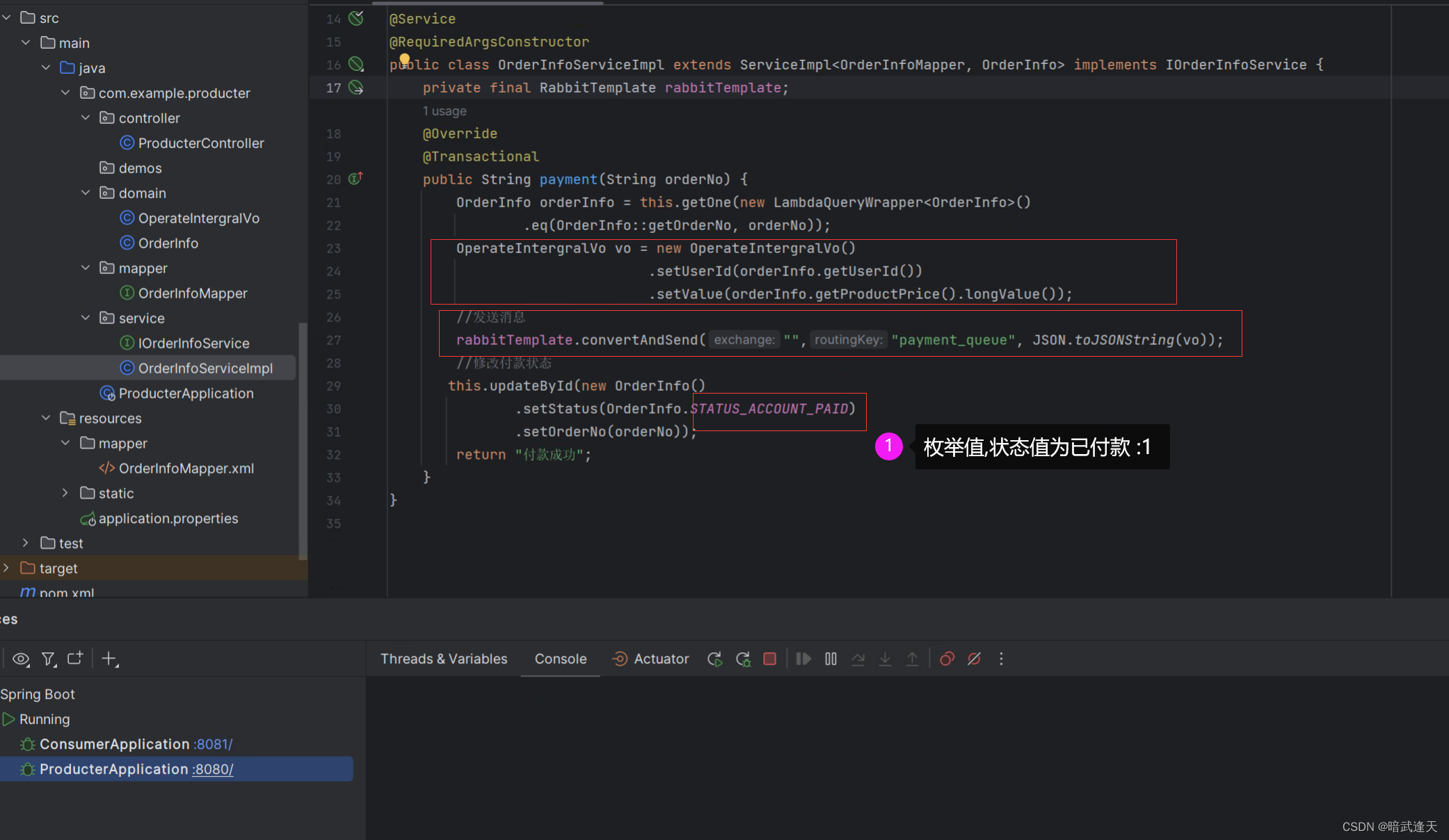
消费者监听消费

启动测试:

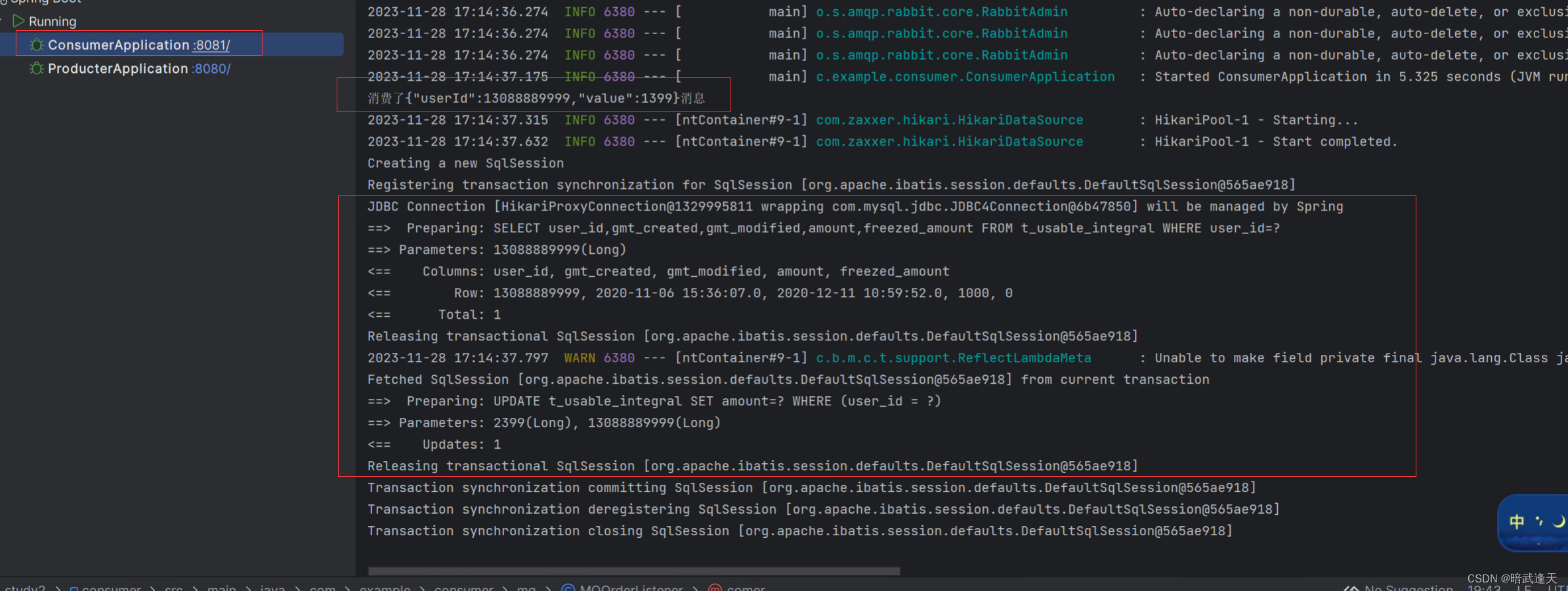
查看数据库
 积分新增成功,由原先的1000,新增了订单的productPrice的1399变为了2399
积分新增成功,由原先的1000,新增了订单的productPrice的1399变为了2399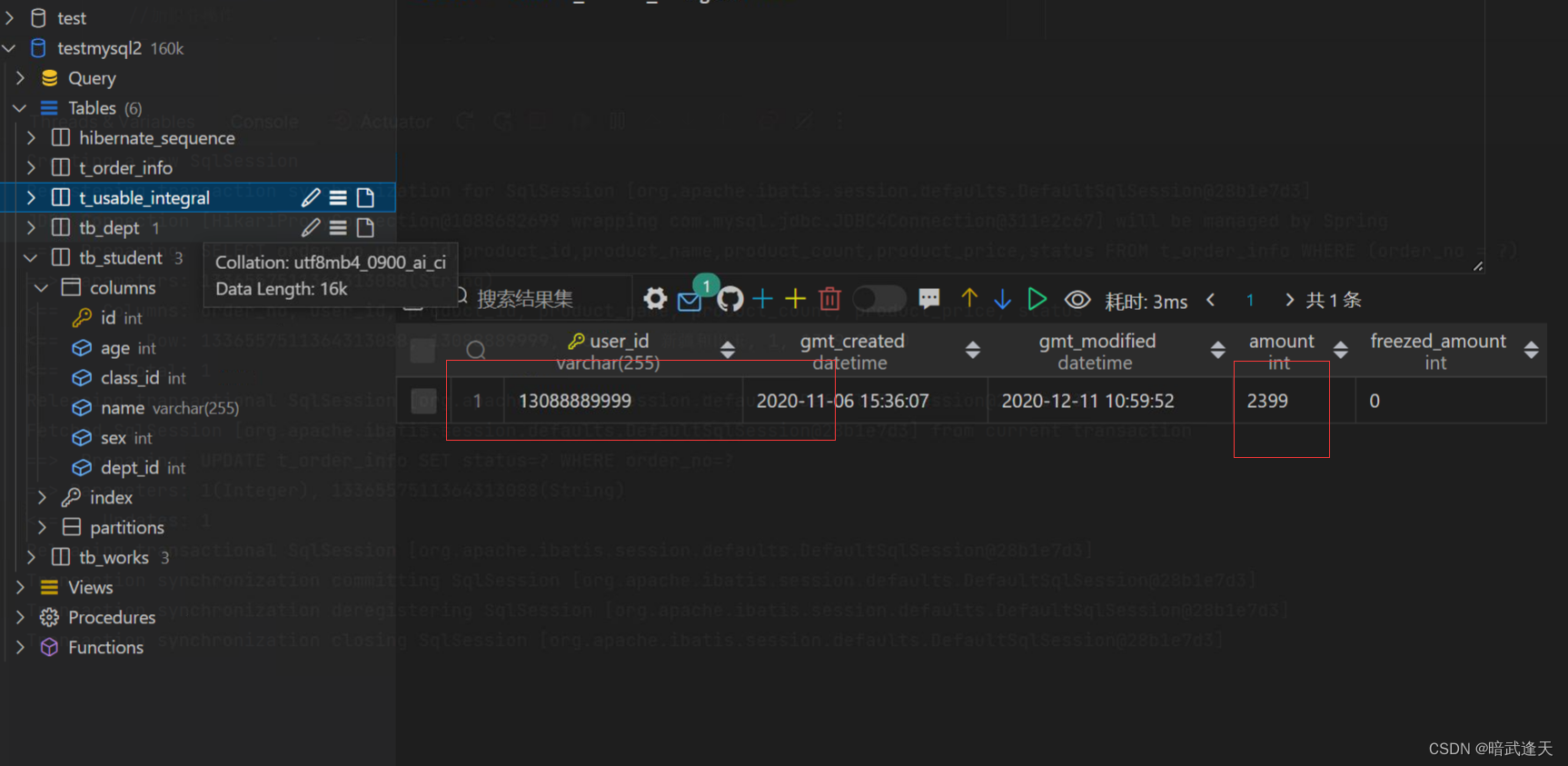
消费成功
注意在启动测试这个案例前先把之前测试时设置的手动签收和预取关掉,否则消费者不会自动实时消费生产者生产的消息
可靠性投递示例
介绍
可靠性投递是指在消息队列中确保消息得到正确且可靠地传递,即使在出现网络故障或服务器宕机等异常情况下,消息也不会丢失。在RabbitMQ中,可靠性投递通常采用以下两个概念:
-
生产者确认(Publisher Confirms):当生产者将消息发送到RabbitMQ时,会等待RabbitMQ发送确认消息,告诉生产者消息已被成功接收。如果RabbitMQ没有收到消息,或者消息发送失败,则会通知生产者重新发送消息。
-
消费者确认(Consumer Acknowledgements):当消费者从队列中接收消息时,它们会发送一个确认消息给RabbitMQ,告诉RabbitMQ已经接收到并处理了该消息。如果消费者未发送确认消息,则RabbitMQ会认为消息未被正确处理,从而重新将消息发送给消费者。
代码
生产者服务中开启配置

