6.2 构建并评价聚类模型
- 6.2.1 使用sklearn估计器构建聚类模型
- 1、聚类的概念
- 2、常见聚类方法
- 3、使用sklearn估计器构建聚类模型
- 4、sklearn估计器
- 代码:构建K-Means聚类模型
- 6.2.2 评价聚类模型
- 1、FMI评价法
- 2、轮廓系数评价法
- 3、Calinski-Harabasz指数评价法
6.2.1 使用sklearn估计器构建聚类模型
1、聚类的概念
- 聚类是把各不相同的个体分割为有更多相似性子集合的工作。
- 聚类生成的子集合称为簇
聚类的要求
- 生成的簇内部的任意两个对象之间具有较高的相似度
- 属于不同簇的两个对象间具有较高的相异度
聚类与分类的区别在于聚类不依赖于预先定义的类,没有预定义的类和样本——聚类是一种无监督的数据挖掘任务
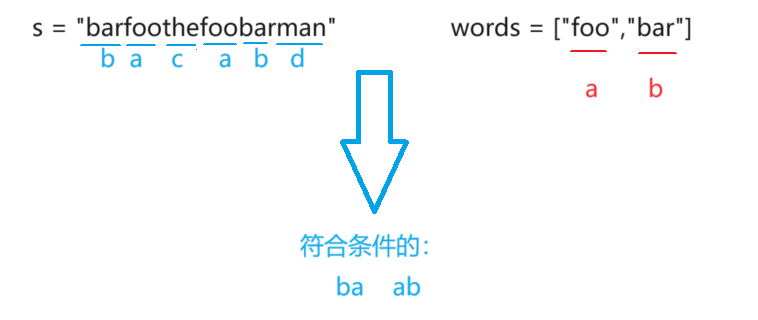
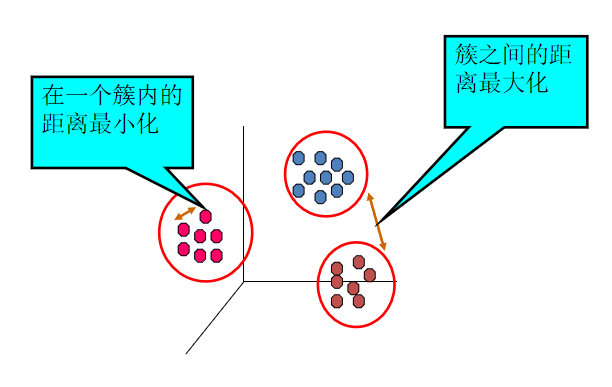
聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将它们划分为若干组,划分的原则是组内(内部)距离最小化,而组外(外部)距离最大化,如下图所示。
2、常见聚类方法

3、使用sklearn估计器构建聚类模型
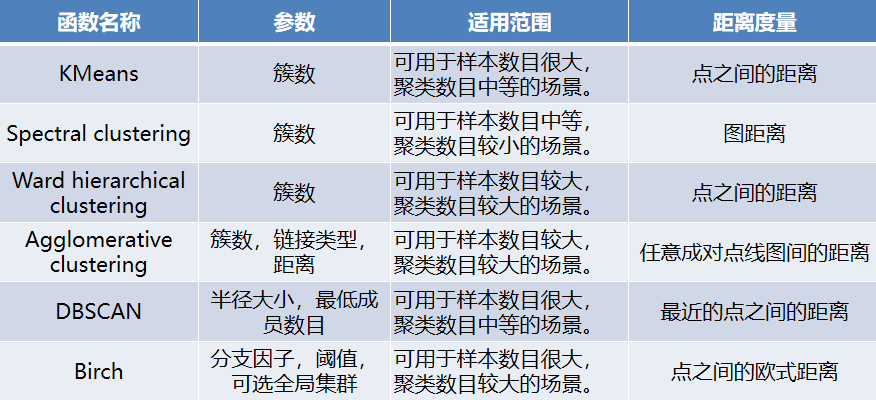
sklearn常用的聚类算法模块cluster提供的聚类算法及其适用范围如下所示。
4、sklearn估计器
聚类算法实现需要sklearn估计器(estimator)。sklearn估计器和转换器类似,拥有fit和predict两个方法。

代码:构建K-Means聚类模型
from sklearn.datasets import load_iris # 鸢尾花数据集 三分类
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaleriris = load_iris()
iris_data = iris['data']
# print(iris_data)
iris_target = iris['target']
# print(iris_target)
scale = MinMaxScaler().fit(iris_data) # 训练规则
dataScale = scale.transform(iris_data) # 应用规则
# print(iris_data)
kmeans = KMeans(n_clusters=3, random_state=123) # 构建模型
kmeans.fit(dataScale) # 训练模型
print("KMeans模型:", kmeans)# 聚类结果可视化
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt# 使用TSNE进行数据降维,降成二维
