目录
摘要
文献阅读1
1、标题和提出问题
2、物理模型对于水质预测的缺陷
3、模型框架
4、相关公式
5、结果分析
文献阅读2
1、标题和提出问题
2、问题叙述
3、模型框架
4、误差修补
5、实验结果和分析
总结
摘要
本周阅读了2篇论文,分别为一种基于深度学习和特征提取方法的非点源污染水质预测模型,一种基于高斯扩散的大气环境质量数据深度学习修复方法研究。总得来说,第一篇文章的核心为提取空间特征、降维、预测。第二篇为根据物理模型算出来的数据误差,依据这些数据误差通过神经网络对数据进行修补。之后将修补后的数据用于长序列缺失的大气环境数据中。实验证明这两篇论文所提出来的效果都十分优秀,为解决水质预测和数据修复提供了一种全新的方法。
This week, 2 papers are read。One is a non point source pollution water quality prediction model based on deep learning and feature extraction methods,the other is research on Deep Learning Restoration Method for Atmospheric Environmental Quality Data Based on Gaussian Diffusion.Overall,The core of the first article is to extract spatial features, reduce dimensionality, and predict.The second part is about data errors calculated based on physical models, which are then repaired using neural networks.Afterwards, the repaired data will be used in the long sequence missing atmospheric environment data.The experiments have shown that the results proposed in these two papers are excellent, providing a new method for solving water quality prediction and data restoration.
