今天介绍darknet识别文字点选验证码, Darknet is an open source neural network framework written in C and CUDA. darknet是基于yolo算法的神经网络框架。
废话少说先热热身
平台是Ubuntu20,首先要安装NVIDIA驱动
1、安装驱动
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA 找见对应的驱动下载安装
2、安装cuda
查看版本兼容 CUDA Compatibility :: NVIDIA Data Center GPU Driver Documentation
下载 CUDA Toolkit Archive | NVIDIA Developer
Ubuntu 通过deb(local)方式安装
3、安装cudnn
下载对应版本 CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
4、安装完成后(测试是否成功)
~$ nvidia-smi Wed Sep 16 13:57:38 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 208... On | 00000000:08:00.0 Off | N/A | | 45% 34C P8 4W / 215W | 1721MiB / 7973MiB | 0% Default | +-------------------------------+----------------------+----------------------+
接下来安装darknet
1、安装
wget https://github.com/pjreddie/darknet/archive/master.zip unzip master.zip# 修改Makefile(GPU和 CUDNN改成1,默认是0)vim darknet-master/MakefileGPU=1CUDNN=1# 保存退出,然后编译make
2、测试
下载官方的权重文件
wget https://pjreddie.com/media/files/yolov3-tiny.weights
识别
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
结果:能识别出来并标记位置,这很符合我们想要的结果
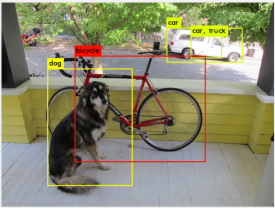
分类
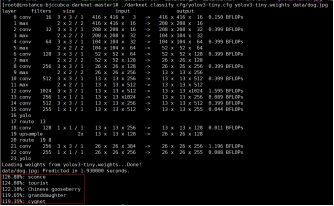
./darknet classify cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
结果:
热身完了,现在开始训练自己的模型
以某验文字点选验证码为例,先看看样本,我们要做的就是按照左下角小字的顺序,点击图片上的文字验证。

先说说思路(只说大字,小字的类似):
1、搜集足够的样本数据
2、标注字的位置
3、训练定位器
4、识别字的位置,并切割
5、标注字的类别
6、训练分类器
一、准备数据
定位器需要标注大概 1000张左右就可以了
分类器需要标注大概 36W 张(越多越好,鲁迅说过大力出奇迹 ( •̀ .̫ •́ )✧)
二、标注位置
标注工具有很多,我用的是labelImg-1.8.1
1)、安装(配置过程按照教程)
https://github.com/tzutalin/labelImg/archive/master.zip
2)、配置好之后打开,开始标注

a、选择yolo模式
b、定位器只设定一个类,使用默认标签名word(标签名可以任意取)
c、开始标注
d、标注图片中所有的字,可以看出图上有4个汉字(只关注大字)
e、可以看到标注完后有4个结果
f、然后保存
g、点击下一个继续标注
3)、标注结果文件
标注完后,在图片所在的目录生成了结果文件,与图片命名相同。

标注文件里有4行数据,对应4个字,以第一行为例
1 表示标签文件的第一个(从0开始)0.129360 位置的中心x坐标0.200521 位置的中心y坐标0.252907 相对宽度w0.208333 相对高度h
三、标注完后开始训练预处理
a、/home/data目录下,创建训练集 测试集目录
mkdir train
mkdir test
b、将标注好的数据以9:1的比率分别放入train和test目录,制作训练文件
find `pwd`/train -name \*.jpg > train.listfind `pwd`/test -name \*.jpg > test.listtrain.list内容,就是标注后的图片绝对路径/home/data/train/0.jpg/home/data/train/1.jpg/home/data/train/2.jpg/home/data/train/3.jpg/home/data/train/4.jpg/home/data/train/5.jpg
c、模型配置文件,定位使用yolov3-tiny.cfg就足够
/home/data/word.cfg
*、蓝色可以改[net]batch=1 # 测试时1,训练时根据显存大小设置64 32 16subdivisions=1 # 测试时1,训练时根据batch 配置 16 8 4 2width=416 # 网络输入宽度,取默认值height=416 # 网络输入高度,取默认值channels=3 # 网络输入通道数momentum=0.9decay=0.0005 # 防止过拟合angle=0 # 旋转角度,增强样本量saturation = 1.5 # 饱和度exposure = 1.5 # 曝光量hue=.1learning_rate=0.001 # 学习率burn_in=1000max_batches = 500200 # 最大训练次数policy=steps # 学习策略steps=400000,450000scales=.1,.1*、红色必须改[convolutional]size=1stride=1pad=1filters=18# 值为3*(classes + 5) activation=linear[yolo]mask = 0,1,2anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319classes=1 #数据集类别(定位器只有1类)num=6jitter=.3ignore_thresh = .7truth_thresh = 1random=1
d、标签文件
/home/data/word.labels
文件中每一行都表示一个标签