tsne = TSNE(n_components=2, init='random', random_state=177).fit(iris_data)
df = pd.DataFrame(tsne.embedding_)
df['labels'] = kmeans.labels_
# 提取不同的标签
df0 = df[df['labels'] == 0]
df1 = df[df['labels'] == 1]
df2 = df[df['labels'] == 2]
# 绘制图形
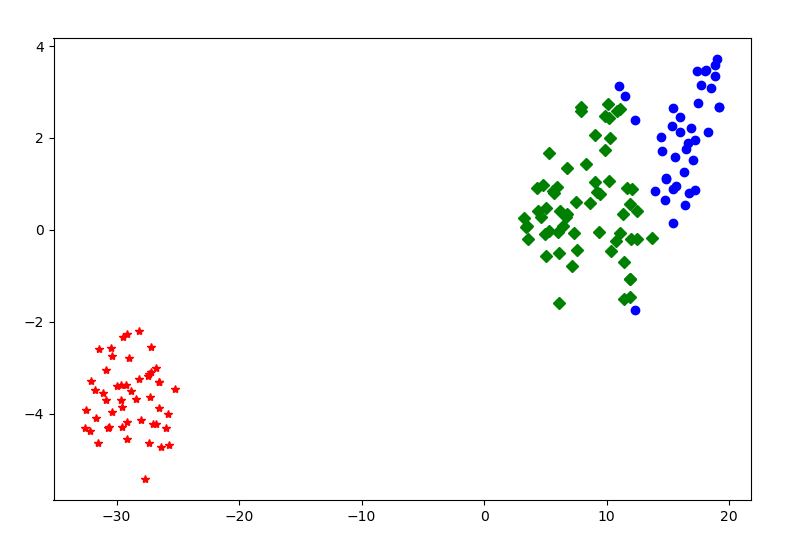
fig = plt.figure(figsize=(9, 6))
plt.plot(df0[0], df0[1], 'bo',df1[0], df1[1], 'r*',df2[0], df2[1], 'gD')
plt.show() # 显示图片
6.2.2 评价聚类模型
聚类评价的标准是组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。即组内的相似性越大,组间差别越大,聚类效果就越好。
sklearn的metrics模块提供的聚类模型评价指标。
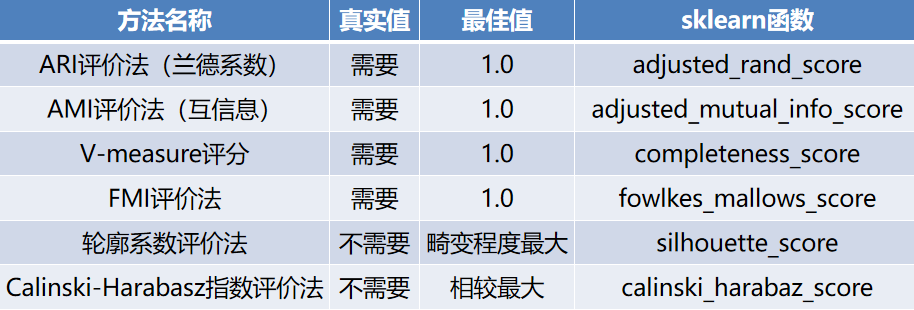
上表总共列出了6种评价的方法,其中前4种方法均需要真实值的配合才能够评价聚类算法的优劣,后2种则不需要真实值的配合。但是前4种方法评价的效果更具有说服力,并且在实际运行的过程中在有真实值做参考的情况下,聚类方法的评价可以等同于分类算法的评价。
除了轮廓系数以外的评价方法,在不考虑业务场景的情况下都是得分越高,其效果越好,最高分值均为1。而轮廓系数则需要判断不同类别数目的情况下其轮廓系数的走势,寻找最优的聚类数目。
1、FMI评价法
# 1、使用FMI评价KMeans聚类模型
from sklearn.metrics import fowlkes_mallows_score
from sklearn.datasets import load_iris # 鸢尾花数据集 三分类
from sklearn.cluster import KMeans
iris = load_iris()
iris_data = iris['data']
iris_target = iris['target']
for i in range(2, 7):# 构建并训练模型kmeans = KMeans(n_clusters=i, random_state=123).fit(iris_data)score = fowlkes_mallows_score(iris_target, kmeans.labels_)print('iris数据聚%d类FMI评价分值为:%f' %(i, score))
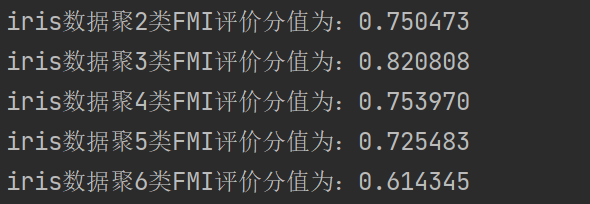
iris数据聚3类的时候FMI评价分值最高,故聚类为3类的时候K-Means聚类模型最好。