#开启发布确认机制
spring.rabbitmq.publisher-confirm-type=correlated
当消息经生产者投递到交换机后,为避免消息丢失,需要回调RabbitTemplate.ConfirmCallback接口,回调接口后,尤其是要对投递失败的消息进行处理或者记录下来保证消息不丢失。该接口不管消息投递到交换机成功或者失败都会进行回调,未避免消息丢失,可以选择在回调接口中只处理或者登记投递失败的消息,达到消息不丢失的目的。

交换机投递确认回调
添加发布确认组件

先在mq图像化管理中找到一个真实存在的交换机进行成功投递,查看成功投递后的回调

 测试投递
测试投递
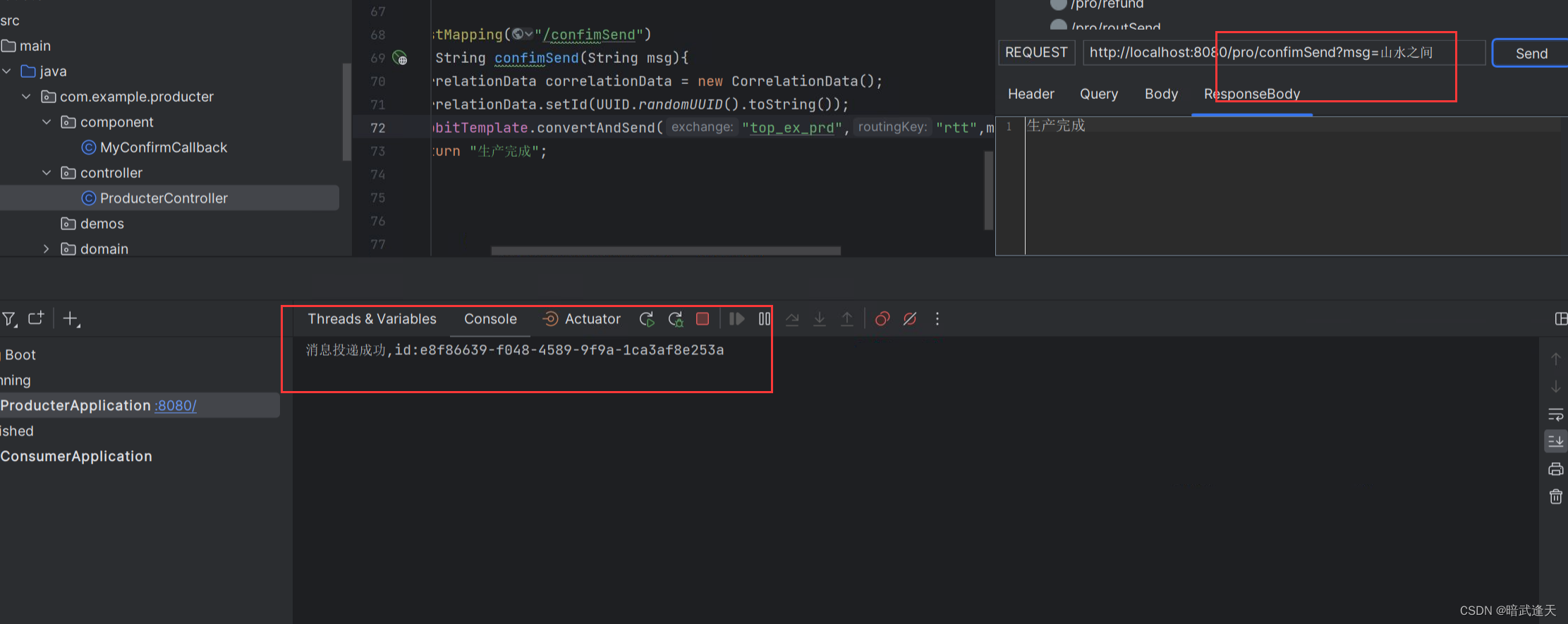
成功调用消息成功回调
再书写一个不存在的交换机模拟失败投递
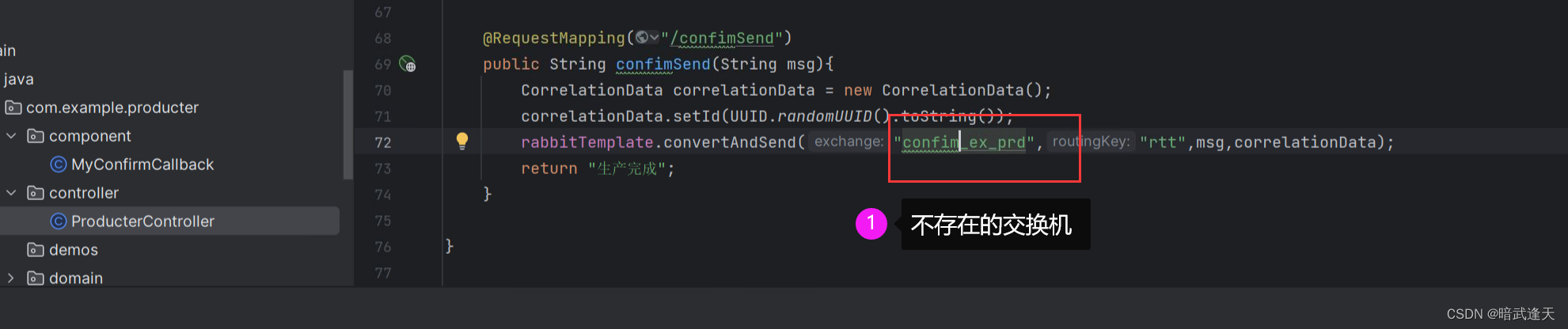
 失败回调成功执行,后续可以在这里手写失败的回调业务逻辑
失败回调成功执行,后续可以在这里手写失败的回调业务逻辑
队列投递确认回调
上面成功投递的示例中还存在一定问题,那就是交换机投递成功是后面的队列是否投递成功没有检测到,之前测试的队列是rtt,但是图型化中是没有这个队列的
消息经交换机路由到队列后回调接口ReturnCallback ,保证消息在发送队列处不丢失
消息由交换机和消息队列中异常,导致消息丢失问题,解决办法就是在添加消息从交换机路由到队列中失败后回调的接口,在回调接口中把失败的消息保存下来就可以避免消息丢失了。