e、数据集配置文件
/home/data/word.dataclasses = 1 # 类别个数train = /home/data/train.list # 训练集文件位置valid = /home/data/test.list # 测试集文件位置labels = /home/data/word.labels # 标签位置backup = backup/word # 结果保存位置top=5 # 表示输出前5个结果
f、开始训练
1、最后目录结构
/home/data├── test # 测试集目录├── test.list # 测试集文件├── train # 训练集目录├── train.list # 训练集文件├── word.cfg # 模型配置文件├── word.data # 数据集配置文件└── word.labels # 标签文件
2、准备好之后就开始训练
./darknet detector train /home/data/word.data /home/data/word.cfg
3、开始打印日志:

第1部分:
Region 16 Avg IOU 表示当前subdivision 内图片的评价IOU数字越大表明 精度越高Class 标注物体的正确率Obj 目标越接近1越好No Obj 趋于0.5R 当前模型在所有 subdivision 样本中检测出的正样本与实际正样本的比值count所有当前 subdivision 图片中包含正样本标签数量
第2部分:
434483 当前迭代次数 0.008373 总体损失(损失很小的时候就可以停止训练)0.008263 avg 平均损失0.000100 rate 当前学习率0.093013 seconds 当前批次花费时间6951728 images 参与训练的图片总数
4、检测结果
如果显存足够大,训练过程会很快,训练完成开始检测,可以看到成功识别出4个汉字(大字)的位置并标注
./darknet detect /home/data/word.cfg /home/data/word.weights 0.jpg

四、识别位置并切割
darknet中python目录darknet.py
# 修改点# so文件路径 lib = CDLL("libdarknet.so", RTLD_GLOBAL)# 配置文件和模型路径net = load_net("/home/data/result/word.cfg", "/home/data/result/word.weights", 0)meta = load_meta("/home/data/result/word.data")# 调用识别函数后返回类别和坐标(b'0', 0.9999345541000366, (89.49639129638672, 259.5166320800781, 78.38817596435547, 58.78640365600586))b'0' 类别0.9999345541000366 识别率89.49639129638672 位置中心x坐标259.5166320800781 位置中心y坐标78.38817596435547 相对宽度w58.78640365600586 相对高度h# 根据x y w h可以计算出位置的四边的边界位置左 left = x - (w / 2)右 right = x + (w / 2)上 top = y - (h / 2)下 bottom = y + (h / 2)
切割完后

五、标注类别
将所有数据集分割后,开始标注类别,可以借助百度识别,但是效率不高。我们考虑半监督学习,自行标注一部分,然后训练,再根据训练结果识别,然后再重复之前的操作。
标注完后大概有4277个类 也就是4277个汉字。

六、训练分类器
前两步和定位器一样
c、模型配置文件,分类器参考darknet19.cfg
/home/data/class.cfg
*、蓝色可以改[net]batch=1 # 测试时1,训练时根据显存大小设置64 32 16subdivisions=1 # 测试时1,训练时根据batch 配置 16 8 4 2learning_rate=0.001 # 学习率max_batches = 500200 # 最大训练次数policy=poly # 学习策略angle=7 # 旋转样本*、红色必须改[convolutional]filters=4277 # 总共有多少类size=1stride=1pad=1activation=linear[avgpool][softmax]groups=1
d、标签文件
/home/data/class.labels
文件中每一行都表示一个标签(所以共有4277行)

e、数据集配置文件
/home/data/class.data
classes = 4277 # 类别个数train = /home/data/train.list # 训练集文件位置valid = /home/data/test.list # 测试集文件位置labels = /home/data/class.labels # 标签位置backup = backup/class # 结果保存位置top=5 # 表示输出前5个结果
f、开始训练
1、训练
./darknet classifier train /home/data/class.data /home/data/class.cfg
2、日志

3、训练完成后检测结果
./darknet classifier predict /home/data/class.data /home/data/class.cfg /home/data/class.weights code0.jpg



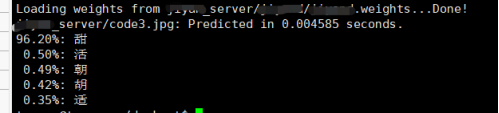
可以看出四个字全部识别出来了,识别率还是很高的,好了任务完成~~
(本文只用于学习交流,如涉及作品内容、版权或其它问题,请及时与我们联系,我们将立即更正或删除相关内容。)

![[De1CTF 2019]SSRF Me | BUUCTF](https://img-blog.csdnimg.cn/73425d04c4794a7d94d39103aff9a194.png)