InstructGPT论文详解(Training language models to follow instructions with human feedback,学习ChatGPT必看论文)
返回论文和资料目录
1.导读
继ChatGPT大火后,越来越多人想了解ChatGPT相关技术。OpenAI官网虽然没有给出ChatGPT足够详细的信息,但给出了一篇推荐阅读论文InstructGPT,经过对比,可以发现两者技术相差不大,所以完全可以通过InstructGPT了解ChatGPT。下面就给出InstructGPT内容详解。
阅读本文内容最好提前了解GPT1-GPT3。
2.摘要和概述
这篇文章企图解决的问题:已有的大型语言模型(例如GPT3.5)并非模型越大越好。越大的模型仍然会生成假的、有害的、简单的和没有用的内容。简单的说,得不到用户想要的内容。
解决方法:1.人工引导,使用监督学习。2.强化学习,人工帮助的情况下,训练一个模型,该模型会进一步引导GPT模型生成优质的结果。
实验结果:InstructGPT使用1.3B参数的模型对比GPT-3的1750B参数模型能取得更优的性能(即能生成更优,更有用,更安全,更无害的内容,调戏过ChatGPT的人应该更有体会)。
3.引言
已有大型语言模型经常会生成不想要的内容(很好理解,因为目标函数只是预测下一个词和数据集信噪比高的原因)。
所以,本文使用微调的方法在一个大型语言模型LM上进行改进。大致思路是:首先,收集大量的指令prompt(可以理解为问题,但实际是指令大于问题,例如帮我写一首诗是一个指令,但具体问题的时候我们可能不是这么问的,即我们有多种问法,所以一个指令对应于多个问题),让人工提供答案,扩充数据集,进行第一步的引导。其次,人工给LM的回答进行排名,并用这些排名作为标签label。以(prompt,label)形式训练一个RM模型,该训练完成后模型能对LM生成的答案进行打分,告诉LM哪些是好的回答。最后,RM会作为一个奖励函数,同时使用PPO算法微调GPT模型最大化RM奖励函数。
评估:使用未在数据集中出现的prompt,采用人工的方式对GPT模型生成的结果进行打分。
模型:InstructGPT模型考虑3种设置方案:1.3B,6B,150B。模型的结构和GPT-3保持一致。
实验结果:
- 在人工打分结果上,InstructGPT显著优于GPT-3
- InstructGPT的结果比GPT-3更真实,即不会瞎说(但从ChatGPT的结果来看,还是有待提高)
- InstructGPT的结果比GPT-3更不会有害,即不会有种群歧视之类的
- 面对具体的NLP数据集,还可以改进
- 面对没有出现的人工引导的prompt, InstructGPT的结果也会更好,即 InstructGPT模型得到了推广
- InstructGPT效果会比使用一般的公开的NLP数据集后的GPT模型更好
- InstructGPT仍然会犯简单的小错误(从ChatGPT的结果来看确实)。
4. InstructGPT流程
InstructGPT流程如下图所示。可以分成3个阶段:
- 阶段一:在这个阶段前,我们首先有一个大型语言模型GPT-3.5。然后,我们随机从指令库中采样出一些指令prompt,并人工给出答案。最后,将这些指令和答案作为新的数据集进一步训练GPT-3.5模型,这里是由人工给出的答案作为标签,所以是有监督学习。我们将这一阶段完成后的模型称为SFT(supervised fine-tuning )。
- 阶段二:使用SFT对指令库中的指令生成多个答案。然后人工对这些答案进行排名。使用这些排名训练一个奖励模型RW,即可以通过这个模型对一个指令的多个回答给出奖励值。
- 阶段三:从指令库中采样一批指令,让SFT回答多个答案,并使用RW给出预测的奖励值。最后,使用奖励值采用PPO算法更新模型。

5.数据集
我觉得主要包含4个数据集,并且刚好4个数据集对应于不同的阶段。第2、3和4个数据集对应于InstructGPT流程的第1-3个阶段,而第1个数据集对应于第一个阶段前的训练GPT3.5模型的阶段。
在了解4个数据集前要先了解OpenAI先做了个指令库数据集
指令库数据集:前面多次提到指令库,这个指令库来自于OpenAI以前的GPT模型提供的API中收集的用户问题。但这些问题经过了一定的处理,包括去除重复,限制每个用户最多200个指令,去除个人身份信息等。下表Table1给出了来自API的指令分布。然而,这个处理好后的指令库数据集也并不全面,好用。所以InstructGPT让人工(请的labelers)写了3类指令进行扩充:(1)Plain:尽可能广地写各种指令,增加多样性。(2)Few-shot:写出一些指令,并给出多对(问题,回答)。(3)User-based:根据刚才OpenAI提供的API中得到的用户的请求队列waitlist中收集用户需求,并写出对应的指令。