2、轮廓系数评价法
使用轮廓系数评价法评估K-Means模型,然后做出轮廓系数走势图,根据图形判断聚类效果。
# 2、使用轮廓系数评价法评价K-Means聚类模型
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris # 鸢尾花数据集 三分类
from sklearn.cluster import KMeans
iris = load_iris()
iris_data = iris['data']
iris_target = iris['target']
si = []
for i in range(2, 15):kmeans = KMeans(n_clusters=i, random_state=0).fit(iris_data) # 构建并训练模型score = silhouette_score(iris_data, kmeans.labels_)si.append(score)plt.figure(figsize=(10, 6))
plt.plot(range(2, 15), si, linewidth=1.5)
plt.show()
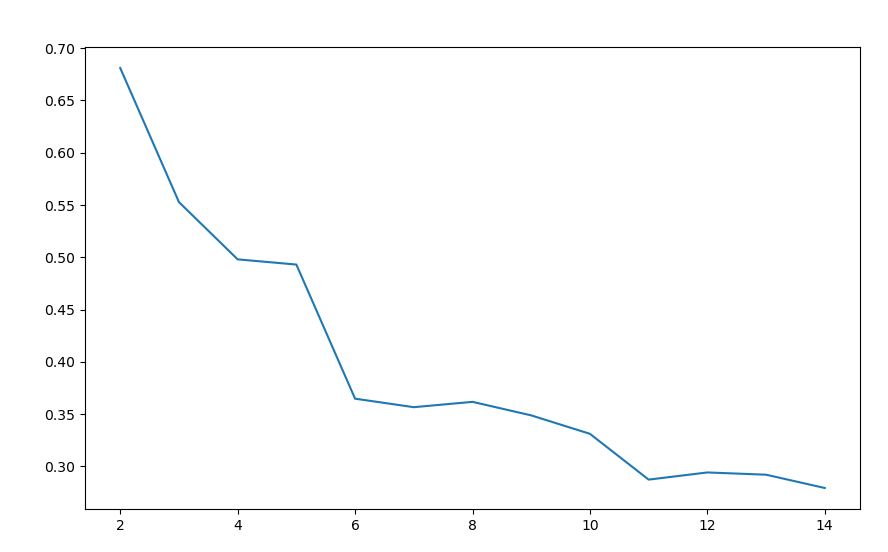
从图形结果可以看出,聚类数目为2、3和5、6时平均畸变程度最大。由于iris数据本身就是3种鸢尾花的花瓣、花萼长度和宽度的数据,侧面说明了聚类数目为3的时候效果最佳。
3、Calinski-Harabasz指数评价法
# 3、使用Calinski-Harabasz 指数评价K-Means聚类模型
from sklearn.metrics import calinski_harabasz_score
from sklearn.datasets import load_iris # 鸢尾花数据集 三分类
from sklearn.cluster import KMeans
iris = load_iris()
iris_data = iris['data']
iris_target = iris['target']
for i in range(2, 7):# 构建并训练模型kmeans = KMeans(n_clusters=i, random_state=123).fit(iris_data)score = calinski_harabasz_score(iris_data, kmeans.labels_)print('iris数据聚%d类calinski_harabasz指数为:%f' % (i, score))
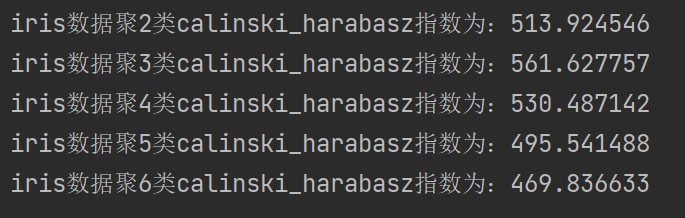
使用Calinski-Harabasz指数评价法,分值越高,聚类效果越好。从结果可以看出3的得分最高。
在具备真实值作为参考的情况下,几种方法均可以很好地评估聚类模型。在没有真实值作为参考的时候,轮廓系数评价方法和Calinski-Harabasz指数评价方法可以结合使用。