文献阅读1
1、标题和提出问题
标题:一种基于深度学习和特征提取方法的非点源污染水质预测模型
提出问题:大气环境监测数据越来越多地应用于大气污染物运输和扩散的研究。许多城市已建立了空气质量自动在线监测站。然而,部分监测站由于日常设备维护和极端天气等原因,出现数据缺失和偏差,影响了区域空气质量大数据的构建,准确预测当地空气质量,研究空气污染机制等等。因此,准确预测PM2.5浓度需要修复长序列缺失数据,充分利用空气质量数据。
非点源污染:指不来自单一源头或特定点的污染源的排放,而是来自分散的、多源的、广泛分布的污染源,通常无法明确追踪到特定的排放点。这种类型的污染通常涉及到雨水、雪水、地表径流等流动性的水,这些水体在流经不同区域时携带着污染物,最终将其释放到河流、湖泊、海洋或地下水系统中。
特点:分散性源头、难以定位、多种污染物、与气象条件相关
2、物理模型对于水质预测的缺陷
-
复杂性和简化假设: 自然界的水质系统通常非常复杂,包括多种物理、化学和生态过程的相互作用。物理模型通常需要进行简化和假设,以便进行数学建模。这些简化假设可能无法完全捕捉实际系统的复杂性,从而导致模型的不准确性。
-
参数估计问题: 物理模型通常需要许多参数来描述系统的性质,如水体的流速、污染物的扩散系数等。估计这些参数通常是一个挑战,因为它们可能难以准确测量或估计。
-
数据需求: 物理模型需要大量的数据来初始化和验证模型。这些数据包括地形、气象、水质和水文数据等。如果数据不足或质量不佳,模型的预测能力将受到限制。
-
计算复杂性: 物理模型通常需要进行复杂的数值模拟,包括求解偏微分方程等。这可能需要大量的计算资源和时间,特别是在大规模或高分辨率的水质模拟中。
-
模型不确定性: 物理模型中存在许多不确定性,如参数估计误差、模型结构不确定性等。这些不确定性可能会传播到模型的预测中,使得预测结果不确定。
-
适应性和灵活性: 物理模型通常较难适应不同地区或不同时间尺度的水质预测。在新的环境或情境下,需要进行模型参数的重新调整和模型结构的修改。
