AI视野·今日CS.CV 计算机视觉论文速览
Fri, 22 Sep 2023
Totally 90 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚SVGCustomization, 基于文本的矢量图生成定制(from 香港城市大学)。
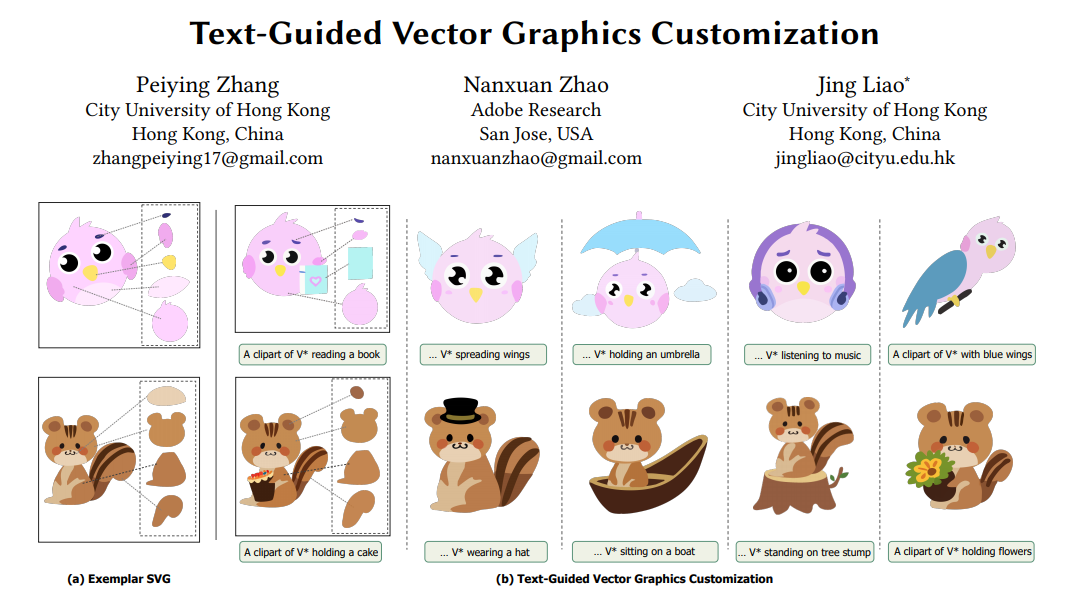
website:https://intchous.github.io/SVGCustomization/
Daily Computer Vision Papers
| Active Stereo Without Pattern Projector Authors Luca Bartolomei, Matteo Poggi, Fabio Tosi, Andrea Conti, Stefano Mattoccia 本文提出了一种新颖的框架,将主动立体原理集成到标准被动相机系统中,无需物理图案投影仪。我们根据从深度传感器获得的稀疏测量结果,在左右图像上虚拟地投影一个图案。任何此类设备都可以无缝插入我们的框架中,从而允许在任何可能的环境中部署虚拟主动立体设置,克服图案投影仪的限制,例如有限的工作范围或环境条件。 |
| TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance Authors Kan Wu, Houwen Peng, Zhenghong Zhou, Bin Xiao, Mengchen Liu, Lu Yuan, Hong Xuan, Michael Valenzuela, Xi Stephen Chen, Xinggang Wang, Hongyang Chao, Han Hu 在本文中,我们提出了一种新颖的跨模态蒸馏方法,称为 TinyCLIP,用于大规模语言图像预训练模型。该方法引入了亲和力模仿和权重继承两项核心技术。亲和模仿探索了蒸馏过程中模态之间的相互作用,使学生模型能够模仿教师在视觉语言亲和空间中学习跨模态特征对齐的行为。权重继承将预训练的权重从教师模型传输到学生模型,以提高蒸馏效率。此外,我们将该方法扩展到多级渐进蒸馏,以减轻极端压缩期间信息权重的损失。综合实验证明了 TinyCLIP 的功效,表明它可以将预训练的 CLIP ViT B 32 的大小减少 50 倍,同时保持可比的零射击性能。在以可比较的性能为目标的同时,与从头开始训练相比,具有权重继承的蒸馏可以将训练速度提高 1.4-7.8 倍。此外,我们的 TinyCLIP ViT 8M 16 在 YFCC 15M 上进行训练,在 ImageNet 上实现了令人印象深刻的 41.1 的零样本 top 1 精度,比原始 CLIP ViT B 16 提高了 3.5,同时仅使用 8.9 个参数。最后,我们展示了 TinyCLIP 在各种下游任务中良好的可移植性。 |
| LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent Authors Jianing Yang, Xuweiyi Chen, Shengyi Qian, Nikhil Madaan, Madhavan Iyengar, David F. Fouhey, Joyce Chai 3D 视觉基础是家用机器人的一项关键技能,使它们能够根据环境进行导航、操纵物体并回答问题。虽然现有方法通常依赖于大量标记数据或在处理复杂语言查询时表现出局限性,但我们提出了 LLM Grounder,这是一种新颖的零样本、开放词汇、基于大型语言模型 LLM 的 3D 视觉基础管道。 LLM Grounder 利用 LLM 将复杂的自然语言查询分解为语义成分,并采用 OpenScene 或 LERF 等视觉基础工具来识别 3D 场景中的对象。然后,法学硕士评估所提出的对象之间的空间和常识关系,以做出最终的基础决定。我们的方法不需要任何标记的训练数据,并且可以推广到新颖的 3D 场景和任意文本查询。我们根据 ScanRefer 基准评估 LLM Grounder,并展示最先进的零射击接地精度。我们的研究结果表明,LLM 显着提高了基础能力,尤其是对于复杂的语言查询,使 LLM Grounder 成为机器人领域 3D 视觉语言任务的有效方法。 |
| TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning Authors Chaeyoung Jung, Suyeon Lee, Kihyun Nam, Kyeongha Rho, You Jin Kim, Youngjoon Jang, Joon Son Chung 这项工作的目标是主动说话者检测 ASD,这是一项确定一个人在一系列视频帧中是否说话的任务。以前的工作通过探索网络架构来处理该任务,而学习有效表示的探索较少。在这项工作中,我们提出了 TalkNCE,一种新颖的谈话感知对比损失。损失仅适用于屏幕上的人实际说话的完整片段的一部分。这鼓励模型通过语音和面部动作的自然对应来学习有效的表示。我们的损失可以与训练 ASD 模型的现有目标联合优化,而不需要额外的监督或训练数据。实验表明,我们的损失可以轻松集成到现有的 ASD 框架中,从而提高其性能。 |
| SlowFast Network for Continuous Sign Language Recognition Authors Junseok Ahn, Youngjoon Jang, Joon Son Chung 这项工作的目标是有效提取连续手语识别 CSLR 的空间和动态特征。为了实现这一目标,我们利用了两个路径 SlowFast 网络,其中每个路径以不同的时间分辨率运行,以分别捕获空间手部形状、面部表情和动态运动信息。此外,我们还引入了两种不同的特征融合方法,针对 CSLR 的特点精心设计: 1 Bi orientation Feature Fusion BFF ,有利于将动态语义转换为空间语义,反之亦然; 2 Pathway Feature Enhancement PFE ,丰富动态和空间语义通过辅助子网络进行表示,同时避免需要额外的推理时间。因此,我们的模型进一步并行增强了空间和动态表示。 |
| PanoVOS:Bridging Non-panoramic and Panoramic Views with Transformer for Video Segmentation Authors Shilin Yan, Xiaohao Xu, Lingyi Hong, Wenchao Chen, Wenqiang Zhang, Wei Zhang 全景视频包含更丰富的空间信息,因其在自动驾驶、虚拟现实等领域的卓越经验而受到广泛关注。然而,现有的视频分割数据集仅关注传统的平面图像。为了应对这一挑战,在本文中,我们提出了一个全景视频数据集 PanoVOS。该数据集提供了 150 个视频,视频分辨率高,动作多样。为了量化 2D 平面视频和全景视频之间的域差距,我们在 PanoVOS 上评估了 15 个现成的视频对象分割 VOS 模型。通过错误分析,我们发现它们都未能解决全景视频的像素级内容中断问题。因此,我们提出了一种全景空间一致性变换器 PSCFormer ,它可以有效地利用前一帧的语义边界信息与当前帧进行像素级匹配。大量的实验表明,与之前的SOTA模型相比,我们的PSCFormer网络在全景设置下的分割结果方面表现出很大的优势。 |
| Text-Guided Vector Graphics Customization Authors Peiying Zhang, Nanxuan Zhao, Jing Liao 矢量图形广泛应用于数字艺术中,并因其可扩展性和逐层拓扑特性而受到设计师的重视。然而,矢量图形的创建和编辑需要创造力和设计专业知识,从而导致一个耗时的过程。在本文中,我们提出了一种新颖的管道,可以根据文本提示生成高质量的定制矢量图形,同时保留给定示例 SVG 的属性和分层信息。我们的方法利用大型预训练文本到图像模型的功能。通过微调模型的交叉关注层,我们生成由文本提示引导的定制光栅图像。为了初始化 SVG,我们引入了一种基于语义的路径对齐方法,该方法可以保留和转换示例 SVG 中的关键路径。此外,我们使用图像级和矢量级损失来优化路径参数,确保平滑的形状变形,同时与定制的光栅图像对齐。我们使用来自矢量级别、图像级别和文本级别角度的多个指标来广泛评估我们的方法。评估结果证明了我们的流程在生成具有卓越质量的多样化矢量图形定制方面的有效性。 |
| Learning to Drive Anywhere Authors Ruizhao Zhu, Peng Huang, Eshed Ohn Bar, Venkatesh Saligrama 人类驾驶员可以在不同的地理位置和不同的道路条件和规则(例如左侧交通和右侧交通)中无缝地调整其驾驶决策。相比之下,现有的自动驾驶模型迄今为止仅部署在有限的操作域内,即没有考虑到跨位置的不同驾驶行为或模型可扩展性。在这项工作中,我们提出了 AnyD,这是一种单一的地理感知条件模仿学习 CIL 模型,可以有效地从具有动态环境、交通和社会特征的异构和全球分布数据中学习。我们的主要见解是引入基于高容量地理位置的通道注意机制,该机制有效地适应当地的细微差别,同时还以数据驱动的方式灵活地对区域之间的相似性进行建模。通过优化对比模仿目标,我们提出的方法可以有效地扩展固有不平衡的数据分布和位置相关事件。我们展示了 AnyD 代理在多个数据集、城市和可扩展部署范例(即集中式、半监督式和分布式代理训练)中的优势。 |
| Can We Reliably Improve the Robustness to Image Acquisition of Remote Sensing of PV Systems? Authors Gabriel Kasmi, Laurent Dubus, Yves Marie Saint Drenan, Philippe Blanc 光伏发电对于能源系统脱碳至关重要。由于缺乏集中数据,屋顶光伏装置的遥感是监测区域范围内屋顶光伏装置群演变的最佳选择。然而,当前的技术缺乏可靠性,并且对采集条件的变化特别敏感。为了克服这个问题,我们利用小波尺度归因方法 WCAM,它在空间尺度域中分解模型的预测。 WCAM 使我们能够评估光伏模型的表示形式,并提供见解以得出提高采集条件鲁棒性的方法,从而增加对深度学习系统的信任,鼓励将其用于清洁能源在电力中的安全集成 |
| ORTexME: Occlusion-Robust Human Shape and Pose via Temporal Average Texture and Mesh Encoding Authors Yu Cheng, Bo Wang, Robby T. Tan 在单目视频的 3D 人体形状和姿势估计中,使用有限标记数据训练的模型无法很好地推广到具有遮挡的视频,这在野外视频中很常见。最近的人类神经渲染方法侧重于由现成的人体形状和姿势方法初始化的新颖视图合成,有可能纠正初始人体形状。然而,现有的方法存在一些缺点,例如遮挡处理错误、对不准确的人体分割敏感以及由于非正则化的不透明场而导致损失计算无效。为了解决这些问题,我们引入了 ORTexME,这是一种遮挡鲁棒时间方法,它利用输入视频中的时间信息来更好地规范遮挡的身体部位。虽然我们的 ORTexME 基于 NeRF,但为了确定 NeRF 射线采样的可靠区域,我们利用新颖的平均纹理学习方法来学习人的平均外观,并根据平均纹理推断掩模。此外,为了指导 NeRF 中的不透明场更新以抑制模糊和噪声,我们建议使用人体网格。定量评估表明,我们的方法在具有挑战性的多人 3DPW 数据集上取得了显着改进,其中我们的方法实现了 1.8 P MPJPE 误差减少。 |
| Autoregressive Sign Language Production: A Gloss-Free Approach with Discrete Representations Authors Eui Jun Hwang, Huije Lee, Jong C. Park 无光泽手语制作 SLP 可以将口语句子直接翻译成手语,无需光泽中介。本文提出了手语矢量量化网络,这是一种新颖的 SLP 方法,利用矢量量化从手语姿势序列中导出离散表示。我们的方法植根于手动和非手动签名元素,支持高级解码方法并集成潜在级别对齐以增强语言连贯性。 |
| SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset Authors Sagar M. Waghmare, Kimberly Wilber, Dave Hawkey, Xuan Yang, Matthew Wilson, Stephanie Debats, Cattalyya Nuengsigkapian, Astuti Sharma, Lars Pandikow, Huisheng Wang, Hartwig Adam, Mikhail Sirotenko 我们介绍 SANPO,一个大规模的以自我为中心的视频数据集,专注于户外环境中的密集预测。它包含在不同的户外环境中收集的立体视频会话,以及渲染的合成视频会话。综合数据由 Parallel Domain 提供。所有会话都有密集的深度和里程标签。所有合成会话和真实会话的子集都具有时间一致的密集全景分割标签。据我们所知,这是第一个具有大规模密集全景分割和深度注释的人类自我中心视频数据集。除了数据集之外,我们还为未来的研究提供零样本基线和 SANPO 基准。 |
| Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features Authors Travis Zhang, Katie Luo, Cheng Perng Phoo, Yurong You, Wei Lun Chao, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger 自动驾驶汽车 3D 物体检测系统的快速发展显着提高了准确性。然而,这些系统很难在不同的驾驶环境中通用,这可能会导致检测交通参与者时出现安全关键故障。为了解决这个问题,我们提出了一种方法,利用多个位置的未标记重复遍历来使物体检测器适应新的驾驶环境。通过合并重复激光雷达扫描计算出的统计数据,我们可以有效地指导适应过程。我们的方法使用空间量化历史特征增强基于激光雷达的检测模型,并引入轻量级回归头来利用统计数据进行特征正则化。此外,我们利用统计数据进行新颖的自我训练过程来稳定训练。该框架与检测器模型无关,并且在现实世界数据集上的实验证明了显着的改进,实现了高达 20 个点的性能增益,特别是在检测行人和远处物体方面。 |
| Vulnerability of 3D Face Recognition Systems to Morphing Attacks Authors Sanjeet Vardam, Luuk Spreeuwers 近年来,由于硬件和软件的发展,人脸识别系统已成为主流。我们正在不断努力,使它们变得更好、更安全。这也带动了3D人脸识别系统的快速发展。这些 3DFR 系统有望克服 2DFR 系统的某些漏洞。 2DFR 系统领域面临的问题之一是人脸图像变形。为了生成高质量的面部变形以及检测来自这些变形的攻击,正在进行大量研究。相比之下,对 3DFR 系统针对 3D 人脸变形的脆弱性的了解较少。但与此同时,人们期望 3DFR 系统能够更强大地抵御此类攻击。本文试图对此问题进行研究并获取更多信息。该论文描述了几种可用于生成 3D 面部变形的方法。然后将使用此方法生成的面部变形与有贡献的面部进行比较以获得相似度分数。 |
| Exploiting CLIP-based Multi-modal Approach for Artwork Classification and Retrieval Authors Alberto Baldrati, Marco Bertini, Tiberio Uricchio, Alberto Del Bimbo 鉴于多模态图像预训练的最新进展,其中使用语义密集文本监督训练的视觉模型往往比使用分类属性或通过无监督技术训练的视觉模型具有更好的泛化能力,在这项工作中,我们研究了如何将最新的 CLIP 模型应用于以下几个任务:艺术品领域。我们对 NoisyArt 数据集进行了详尽的实验,该数据集是从网络公共资源中爬取的艺术品图像的数据集。 |
| FourierLoss: Shape-Aware Loss Function with Fourier Descriptors Authors Mehmet Bahadir Erden, Selahattin Cansiz, Onur Caki, Haya Khattak, Durmus Etiz, Melek Cosar Yakar, Kerem Duruer, Berke Barut, Cigdem Gunduz Demir 编码器解码器网络成为各种医学图像分割任务的流行选择。当使用标准损失函数对它们进行训练时,这些网络不会被明确强制保持图像中对象的形状完整性。然而,网络的这种能力对于获得更准确的结果非常重要,特别是当物体与其周围环境之间的对比度差异较小时。针对这个问题,这项工作引入了一种新的形状感知损失函数,我们将其命名为 FourierLoss。该损失函数依赖于通过在其对象上计算的傅立叶描述符来量化地面实况和预测分割图之间的形状差异,并在网络训练中惩罚这种差异。与之前的研究不同,FourierLoss 提供了一种具有可训练超参数的自适应损失函数,这些超参数控制网络在训练过程中强制学习的形状细节级别的重要性。这种控制是通过所提出的自适应损失更新机制实现的,该机制通过反向传播与网络权重同时端到端地学习超参数。由于使用这种机制,网络可以在不同的训练时期动态地改变其注意力,从学习对象的总体轮廓到学习其轮廓点的细节,反之亦然。 |
| Multi-Task Cooperative Learning via Searching for Flat Minima Authors Fuping Wu, Le Zhang, Yang Sun, Yuanhan Mo, Thomas Nichols, Bartlomiej W. Papiez 多任务学习 MTL 在医学图像分析中显示出巨大的潜力,提高了学习特征的泛化性和单个任务的性能。然而,MTL 的大部分工作都集中在架构设计或梯度操作上,而在这两种情况下,特征都是以竞争的方式学习的。在这项工作中,我们建议将 MTL 表述为多双层优化问题,从而迫使特征以协作方式从每个任务中学习。具体来说,我们更新每个任务的子模型,或者利用其他任务的学习子模型。为了缓解优化过程中的负迁移问题,我们针对其他任务的特征搜索当前目标函数的平坦最小值。为了证明所提出方法的有效性,我们在三个公开可用的数据集上验证了我们的方法。所提出的方法显示了合作学习的优势,并且与最先进的 MTL 方法相比,产生了有希望的结果。 |
| Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer -- Current Trends and Research Perspectives Authors Karolina Seweryn, Anna Wr blewska, Szymon ukasik 由于足球比赛的复杂性和动态性以及球员之间的互动,理解足球中的动作场景是一项具有挑战性的任务。本文全面概述了该任务,分为动作识别、定位和时空动作定位,特别强调了所使用的模态和多模态方法。我们探索用于评估模型性能的公开数据源和指标。本文回顾了利用深度学习技术和传统方法的最新技术方法。我们专注于多模态方法,它集成了来自多个源的信息,例如视频和音频数据,以及以各种方式表示一个源的信息。讨论了方法的优点和局限性,以及它们提高模型准确性和鲁棒性的潜力。最后,本文重点介绍了足球动作识别领域的一些开放研究问题和未来方向,包括多模态方法推进该领域发展的潜力。 |
| Self-Calibrating, Fully Differentiable NLOS Inverse Rendering Authors Kiseok Choi, Inchul Kim, Dongyoung Choi, Julio Marco, Diego Gutierrez, Min H. Kim 现有的时间分辨非视线 NLOS 成像方法通过反转在可见中继表面测量的间接照明的光路来重建隐藏场景。这些方法很容易因反演模糊性和捕获噪声而产生重建伪影,而这些噪声通常可以通过手动选择滤波函数和参数来减轻。我们引入了完全可微的端到端 NLOS 逆渲染管道,该管道在隐藏场景重建期间自校准成像参数,仅使用测量的照明作为输入,同时在时域和频域中工作。我们的管道从 NLOS 体积强度中提取隐藏场景的几何表示,并使用可微瞬态渲染估计由此类几何信息产生的中继墙处的时间分辨照明。然后,我们使用梯度下降通过最小化模拟时间分辨照明和测量照明之间的误差来优化成像参数。我们的端到端可微管道将基于衍射的体积 NLOS 重建与路径空间光传输和简单的光线行进技术结合起来,以提取隐藏场景的详细、密集的表面点和法线集。 |
| Beyond Image Borders: Learning Feature Extrapolation for Unbounded Image Composition Authors Xiaoyu Liu, Ming Liu, Junyi Li, Shuai Liu, Xiaotao Wang, Lei Lei, Wangmeng Zuo 为了提高图像构图和美学质量,大多数现有方法通过剔除图像边界附近的冗余内容来调制捕获的图像。然而,这种图像裁剪方法在图像视图的范围上受到限制。已经提出了一些方法来外推图像并从外推图像预测裁剪框。尽管如此,合成的外推区域可能包含在裁剪图像中,使得图像合成结果不真实,并且可能导致图像质量下降。在本文中,我们通过提出一个用于相机视图和图像合成的无界推荐的联合框架(即 UNIC )来规避这个问题。这样,裁剪后的图像是预测摄像机视角获取的图像的子图像,因此可以保证真实且图像质量一致。具体来说,我们的框架将当前相机预览帧作为输入,并提供视图调整的建议,其中包含不受图像边界限制的操作,例如放大或缩小以及相机移动。为了提高视图调整预测的预测精度,我们通过特征外推进一步扩展视场。经过一次或多次视图调整后,我们的方法收敛并产生相机视图和显示图像构图推荐的边界框。在现有图像裁剪数据集构建的数据集上进行了大量实验,显示了我们的 UNIC 在无限制推荐相机视图和图像合成方面的有效性。 |
| BASE: Probably a Better Approach to Multi-Object Tracking Authors Martin Vonheim Larsen, Sigmund Rolfsjord, Daniel Gusland, J rgen Ahlberg, Kim Mathiassen 视觉对象跟踪领域以简单跟踪算法和临时方案相结合的方法为主。令人惊讶的是,在其他领域处于领先地位的概率跟踪算法却没有出现在排行榜上。我们发现,考虑目标运动学中的距离、利用探测器置信度和对非均匀杂波特征进行建模对于概率跟踪器在视觉跟踪中工作至关重要。以前的概率方法未能解决大部分或所有这些方面,我们认为这就是为什么它们远远落后于当前最先进的 SOTA 方法的原因,在 MOT17 前 100 名中没有概率跟踪器。为了重新点燃概率方法的进步,我们提出了一套应对这些挑战的实用模型,并演示了如何将它们纳入概率框架中。我们提出了 BASE 贝叶斯近似单假设估计器,这是一种简单、高性能且易于扩展的视觉跟踪器,在 MOT17 和 MOT20 上实现了最先进的 SOTA,而无需使用 Re Id。 |
| Face Identity-Aware Disentanglement in StyleGAN Authors Adrian Suwa a, Bartosz W jcik, Magdalena Proszewska, Jacek Tabor, Przemys aw Spurek, Marek mieja 条件 GAN 经常用于操纵面部图像的属性,例如表情、发型、姿势或年龄。尽管最先进的模型成功地修改了所请求的属性,但它们同时修改了图像的其他重要特征,例如人的身份。在本文中,我们通过引入 PluGeN4Faces(StyleGAN 的插件)来重点解决这个问题,它明确地将面部属性与人的身份分开。我们的关键思想是对从电影帧中检索的图像进行训练,其中给定的人以各种姿势出现并具有不同的属性。通过应用一种对比损失,我们鼓励模型将同一个人的图像分组在潜在空间的相似区域。 |
| Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded Environments Authors Yifei Chen, Kunyu Peng, Alina Roitberg, David Schneider, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, Rainer Stiefelhagen 为了将动作识别方法集成到自主机器人系统中,考虑涉及目标遮挡的不利情况至关重要。这种场景尽管具有实际意义,但在现有的基于自我监督骨架的动作识别方法中很少得到解决。为了赋予机器人解决遮挡问题的能力,我们提出了一种简单有效的方法。我们首先使用遮挡的骨架序列进行预训练,然后使用 k 均值在序列嵌入上对 KMeans 进行聚类,以对语义相似的样本进行分组。接下来,我们使用 K 最近邻 KNN 根据最近样本邻居来填充缺失的骨架数据。估算不完整的骨架序列以创建相对完整的序列作为输入,为现有的基于骨架的自监督模型提供了显着的好处。同时,在最先进的部分空间时间学习 PSTL 的基础上,我们引入了遮挡部分空间时间学习 OPSTL 框架。此增强功能利用自适应空间遮蔽 ASM 来更好地利用高质量、完整的骨骼。 |
| Precision in Building Extraction: Comparing Shallow and Deep Models using LiDAR Data Authors Muhammad Sulaiman, Mina Farmanbar, Ahmed Nabil Belbachir, Chunming Rong 建筑分段对于基础设施开发、人口管理和地质观测至关重要。本文针对浅层模型,因为它们具有可解释的性质,可以评估用于监督分割的 LiDAR 数据的存在。本文使用的基准数据发布于NORA MapAI深度学习模型竞赛。将浅层模型与基于 Intersection over Union IoU 和 Boundary Intersection over Union BIoU 的深度学习模型进行比较。在提议的工作中,从原始掩模生成边界掩模以提高 BIoU 分数,这与构建形状边界有关。通过在任务 1 中仅使用航拍图像训练模型以及在任务 2 中结合航拍和 LiDAR 数据训练模型来测试 LiDAR 数据的影响,然后进行比较。仅使用航拍图像任务 1 时,浅层模型的 IoU 性能优于深度学习模型 8 倍;在组合航拍图像和 LiDAR 数据任务 2 中,浅层模型的性能优于深度学习模型 2 倍。相比之下,深度学习模型在 BIoU 分数上表现出更好的性能。边界掩模在这两项任务中将 BIoU 分数提高了 4。 |
| Elevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision Authors Yiping Wei, Kunyu Peng, Alina Roitberg, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, Rainer Stiefelhagen 用于人类动作识别的自监督表示学习近年来发展迅速。大多数现有作品都是基于骨架数据,同时使用多模态设置。 |
| ZS6D: Zero-shot 6D Object Pose Estimation using Vision Transformers Authors Philipp Ausserlechner, David Haberger, Stefan Thalhammer, Jean Baptiste Weibel, Markus Vincze 随着机器人系统越来越多地遇到复杂且不受约束的现实世界场景,需要识别不同的物体。最先进的 6D 物体姿态估计方法依赖于物体特定的训练,因此不能推广到看不见的物体。最近新颖的物体姿态估计方法正在使用特定于任务的微调 CNN 进行深度模板匹配来解决这个问题。这种姿态估计的适应仍然需要昂贵的数据渲染和训练过程。例如,MegaPose 在包含 200 万张图像(显示 20,000 个不同对象)的数据集上进行训练,以达到这种泛化能力。为了克服这个缺点,我们引入了 ZS6D,用于零样本新物体 6D 姿态估计。使用预先训练的 Vision Transformers ViT 提取的视觉描述符用于将渲染模板与对象的查询图像进行匹配并建立本地对应关系。这些局部对应关系能够导出几何对应关系,并用于通过基于 RANSAC 的 PnP 来估计对象的 6D 姿态。这种方法表明,通过预先训练的 ViT 提取的图像描述符非常适合实现比两种最先进的新颖对象 6D 姿态估计方法显着的改进,而不需要特定于任务的微调。在 LMO、YCBV 和 TLESS 上进行了实验。 |
| NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields Authors Floris Erich, Naoya Chiba, Yusuke Yoshiyasu, Noriaki Ando, Ryo Hanai, Yukiyasu Domae 我们提出了 NeuralLabeling,一种标签方法和工具集,用于使用边界框或网格来注释场景,并生成分割掩模、可供性图、2D 边界框、3D 边界框、6DOF 对象姿势、深度图和对象网格。 NeuralLabeling 使用神经辐射场 NeRF 作为渲染器,允许使用 3D 空间工具执行标记,同时结合遮挡等几何线索,仅依赖于从多个视点捕获的图像作为输入。为了演示 NeuralLabeling 对机器人实际问题的适用性,我们将地面实况深度图添加到 30000 帧透明物体 RGB 中,以及使用 RGBD 传感器捕获的放置在洗碗机中的眼镜的噪声深度图,从而生成 Dishwasher30k 数据集。 |
| Ego3DPose: Capturing 3D Cues from Binocular Egocentric Views Authors Taeho Kang, Kyungjin Lee, Jinrui Zhang, Youngki Lee 我们推出了 Ego3DPose,一种高精度的双目自我中心 3D 姿势重建系统。双目自我中心设置在各种应用中提供了实用性和有用性,但是,它仍然在很大程度上处于探索之中。由于观看扭曲、严重的自遮挡以及以自我为中心的 2D 图像中关节的视野有限,它一直面临姿势估计精度较低的问题。在这里,我们注意到,以自我为中心的双眼输入中包含的两个重要的 3D 线索,立体对应和透视被忽略了。当前的方法严重依赖 2D 图像特征,隐式学习 3D 信息,这会导致对常见运动的偏差,并导致整体精度较低。我们观察到,它们不仅无法应对遮挡情况,而且无法估计可见的关节位置。为了应对这些挑战,我们提出了两种新颖的方法。首先,我们设计了一个双路径网络架构,其中的路径可以通过其双目热图独立估计每个肢体的姿势。在不提供全身信息的情况下,它可以减轻对经过训练的全身分布的偏见。其次,我们利用身体四肢的自我中心视图,它表现出强烈的透视变化,例如,当靠近相机时,手的尺寸非常大。我们提出了一种使用三角学的新视角感知表示,使网络能够估计肢体的 3D 方向。最后,我们开发了一个端到端的姿态重建网络,可以协同这两种技术。我们的综合评估表明,Ego3DPose 的姿势估计误差优于最先进的模型,即 UnrealEgo 数据集中的 MPJPE 减少了 23.1。 |
| A Study of Forward-Forward Algorithm for Self-Supervised Learning Authors Jonas Brenig, Radu Timofte 自监督表示学习在过去几年中取得了显着进展,最近的一些方法能够在没有标签的情况下学习有用的图像表示。这些方法是使用事实上的标准反向传播进行训练的。最近,Geoffrey Hinton 提出了前向前向算法作为替代训练方法。 |
| Fully Transformer-Equipped Architecture for End-to-End Referring Video Object Segmentation Authors Ping Li, Yu Zhang, Li Yuan, Xianghua Xu 引用视频对象分割 RVOS 需要对自然语言查询引用的视频中的对象进行分割。现有的方法主要依靠复杂的管道来处理这种跨模式任务,并且没有明确地建模对象级空间上下文,而对象级空间上下文在定位所引用的对象中起着重要作用。因此,我们提出了一个完全基于 Transformer 构建的端到端 RVOS 框架,称为 textit Full Transformer Equipped Architecture FTEA ,它将 RVOS 任务视为掩码序列学习问题,并将视频中的所有对象视为候选对象。给定带有文本查询的视频剪辑,编码器生成视觉文本特征,而相应的像素级和单词级特征在语义相似性方面对齐。为了捕获对象级空间上下文,我们开发了 Stacked Transformer,它单独表征每个候选对象的视觉外观,其特征图直接按顺序解码为二进制掩码序列。最后,模型找到掩码序列和文本查询之间的最佳匹配。此外,为了使候选对象生成的掩模多样化,我们对模型施加多样性损失,以捕获所引用对象的更准确的掩模。实证研究表明了该方法在三个基准上的优越性,例如,FETA 在 A2D Sentences 3782 视频和 J HMDB Sentences 928 视频的 mAP 方面分别达到了 45.1 和 38.7,在 Ref YouTube VOS 上的数学 J F 方面分别达到了 56.6 3975 个视频和 7451 个物体。 |
| Video Scene Location Recognition with Neural Networks Authors Luk Korel, Petr Pulc, Ji Tumpach, Martin Hole a 本文深入探讨了使用人工神经网络从具有一小组重复拍摄位置的视频序列(例如电视连续剧)中进行场景识别的可能性。该方法的基本思想是从每个场景中选择一组帧,通过预先训练的单图像预处理卷积网络对其进行转换,并使用神经网络的后续层对场景位置进行分类。所考虑的网络已经在从《生活大爆炸》电视剧中获得的数据集上进行了测试和比较。我们研究了不同的神经网络层来组合各个帧,特别是 AveragePooling、MaxPooling、Product、Flatten、LSTM 和双向 LSTM 层。 |
| TextCLIP: Text-Guided Face Image Generation And Manipulation Without Adversarial Training Authors Xiaozhou You, Jian Zhang 文本引导图像生成旨在根据给定文本生成所需图像,而文本引导图像操作是指根据指定文本对给定图像的部分进行语义编辑。对于这两个类似的任务,关键点是确保图像保真度和语义一致性。以前的许多方法需要复杂的多阶段生成和对抗性训练,同时努力为这两项任务提供统一的框架。在这项工作中,我们提出了 TextCLIP,这是一个无需对抗训练的文本引导图像生成和操作的统一框架。该方法接受与这两个不同任务相对应的图像或随机噪声的输入,并在特定文本的条件下,精心设计的映射网络,利用StyleGAN的强大生成能力和Contrastive Language Image Pre的文本图像表示能力训练CLIP生成目前可以生成的高达1024倍1024分辨率的图像。 |
| Unlocking the Heart Using Adaptive Locked Agnostic Networks Authors Sylwia Majchrowska, Anders Hildeman, Philip Teare, Tom Diethe 用于医学成像应用的深度学习模型的监督训练需要大量标记数据。这是一个挑战,因为图像需要由医疗专业人员进行注释。为了解决这个限制,我们引入了自适应锁定不可知网络 ALAN,这是一个涉及使用大型骨干模型进行自监督视觉特征提取以产生解剖学上稳健的语义自分割的概念。在 ALAN 方法中,这种自我监督训练仅在大型且多样化的数据集上发生一次。由于分割的直观可解释性,可以使用参数很少的白盒模型轻松设计针对特定任务定制的下游模型。反过来,这开启了与领域专家交流模型的内部运作并向其中引入先验知识的可能性。这也意味着与完全监督的方法相比,下游模型对数据的需求更少。这些特性使 ALAN 特别适合资源稀缺的场景,例如昂贵的临床试验和罕见疾病。在本文中,我们将 ALAN 方法应用于三个公开的超声心动图数据集 EchoNet Dynamic、CAMUS 和 TMED 2。我们的研究结果表明,自监督骨干模型可以在心尖四腔视图中稳健地识别心脏的解剖分区。 |