所以还需要添加队列是否投递成功的监听回调
添加发布确认返回

spring.rabbitmq.publisher-returns=true
追加实现returnCallback
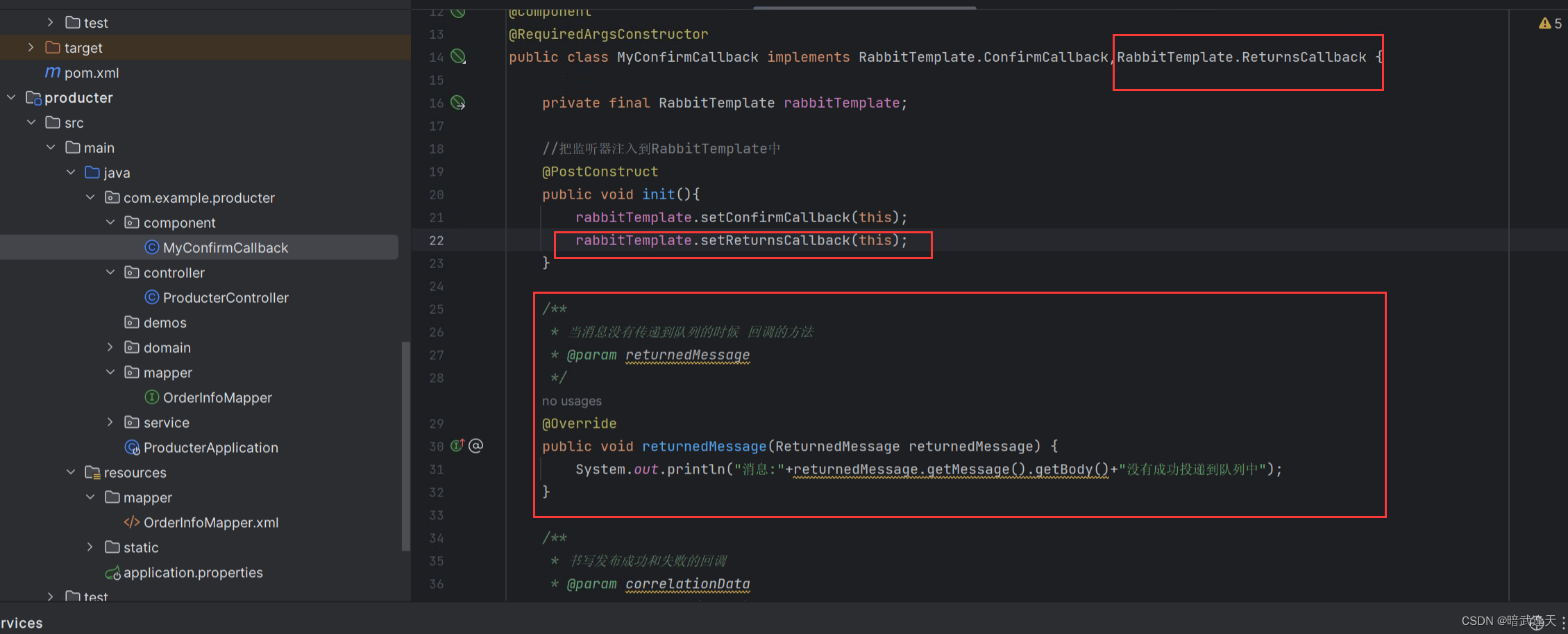
测试:
 延迟消息场景示例
延迟消息场景示例
介绍
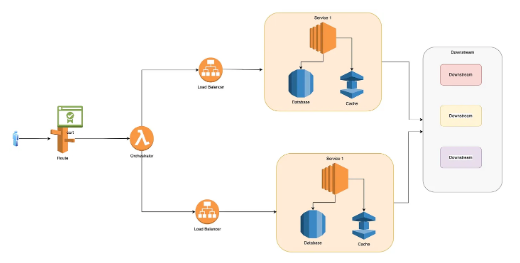
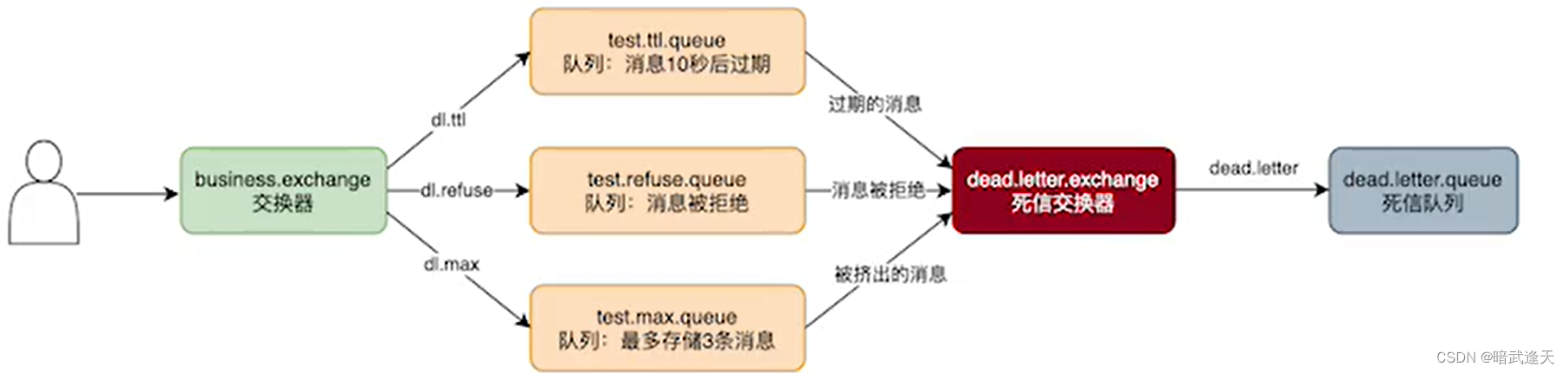
创建一个具有延时消息处理能力的队列,并将队列绑定到延时消息交换机上。此时,需要指定交换机的 delayed_routing_key 属性,表示延时发送的时间。
向延时消息交换机发送消息时,需要在消息的 headers 中添加一个 x-delay 属性,值为延时发送的时间,即 delayed_routing_key 中的值。
这样,当消息到达延时消息交换机时,会根据 headers 中的 x-delay 属性值,自动进行延迟发送。当延迟时间到达后,消息会被投递到绑定的队列中进行处理。
延时消息的实现可以确保消息在指定时间后被投递,从而提高了消息系统的可靠性和稳定性。
原理图
代码示例
图形化创建绑定交换机队列
创建死信交换机
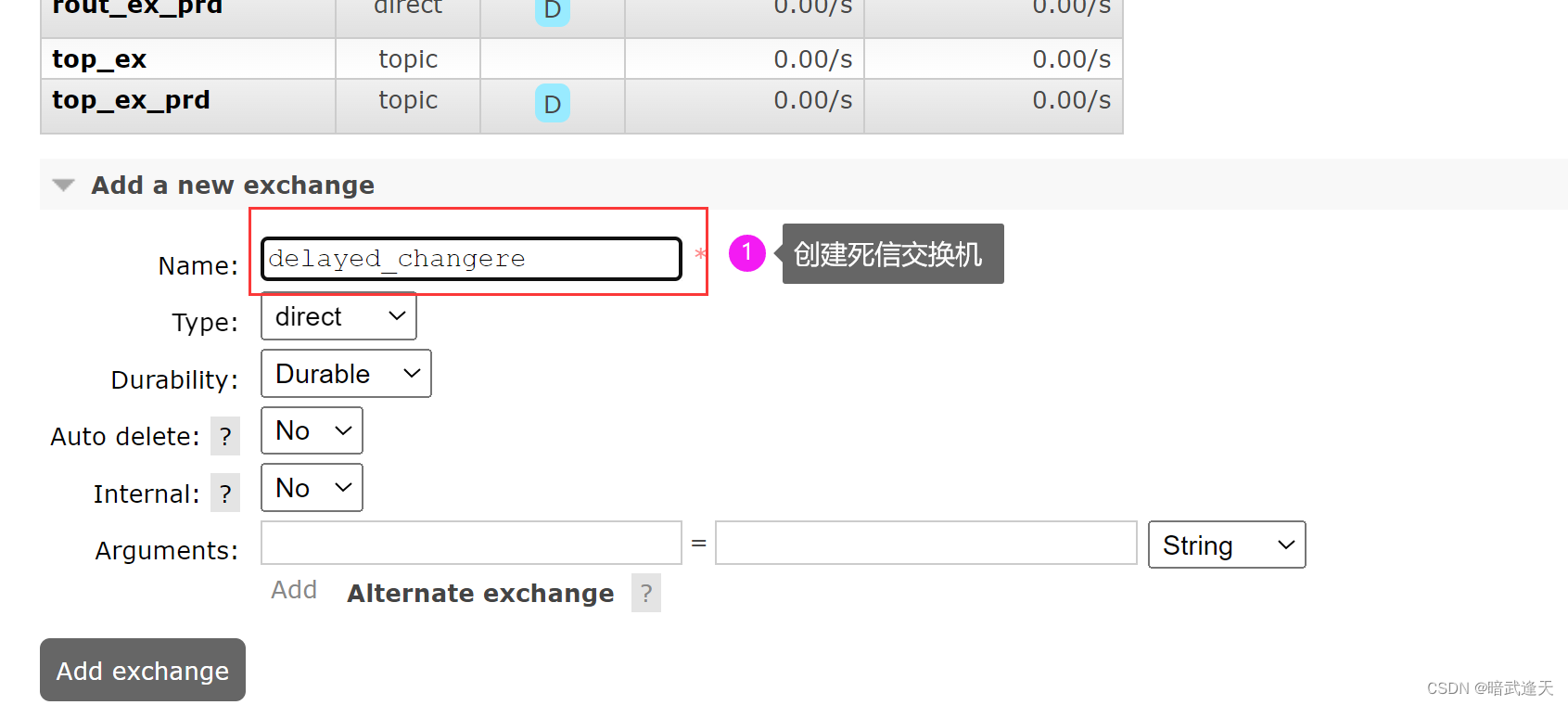
创建死信队列

