Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
使用不可靠的伪标签的半监督语义分割
Paper:https://openaccess.thecvf.com/content/CVPR2022/html/Wang_Semi-Supervised_Semantic_Segmentation_Using_Unreliable_Pseudo-Labels_CVPR_2022_paper.html
Code:https://github.com/Haochen-Wang409/U2PL/
Blog:https://haochen-wang409.github.io/U2PL/
Abstract
半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。
常见的做法是选择高度置信的预测作为伪真实值,但这会导致大多数像素由于不可靠而可能未被使用的问题。我们认为每个像素对模型训练都很重要,即使它的预测是模糊的。直观上,不可靠的预测可能会在顶级类别(即具有最高概率的类别)之间混淆,但是,它应该对不属于其余类别的像素充满信心。
因此,这样的像素可以令人信服地被视为那些最不可能的类别的负样本。 基于这一见解,我们开发了一个有效的管道来充分利用未标记的数据。具体来说,我们通过预测熵分离可靠和不可靠的像素,将每个不可靠的像素推送到由负样本组成的按类别队列,并设法使用所有候选像素来训练模型。
考虑到训练的演变,预测变得越来越准确,我们自适应地调整可靠-不可靠分区的阈值。各种基准和训练设置的实验结果证明了我们的方法相对于最先进的替代方案的优越性。
1 Introduction
语义分割是计算机视觉领域的一项基本任务,并且随着深度神经网络的兴起而得到了显着的进步[7,30,36,47]。现有的监督方法依赖于大规模注释数据,而在实践中获取这些数据的成本可能太高。为了缓解这个问题,人们对半监督语义分割进行了许多尝试[1,4,11,17,23,34,44,49],它学习只有少量标记样本和大量未标记样本的模型。在这样的背景下,如何充分利用未标记的数据就变得至关重要。