-
局部性: 物理模型往往具有较强的局部性,即模型在一定条件下的适用性受到限制。在不同条件下,模型的性能可能会下降。
-
数据缺失: 当有关水质的数据缺失或不完整时,物理模型的预测能力可能受到严重影响,因为它们通常需要准确的输入数据。
3、模型框架
组成部分:SOD模块、VGG模块和LSTM模块耦合的混合深度学习模型 。
包括数据采集部分、VGG 特征提取部分、污染物输运扩散模拟部分、误差修正部分和结果分析部分。首先,采集研究数据,包括空间信息、水文气象参数和污染物参数,并进行预处理;其次,采用 VGG 模型提取流域空间特征,生成具有空间特征的多维时间序列数据;再次,研究了水质监测站的空间相关性,建立了多水源水扩散模型。利用模拟结果与观测结果的差异构建误差序列。第四,建立了一种混合深度学习模型来预测 NPS污染引起的水质变化。最后,以均方根误差(RMSE)、平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE)作为评价参数,通过实验对模型参数进行优化。通过与最先进的预测模型的比较,验证了所提出模型的准确性。
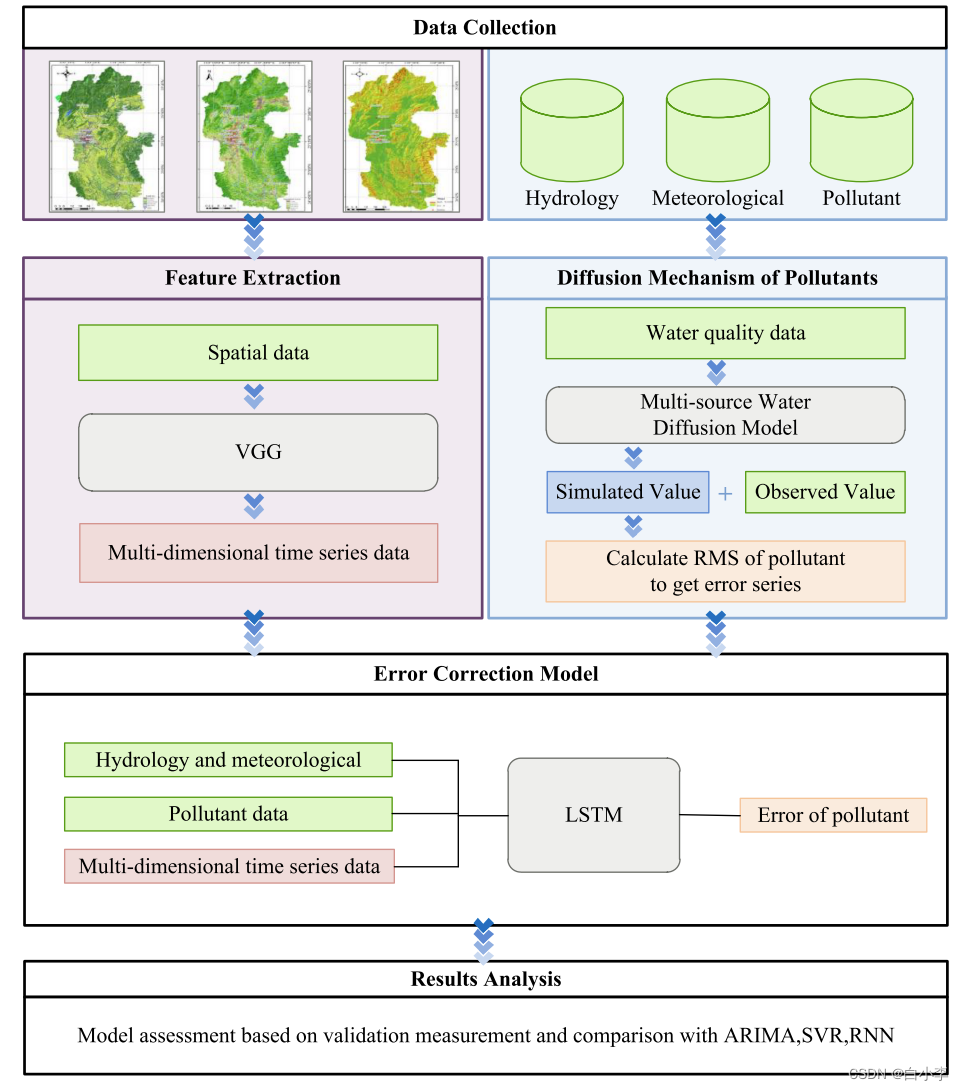
输入输出集构建:首先,从网络中收集了遥感数据,包括土地利用、植被、坡度等。其次,将空间特征的图像转换为224×224×3的图像格式,然后采用VGG模型提取特征。最后,得到了空间图像的时间序列高维特征。为了消除高维冗余特征对噪声的影响,采用主成分分析方法对高维特征进行降维,获得多维空间特征时间序列数据。将这些数据与水文气象数据、污染物数据和目标污染物误差相结合,可以构建混合深度学习模型的输入和输出数据集。
4、相关公式
模型主要由水平衡方程驱动,可表示为:

输入矩阵:

目标序列:
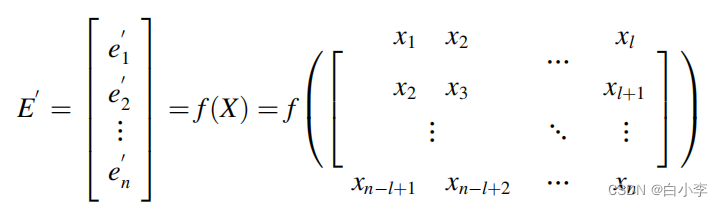
输入输出方程定义:

5、结果分析
采用视觉几何组方法提取输入遥感图像的空间特征并降维。这样,高维数据就可以被表征为多维空间特征时间序列数据,作为图像数据的特征表达向量。利用2018年1月、2018年7月和2019年1月的遥感数据,证明了本部分所建立的VGG模型的有效性。降维前后的数据如下图所示:

经过降维后,可以提取遥感图像的空间特征,并对提取的数据进行分离,这大大降低了由计算和由冗余信息引起的识别误差。更重要的是,通过降维,可以将复杂的遥感图像转化为简单的多维向量,可以直接与深度学习方法相结合,实现考虑空间特征的水质预测。
传统的深度学习方法受到历史数据的限制,无法有效预测极值,而物理模型可以确保预测在可控范围内。为了评估所提出模型对极值的预测性能:
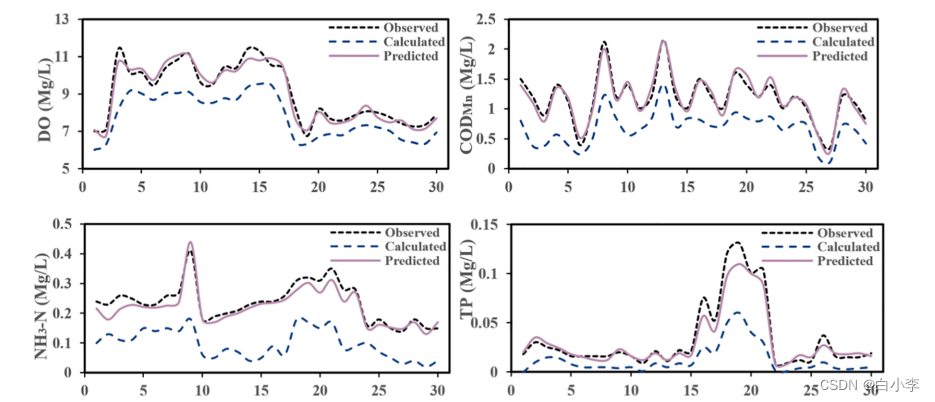
预测值与实测值的最大相对误差分别为 6.07%、11.6%、22.1%和 23.9%。显然,所建立的 SOD- VGG-LSTM 模型在预测日尺度极值时,耦合机理模型后取得了较好的预测精度。
消融实验:

不考虑空间特征的 LSTM模型的预测精度低于 SOD-VGG-LSTM模型。
文献阅读2
1、标题和提出问题
标题:一种基于高斯扩散的大气环境质量数据深度学习修复方法研究
提出问题:在大气污染物传输和扩散的研究领域,大气环境监测数据越来越多地应用被应用。目前,大量的大气质量自动在线监测站被建设在重点城市。但是,数据偏离或缺失的问题常出现,受影响于设备日常维护和极端气象,在数十乃至上百个站点的自动连续在线监测过程中。构建区域大气质量大数据、准确预测当地大气质量和研究大气污染机理,受这个现象影响较大。因此,开展大气质量连续监测数据的清洗与修复技术研究,已具备了实用和学术价值。
2、问题叙述
采用深度学习模拟大气污染物传输的前提条件,是明确污染物受哪些因素影响,其物理规律如何表示。城市下垫面的地形与地面建筑物,会影响了大气污染物的传输扩散。除此之外,PM2.5的形成原因不仅与温度、湿度、气压等气象要素有关,也与CO、SO2等污染物因子有关。这些影响因素通常与PM2.5浓度具有非线性的相关性。如果使用传统的高斯扩散模型,不足以描述区域污染物的时空动态变化特性和有效地预测污染物浓度
气象数据和污染物数据是典型的时间序列数据,而循环神经网络由于其记忆功能,能够结合历史信息对未来时刻的信息进行预测,通过历史的污染物数据,捕捉数据特征,获取污染物浓度变化规律,在预测PM2.5浓度方面具有非常大的优势。为此,通过高斯扩散模型模拟污染物扩散的同时,结合深度学习方法挖掘时序数据中内在的规律,更好地表示污染物扩散过程,从而达到数据修复的目的。