| On-the-Fly SfM: What you capture is What you get Authors Zongqian Zhan, Rui Xia, Yifei Yu, Yibo Xu, Xin Wang 在过去的几十年里,运动 SfM 结构在结构方面取得了丰硕的成果。然而,它们中的绝大多数基本上以离线方式工作,即首先捕获图像,然后将其一起馈送到 SfM 管道中以获得位姿和稀疏点云。相反,在这项工作中,我们提出了一种在图像捕获时运行在线 SfM 的即时 SfM,新拍摄的 On the Fly 图像使用相应的位姿和点进行在线估计,即,您捕获的就是您得到的。具体来说,我们的方法首先采用使用基于学习的全局特征进行无监督训练的词汇树,以对图像中新飞的图像进行快速图像检索。然后,提出了一种具有最小二乘LSM的鲁棒特征匹配机制来提高图像配准性能。最后,通过研究图像中连接的相邻图像中新飞的影响,使用高效的分层加权局部束调整BA进行优化。 |
| Using Saliency and Cropping to Improve Video Memorability Authors Vaibhav Mudgal, Qingyang Wang, Lorin Sweeney, Alan F. Smeaton 视频可记忆性是当观看者与视频内容没有情感联系时特定视频被观看者记住的可能性的度量。这是一个重要的特征,因为更令人难忘的视频更有可能被分享、观看和讨论。本文介绍了一系列实验的结果,在这些实验中,我们通过根据图像显着性有选择地裁剪帧来提高视频的可记忆性。我们展示了基本固定裁剪的结果以及动态裁剪的结果,其中裁剪的大小和裁剪在帧内的位置随着视频播放和跟踪显着性而移动。 |
| Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training Authors Shuang Zeng, Lei Zhu, Xinliang Zhang, Zifeng Tian, Qian Chen, Lujia Jin, Jiayi Wang, Yanye Lu 对比学习是一种从未标记数据中学习图像级表示的强大技术,为解决大规模预训练和有限标记数据之间的困境带来了一个有希望的方向。然而,大多数现有的对比学习策略主要是针对自然图像的下游任务而设计的,因此当直接应用于下游任务通常是分割的医学图像时,它们不是最优的,甚至比从头开始学习更糟糕。在这项工作中,我们提出了一种名为 JCL 的新型非对称对比学习框架,用于具有自监督预训练的医学图像分割。具体来说,1提出了一种新颖的非对称对比学习策略,可以在一个阶段同时预训练编码器和解码器,从而为分割模型提供更好的初始化。 2 多级对比损失旨在分别考虑特征级、图像级和像素级投影之间的对应关系,以确保编码器和解码器在预训练期间可以学习多级表示。 |
| OSNet & MNetO: Two Types of General Reconstruction Architectures for Linear Computed Tomography in Multi-Scenarios Authors Zhisheng Wang, Zihan Deng, Fenglin Liu, Yixing Huang, Haijun Yu, Junning Cui 最近,线性计算机断层扫描LCT系统引起了人们的广泛关注。为了弱化投影截断并对LCT感兴趣区域ROI进行成像,反投影过滤BPF算法是一种有效的解决方案。然而,在LCT的BPF中,很难实现稳定的内部重建,并且对于LCT的微分反投影DBP图像,希尔伯特变换的多次旋转有限逆希尔伯特滤波逆旋转操作会导致图像模糊。为了满足LCT的多种重建场景,包括内部ROI、完整物体和超出视场FOV的外部区域,并避免希尔伯特滤波的旋转操作,我们提出了两种类型的重建架构。首先叠加多个DBP图像以获得完整的DBP图像,然后使用网络学习叠加的希尔伯特滤波函数,简称为Overlay Single Network OSNet。第二种是利用多个网络分别对多次线性扫描的DBP图像训练不同方向的希尔伯特滤波模型,然后将重建结果进行叠加,即Multiple Networks Overlaying MNetO。在两种架构中,我们将 Swin Transformer ST 块引入到 pix2pixGAN 的生成器中,以同时从 DBP 图像中提取局部和全局特征。我们研究了来自不同网络、FOV 大小、像素大小、投影数量、几何放大倍率和处理时间的两种架构。实验结果表明两种架构都可以恢复图像。 OSNet 在各种场景下都优于 BPF。对于不同的网络,ST pix2pixGAN 优于 pix2pixGAN 和 CycleGAN。 |
| TCOVIS: Temporally Consistent Online Video Instance Segmentation Authors Junlong Li, Bingyao Yu, Yongming Rao, Jie Zhou, Jiwen Lu 近年来,视频实例分割VIS取得了重大进展,许多离线和在线方法都实现了最先进的性能。虽然离线方法具有产生时间一致的预测的优点,但它们不适合实时场景。相反,在线方法更实用,但保持时间一致性仍然是一项具有挑战性的任务。在本文中,我们提出了一种新颖的视频实例分割在线方法,称为 TCOVIS,它充分利用视频剪辑中的时间信息。我们方法的核心由全局实例分配策略和时空增强模块组成,从两个方面提高了特征的时间一致性。具体来说,我们在整个视频剪辑中执行预测和真实情况之间的全局最优匹配,并以全局最优目标监督模型。我们还捕获空间特征并将其与帧之间的语义特征聚合,从而实现时空增强。我们在四个广泛采用的 VIS 基准(即 YouTube VIS 2019 2021 2022 和 OVIS)上评估了我们的方法,并在所有基准上实现了最先进的性能,没有任何附加功能。例如,在 YouTube VIS 2021 上,TCOVIS 使用 ResNet 50 和 Swin L 主干网分别实现了 49.5 AP 和 61.3 AP。 |
| DEYOv3: DETR with YOLO for Real-time Object Detection Authors Haodong Ouyang 最近,端到端物体检测器由于其出色的性能而受到研究界的广泛关注。然而,DETR通常依赖于ImageNet上主干网的有监督预训练,这限制了DETR的实际应用和主干网的设计,影响了模型潜在的泛化能力。在本文中,我们提出了一种新的训练方法,称为逐步训练。具体来说,在第一阶段,使用一对多预训练的 YOLO 检测器来初始化端到端检测器。在第二阶段,主干网和编码器与DETR类模型一致,但只有检测器需要从头开始训练。由于这种训练方法,物体检测器不需要额外的数据集ImageNet来训练backbone,这使得backbone的设计更加灵活,大大降低了检测器的训练成本,有利于物体的实际应用探测器。同时,与DETR类模型相比,分步训练方法能够获得比传统DETR类模型训练方法更高的准确率。借助这种新颖的训练方法,我们提出了一种全新的端到端实时目标检测模型,称为 DEYOv3。 DEYOv3 N 在 COCO val2017 上达到 41.1,在 T4 GPU 上达到 270 FPS,而 DEYOv3 L 达到 51.3 AP 和 102 FPS。在不使用额外训练数据的情况下,DEYOv3 在速度和准确性方面都超越了所有现有的实时目标检测器。 |
| MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion Authors Ting Jiang, Chuan Wang, Xinpeng Li, Ru Li, Haoqiang Fan, Shuaicheng Liu 在本文中,我们介绍了一种高质量多重曝光图像融合 MEF 的新方法。我们证明了曝光的融合权重可以被编码到一维查找表 LUT 中,该表将像素强度值作为输入并产生融合权重作为输出。我们为每次曝光学习一个 1D LUT,然后来自不同曝光的所有像素都可以独立查询该曝光的 1D LUT,以实现高质量和高效的融合。具体来说,为了学习这些 1D LUT,我们将帧、通道和空间等各个维度的注意力机制引入到 MEF 任务中,从而使我们比最先进的 SOTA 带来显着的质量改进。此外,我们还收集了一个新的 MEF 数据集,其中包含 960 个样本,其中 155 个由专业人员手动调整,作为评估的基本事实。我们的网络以无监督的方式由该数据集进行训练。进行了大量的实验来证明所有新提出的组件的有效性,结果表明,我们的方法在我们和另一个代表性数据集 SICE 中无论是定性还是定量都优于 SOTA。此外,我们的 1D LUT 方法在 PC GPU 上运行 4K 图像只需不到 4 毫秒。鉴于其高质量、高效性和稳健性,我们的方法已被应用于全球多个品牌的数百万部 Android 手机中。 |
| MoPA: Multi-Modal Prior Aided Domain Adaptation for 3D Semantic Segmentation Authors Haozhi Cao, Yuecong Xu, Jianfei Yang, Pengyu Yin, Shenghai Yuan, Lihua Xie 用于 3D 语义分割的多模态无监督域自适应 MM UDA 是一种实用的解决方案,可将语义理解嵌入自治系统中,而无需昂贵的逐点注释。虽然以前的 MM UDA 方法可以实现整体改进,但它们存在严重的类不平衡性能,限制了它们在实际应用中的采用。这种不平衡的性能主要是由于 1 使用不平衡数据进行自训练和 2 缺乏像素级 2D 监督信号造成的。在这项工作中,我们提出了多模态先验辅助 MoPA 域自适应来提高稀有物体的性能。具体来说,我们开发了基于有效地面的插入 VGI,通过插入先前从野外收集的稀有物体来纠正不平衡的监督信号,同时避免引入导致琐碎解决方案的人工伪影。同时,我们的 SAM 一致性损失利用 SAM 的 2D 先验语义掩码作为像素级监督信号,以鼓励对语义掩码中的每个对象进行一致的预测。然后,从模态特定先验中学到的知识可以跨模态共享,以实现更好的稀有对象分割。大量实验表明,我们的方法在具有挑战性的 MM UDA 基准上实现了最先进的性能。 |
| FGFusion: Fine-Grained Lidar-Camera Fusion for 3D Object Detection Authors Zixuan Yin, Han Sun, Ningzhong Liu, Huiyu Zhou, Jiaquan Shen 激光雷达和摄像头是关键传感器,可为自动驾驶中的 3D 检测提供补充信息。虽然大多数流行的方法逐渐缩小 3D 点云和相机图像的比例,然后融合高级特征,但缩小后的特征不可避免地会丢失低级详细信息。在本文中,我们提出了细粒度激光雷达相机融合FGFusion,充分利用图像和点云的多尺度特征,并以细粒度的方式融合它们。首先,我们设计了一个双路径层次结构来提取图像的高级语义和低级详细特征。其次,引入辅助网络来引导点云特征更好地学习细粒度的空间信息。最后,我们提出多尺度融合MSF来融合图像和点云的最后N个特征图。 |
| DimCL: Dimensional Contrastive Learning For Improving Self-Supervised Learning Authors Thanh Nguyen, Trung Pham, Chaoning Zhang, Tung Luu, Thang Vu, Chang D. Yoo 自监督学习 SSL 取得了显着的成功,其中对比学习 CL 发挥了关键作用。然而,最近开发的新的非 CL 框架已经实现了可比或更好的性能,并且具有很大的改进潜力,促使研究人员进一步增强这些框架。将 CL 融入非 CL 框架被认为是有益的,但经验证据表明没有明显的改进。鉴于此,本文提出了一种沿维度方向而不是传统对比学习中沿批量方向执行CL的策略,称为维度对比学习DimCL。 DimCL 旨在增强功能多样性,它可以作为先前 SSL 框架的正则化器。 DimCL 已被证明是有效的,并且硬度感知特性被认为是其成功的关键原因。 |
| A Real-Time Multi-Task Learning System for Joint Detection of Face, Facial Landmark and Head Pose Authors Qingtian Wu, Liming Zhang 极端的头部姿势对一系列面部分析任务构成了常见的挑战,包括面部检测、面部标志检测 FLD 和头部姿势估计 HPE 。这些任务是相互依赖的,其中准确的 FLD 依赖于强大的人脸检测,而 HPE 与这些关键点有着错综复杂的关联。本文重点关注这些任务的整合,特别是在解决大角度面部姿势带来的复杂性时。这项研究的主要贡献是提出了一种实时多任务检测系统,能够同时执行人脸、面部标志和头部姿势的联合检测。该系统建立在广泛采用的 YOLOv8 检测框架之上。它通过合并额外的标志回归头来扩展原始对象检测头,从而实现关键面部标志的有效定位。此外,我们对原有YOLOv8框架内的各个模块进行了优化和增强。为了验证我们提出的模型的有效性和实时性能,我们在 300W LP 和 AFLW2000 3D 数据集上进行了广泛的实验。 |