典型的解决方案是为没有注释的像素分配伪标签。具体来说,给定未标记的图像,现有技术[28,42]借用基于标记数据训练的模型的预测,并使用像素级预测作为 “Ground Truth” 来反过来增强监督模型。为了减轻模型可能遭受不正确的伪标签的确认偏差问题 [2],现有方法建议使用其置信度分数来过滤预测 [43,44,51,52]。换句话说,只有高度置信的预测才被用作伪标签,而模糊的预测则被丢弃。
然而,仅使用可靠预测带来的一个潜在问题是,某些像素可能在整个训练过程中永远不会被学习到。 例如,如果模型不能令人满意地预测某些特定类别(例如 图 1 中的椅子),则很难为此类类别的像素分配准确的伪标签,这可能会导致训练不足且类别不平衡。从这个角度来看,我们认为,为了充分利用未标记的数据,每个像素都应该得到合理利用。
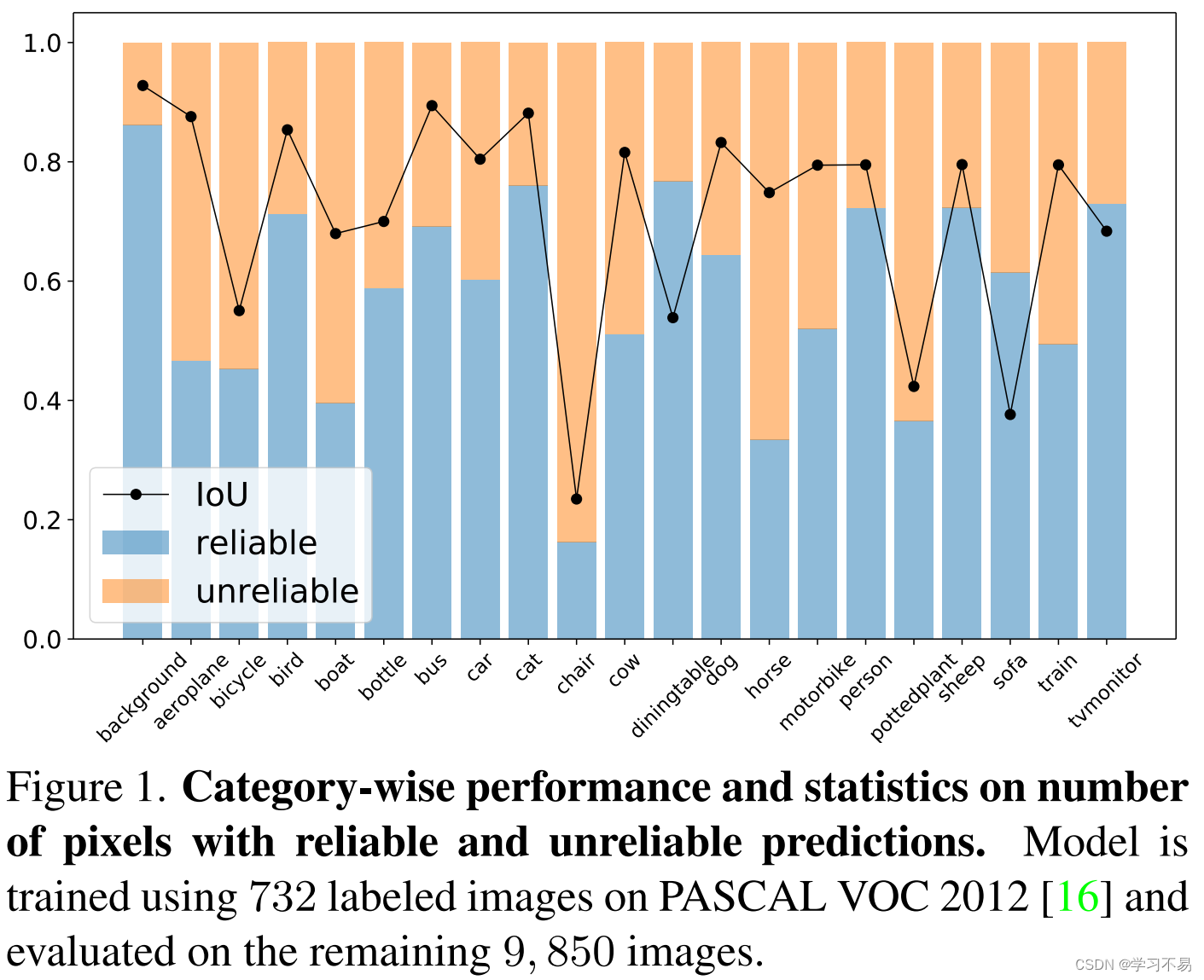
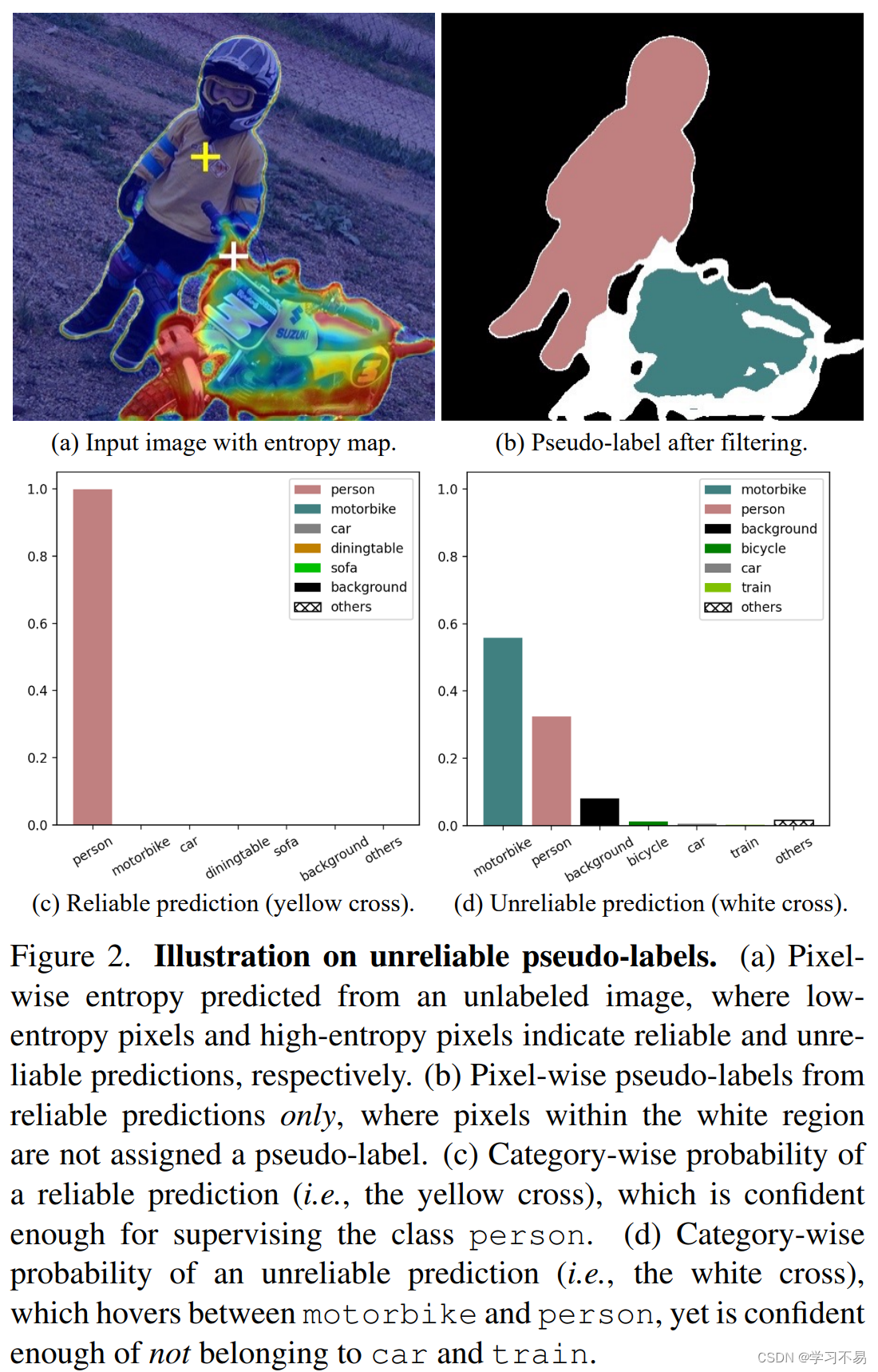
如上所述,直接使用不可靠的预测作为伪标签将导致性能下降[2]。在本文中,我们提出了一种使用不可靠伪标签的替代方法。我们将我们的框架称为 U 2 P L U^2PL U2PL。首先,我们观察到,不可靠的预测通常只会在少数类别而不是所有类别之间产生混淆。以图 2为例,带有白色十字的像素在摩托车和人类上获得相似的概率,但模型非常确定该像素不属于汽车和火车类。基于这一观察,我们重新将令人困惑的像素视为那些不太可能的类别的负样本。 具体来说,在从未标记的图像中获得预测后,我们采用每像素熵作为度量(见图 2)将所有像素分为两组,即可靠组和不可靠组。所有可靠的预测都用于导出正伪标签,而具有不可靠预测的像素则被推入充满负样本的内存库中。为了避免所有负面伪标签仅来自类别的子集,我们为每个类别使用一个队列。这样的设计保证了每个类的负样本数量是平衡的。 同时,考虑到随着模型越来越准确,伪标签的质量也越来越高,我们提出了一种自适应调整可靠和不可靠像素划分阈值的策略。
我们在广泛的训练环境下评估了 PASCAL VOC 2012 [16] 和 Cityscapes [12] 上提出的 U 2 P L U^2PL U2PL,我们的方法超越了最先进的竞争对手。此外,通过可视化分割结果,我们发现由于我们充分使用了不可靠的伪标签,我们的方法在那些模糊区域(例如不同对象之间的边界)上取得了更好的性能。
2 Related Work
