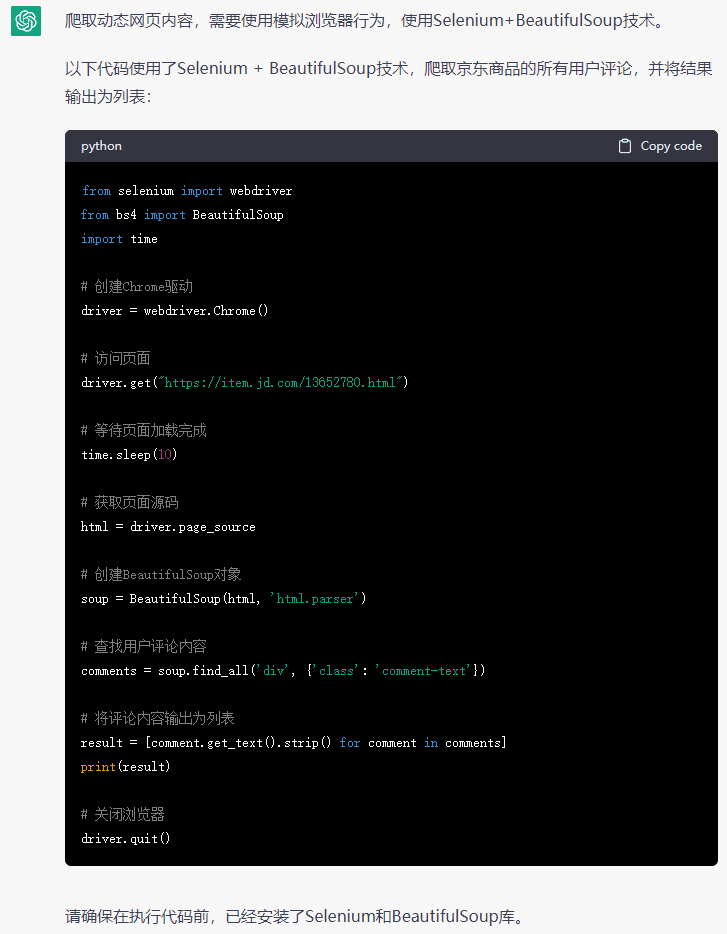
在许多自然语言处理(NLP)任务中,文本数据增强是克服样本量有限挑战的有效策略。
目前的文本数据增强方法要么不能保证生成数据的正确标记(缺乏可信度),要么不能保证生成数据的足够多样性(缺乏完整性),要么两者兼有。
ChatGPT在具有无与伦比的语言丰富性的数据上进行训练,并采用了具有大规模人类反馈的强化训练过程,这使得模型与人类语言的自然性具有亲和力。我们的文本数据增强方法ChatAug将训练样本中的每个句子重新表达为多个概念相似但语义不同的样本。然后,增强样本可以用于下游模型训练。
假设llm的发展将做到人类级别的注释性能,从而彻底改变NLP中的few-shot和多任务领域。
数据增强
数据增强,即通过转换人工生成新的文本,被广泛用于改进文本分类中的模型训练。在NLP中,现有的数据增强方法在不同的粒度级别上工作:字符、单词、句子和文档。
目前的文本数据增强方法问题:
•不能保证生成数据的正确标记(缺乏可信度),
•不能保证生成数据的足够多样性(缺乏完整性),
Few-shot Learning
Few-shot Learning ,专注于开发解决方案以应对小样本量的挑战。 FSL 研究旨在利用先验知识快速泛化到仅包含少量标记样本的新任务。 few-shot learning 的一个经典应用场景是当由于隐私、安全或道德考虑而难以或不可能获得监督示例时。
因此,本文提出的 ChatAug 方法已证明能够生成准确和全面的训练样本,可以克服当前 FSL 方法的问题,并有可能改变 NLP 中少样本学习的格局。
Very Large Language Models
大型语言模型旨在学习输入文本的准确潜在特征表示。这些大型语言模型的核心是受 BERT 和 GPT 启发的转换器模型,尽管规模要大得多。非常大的语言模型可以潜在地消除微调的需要,同时保持竞争性能 。
ChatGPT 基于 GPT-3 ,GPT-3 是在海量 Web 数据上训练的,信息多样且丰富。此外,ChatGPT 通过人类反馈强化学习 (RLHF) 进行训练。在 RLHF 期间,人类反馈被纳入生成和选择最佳结果的过程。更具体地说,奖励模型是根据人类注释者的排名或生成的结果来训练的。反过来,这个奖励模型奖励最符合人类偏好和人类价值观的模型输出。
method
Overall Framework
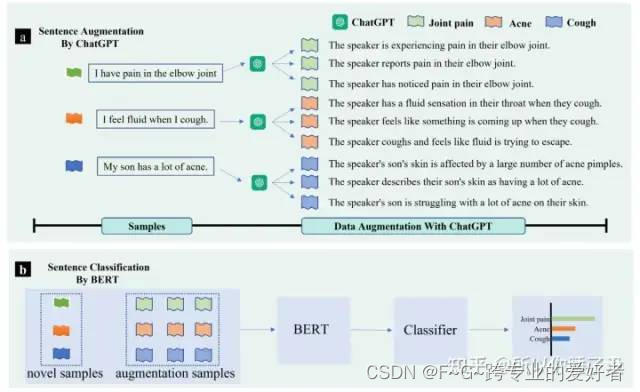
a(上图):首先, ChatGPT 进行数据扩充。将所有类别的样本输入 ChatGPT 并提示 ChatGPT 生成与现有标记实例保持语义一致性的样本。 b(下图):下一步,在少量样本和生成的数据样本上训练基于 BERT 的句子分类器,并评估模型的分类性能。
训练算法步骤:

Data Augmentation with ChatGPT
与 GPT 、GPT-2 和 GPT-3类似,ChatGPT 属于自回归语言模型家族,使用 transformer decoder blocks 作为模型骨干。
预训练期间,进行无监督的样本估计。ChatGPT被认为是来自一组样本
X=x1,x2,...,xnX = {x_1, x_2, ...,x_n}X=x1,x2,...,xn
的无监督分布估计,由m个token组成的样本 x_i定义为
xi=(s1,s2,...,sm)xi = (s_1, s_2, ..., s_m)xi=(s1,s2,...,sm)
预训练的目标是最大化以下似然:
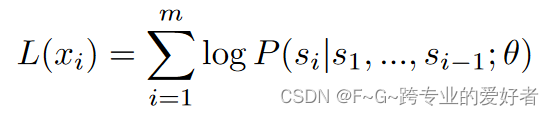
其中 θ 表示 ChatGPT 的可训练参数。
tokens表示为
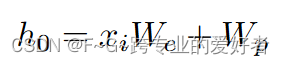
其中 W_e 是tokens(就个单词)嵌入矩阵,W_p 是位置(每个单词的位置)嵌入矩阵。
然后使用N个transformer块来提取样本的特征:
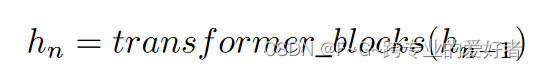
最后预测目标token:
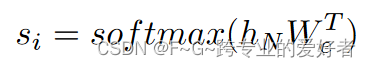
其中 h_N 是顶部变压器块的输出。
预训练后,ChatGPT 的开发人员应用人类反馈强化学习 (RLHF) 来微调预训练语言模型。 RLHF 通过根据人类反馈对语言模型进行微调,使语言模型与用户对广泛任务的意图保持一致。
ChatGPT的RLHF包含三个步骤
step1:Supervised Fine-tuning (SFT)
ChatGPT 使用标记数据进行进一步训练。 AI 培训师扮演用户和 AI 助手的角色,根据prompt建立答案。带有prompt的答案构建为监督数据,用于进一步训练预训练模型。经过进一步的预训练,就可以得到SFT模型。
step2:Reward Modeling (RM)
基于 SFT 方法,训练奖励模型以输入提示和响应,并输出标量奖励。标记器将输出从最好到最差进行排名,以构建排名数据集。两个输出之间的损失函数定义如下:
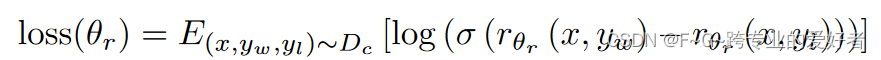
其中θ_r是奖励模型的参数; x 是prompt,y_w 是 y_w 和 y_l 对中的首选完成; D_c 是人类比较的数据集。
step3:Reinforcement Learning (RL)
通过使用奖励模型,可以使用近端策略优化 (PPO) 对 ChatGPT 进行微调。为了修复公共 NLP 数据集的性能回归,RLHF 将预训练梯度混合到 PPO 梯度中,也称为 PPOptx:
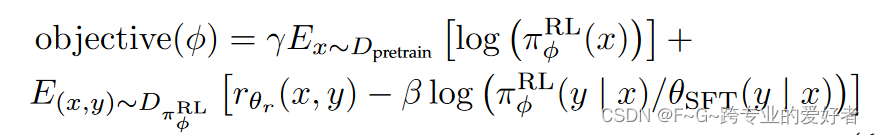
其中 πRL φ 是学习的 RL 策略,θ_SFT 是监督训练模型,D_pretrain 是预训练分布。 γ是控制预训练梯度强度的预训练损失系数,β是控制KL惩罚强度的KL(Kullback-Leibler)奖励系数。
与以往的数据增广方法相比,ChatGPT 更适合数据增广,原因如下:
• ChatGPT 使用大规模语料库进行预训练,因此具有更广阔的语义表达空间,有助于增强数据扩充的多样性。
• 由于ChatGPT微调阶段引入了大量人工标注样本,ChatGPT生成的语言更符合人类的表达习惯。
• 通过强化学习,ChatGPT 可以比较不同表情的优缺点,确保增强数据具有更高的质量
总的来说,chatgpt的数据增强为样本分类提供了不少样本。
Few-shot Text Classification
应用 BERT 来训练少样本文本分类模型。 BERT顶层的输出特征h可以写为:
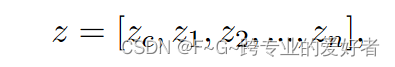
目标函数:小样本学习目标函数由两部分组成:交叉熵和对比学习损失。我们将 z_c 作为最终预测的分类器送入全连接层:
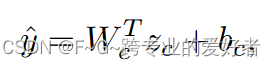
其中W_c和b_c为可训练参数,将交叉熵作为目标函数之一:
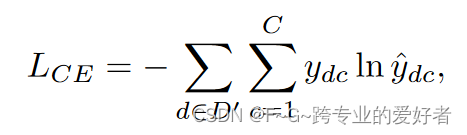
其中C是输出维度,等于基础数据集和新数据集标签空间的并集,y_d是ground truth。
然后,为了充分利用基础数据集中的先验知识来指导新数据集的学习,引入了对比损失函数,使同一类别的样本表示更加紧凑,不同类别的样本表示更加分离.同一批次样本对之间的对比损失定义如下:
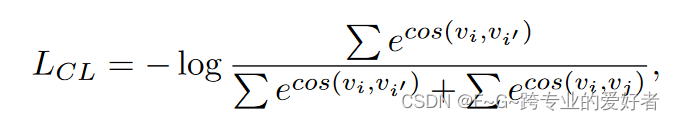
在基础数据集上的 BERT 微调阶段,仅使用交叉熵作为目标函数。在few-shot learning阶段,结合交叉熵和对比学习损失作为目标函数:
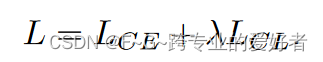
评估指标
使用余弦相似度和 TransRate 作为指标来评估我们的增强数据的完整性(即,特征是否包含有关目标任务的足够信息)和紧凑性(即,每个类的特征是否足够紧凑以实现良好的泛化)。
嵌入相似度
评估数据增强方法生成的样本与实际样本之间的语义相似性,采用生成样本与测试数据集实际样本之间的嵌入相似性。将样本输入到预训练的 BERT 中,并使用 CLS 令牌的表示作为样本嵌入。余弦相似性度量遵循以下约定:
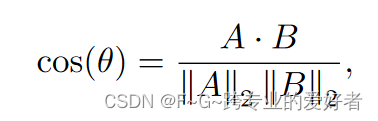
其中 A 和 B 分别表示比较中的两个嵌入向量。