| Fast Satellite Tensorial Radiance Field for Multi-date Satellite Imagery of Large Size Authors Tongtong Zhang, Yuanxiang Li 现有的卫星图像 NeRF 模型存在速度慢、强制输入太阳信息以及处理大型卫星图像的限制等问题。作为回应,我们提出了 SatensoRF,它显着加速了整个过程,同时为大尺寸卫星图像使用更少的参数。此外,我们观察到神经辐射场中朗伯表面的普遍假设不符合植物和水生元素的要求。与传统的基于分层 MLP 的场景表示相比,我们选择了颜色、体积密度和辅助变量的多尺度张量分解方法来对镜面反射颜色的光场进行建模。 |
| SAM-OCTA: A Fine-Tuning Strategy for Applying Foundation Model to OCTA Image Segmentation Tasks Authors Chengliang Wang, Xinrun Chen, Haojian Ning, Shiying Li 在光学相干断层扫描血管造影OCTA图像分析中,需要对特定目标进行分割操作。现有方法通常在监督数据集上进行训练,样本有限,大约为几百,这可能导致过度拟合。为了解决这个问题,采用低秩自适应技术进行基础模型微调,并提出相应的提示点生成策略来处理 OCTA 数据集上的各种分割任务。该方法被命名为 SAM OCTA,并已在公开的 OCTA 500 数据集上进行了实验。在实现最先进的性能指标的同时,该方法实现了局部血管分割以及有效的动脉静脉分割,这在以前的工作中没有得到很好的解决。 |
| 2DDATA: 2D Detection Annotations Transmittable Aggregation for Semantic Segmentation on Point Cloud Authors Guan Cheng Lee 最近,由于激光雷达和摄像头等不同传感器的信息互补,多模态模型被引入。它需要配对数据以及对所有模态的精确校准,模态之间复杂的校准极大地增加了收集此类高质量数据集的成本,并阻碍了其应用于实际场景。继承之前的工作,我们不仅融合了多模态的信息而没有上述问题,而且还耗尽了RGB模态的信息。我们引入了2D检测注释可传输聚合textbf 2DDATA,设计了一个数据特定分支,称为textbf本地对象分支,其目的是处理某个边界框中的点,因为它很容易获取2D边界框注释。 |
| A Vision-Centric Approach for Static Map Element Annotation Authors Jiaxin Zhang, Shiyuan Chen, Haoran Yin, Ruohong Mei, Xuan Liu, Cong Yang, Qian Zhang, Wei Sui 在线静态地图元素(又称高清地图构建算法)的最新发展对具有地面实况注释的数据提出了巨大的需求。然而,现有的公共数据集目前无法提供有关一致性和准确性的高质量训练数据。为此,我们提出了 CAMA 一种以视觉为中心的方法,以实现一致且准确的地图注释。如果没有 LiDAR 输入,我们提出的框架仍然可以生成静态地图元素的高质量 3D 注释。具体来说,注释可以在所有周围的摄像机上实现高重投影精度,并且在整个序列上保持时空一致。我们将我们提出的框架应用于流行的 nuScenes 数据集,以提供高效且高度准确的注释。 |
| How Robust is Google's Bard to Adversarial Image Attacks? Authors Yinpeng Dong, Huanran Chen, Jiawei Chen, Zhengwei Fang, Xiao Yang, Yichi Zhang, Yu Tian, Hang Su, Jun Zhu 多模态大语言模型 集成文本和其他模态(尤其是视觉)的 MLLM 在各种多模态任务中取得了前所未有的性能。然而,由于视觉模型的对抗鲁棒性问题尚未解决,MLLM 通过引入视觉输入可能会带来更严重的安全风险。在这项工作中,我们研究了 Google 的 Bard 的对抗鲁棒性,这是 ChatGPT 的竞争聊天机器人,最近发布了其多模式功能,以更好地了解商业 MLLM 的漏洞。通过攻击白盒代理视觉编码器或 MLLM,生成的对抗性示例可能会误导 Bard 输出错误的图像描述,仅基于可转移性,成功率为 22。我们表明,对抗性示例还可以攻击其他 MLLM,例如,针对 Bing Chat 的攻击成功率为 26,针对 ERNIE 机器人的攻击成功率为 86。此外,我们还确定了 Bard 的两种防御机制,包括人脸检测和图像毒性检测。我们设计了相应的攻击来规避这些防御,这表明巴德目前的防御也是脆弱的。我们希望这项工作能够加深我们对 MLLM 鲁棒性的理解,并促进未来的防御研究。 |
| CPR-Coach: Recognizing Composite Error Actions based on Single-class Training Authors Shunli Wang, Qing Yu, Shuaibing Wang, Dingkang Yang, Liuzhen Su, Xiao Zhao, Haopeng Kuang, Peixuan Zhang, Peng Zhai, Lihua Zhang 细粒度的医疗行为分析任务最近受到了模式识别界的广泛关注,但它面临着数据和算法短缺的问题。心肺复苏 CPR 是紧急救治中的一项基本技能。目前,心肺复苏技能的考核主要依靠假人和培训师,导致培训成本高、效率低。本文首次构建了基于视觉的系统来完成CPR中的错误动作识别和技能评估。具体来说,我们定义了心脏外按压期间的 13 种单一错误动作和 74 种复合错误动作,然后开发了一个名为 CPR Coach 的视频数据集。本文以 CPR Coach 为基准,深入研究并比较了现有基于不同数据模态的动作识别模型的性能。为了解决不可避免的单类训练多类测试问题,我们提出了一种名为 ImagineNet 的人类认知启发框架,以提高模型在受限监督下的多错误识别性能。大量的实验验证了该框架的有效性。我们希望这项工作能够推进细粒度医疗行为分析和技能评估的研究。 |
| Deshadow-Anything: When Segment Anything Model Meets Zero-shot shadow removal Authors Xiao Feng Zhang, Tian Yi Song, Jia Wei Yao Segment Anything SAM 是一种在广泛的视觉数据集上训练的高级通用图像分割模型,为图像分割和计算机视觉树立了新的基准。然而,在区分阴影及其背景时,它面临着挑战。为了解决这个问题,我们开发了Deshadow Anything,考虑到大规模数据集的泛化性,我们对大规模数据集进行了微调以实现图像阴影去除。扩散模型可以沿着图像的边缘和纹理扩散,有助于去除阴影,同时保留图像的细节。此外,我们设计了多自注意力引导MSAG和自适应输入扰动DDPM AIP来加速扩散的迭代训练速度。 |
| MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation Authors Fei Pan, Xu Yin, Seokju Lee, Sungeui Yoon, In So Kweon 无监督域适应 UDA 是处理语义分割任务目标域中注释缺失的有效方法。在这项工作中,我们考虑了一种更实用的 UDA 设置,其中目标域包含未标记视频的连续帧,这些帧在实践中很容易收集。最近的一项研究表明,从具有几何约束的未标记视频中对物体运动进行自我监督学习。我们设计了一个运动引导域自适应语义分割框架 MoDA,它利用自监督对象运动来学习目标域中的有效表示。 MoDA 与之前对目标域帧使用时间一致性正则化的方法不同。相反,MoDA 使用不同的策略分别处理前景和背景类别上的域对齐。具体来说,MoDA 包含前景对象发现和前景语义挖掘,通过从对象运动获取实例级指导来对齐前景域间隙。此外,MoDA 还包括背景对抗训练,其中包含背景类别特定的鉴别器来处理背景域差距。多个基准的实验结果凸显了 MoDA 相对于域自适应图像分割和域自适应视频分割中现有方法的有效性。 |
| Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation Authors Ping Li, Yu Zhang, Li Yuan, Huaxin Xiao, Binbin Lin, Xianghua Xu 无监督视频对象分割 VOS 旨在在没有任何先验知识的情况下识别视频中主要前景对象的轮廓。然而,以前的方法没有充分利用时空上下文,无法实时解决这一具有挑战性的任务。这促使我们从整体角度开发一种高效的长短时间注意力网络,称为 LSTA,用于无监督 VOS 任务。具体来说,LSTA由两个主要模块组成,即长时间记忆和短时间注意力。前者捕获过去帧和当前帧的长期全局像素关系,它通过编码外观模式来对持续存在的对象进行建模。同时,后者揭示了附近一帧和当前帧的短期局部像素关系,通过编码运动模式来建模运动对象。为了加速推理,采用高效投影和基于局部性的滑动窗口分别实现两个光模块接近线性的时间复杂度。 |
| Understanding Pose and Appearance Disentanglement in 3D Human Pose Estimation Authors Krishna Kanth Nakka, Mathieu Salzmann 由于现在可以在监督学习场景中以非常高的精度实现 3D 人体姿势估计,因此解决 3D 姿势注释不可用的情况受到越来越多的关注。特别是,已经提出了几种以自监督方式学习图像表示的方法,以便将外观信息与姿势信息分开。然后,这些方法只需要少量的监督数据来使用姿势相关的潜在向量作为输入来训练姿势回归器,因为它应该没有外观信息。在本文中,我们进行了深入分析,以了解最先进的解纠缠表示学习方法在多大程度上真正将外观信息与姿势信息分开。首先,我们通过各种图像合成实验,从自监督网络的角度研究解缠结。其次,我们从对抗性攻击的角度研究了 3D 姿态回归器的解缠结。具体来说,我们设计了一种对抗策略,专注于生成主体的自然外观变化,并且我们可以预期解开的网络是稳健的。总而言之,我们的分析表明,三种最先进的表示学习框架的解缠还远未完成,并且它们的姿势代码包含重要的外观信息。 |
| Neural Image Compression Using Masked Sparse Visual Representation Authors Wei Jiang, Wei Wang, Yue Chen 我们研究基于稀疏视觉表示 SVR 的神经图像压缩,其中图像被嵌入到由学习的视觉码本跨越的离散潜在空间中。通过与解码器共享码本,编码器传输高效且跨平台稳健的整数码字索引,并且解码器使用索引来检索嵌入的潜在特征以进行重建。先前基于SVR的压缩缺乏有效的率失真权衡机制,只能追求高重建质量或低传输比特率。我们提出了一种掩码自适应密码本学习 M AdaCode 方法,该方法将掩码应用于潜在特征子空间以平衡比特率和重建质量。学习一组依赖于语义类别的基础码本,将它们加权组合以生成用于高质量重建的丰富的潜在特征。组合权重是从每个输入图像自适应地导出的,以额外的传输成本提供保真度信息。通过在编码器中屏蔽掉不重要的权重并在解码器中恢复它们,我们可以权衡传输比特的重建质量,并且屏蔽率控制比特率和失真之间的平衡。 |
| Orbital AI-based Autonomous Refuelling Solution Authors Duarte Rondao, Lei He, Nabil Aouf 由于其外形尺寸小且功耗、质量和体积成本低廉,相机正迅速成为太空交会机载传感器的选择。然而,在对接方面,它们通常扮演次要角色,而主要工作是由激光雷达等主动传感器完成的。本文记录了一种基于人工智能的人工智能导航算法的开发,旨在成熟使用机载可见波长相机作为对接和在轨服务 OOS 的主要传感器,减少对激光雷达的依赖并大大降低成本。具体来说,人工智能的使用可以将相对导航解决方案扩展到多种场景,例如,在目标或照明条件方面,否则必须使用经典图像处理方法逐案制作。多个卷积神经网络 CNN 主干架构以与国际空间站 ISS 对接操作的综合生成数据为基准,分别实现接近 1 范围归一化和 1 度的位置和姿态估计。 |