3、模型框架
组成部分:数据采集、高斯模拟、错误修正、结果分析和应用验证等五个部分。首先,研究数据从桂林市监测站中采集,接着是通过污染扩散过程设计的多点高斯扩散模型,然后是使用GRU的PM2.5预测模型。在第四部分中,以MAE、RMSE和SMAPE作为评估参数,通过实验进行参数优化,并通过模型对比进行效果验证。最后,将该方法应用于目标站点的长序列缺失数据填充。

结合风向对PM2.5污染扩散的分析,将目标站点上风向的站点简化视为PM2.5的发生地。对这些源强点建立高斯扩散模型,通过模拟PM2.5的扩散过程对目标站点的PM2.5进行预测。高斯扩散模型如下所示:
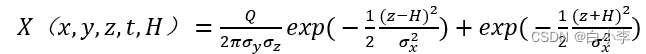
将计算所得的目标站点每个小时的PM2.5预测值与实际的PM2.5浓度值作均方根误差,得到关于目标站点PM2.5的误差时间序列。均方根误差计算方法:

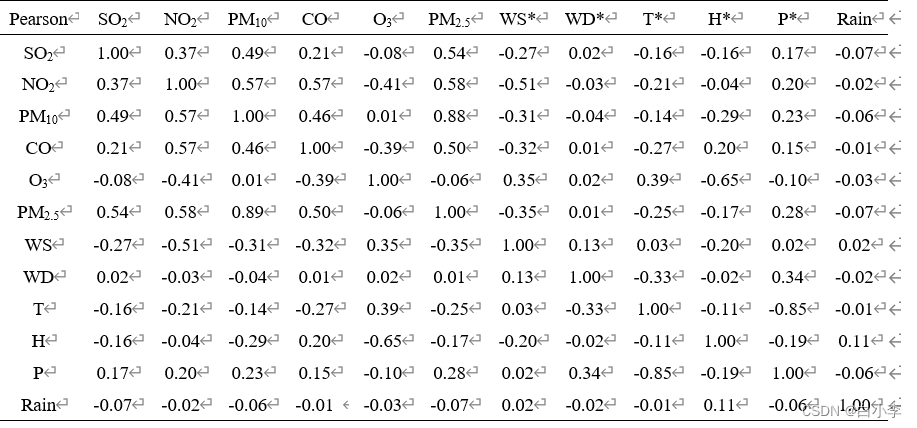
从下表可以看出,SO2、NO2、PM10、CO和气压与PM2.5呈正相关,O3、风速、风向、气温、湿度和雨量与PM2.5呈负相关。各气象变量之间存在较弱的相关性,说明气象变量之间不存在信息重复,可以直接作为预测模型的输入。
4、误差修补
误差修正模型预测的目标是利用过去几个小时的PM2.5误差、气象指标和污染物指标(固定预测窗口l)预测下1个小时的PM2.5误差。为了实现这一目标,使用滚动预测方案。在该方案中,首先利用预测窗口中的所有指标来预测下1个小时的PM2.5误差。然后,将时间窗口整体移动1个小时,其中包含了新预测的误差数据,将其作为预测误差的最新元素。重复这个过程,直到所有待修复数据的PM2.5误差预测完毕。
输入矩阵:

目标序列:

空气质量与其历史价值具有时间相关性。一方面,空气质量可以根据过去几个小时的数值来推断。另一方面,空气质量与值之间存在较长的历史相关性,是具有一定周期规律的时间序列。为了研究空气污染的时间依赖性,设计了一个全连接的深度GRU网络作为时间预测器。模型结构如图5所示,由两个GRU层和两个回归层构成误差修正模型。前两个GRU层由GRU神经元组成,用于探索长期的时间依赖关系。剩余层由用回归神经元组成,利用前几层计算的时间变化,给出PM2.5误差的最终时间预测。模型的输入和输出为持续的时间序列。GRU网络在捕获长时间相关性方面表现突出,可以记住长时间内空气质量的周期模式。