TransRate
TransRate 是一种量化可迁移性的指标,它基于预训练模型提取的特征与其标签之间的互信息,单次通过目标数据。更高的 TransRate 可能表明数据的可学习性更好。更具体地说,从源任务 T_s 到目标任务 T_t 的知识迁移如下所示:
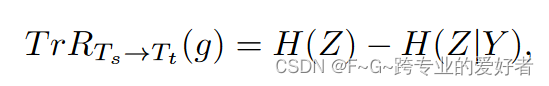
实验结果
分类性能比较
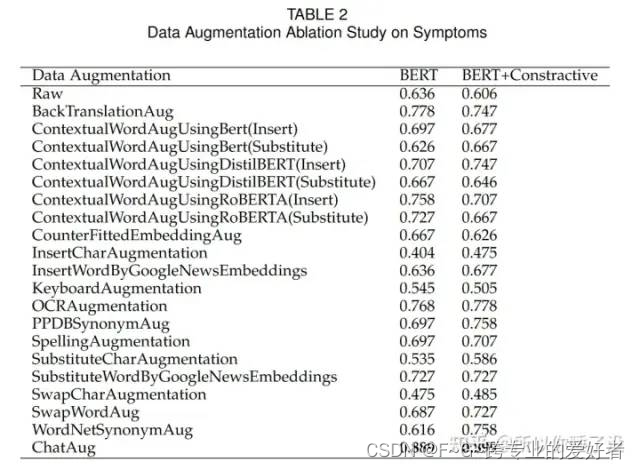

表 2 和表 3 显示 ChatAug 在 Symptoms 和 PubMed20K 数据集上都达到了最高的准确性。
在 PubMed20K 数据集中,ChatAug 对于 BERT 和具有对比损失的 BERT 均达到 83.5% 的准确率,而在没有数据增强的情况下,准确率分别仅为 79.2% 和 79.8%。在 Symptoms 数据集中,没有数据增强的 BERT 的准确率仅为 63.6%,而有 Contrastive loss 的准确率为 60.6%。 ChatAug 方法将准确率分别显着提高到 88.9% 和 89.9%。
这些结果表明,使用 ChatGPT 进行数据扩充对于增强机器学习模型在各种应用程序中的性能更为有效。
增强数据集的评估
该部分评估了增强数据在潜在空间中的性能,并在下图中可视化了结果。使用余弦相似性和 TransRate 度量评估潜在嵌入。
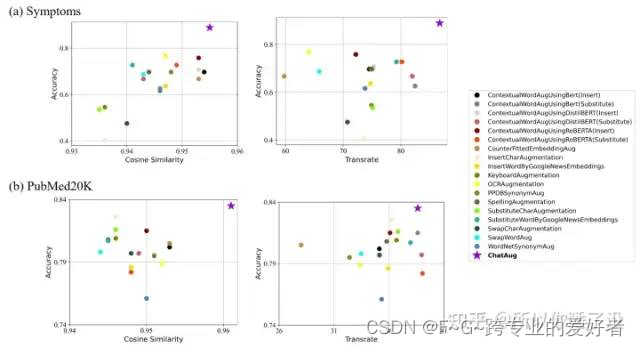
横轴表示余弦相似度值和Transrate值,纵轴表示分类准确率。由于嵌入式相似度衡量的是增强数据与测试数据集之间的相似性,相似度越高意味着增强数据与真实数据越匹配,并且具有更高的完整性和紧凑性。由于更高的 TransRate 可能表明数据的可学习性更好,因此更高的 TransRate 意味着具有更高质量的增强数据。
最理想的候选方法应该位于上图中可视化的右上角。如图 所示,ChatAug 在 Symptoms 数据集和 PubMed20K 数据集上的完整性和紧凑性方面都产生了高质量的样本。
总结
虽然上面的结果表示出chatgpt对于数据增强的强大能力,但还是存在局限性。由于缺乏特定领域知识,就可能产生不正确的增强数据。所以,未来的研究中,还是避免不了微调。
所提出的 ChatAug 方法在文本分类中显示出可喜的结果。未来研究的一个有前途的方向是调查 ChatAug 在更广泛的下游任务中的有效性。也就是提高其鲁棒性。
参考文献:
Dai H, Liu Z, Liao W, et al. ChatAug: Leveraging ChatGPT for Text Data Augmentation[J]. arXiv preprint arXiv:2302.13007, 2023.