| Attentive VQ-VAE Authors Mariano Rivera, Angello Hoyos 我们提出了一种新颖的方法,通过集成注意力残差编码器 AREN 和残差像素注意力层来增强 VQVAE 模型的功能。我们研究的目标是提高 VQVAE 的性能,同时保持实用的参数水平。 AREN 编码器旨在在多个级别上有效运行,适应不同的架构复杂性。关键的创新是将像素间自动注意机制集成到 AREN 编码器中。这种方法使我们能够有效地捕获和利用潜在向量的上下文信息。此外,我们的模型使用额外的编码级别来进一步增强模型的表示能力。我们的注意力层采用最小参数方法,确保仅当来自其他像素的相关信息可用时才修改潜在向量。 |
| GenLayNeRF: Generalizable Layered Representations with 3D Model Alignment for Multi-Human View Synthesis Authors Youssef Abdelkareem, Shady Shehata, Fakhri Karray 由于复杂的人际遮挡,多人类场景的新颖视图合成 NVS 提出了挑战。分层表示通过将场景划分为多层辐射场来处理复杂性,但是,它们主要受限于每个场景的优化,从而导致效率低下。可泛化的人体视图合成方法将预装的 3D 人体网格与图像特征相结合以达到泛化的目的,但它们主要设计用于在单个人体场景上操作。另一个缺点是依赖多步优化技术来对 3D 身体模型进行参数预拟合,这些模型在稀疏视图设置中与图像未对准,从而导致合成视图中出现幻觉。在这项工作中,我们提出了 GenLayNeRF,一种通用的分层场景表示,用于多个人类主体的自由视点渲染,不需要每个场景优化和非常稀疏的视图作为输入。我们将场景划分为由 3D 身体网格锚定的多个人体层。然后,我们通过新颖的端到端可训练模块确保身体模型与输入视图的像素级对齐,该模块执行迭代参数校正并结合多视图特征融合以生成对齐的 3D 模型。对于 NVS,我们提取逐点图像对齐和人类锚定特征,这些特征使用自注意力和交叉注意力模块进行关联和融合。我们使用基于注意力的 RGB 融合模块将低级 RGB 值增强到特征中。为了评估我们的方法,我们构建了两个多人类视图合成数据集 DeepMultiSyn 和 ZJU MultiHuman。 |
| Hand Gesture Recognition with Two Stage Approach Using Transfer Learning and Deep Ensemble Learning Authors Serkan Sava , Atilla Erg zen 人机交互 HCI 多年来一直是研究的主题,最近的研究重点是通过各种技术提高其性能。在过去的十年中,深度学习研究在各个研究领域都表现出了出色的表现,促使研究人员探索其在人机交互中的应用。卷积神经网络可用于使用深层架构从图像中识别手势。在本研究中,我们在 HG14 数据集上评估了预训练的高性能深度架构,该数据集由 14 种不同的手势类别组成。在 22 个不同的模型中,VGGNet 和 MobileNet 模型的版本获得了最高的准确率。具体来说,VGG16和VGG19模型的准确率分别为94.64和94.36,而MobileNet和MobileNetV2模型的准确率分别为96.79和94.43。我们使用集成学习技术对数据集进行手势识别,该技术结合了四种最成功的模型。通过利用这些模型作为基础学习器并应用 Dirichlet 集成技术,我们实现了 98.88 的准确率。 |
| Sentence Attention Blocks for Answer Grounding Authors Seyedalireza Khoshsirat, Chandra Kambhamettu 答案接地是为视觉问答任务找到相关视觉证据的任务。虽然针对此任务引入了各种各样的注意力方法,但它们面临以下三个问题:设计不允许使用预训练网络,并且无法从大数据预训练中受益,定制设计不基于良好的模型。植根于以前的设计,因此限制了网络的学习能力,或者复杂的设计使得重新实施或改进它们变得具有挑战性。在本文中,我们提出了一种新颖的架构块,我们称之为句子注意块,来解决这些问题。所提出的块通过显式建模图像特征图和句子嵌入之间的相互依赖性来重新校准通道明智的图像特征图。我们直观地演示了该块如何基于句子嵌入过滤掉不相关的特征映射通道。我们以众所周知的注意力方法开始我们的设计,并通过进行微小的修改,我们改进了结果以实现最先进的准确性。我们的方法的灵活性使得可以轻松使用不同的预训练骨干网络,并且其简单性使其易于理解和重新实现。我们在 TextVQA X、VQS、VQA X 和 VizWiz VQA Grounding 数据集上证明了我们的方法的有效性。 |
| Continuous Levels of Detail for Light Field Networks Authors David Li, Brandon Y. Feng, Amitabh Varshney 最近,出现了几种生成具有多级细节 LOD 的神经表示的方法。 LOD 可以在适当的时候通过使用较低的分辨率和较小的模型尺寸来改进渲染。然而,现有的方法通常关注一些离散的 LOD,这些细节随着细节的改变而受到混叠和闪烁伪影的影响,并限制了它们适应资源限制的粒度。在本文中,我们提出了一种使用连续 LOD 来编码光场网络的方法,从而可以根据渲染条件进行微调。我们的训练过程使用求和面积表过滤,可以在各种 LOD 上进行高效、连续的过滤。此外,我们使用基于显着性的重要性采样,这使得我们的光场网络能够分配其容量(特别是在较低 LOD 时受到限制),以表示观看者最有可能关注的细节。 |
| Distilling Adversarial Prompts from Safety Benchmarks: Report for the Adversarial Nibbler Challenge Authors Manuel Brack, Patrick Schramowski, Kristian Kersting 文本条件图像生成模型最近取得了惊人的图像质量和对齐结果。因此,它们被用于越来越多的应用中。由于它们是高度数据驱动的,依赖于从网络上随机抓取的数十亿规模的数据集,因此它们也会产生不安全的内容。作为对 Adversarial Nibbler 挑战的贡献,我们从现有安全基准中提炼出一大批超过 1,000 个潜在的对抗性输入。 |
| Revisiting Kernel Temporal Segmentation as an Adaptive Tokenizer for Long-form Video Understanding Authors Mohamed Afham, Satya Narayan Shukla, Omid Poursaeed, Pengchuan Zhang, Ashish Shah, Sernam Lim 虽然大多数现代视频理解模型都在短距离剪辑上运行,但现实世界的视频通常长达几分钟,并且具有语义一致的可变长度片段。处理长视频的常见方法是在固定时间长度的均匀采样剪辑上应用短格式视频模型并聚合输出。这种方法忽略了长视频的根本性质,因为固定长度的剪辑通常是多余的或无信息的。在本文中,我们的目标是为长视频提供一种通用且自适应的采样方法,以代替事实上的均匀采样。将视频视为语义一致的片段,我们制定了一种基于内核时间分割 KTS 的任务无关、无监督且可扩展的方法,用于对长视频进行采样和标记。 |
| EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian Authors Ofir Gordon, Hai Victor Habi, Arnon Netzer 深度神经网络 DNN 的量化已成为将此类网络嵌入最终用户设备的关键要素。然而,当前的量化方法通常会遭受代价高昂的精度下降。在本文中,我们提出了一种名为 EPTQ 的增强训练后量化新方法。该方法基于具有自适应层权重的知识蒸馏。此外,我们引入了一种新的无标签技术来近似任务损失的 Hessian 迹,称为无标签 Hessian。该技术消除了计算 Hessian 矩阵所需的标记数据集。自适应知识蒸馏使用无标签 Hessian 技术,在执行优化时更加关注模型的敏感部分。根据经验,通过采用 EPTQ,我们在各种模型、任务和数据集上取得了最先进的结果,包括 ImageNet 分类、COCO 对象检测和用于语义分割的 Pascal VOC。 |
| Light Field Diffusion for Single-View Novel View Synthesis Authors Yifeng Xiong, Haoyu Ma, Shanlin Sun, Kun Han, Xiaohui Xie 单视图新颖视图合成是基于单个参考图像从新视点生成图像的任务,是计算机视觉中的一项重要但具有挑战性的任务。最近,去噪扩散概率模型DDPM因其强大的生成高保真图像的能力而在该领域变得流行。然而,当前基于扩散的方法直接依赖相机位姿矩阵作为观看条件,全局且隐式地引入 3D 约束。这些方法可能会遇到从不同角度生成的图像不一致的问题,特别是在具有复杂纹理和结构的区域。在这项工作中,我们提出了光场扩散 LFD,这是一种基于条件扩散的单视图新颖视图合成模型。与之前使用相机位姿矩阵的方法不同,LFD 将相机视图信息转换为光场编码,并将其与参考图像组合。该设计在扩散模型中引入了局部像素约束,从而鼓励更好的多视图一致性。对多个数据集的实验表明,我们的 LFD 可以有效生成高保真图像,即使在复杂的区域也能保持更好的 3D 一致性。 |
| RMT: Retentive Networks Meet Vision Transformers Authors Qihang Fan, Huaibo Huang, Mingrui Chen, Hongmin Liu, Ran He Transformer 最早出现在自然语言处理领域,后来迁移到计算机视觉领域,在视觉任务中表现出了优异的性能。然而最近,Retentive Network RetNet 作为一种有潜力取代 Transformer 的架构出现,引起了 NLP 界的广泛关注。因此,我们提出一个问题:将RetNet的思想转移到视觉上是否也能为视觉任务带来出色的表现。为了解决这个问题,我们结合RetNet和Transformer提出了RMT。受 RetNet 的启发,RMT 在视觉主干中引入了显式衰减,将与空间距离相关的先验知识引入视觉模型。这种与距离相关的空间先验允许对每个令牌可以关注的令牌范围进行显式控制。此外,为了减少全局建模的计算成本,我们沿着图像的两个坐标轴分解该建模过程。大量实验表明,我们的 RMT 在各种计算机视觉任务中表现出卓越的性能。例如,RMT 仅使用 4.5G FLOP 在 ImageNet 1k 上实现了 84.1 Top1 acc。据我们所知,在所有模型中,当模型大小相似并使用相同策略进行训练时,RMT 获得了最高的 Top1 acc。此外,RMT 在目标检测、实例分割和语义分割等下游任务中显着优于现有的视觉主干。 |
| ForceSight: Text-Guided Mobile Manipulation with Visual-Force Goals Authors Jeremy A. Collins, Cody Houff, You Liang Tan, Charles C. Kemp 我们推出了 ForceSight,这是一种用于文本引导移动操作的系统,可使用深度神经网络预测视觉力目标。给定与文本提示相结合的单个 RGBD 图像,ForceSight 确定相机帧运动学目标中的目标末端执行器姿势以及相关的力 力目标 。这两个组成部分共同构成了视觉力目标。先前的工作已经证明,输出人类可解释的运动学目标的深度模型可以实现真实机器人的灵巧操纵。力对于操纵至关重要,但在这些系统中通常被降级到较低级别的执行。当部署在配备有手眼 RGBD 摄像头的移动机械手上时,ForceSight 执行了诸如精确抓取、抽屉打开和对象移交等任务,在未见过的环境中(对象实例与训练数据存在显着差异)的成功率为 81。在一项单独的实验中,仅依靠视觉伺服并忽略力目标将成功率从 90 降至 45,这表明力目标可以显着提高性能。 |