创建监听的消费队列
 绑定死信交换机和两个队列
绑定死信交换机和两个队列

生产者接口
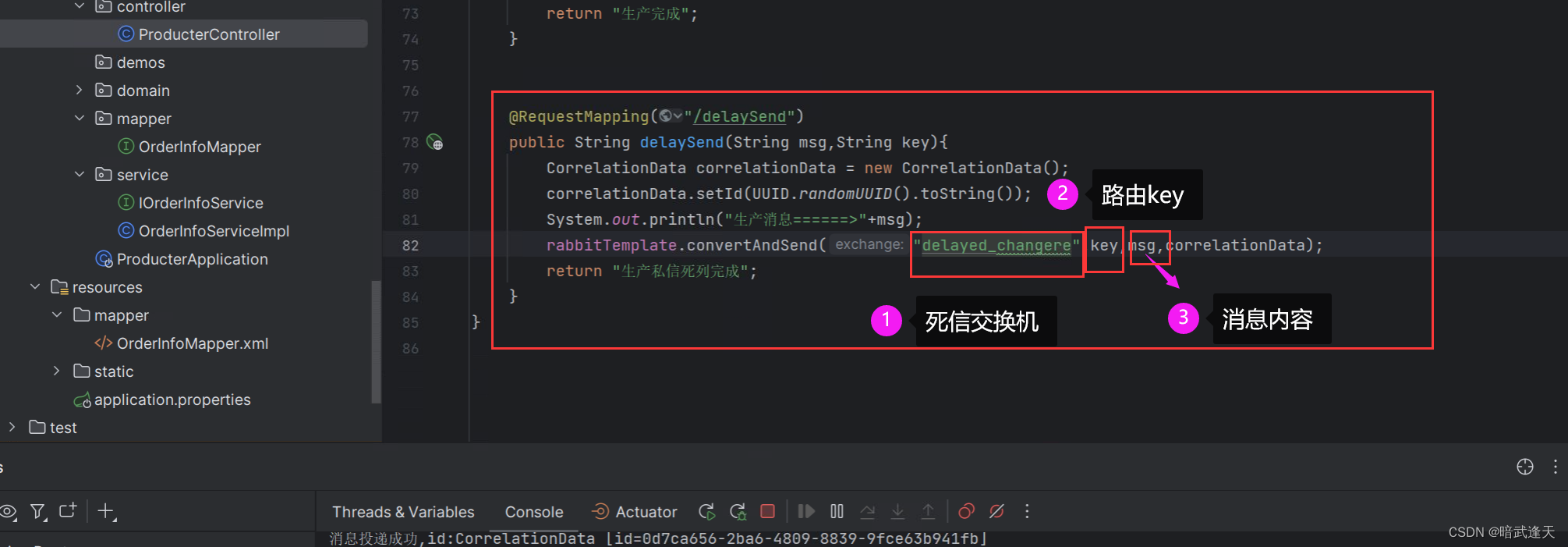
消费者监听
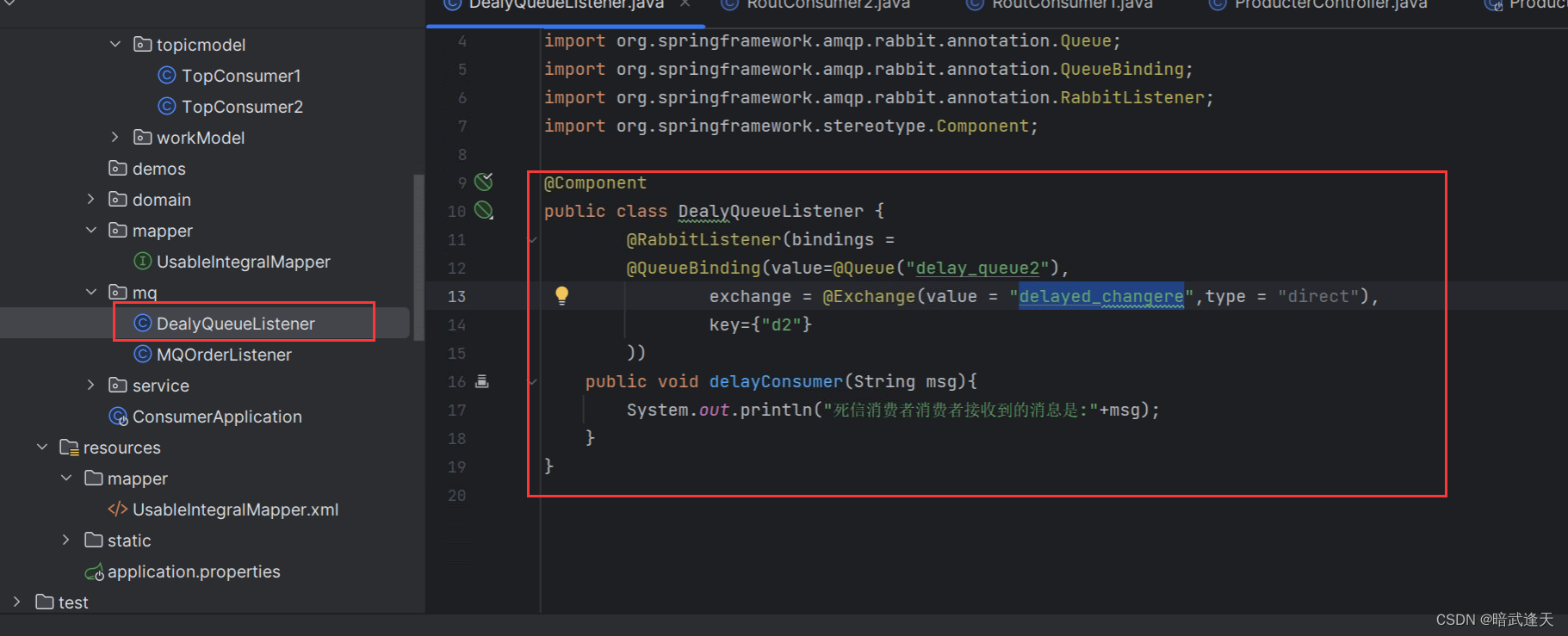
注意这里消费者监听的是delay_queue2,这是一个正常的消费队列,不是死信队列,死信队列可以理解为没有消费者监听的队列,且消息有过期时间 前面在图形化中新建死信队列时已经设置过过期时间为10000ms(10s)
启动测试:

可以看到生产者生产了几条消息后,在图形化中的delay_queue1中有消息堆叠,10秒内不会被消费掉,10秒后消费者日志才陆续进行消费打印,图形化中的消息也被消费掉不再堆叠
如果这里看的清晰,可以先将消费者停掉,直接启动生产者,看看10秒过期后消息会不会从delay_queue1自动转发到delay_queue2
停掉消费者,单启动生产者进行消息生产,观察现象
可以看到消息过期后自动转发到delay_queue2了,而delay_queue2之前消费者是正常监听的,所以由delay_queue1的消息过期时间间接就实现了延迟消息的效果
纯代码创建
死信队列中也区分一个队列过期时间和每个消息的过期时间
死信队列是一个特殊的队列,用于存储无法被消费的消息,这些消息通常被定义为无法被路由或者由于一些原因被拒绝。死信队列通常会在原始消息被拒绝、超时、过期或达到最大重试次数等情况下被触发。
队列过期时间指的是队列本身的过期时间,在该队列中的所有消息的过期时间都是一致的,在该时间到达时,队列会自动删除。而消息过期时间指的是消息本身的过期时间,在该时间到达时,消息会被标记为过期,然后会被发送到死信队列。两者的作用不同,队列过期时间控制整个队列的生命周期,而消息过期时间只控制单个消息的生命周期。
当消息过期时间配置到队列中时,当消息在队列中等待时,如果消息已经达到过期时间,那么这个消息将会被视为死信消息并被发送到死信队列中。如果队列本身已经到达过期时间,则这个队列将会被删除,而其中所有的消息也会成为死信消息并被发送到死信队列中。因此,两者的区别在于,队列过期时间会影响所有消息,而消息过期时间只影响每个消息的生命周期。
消息过期
队列过期
下面先演示代码中创建队列过期时间的例子
新建配置类创建交换机和队列并进行绑定

import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.HashMap;
import java.util.Map;@Configuration
public class RabbitMqConfig {@Beanpublic DirectExchange ttlQueueExchange(){/*** 参数一 : 交换机名称* 参数二: 当前交换机是否持久化 true表示进行持久化* 参数三: 是否自动删除 false: 不会自动删除*/return new DirectExchange("ttl_queue_exchange",true, false);}@Beanpublic Queue ttlQueue(){/*** 参数一 : 队列名称* 参数二: 队列是否持久化 true表示进行持久化* 参数三: 是否唯一绑定某一个交换机* 参数四: 表示当前队列是否删除* 参数五: 配置队列初始化参数 过期时间,队列容纳消息数等*/Map<String,Object> map = new HashMap<>();//x-message-ttl 固定属性 表示当前队列过期时间 单位毫秒map.put("x-message-ttl",15000);//x-max-length 固定属性 表示当前队列中最多可以存放的消息条数map.put("x-max-length",5);return new Queue("ttl_queue",true, false,false,map);}//消息队列和交换机进行绑定@Beanpublic Binding bindingTtlQueue(){return BindingBuilder.bind(ttlQueue()).to(ttlQueueExchange()).with("ttl_key");}
}
图形化界面中现在还有没有ttl_queue_exchange交换机和ttl_queue队列

生产者接口,之前设置队列时设置队列最多存储5条消息,过期时间15秒,这里直接生产10条消息进行测试

启动生产者进行测试:
可以看到生产者虽然生产了10条消息,但是队列中始终只存了5条消息,且15秒后队列中的所有消息自动过期,此时没有消费者服务启动,说明死信队列已生效
单个消息过期
创建消息过期交换机和队列以及绑定配置
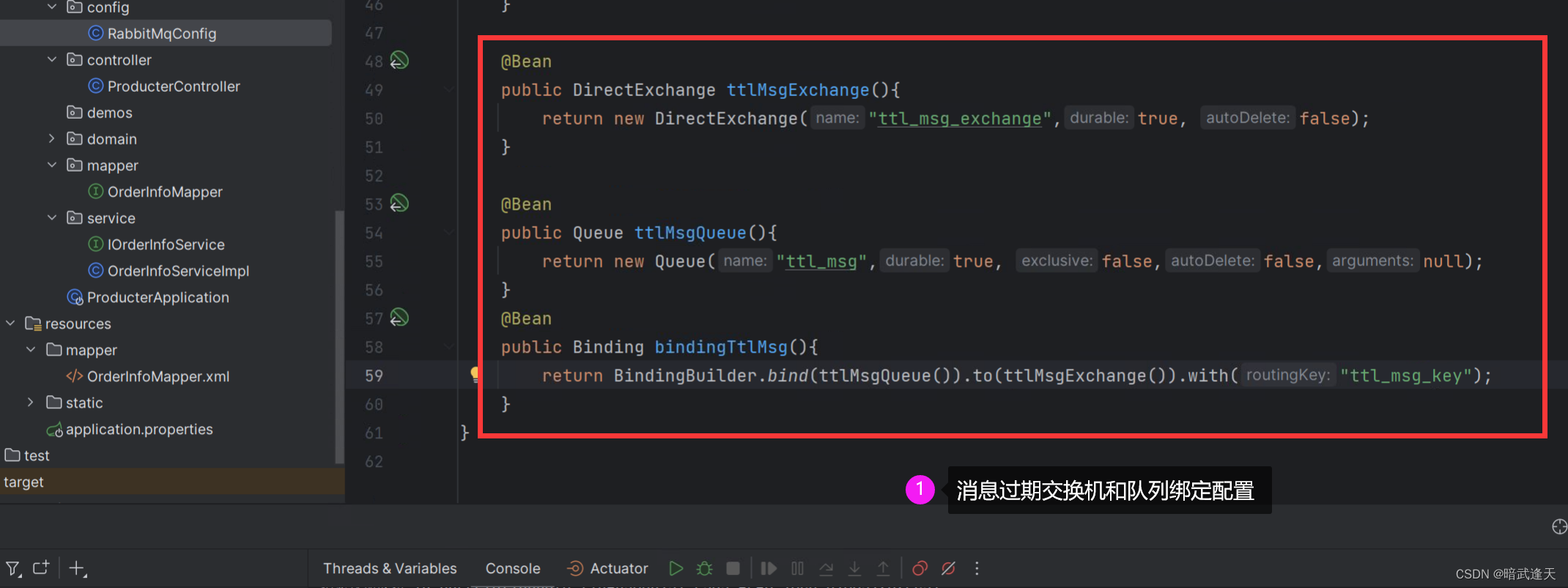
生产者接口
启动测试