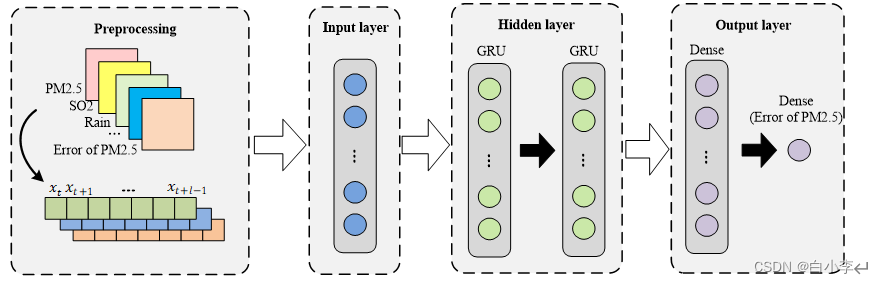
5、实验结果和分析
51站点的PM2.5预测值与实际值如下图所示:

从图中可以看出,模型在整个预测范围内显示出准确的预测性能,即使在污染浓度突然变化的情况也显示出良好的性能。
为了验证高斯扩散与深度学习相结合可以提高对未出现过的突发点的预测精度,取2018年51站点的数据,将大于160视作未出现过的突发点。取一段连续时间的数据作为训练集,离散的被剔除,以确保训练数据中未出现过大于160的数据。
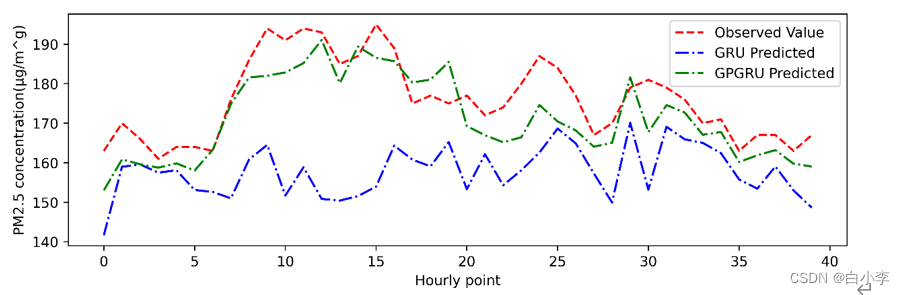
显然,GRU在没有学习类似数据的情况下有更大的误差。高斯扩散模型与GRU具有相似的性能。GD-GRU保证了基于物理定律的预测趋势与实际趋势更一致。
散点图可以推断出模型低估高浓度和高估低浓度的趋势:
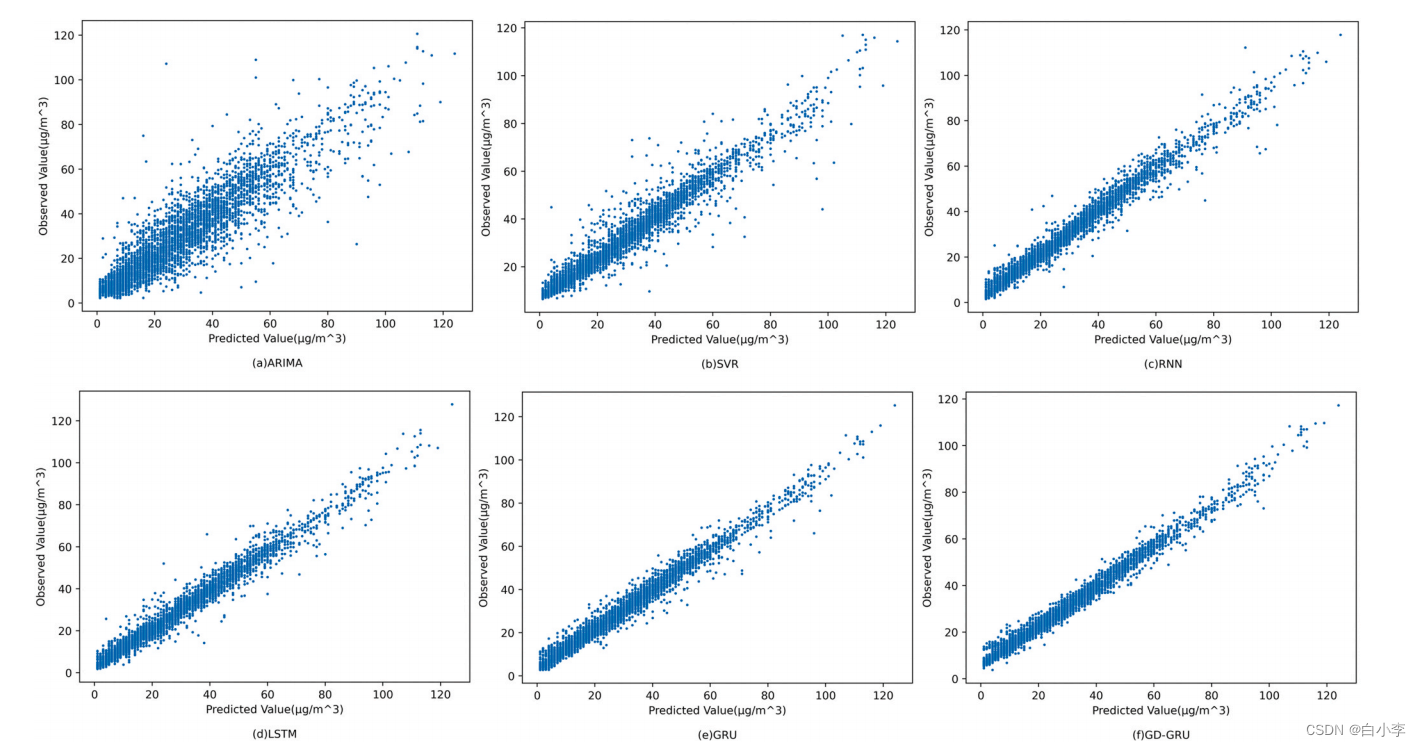
五种方法的预测曲线与观测曲线趋势基本一致,且均具有线性相关关系。传统时序模型和浅层机器学习模型(ARIMA和SVR)的预测值和实际值之间的分布误差相比于其他方法较大。对于深度学习方法,RNN显示出最差的预测效果,在某些极值处的预测产生较大误差。显然,LSTM和GRU有着更好的预测性能。与上述所有模型相比,可以发现所提出模型对污染物的急剧变化更敏感,主要归因于高斯扩散模型能获取更丰富的局部变化信息。
总结
文献1:核心方法便是通过VGG提取特征,获得空间图像的时间序列高维特征,之后对高维特征进行降维,得到多维空间特征时间序列数据,再将这数据与水文气象数据、污染物数据、目标污染物误差相结合,即可构建混合深度学习模型的输入输出数据集。
文献2:核心方法先通过高斯扩散模型对PM2.5进行预测,提去PM2.5的均方根误差作为误差序列,将该误差序列作为参数与其他数据输入到基于GRU神经网络的误差修正模型中。对PM2.5进行数据修正,将修正后的数据应用于长序列缺失的大气环境数据中,证明了修正的准确性。