| Environment-biased Feature Ranking for Novelty Detection Robustness Authors Stefan Smeu, Elena Burceanu, Emanuela Haller, Andrei Liviu Nicolicioiu 我们解决了鲁棒的新颖性检测问题,我们的目标是检测语义内容方面的新颖性,同时对其他不相关因素的变化保持不变。具体来说,我们在具有多个环境的设置中进行操作,我们确定与环境更多相关的一组功能,而不是与任务相关的内容。因此,我们提出了一种方法,该方法从预训练的嵌入和多环境设置开始,并设法根据环境焦点对功能进行排名。首先,我们根据环境之间的特征分布方差计算每个特征的得分。接下来,我们表明,通过丢弃高分的相关性,我们成功地消除了虚假相关性,并将整体性能提高了 6 倍,无论是在协方差还是子总体转移情况下,无论是对于我们引入的真实基准还是综合基准。 |
| See to Touch: Learning Tactile Dexterity through Visual Incentives Authors Irmak Guzey, Yinlong Dai, Ben Evans, Soumith Chintala, Lerrel Pinto 为多指机器人配备触觉传感对于实现人类所擅长的精确、接触丰富且灵巧的操作至关重要。然而,仅仅依靠触觉感知无法提供足够的线索来推理物体的空间配置,从而限制了纠正错误和适应不断变化的情况的能力。在本文中,我们提出了视觉激励的触觉适应 TAVI,这是一个新框架,通过使用基于视觉的奖励优化灵巧策略来增强基于触觉的灵巧性。首先,我们使用基于对比的目标来学习视觉表示。接下来,我们通过基于人类演示的最佳传输匹配,使用这些视觉表示构建奖励函数。最后,我们在机器人上使用在线强化学习来优化基于触觉的策略,从而最大化视觉奖励。在六项具有挑战性的任务上,例如挂钩拾放、拆碗和翻转细长物体,TAVI 使用我们的四指 Allegro 机器人手实现了 73 的成功率。与使用基于触觉和视觉的奖励的策略相比,性能提高了 108 倍,比没有触觉观察输入的策略提高了 135 倍。 |
| Adaptive Input-image Normalization for Solving Mode Collapse Problem in GAN-based X-ray Images Authors Muhammad Muneeb Saad, Mubashir Husain Rehmani, Ruairi O Reilly 由于目标疾病的稀有性,生物医学图像数据集可能会不平衡。生成对抗网络通过生成合成图像来增强数据集,在解决这种不平衡方面发挥着关键作用。生成包含各种特征的合成图像以准确表示训练图像中存在的特征分布非常重要。此外,合成图像中缺乏多样化特征可能会降低机器学习分类器的性能。模式崩溃问题影响生成对抗网络生成多样化图像的能力。模式崩溃有类内和类间两种形式。本文研究了这两种模式崩溃问题,并评估了它们对合成 X 射线图像多样性的后续影响。这项工作通过实证证明了将自适应输入图像归一化与深度卷积 GAN 和辅助分类器 GAN 相结合以缓解模式崩溃问题的好处。合成生成的图像用于数据增强和训练 Vision Transformer 模型。使用准确度、召回率和精确度分数来评估模型的分类性能。 |
| Brain Tumor Detection Using Deep Learning Approaches Authors Razia Sultana Misu 脑肿瘤是异常细胞的集合,可以发展成肿块或簇。由于它们有可能渗透其他组织,因此对患者构成风险。使用的主要成像技术 MRI 或许能够准确识别脑肿瘤。大量的训练数据和模型构建的改进促进了计算机视觉应用中深度学习方法的快速发展,这些方法在监督环境中提供了更好的近似值。对这些方法的需求一直是这种扩张的主要驱动力。深度学习方法在提高使用磁共振成像 MRI 进行脑肿瘤检测和分类的精度方面已显示出希望。本摘要介绍了使用深度学习技术(尤其是 ResNet50)进行脑肿瘤识别的研究。因此,本研究探讨了使用深度学习技术自动化检测过程的可能性。在本研究中,我使用了五种迁移学习模型,即 VGG16、VGG19、DenseNet121、ResNet50 和 YOLO V4,其中 ResNet50 提供最佳或最高准确度 99.54 。 |
| SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs Authors Guangyao Zhai, Xiaoni Cai, Dianye Huang, Yan Di, Fabian Manhardt, Federico Tombari, Nassir Navab, Benjamin Busam 对象重新排列在机器人环境交互中至关重要,代表了嵌入式人工智能的重要功能。在本文中,我们提出了 SG Bot,这是一种新颖的重排框架,它利用从粗到细的方案,并以场景图作为场景表示。与之前依赖已知目标先验或零样本大型模型的方法不同,SG Bot 体现了轻量级、实时和用户可控的特性,将常识知识的考虑与自动生成功能无缝地融合在一起。 SG Bot 采用三重过程观察、想象和执行来熟练地完成任务。最初,在观察过程中从杂乱的场景中识别和提取物体。这些对象首先在常识或用户定义的标准的指导下在场景图中进行粗略组织和描述。然后,该场景图随后通知生成模型,该模型考虑来自初始场景和对象语义的形状信息,形成细粒度的目标场景。最后,在执行过程中,将初始目标场景与设想的目标场景进行匹配,以制定机器人动作策略。 |
| Information Forensics and Security: A quarter-century-long journey Authors Mauro Barni, Patrizio Campisi, Edward J. Delp, Gwenael Do rr, Jessica Fridrich, Nasir Memon, Fernando P rez Gonz lez, Anderson Rocha, Luisa Verdoliva, Min Wu 信息取证和安全 IFS 是一个活跃的研发领域,其目标是确保人们将设备、数据和知识产权用于授权目的,并促进收集确凿证据以追究肇事者的责任。自 20 世纪 90 年代以来的四分之一个世纪以来,IFS 研究领域取得了巨大的发展,以满足数字信息时代的社会需求。 IEEE 信号处理协会 SPS 已成为该领域的重要中心和领导者,下面的文章赞扬了一些具有里程碑意义的技术贡献。 |
| AutoPET Challenge 2023: Sliding Window-based Optimization of U-Net Authors Matthias Hadlich, Zdravko Marinov, Rainer Stiefelhagen 医学成像中的肿瘤分割至关重要,并且依赖于精确的描绘。氟脱氧葡萄糖正电子发射断层扫描 FDG PET 广泛应用于临床实践中检测代谢活跃的肿瘤。然而,FDG PET 扫描可能会将健康或良性组织中不规则的葡萄糖消耗误解为癌症。将 PET 与计算机断层扫描 CT 相结合可以通过整合代谢和解剖信息来增强肿瘤分割。 FDG PET CT 扫描对于癌症分期和重新评估至关重要,利用放射性标记的氟脱氧葡萄糖来突出代谢活跃区域。准确地区分肿瘤特异性摄取与正常组织的生理摄取是精确肿瘤分割的一个具有挑战性的方面。 AutoPET 挑战赛通过提供 1014 项 FDG PET CT 研究数据集来解决这一问题,鼓励 FDG PET CT 领域内准确肿瘤分割和分析的进步。 |
| Bayesian sparsification for deep neural networks with Bayesian model reduction Authors Dimitrije Markovi , Karl J. Friston, Stefan J. Kiebel 深度学习的巨大能力往往受到其模型复杂性的限制,导致对有效稀疏化技术的需求不断增加。深度学习的贝叶斯稀疏化成为一种重要的方法,有助于设计出在各种深度学习应用中计算效率高且在性能方面具有竞争力的模型。深度神经网络贝叶斯稀疏化的最新技术将模型权重的结构收缩先验与基于黑盒随机变分推理的近似推理方案相结合。然而,完整生成模型的模型反演对计算的要求极高,特别是与点估计的标准深度学习相比。在这种情况下,我们主张使用贝叶斯模型缩减 BMR 作为模型权重修剪的更有效替代方案。作为 Savage Dickey 比率的推广,BMR 允许基于简单的非分层生成模型下的后验估计事后消除冗余模型权重。我们的比较研究强调了当应用于全层次生成模型时,BMR 方法相对于已建立的随机变分推理 SVI 方案的计算效率和剪枝率。 |
| Demystifying Visual Features of Movie Posters for Multi-Label Genre Identification Authors Utsav Kumar Nareti, Chandranath Adak, Soumi Chattopadhyay 在电影行业,电影海报几十年来一直是广告和营销的重要组成部分,即使在今天,通过在线、社交媒体和 OTT 平台以数字海报的形式继续发挥着至关重要的作用。通常,电影海报可以有效地宣传和传达电影的精髓,例如电影的类型、视觉风格基调、氛围和故事情节线索主题,这些对于吸引潜在观众至关重要。识别电影的类型通常在向目标观众推荐电影方面具有重要的实际应用。以往对电影类型识别的研究仅限于字幕、剧情简介和电影场景,这些内容大多在电影上映后才能获取。海报通常包含发布前的隐含信息以引起大众兴趣。在本文中,我们仅从电影海报图像中进行自动多标签流派识别,而无需任何有关电影的附加文本元数据信息的帮助,这是此类技术中最早的尝试之一。在这里,我们提出了一个带有概率模块的深度变压器网络,用于仅从海报中识别电影类型。 |
| Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection Authors Haopeng Zhang, Zijing Lin, Feng Gao, Junyu Dong, Qian Du, Heng Chao Li 合成孔径雷达SAR图像变化检测是一项关键任务,在遥感界受到越来越多的关注。然而,现有的SAR变化检测方法主要基于卷积神经网络CNN,对全局注意力机制的考虑有限。在这封信中,我们探索了类似 Transformer 的 SAR 变化检测架构,以纳入全球关注。为此,我们提出了一个卷积和注意力混合器 CAMixer 。首先,为了补偿 Transformer 的归纳偏差,我们以并行方式将自注意力与移位卷积结合起来。并行设计通过自注意力有效捕获全局语义信息,并同时通过移位卷积进行局部特征提取。其次,我们在前馈网络中采用门控机制来增强非线性特征转换。门控机制被表述为两个平行线性层的元素相乘。可以突出显示重要的特征,从而获得针对散斑噪声的高质量表示。在三个 SAR 数据集上进行的大量实验验证了所提出的 CAMixer 的优越性能。 |
| Identification of pneumonia on chest x-ray images through machine learning Authors Eduardo Augusto Roeder 肺炎是世界上婴儿死亡的主要原因。如果及早发现,就有可能改变患者的预后,可以使用影像学检查来帮助诊断确认。尽快执行和解释检查对于良好的治疗至关重要,这种病理最常见的检查是胸部 X 光检查。本研究的目的是开发一种软件,可以识别胸片中是否存在肺炎。该软件是使用迁移学习技术作为基于机器学习的计算模型开发的。在训练过程中,图像是从在线数据库中收集的,其中包含在中国一家医院拍摄的儿童胸部 X 光图像。训练结束后,模型被暴露于新的图像中,在识别此类病理学方面取得了相关结果,用于测试的样本达到了 98 的敏感性和 97.3 的特异性。 |
| Neural Stochastic Screened Poisson Reconstruction Authors Silvia Sell n, Alec Jacobson 从点云重建表面是一个未确定的问题。我们使用神经网络来研究和量化泊松平滑先验下的这种重建不确定性。 |
| Crop Row Switching for Vision-Based Navigation: A Comprehensive Approach for Efficient Crop Field Navigation Authors Rajitha de Silva, Grzegorz Cielniak, Junfeng Gao 耕地中基于视觉的移动机器人导航系统大多局限于行间导航。在此类系统中,从一个作物行切换到下一个作物行的过程通常需要 GNSS 传感器或多个摄像机设置的帮助。本文提出了一种基于视觉的新颖作物行切换算法,该算法使移动机器人能够使用单个前置摄像头导航整个可耕作作物田地。所提出的行切换操作使用基于深度学习的 RGB 图像分割和深度数据来检测作物行的末端,并重新进入下一个作物行的入口点,这将在多状态行切换管道中使用。该管道的每个状态都使用机器人的视觉反馈或车轮里程计来成功导航到下一个作物行。拟议的作物行导航管道在真实的甜菜田中进行了测试,该田地中的作物行具有不连续性、不同的光照水平、阴影和不规则的岬角表面。 |