可以看到该消息30秒后过期拿不到消息体了,单个消息过期设置成功
消息时间过期
当生产者的消息投递到队列后,由于消息设置的有过期时间.在指定时间内没有被消费者消费,此时队列中的消息就会成为死信队列
创建一个正常监听队列的交换机,一个没有消费者监听的过期时间队列,再创建一个监听的死信交换机和死信队列

生产者接口

启动测试,注意此时不启动消费者服务,只观察消息会不会由ttl_time_queue队列转投到dead_queue队列:
可以看到生产者在ttl_time_queue中投递一条消息后,由于没有消费者消费,该队列的消息在设置的过期时间20秒后自动转投给了dead_exchange交换机,交换机又投给了dead_letter_queue队列,由于此时没有消费者所以消息也在dead_letter_queue中没有消费,这里为了方便观察没有开启消费者,下面再启动一次有消费者版的直接观察最后死信队列的延时消费效果
监听dead_letter_queue的消费者:
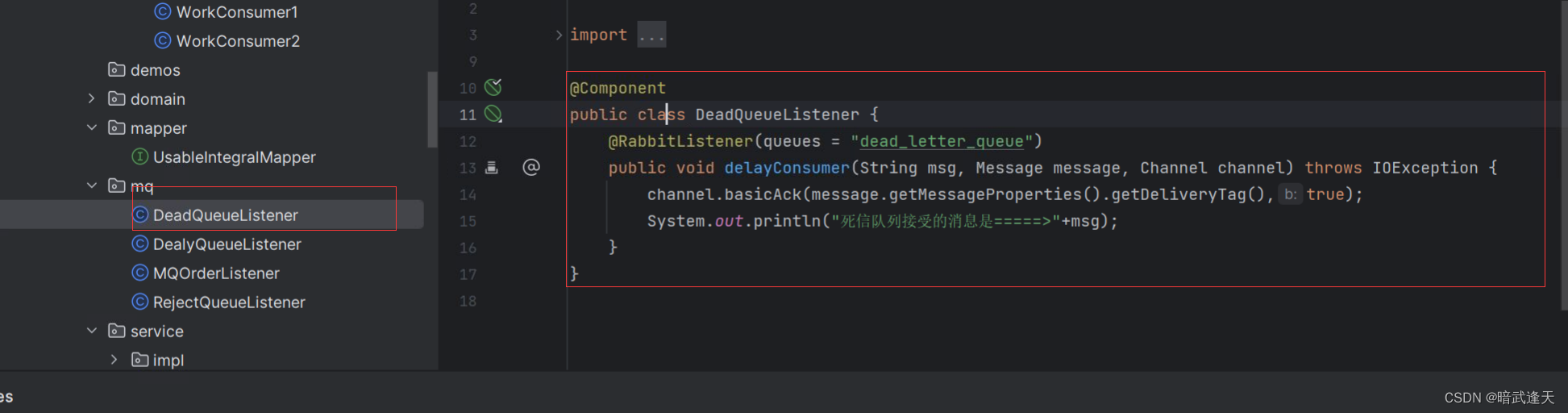
启动测试

可以看到这次ttl_time_queue过期的消息直接被监听dead_letter_queue的消费者消费了,从而间接实现了延时消费
消息溢出
当生产者投递到队列的消息数量超出队列容量时,超出的队列也会被投入到死信队列中
创建一个有规定消息数量的队列

转投的死信交换机和死信队列按照前面消息过期的书写即可
生产者接口,模拟生产10条消息
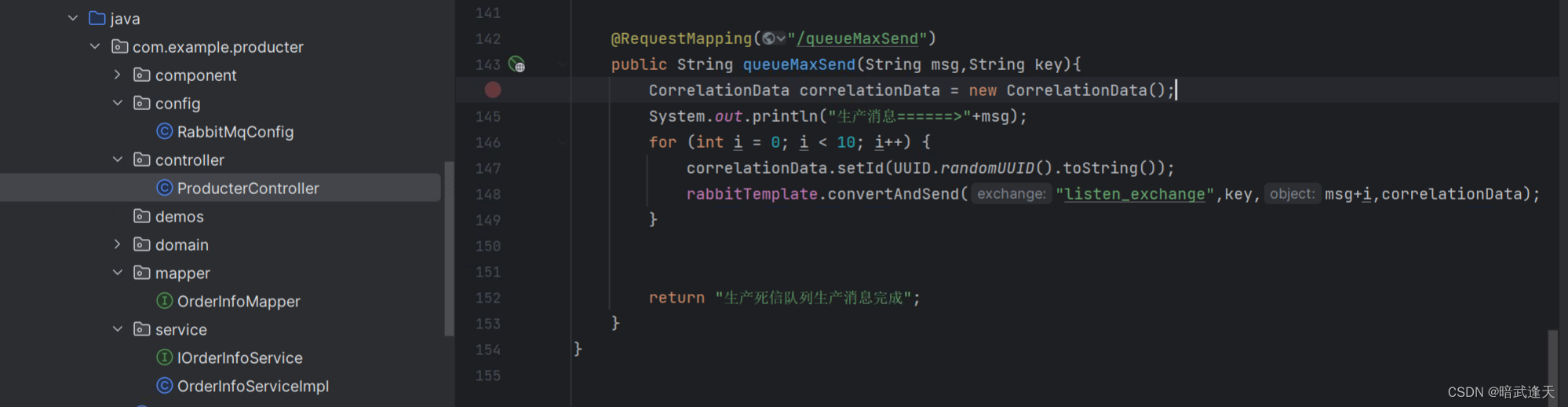
启动测试 观察现象,注意此时也不启动消费者服务,只观察消息会不会由max_queue队列转投到dead_queue队列

可以看到生产者投递了10条消息,有3条是进入到了max_queue中,剩下溢出的7条都转投到了dead_queue队列
此时再启动消费者重新投递10条消息,由于此时max_queue中已经有了3条消息,此时再投递的消息就都是溢出消息查看多出的溢出死信消息是否直接被消费掉

可以看到溢出的消息变成死信消息直接被消费掉了,从而也实现了死信队列
消息被拒
当生产者的消息投递到队列后被消费者拒绝,此时队列中的消息也会成为死信
创建reject_queue队列并配置消息拒绝后转投的交换机和路由