下面是InstructGPT用到的4个数据集:
- 已有的用于训练GPT3.5的数据集:这个数据集主要来自NLP数据集、网络爬虫和OpenAI从其他公司拿来的。可参考GPT-3(Language Models are Few-Shot Learners)的工作。
- 训练SFT的模型(数据量:13k):来自指令数据库中的API和人工写的(prompt,answer),用于第一阶段初步训练InstructGPT。
- 训练RM的排名数据集(数据量:33k):首先从指令数据库中的API和人工写的指令中获得指令,再使用InstructGPT进行回答,人工给InstructGPT的回答进行排名得到排名数据集(prompt,Rank)。该数据集会用于训练得到一个RM模型。
- PPO数据集(数据量:31k):只从指令数据库的API中获得指令,并使用InstructGPT和RM模型分别得到answer和RM给出的分数。最后这个数据集由多个三元组(prompt,answer,RM给出的分数)组成,用于进一步微调采用PPO算法微调InstructGPT。
总结:InstructGPT特有的数据集并不大,13k-33k对于一个公司来说是很小的了。不过仍然有效,能显著提升模型性能。
6.模型的训练
SFT(Supervised fine-tuning ):第一阶段训练的模型SFT。具体地,迭代轮数使用16个epoch、学习率使用余弦衰减、模型残差连接dropout率为0.2。模型结构为标准LM。
RM:第二阶段训练的奖励模型,模型结构是在SFT基础上去掉了最后的unembedding层,并以(prompt,answer,Reward)训练模型。在这,模型一个prompt输出了KKK个结果,所以有(K2)\binom{K}{2}(2K)次比较,OpenAI让labeler对这些比较都进行了标注。模型大小为6B。模型的损失函数为:
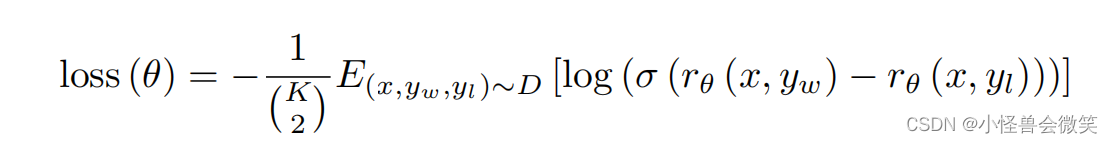
其中xxx是prompt,ywy_wyw是标出的更优的answer,yly_lyl是标出的更差的answer。rθ(x,yw)r_\theta(x,y_w)rθ(x,yw)是模型对xxx和ywy_wyw的输出奖励值rrr,rθ(x,yl)r_\theta(x,y_l)rθ(x,yl)是模型对xxx和yly_lyl的输出奖励值rrr , rθ(x,yw)−rθ(x,yl)r_\theta(x,y_w) - r_\theta(x,y_l)rθ(x,yw)−rθ(x,yl)是两者的差值,训练时需要最大化这个差值,即最小化损失函数。
模型训练超过一个epoch后会过拟合,故只训练一个epoch。
RL(PPO):第三阶段用PPO微调SFT。其目标函数如下, 我们需要最大化它。
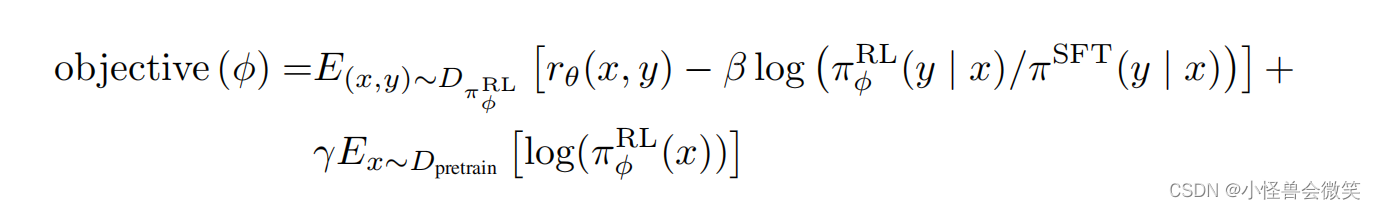
理解时,xxx和yyy分别是prompt和answer
rθ(x,y)r_\theta(x,y)rθ(x,y)是模型对xxx和yyy的输出奖励值rrr,即我们要最大化这个奖励,越大越好。
πRL(y∣x)\pi^{RL}(y|x)πRL(y∣x)是RL模型在给定xxx后输出yyy的分布,πSET(y∣x)\pi^{SET}(y|x)πSET(y∣x)是SFT模型在给定xxx后输出yyy的分布。
我们希望βlog(πRL(y∣x)/πSET(y∣x))\beta \log \left(\pi^{RL}(y|x)/{\pi^{SET}(y|x)}\right)βlog(πRL(y∣x)/πSET(y∣x))越小越好,即两个分布尽量一致。(这里有个背景要说下,由于RL模型是在原SFT模型的最后一层出修改得到的,所以RL模型输出和SFT模型输出不一致。另外,当在优化RL模型时这种不一致会越来越大,因此,我们加上了这一个项。)
最后一项γγγ为0,不用管,详情可看PPO原文。







![前沿重器[31] | 理性聊聊ChatGPT](https://img-blog.csdnimg.cn/img_convert/b516f7e4bd463d54fec34dc524ec9243.png)