| Bridging the Gap: Learning Pace Synchronization for Open-World Semi-Supervised Learning Authors Bo Ye, Kai Gan, Tong Wei, Min Ling Zhang 在开放世界半监督学习中,机器学习模型的任务是从未标记数据中发现新类别,同时保持从标记数据中看到的类别的性能。主要挑战是已知类别和新类别之间存在巨大的学习差距,因为由于准确的监督信息,模型可以更快地学习前者。为了解决这个问题,我们引入了 1 一种基于估计类别分布的自适应边缘损失,它鼓励所见类别中的样本具有较大的负边缘,以同步学习速度;以及 2 伪标签对比聚类,它将可能来自类别的样本聚集在一起输出空间中的同一类,以增强新类发现。我们对多个数据集的广泛评估表明,现有模型仍然阻碍新类别的学习,而我们的方法惊人地平衡了已知类别和新类别,与现有技术相比,在 ImageNet 数据集上实现了 3 倍的平均准确率显着提高。此外,我们发现,微调自我监督的预训练骨干网可以显着提高性能,优于先前文献中的默认设置。 |
| Spatial-Temporal Transformer based Video Compression Framework Authors Yanbo Gao, Wenjia Huang, Shuai Li, Hui Yuan, Mao Ye, Siwei Ma 近年来,学习视频压缩 LVC 取得了显着的进步。与传统视频编码类似,LVC继承了运动估计补偿、残差编码等模块,所有这些模块都是用神经网络NN来实现的。然而,在神经网络及其使用梯度反向传播的训练机制的框架内,大多数现有的工作往往难以从输入的颜色特征中一致地生成稳定的运动信息,这些信息以几何特征的形式存在。而且,帧间预测和残差编码等模块彼此独立,使得充分降低时空冗余的效率低下。为了解决上述问题,在本文中,我们提出了一种基于空间时间变换器的视频压缩 STT VC 框架。它包含一个松弛可变形变压器 RDT,具有基于 Uformer 的偏移估计,用于运动估计和补偿,一个基于多参考帧的多粒度预测 MGP 模块,用于预测细化,以及一个基于空间特征分布先验的变压器 SFD T,用于高效的时空联合残差压缩。具体来说,RDT通过深入研究基于相似性的几何运动特征提取和自注意力之间的关系来稳定地估计帧之间的运动信息。 MGP旨在通过有效探索利用编码运动信息生成的粗粒度预测特征来融合多参考帧信息。 SFD T是通过联合探索残差和时间预测中的空间特征分布来压缩残差信息,以进一步减少时空冗余。 |
| Heart Rate Detection Using an Event Camera Authors Aniket Jagtap, RamaKrishna Venkatesh Saripalli, Joe Lemley, Waseem Shariff, Alan F. Smeaton 事件相机,也称为神经形态相机,是一种新兴技术,与传统的快门和基于帧的相机相比,具有高时间分辨率、低功耗和选择性数据采集等优势。在这项研究中,我们建议利用基于事件的相机的功能来捕捉由手腕区域血流脉动引起的皮肤表面的细微变化。我们研究事件摄像机是否可用于连续无创监测心率 HR。收集并分析了 25 名参与者(包括不同年龄组和肤色)的事件摄像机视频数据。使用传统方法获得的地面真实心率测量值用于评估从事件摄像机数据自动检测心率的准确性。我们的实验结果以及与其他非接触式心率测量方法的性能比较证明了使用事件相机进行脉搏检测的可行性。 |
| Automatic Endoscopic Ultrasound Station Recognition with Limited Data Authors Abhijit Ramesh, Anantha Nandanan, Anantha Nandanan, Priya Nair MD, Gilad Gressel 胰腺癌是一种致命的癌症,在全世界范围内导致癌症相关死亡。早期检测对于改善患者预后和生存率至关重要。尽管医学成像技术取得了进步,但胰腺癌仍然是一种具有挑战性的疾病检测。超声内镜 EUS 是检测胰腺癌最有效的诊断工具。然而,它需要专家对复杂的超声图像进行解释才能完成可靠的患者扫描。为了获得胰腺的完整成像,医生必须学会引导内窥镜进入多个 EUS 站解剖位置,这些位置提供胰腺的不同视图。这是一项很难学习的技能,需要在经验丰富的医生的支持下进行超过 225 次受监督的手术。我们构建了一种人工智能辅助工具,利用深度学习技术在 EUS 手术过程中实时识别胃的这些部位。该计算机辅助诊断 CAD 将帮助更有效地培训医生。从历史上看,开发这种工具所面临的挑战是训练有素的临床医生所需的回顾性标签的数量。为了解决这个问题,我们开发了一款开源用户友好的标签网络应用程序,该应用程序可以简化 EUS 手术期间注释站点的过程,而临床医生只需付出最少的努力。我们的研究表明,仅采用 43 个程序且没有超参数微调即可获得 90 的平衡精度,与当前最先进的技术水平相当。 |
| Dictionary Attack on IMU-based Gait Authentication Authors Rajesh Kumar, Can Isik, Chilukuri K. Mohan 我们提出了一种新颖的身份验证系统对抗模型,该模型使用智能手机内置的惯性测量单元 IMU 记录的步态模式。该攻击思想的灵感来自于对知识 PIN 或基于密码的身份验证系统的字典攻击概念,并以此概念命名。特别是,这项工作研究了是否可以建立一个 IMUGait 模式字典并用它来发起攻击或找到一个可以主动重现与目标 IMUGait 模式相匹配的 IMUGait 模式的模仿者。九名身体和人口统计不同的人以四种预定义的可控和适应性步态因素速度、步长、步宽和大腿抬起的不同水平行走,产生 178 种独特的 IMUGait 模式。每种模式都会攻击多种用户身份验证模型。 |
| PIE: Simulating Disease Progression via Progressive Image Editing Authors Kaizhao Liang, Xu Cao, Kuei Da Liao, Tianren Gao, Zhengyu Chen, Tejas Nama 疾病进展模拟是一个重要的研究领域,对临床诊断、预后和治疗具有重要意义。该领域的一个主要挑战是缺乏对个体患者长期的连续医学成像监测。为了解决这个问题,我们开发了一种名为“渐进式图像编辑 PIE”的新颖框架,该框架能够控制疾病相关图像特征的操作,从而促进精确而真实的疾病进展模拟。具体来说,我们利用文本到图像生成模型的最新进展来准确模拟疾病进展并为每位患者提供个性化治疗。我们从理论上将框架中的迭代细化过程分析为具有指数衰减学习率的梯度下降。为了验证我们的框架,我们在三个医学成像领域进行了实验。我们的结果证明了 PIE 相对于现有方法(例如基于 CLIP 分数真实性和疾病分类置信度对齐的稳定扩散游走和基于样式的流形外推法)的优越性。我们的用户研究收集了 35 名资深医生的反馈,以评估所产生的进展。值得注意的是,76.2 的反馈与生成的进程的保真度一致。据我们所知,PIE 是同类中第一个生成符合现实世界标准的疾病进展图像的。 |
| ContextRef: Evaluating Referenceless Metrics For Image Description Generation Authors Elisa Kreiss, Eric Zelikman, Christopher Potts, Nick Haber 无参考指标,例如 CLIPScore 使用预训练的视觉语言模型来直接评估图像描述,而无需昂贵的真实参考文本。这些方法可以促进快速进展,但前提是它们真正符合人类的偏好判断。在本文中,我们介绍了 ContextRef,这是用于评估此类对齐的无参考指标的基准。 ContextRef 有两个组成部分,即沿着各种已建立的质量维度进行的人工评级,以及旨在发现根本弱点的十种不同的稳健性检查。 ContextRef 的一个重要方面是图像和描述是在上下文中呈现的,这反映了先前的工作表明上下文对于描述质量很重要。使用 ContextRef,我们评估各种预训练模型、评分函数和合并上下文的技术。这些方法对于 ContextRef 都没有成功,但我们表明,仔细的微调可以带来实质性的改进。 |
| Meta OOD Learning for Continuously Adaptive OOD Detection Authors Xinheng Wu, Jie Lu, Zhen Fang, Guangquan Zhang 分布外 OOD 检测对于现代深度学习应用至关重要,它可以识别不应测试或不应用于进行预测的 OOD 样本并发出警报。当前的 OOD 检测方法在从静态分布中抽取分布 ID 和 OOD 样本时取得了重大进展。然而,当应用于现实世界的系统时,这可能是不现实的,因为现实世界的系统经常会随着时间的推移,ID 和 OOD 分布不断变化和变化。因此,为了在现实系统中有效应用,开发能够适应这些动态和不断变化的分布的 OOD 检测方法至关重要。在本文中,我们提出了一种新颖且更现实的设置,称为连续自适应分布外 CAOOD 检测,其目标是开发 OOD 检测模型,该模型能够在部署期间 ID 样本不足的情况下动态快速地适应新到达的分布。为了解决 CAOOD,我们通过设计学习适应图来开发元 OOD 学习 MOL,以便在训练过程中学习良好的初始化 OOD 检测模型。在测试过程中,MOL 通过快速适应新的发行版并进行一些调整,确保了在变化的发行版上的 OOD 检测性能。 |
| When is a Foundation Model a Foundation Model Authors Saghir Alfasly, Peyman Nejat, Sobhan Hemati, Jibran Khan, Isaiah Lahr, Areej Alsaafin, Abubakr Shafique, Nneka Comfere, Dennis Murphree, Chady Meroueh, Saba Yasir, Aaron Mangold, Lisa Boardman, Vijay Shah, Joaquin J. Garcia, H.R. Tizhoosh 最近,一些研究报告了利用来自 Twitter 和 PubMed 等在线数据源的图像,对医学领域图像文本建模的基础模型进行微调。基础模型是大型、深层的人工神经网络,能够通过对极其广泛的数据集进行训练来学习特定领域的上下文。 |
| Cross-scale Multi-instance Learning for Pathological Image Diagnosis Authors Ruining Deng, Can Cui, Lucas W. Remedios, Shunxing Bao, R. Michael Womick, Sophie Chiron, Jia Li, Joseph T. Roland, Ken S. Lau, Qi Liu, Keith T. Wilson, Yaohong Wang, Lori A. Coburn, Bennett A. Landman, Yuankai Huo 分析跨多个尺度的信息的高分辨率全幻灯片图像 WSI 对数字病理学提出了重大挑战。多实例学习 MIL 是通过对对象包(即较小图像块集)进行分类来处理高分辨率图像的常见解决方案。然而,这种处理通常在单一尺度(例如 WSI 的 20 倍放大)下执行,而忽略了对人类病理学家诊断至关重要的重要尺度间信息。在本研究中,我们提出了一种新颖的跨尺度 MIL 算法,将尺度间关系明确聚合到单个 MIL 网络中,用于病理图像诊断。本文的贡献有三个方面 1 提出了一种新颖的跨尺度 MIL CS MIL 算法,该算法集成了多尺度信息和尺度间关系 2 创建并发布了具有尺度特定形态特征的玩具数据集,以检查和可视化差异跨尺度注意 3 我们简单的跨规模 MIL 策略证明了内部和公共数据集的卓越性能。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com