配置监听reject_queue队列的拒绝消费者
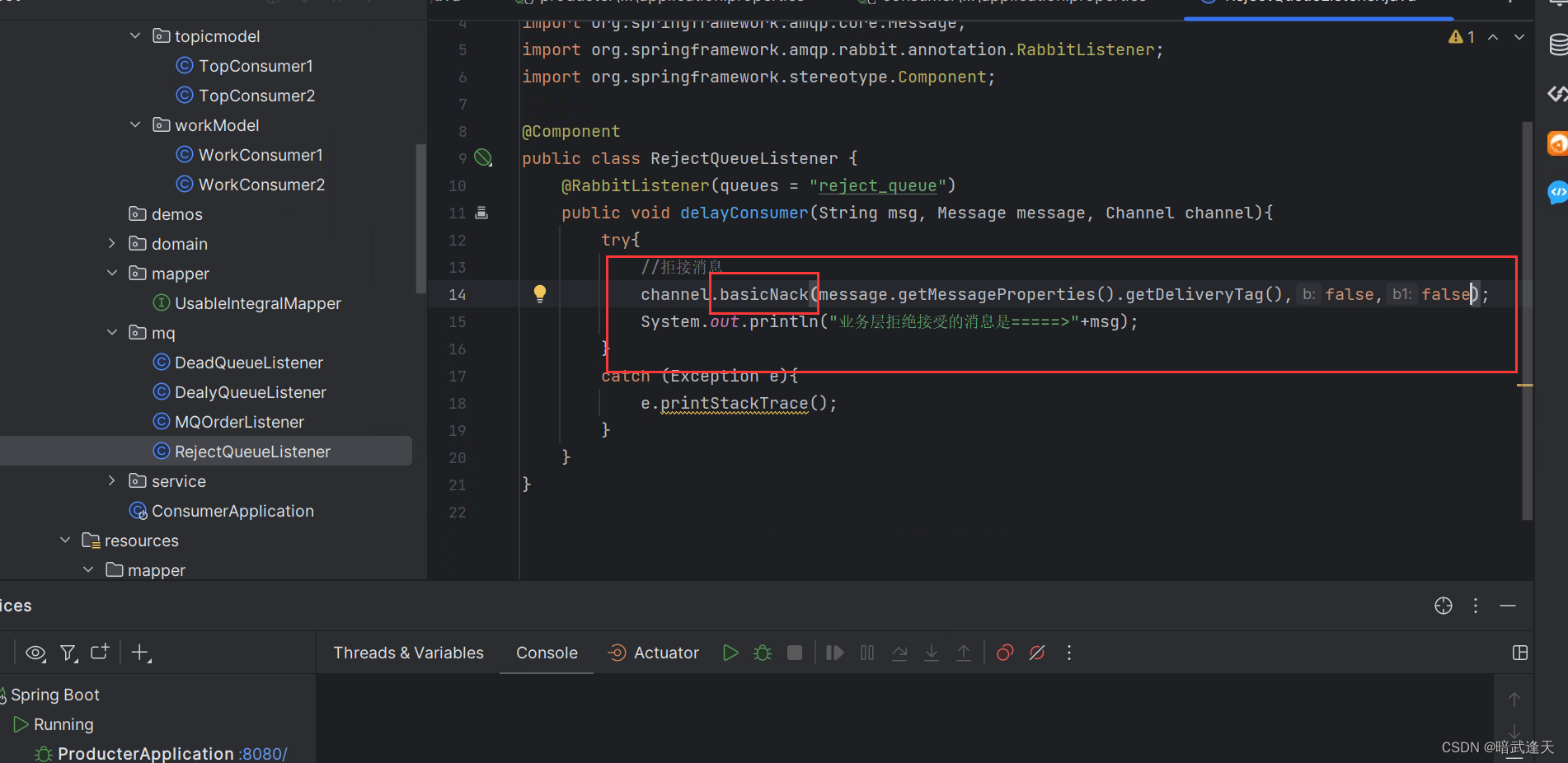
拒绝接收消息
生产者接口:
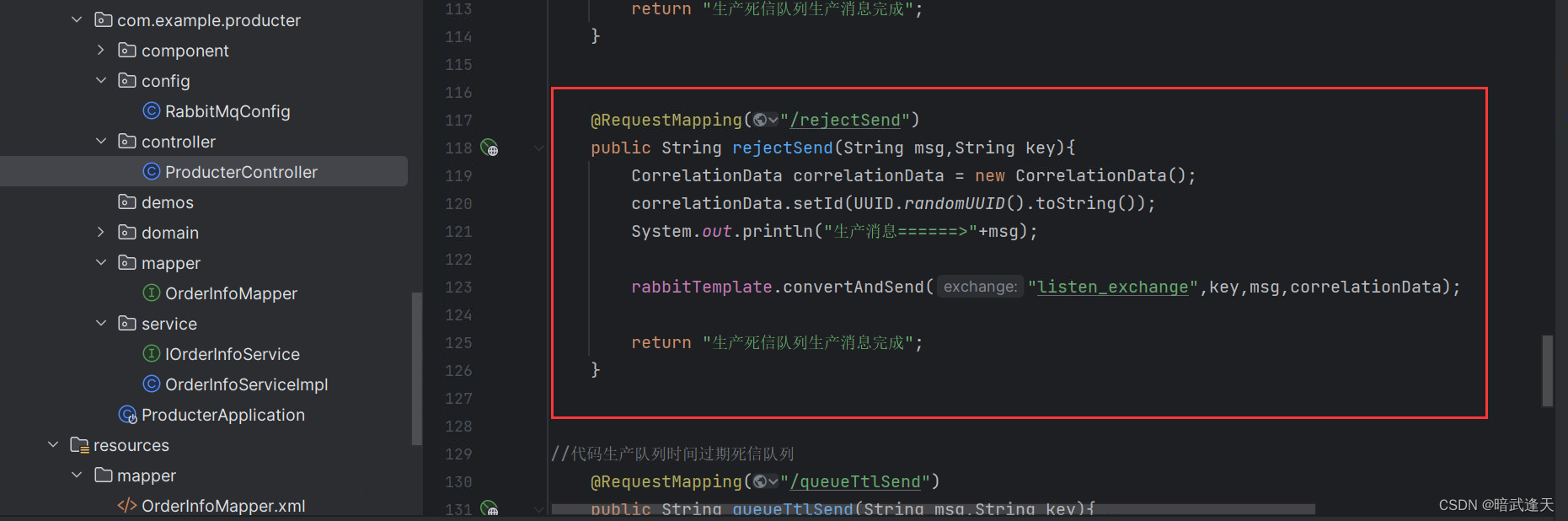
启动测试,先观察reject_queue队列被先消费者拒绝消费后消息是否自动转投到死信队列dead_letter_queue中:
可以看到监听reject_queue的消费者拒绝了该队列的消息后自动将消息转投到dead_letter_queue中了
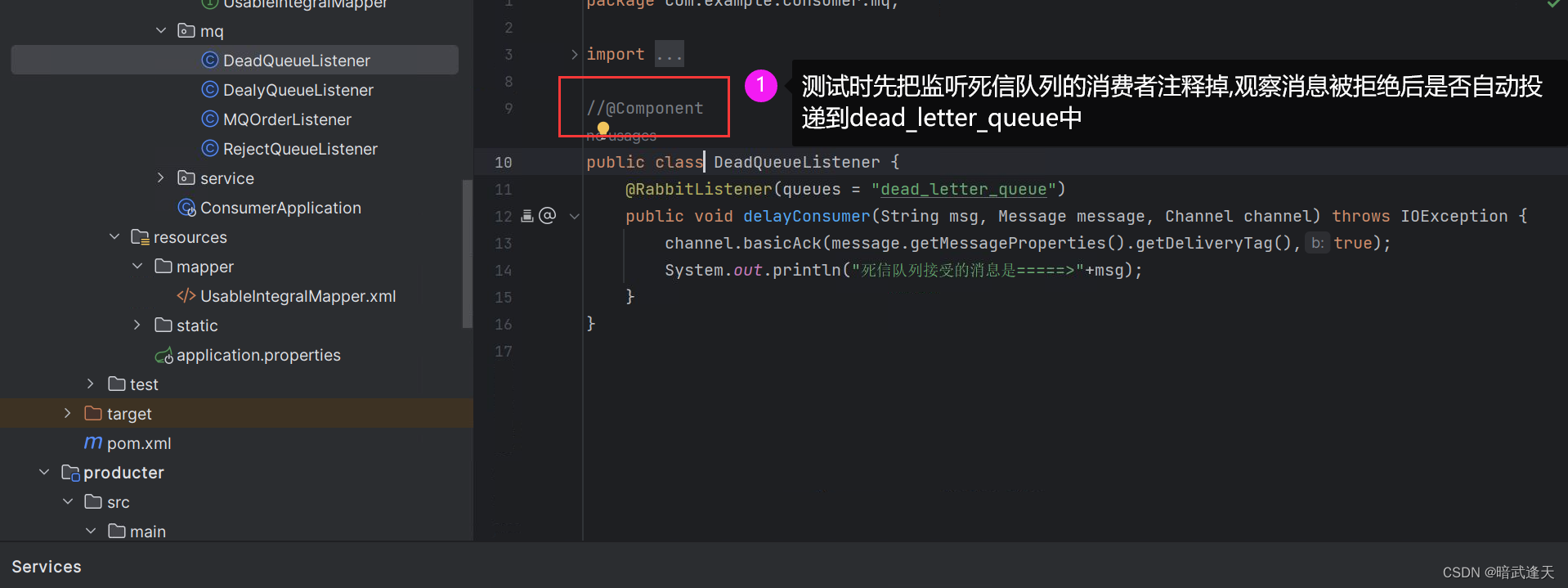
下面将监听 dead_letter_queue的消费者放开,直接测试消息拒绝的死信队列,观察其现象

启动测试:

可以看到监听reject_queue的消费者拒绝了该队列的消息后自动将消息转投到dead_letter_queue中后直接被监听dead_letter_queue的消费者消费掉了,从而也实现了死信队列
下面直接将生产者创建的交换机,队列和绑定情况贴在下面
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.HashMap;
import java.util.Map;@Configuration
public class RabbitMqConfig {//队列消息过期 交换机,队列,绑定配置@Beanpublic DirectExchange ttlQueueExchange(){/*** 参数一 : 交换机名称* 参数二: 当前交换机是否持久化 true表示进行持久化* 参数三: 是否自动删除 false: 不会自动删除*/return new DirectExchange("ttl_queue_exchange",true, false);}@Beanpublic Queue ttlQueue(){/*** 参数一 : 队列名称* 参数二: 队列是否持久化 true表示进行持久化* 参数三: 是否唯一绑定某一个交换机* 参数四: 表示当前队列是否删除* 参数五: 配置队列初始化参数 过期时间,队列容纳消息数等*/Map<String,Object> map = new HashMap<>();//x-message-ttl 固定属性 表示当前队列过期时间 单位毫秒map.put("x-message-ttl",15000);//x-max-length 固定属性 表示当前队列中最多可以存放的消息条数map.put("x-max-length",5);return new Queue("ttl_queue",true, false,false,map);}//消息队列和交换机进行绑定@Beanpublic Binding bindingTtlQueue(){return BindingBuilder.bind(ttlQueue()).to(ttlQueueExchange()).with("ttl_key");}// 单个消息过期交换机,队列,绑定配置@Beanpublic DirectExchange ttlMsgExchange(){return new DirectExchange("ttl_msg_exchange",true, false);}@Beanpublic Queue ttlMsgQueue(){return new Queue("ttl_msg",true, false,false,null);}@Beanpublic Binding bindingTtlMsg(){return BindingBuilder.bind(ttlMsgQueue()).to(ttlMsgExchange()).with("ttl_msg_key");}//监听消息的交换机@Beanpublic DirectExchange listenExchange(){return new DirectExchange("listen_exchange",true, false);}//监听消息的死信交换机@Beanpublic DirectExchange deadExchange(){return new DirectExchange("dead_exchange",true, false);}//监听消息的死信队列@Beanpublic Queue deadLetterQueue(){return new Queue("dead_letter_queue",true, false,false,null);}@Beanpublic Binding bindingDeadExchange(){return BindingBuilder.bind(deadLetterQueue()).to(deadExchange()).with("dead_key");}//时间过期队列@Beanpublic Queue ttlTimeQueue(){Map<String,Object> map = new HashMap<>();//指定给当前被拒绝消费的队列配置拒绝后消息转发的死信交换机//x-dead-letter-exchange 固定属性 表示指定的死信交换机map.put("x-dead-letter-exchange", "dead_exchange");// 设置死信交换机绑定的队列之间的路由键map.put("x-dead-letter-routing-key", "dead_key");map.put("x-message-ttl",20000);// 设置队列过期时间return new Queue("ttl_time_queue",true, false,false,map);}@Beanpublic Binding bindingTtlExchange(){return BindingBuilder.bind(ttlTimeQueue()).to(listenExchange()).with("ttl_key");}//规定数量队列@Beanpublic Queue maxQueue(){Map<String,Object> map = new HashMap<>();//指定给当前被拒绝消费的队列配置拒绝后消息转发的死信交换机//x-dead-letter-exchange 固定属性 表示指定的死信交换机map.put("x-dead-letter-exchange", "dead_exchange");// 设置死信交换机绑定的队列之间的路由键map.put("x-dead-letter-routing-key", "dead_key");map.put("x-max-length",3);// 设置队列最大容量数return new Queue("max_queue",true, false,false,map);}@Beanpublic Binding bindingMaxExchange(){return BindingBuilder.bind(maxQueue()).to(listenExchange()).with("max_key");}//消息拒绝 队列,绑定配置@Beanpublic Queue rejectQueue(){Map<String,Object> map = new HashMap<>();//指定给当前被拒绝消费的队列配置拒绝后消息转发的死信交换机//x-dead-letter-exchange 固定属性 表示指定的死信交换机map.put("x-dead-letter-exchange", "dead_exchange");// 设置死信交换机绑定的队列之间的路由键map.put("x-dead-letter-routing-key", "dead_key");return new Queue("reject_queue",true, false,false,map);}@Beanpublic Binding bindingRejectExchange(){return BindingBuilder.bind(rejectQueue()).to(listenExchange()).with("reject_key");}}
死信队列踩坑
在实际操作中博主也遇到了一些比较容易出现问题的坑,也在这里记录下
前面我们使用死信队列成功实现了延迟消息,但是在正常消费者里是需要填写监听的正常消费队列的
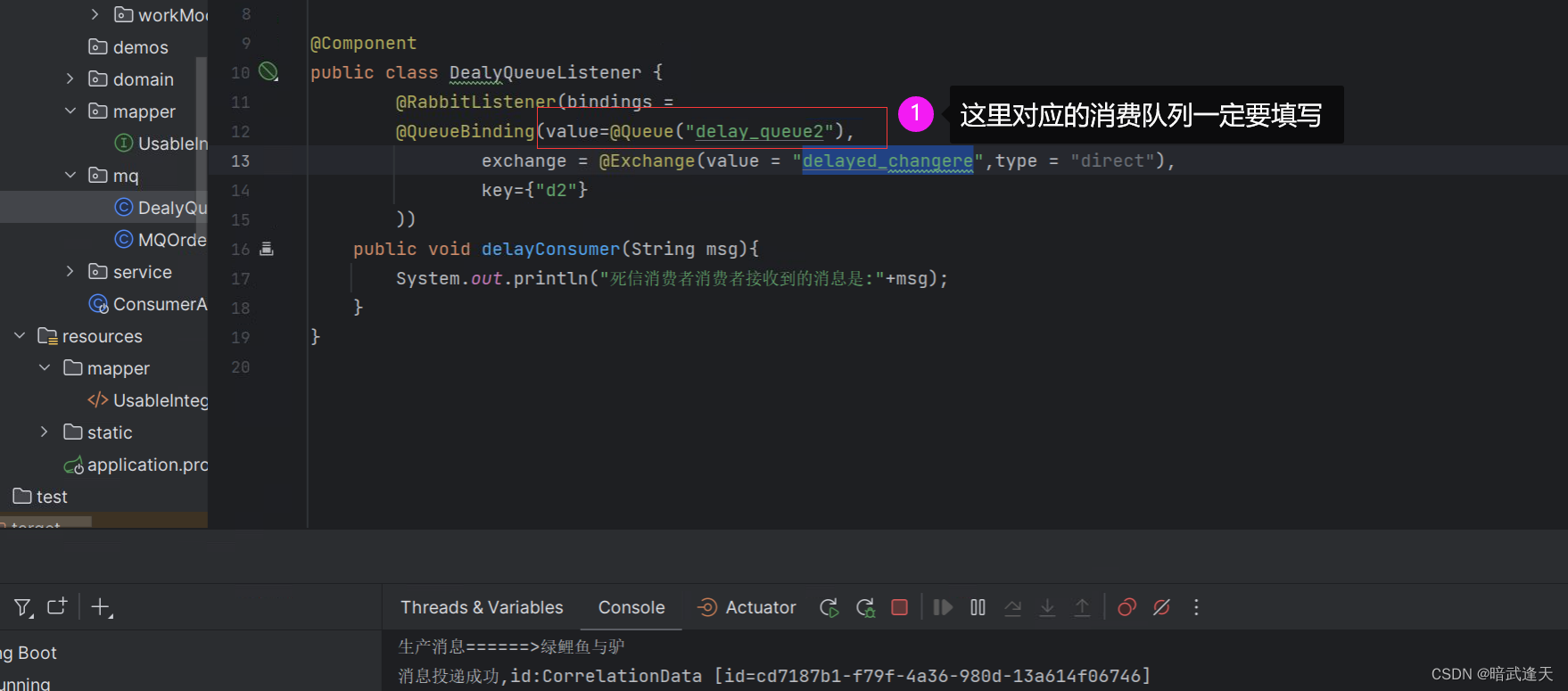
如果这里不填写队列,会造成消息一直堆叠在delay_queue2中,原先博主以为这里交换机和路由都已经绑定过了,可以不填写就行,但是事实还是狠狠打了一巴掌,把错误地方也复现下
我们把这里的队列名称去掉,其他的生产者等都不动,再启动测试看看会有什么现象

启动测试:
可以看到消费者虽然正常打印了消费日志,但是在图形化队列中队列还是一直在堆叠,博主以为只是图像化出了问题,但是把队列名重新加上后再重启消费者,消费者又重新打印消费了刚才的几条消息,而此时图像化界面队列中也不再堆叠消息了,真是大坑一个
此处如果填了队列名,代码中不再填写路由key也是可以正常消费的,看示例

删除路由key,重新测试
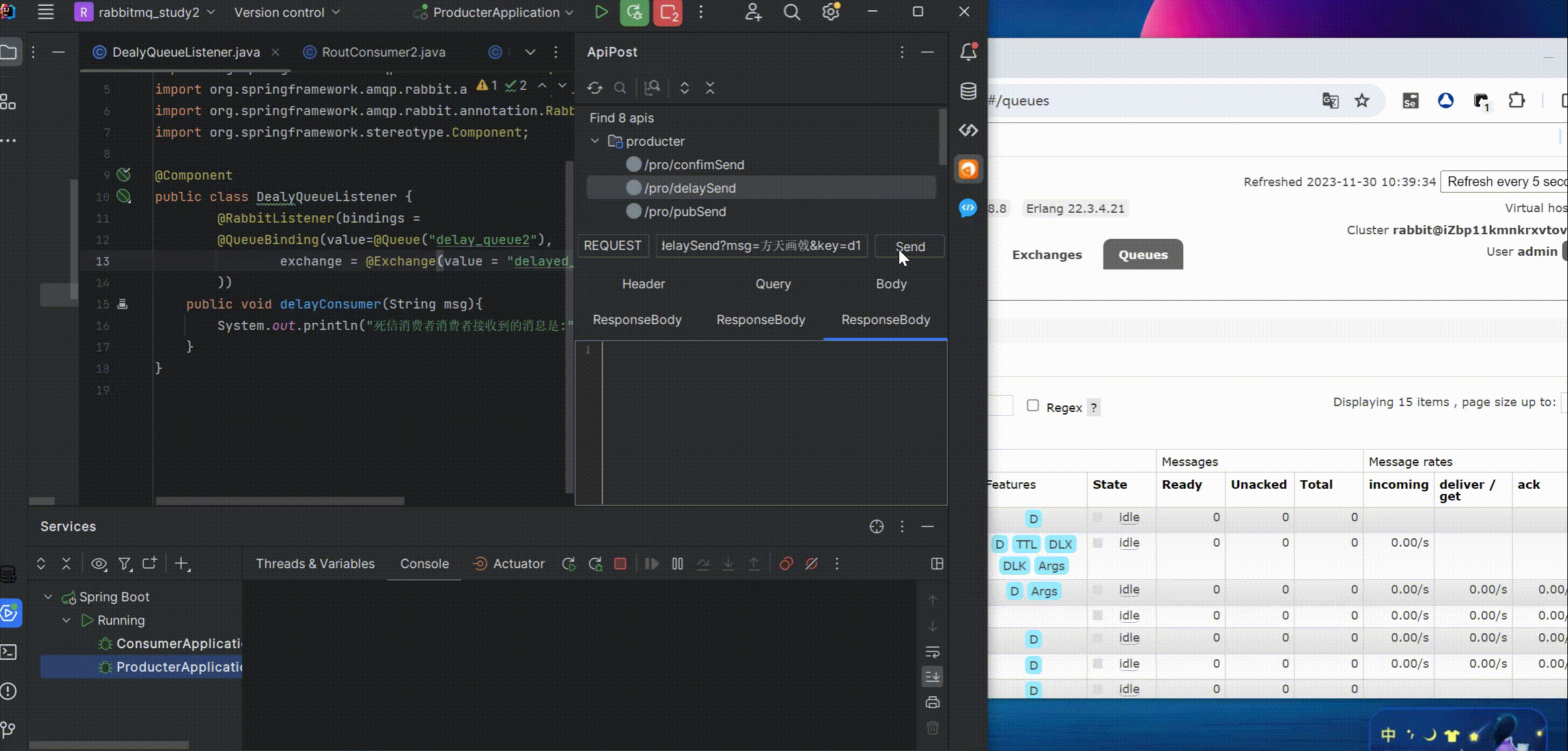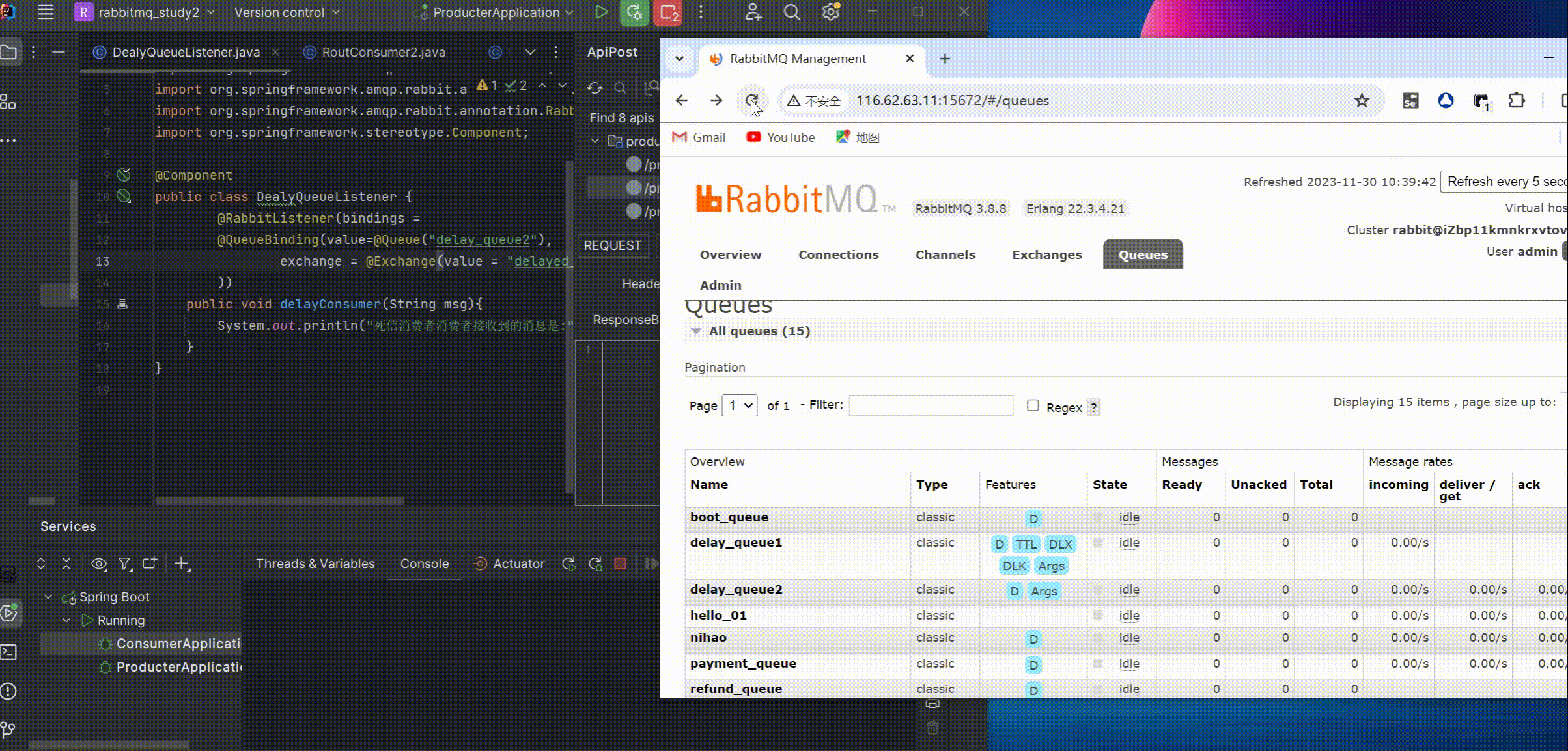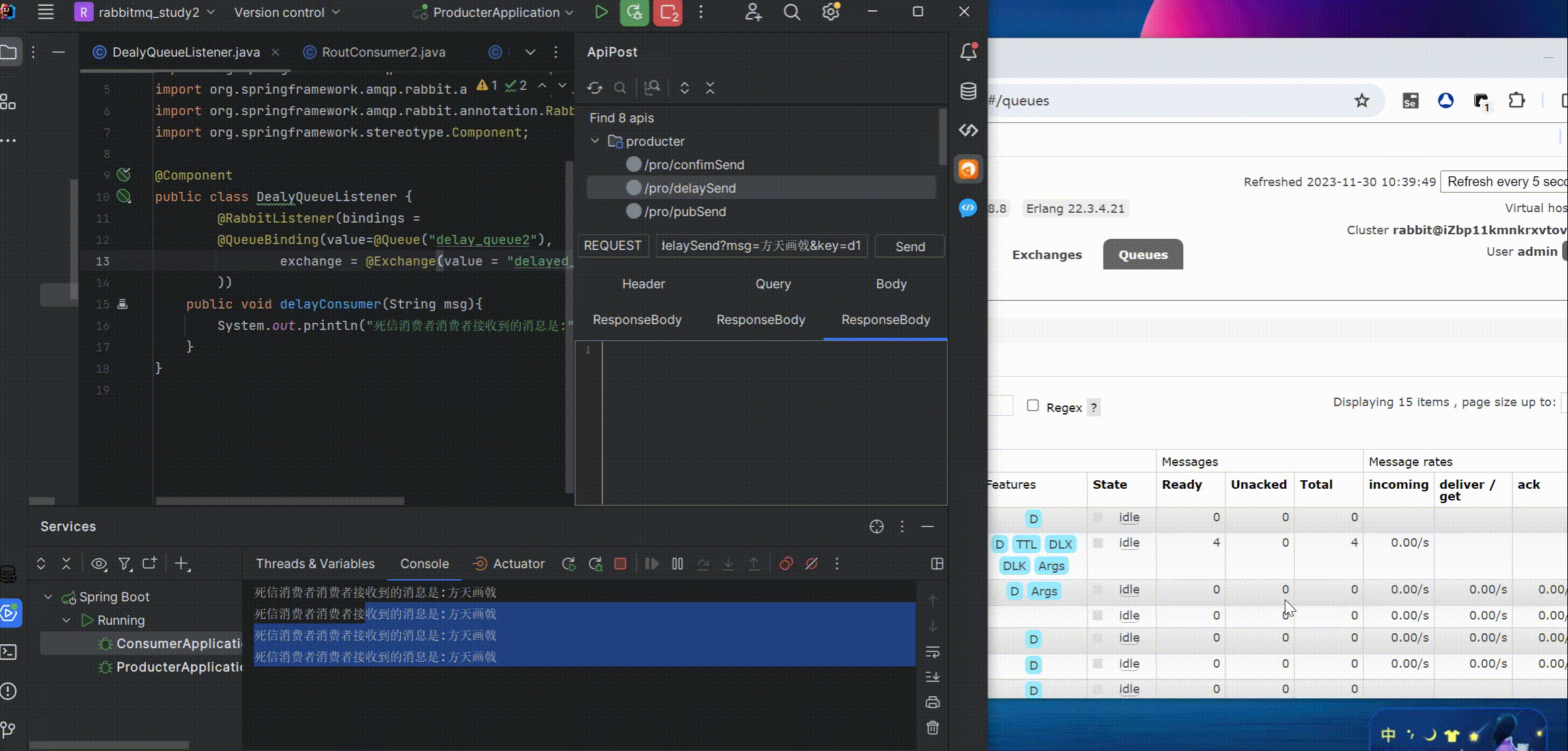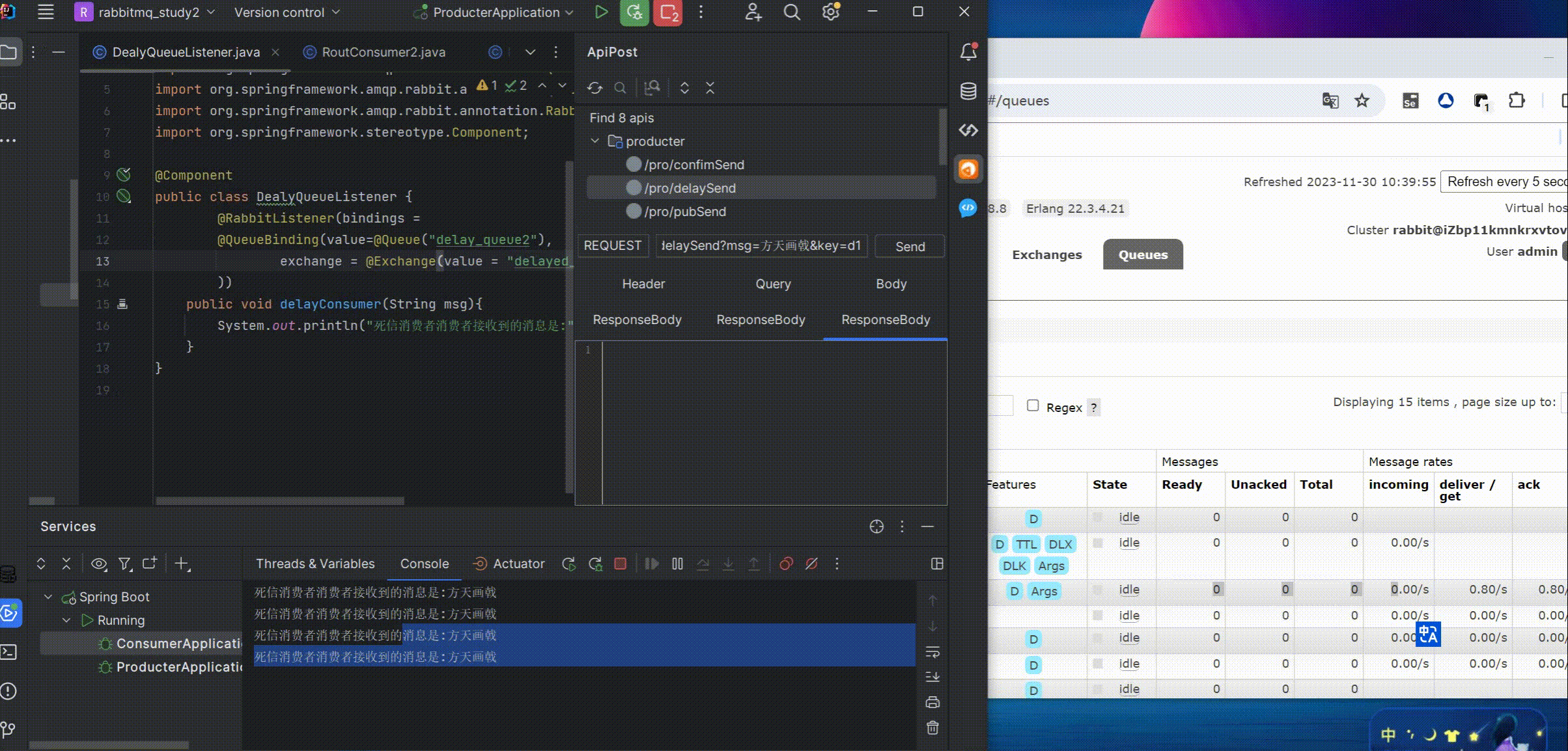
可以看到路由key在图形化界面中已经绑定了,这里不用再指定也可以正常消费
源码
需要以上练习源码demo的小伙伴请自取
rabbitmq实战场景源码