半监督学习有两种典型范式:一致性正则化[3,17,34,37,43]和熵最小化[4,18]。最近,一种更直观但有效的框架:自我训练[28],已成为主流。几种方法[17,44,45]利用强大的数据增强,例如基于自训练的CutOut[15]、CutMix[46]和ClassMix[32]。然而,这些方法并没有过多关注语义分割的特征,而我们的方法则关注那些不可靠的像素,这些像素将被大多数基于自训练的方法过滤掉[35,44,45]。
伪标签用于防止在从教师网络生成输入图像的预测时过度拟合不正确的伪标签 [2, 28]。 FixMatch [38]利用置信度阈值来选择可靠的伪标签。 UPS[35]是一种基于FixMatch[38]的方法,考虑了模型不确定性和数据不确定性。然而,在半监督语义分割中,我们的实验表明,将不可靠的像素纳入训练中可以提高性能。
计算机视觉中的模型不确定性主要通过贝叶斯深度学习方法来测量[14,25,31]。在我们的设置中,我们并不关注如何衡量不确定性。我们简单地使用像素概率分布的熵作为度量。
对比学习被许多成功的自监督学习作品所应用[9,10,19]。在语义分割中,对比学习已成为一种有前途的新范式[1,29,41,48,50]。然而,这些方法忽略了半监督分割中常见的假阴性样本,并且不可靠的像素可能在对比损失中被错误地推开。区分不太可能的不可靠像素类别可以解决这个问题。
负学习旨在通过降低负样本的概率来降低错误信息的风险[26,27,35,40],但这些负样本的选择具有很高的置信度。换句话说,这些方法仍然利用具有可靠预测的像素。相比之下,我们建议充分利用那些不可靠的预测来进行学习,而不是过滤掉它们。
3 Method
在本节中,我们以数学方式建立我们的问题,并概述我们在第 2 节中提出的方法。 3.1
首先。我们关于过滤可靠伪标签的策略在第二节中介绍。 3.2.
最后,我们在第二节中描述了如何使用不可靠的伪标签。 3.3.
3.1 Overview
给定一个标记集 D l = { ( x i l , y i l ) } i = 1 N l \mathcal{D}_l = \left\{ (x^l_i,y^l_i) \right\}^{N_l}_{i=1} Dl={(xil,yil)}i=1Nl 和一个更大的未标记集 D u = { x i u } i = 1 N u \mathcal{D}_u = \left\{ x^u_i \right\}^{N_u}_{i=1} Du={xiu}i=1Nu,我们的目标是通过利用大量未标记集来训练语义分割模型数据和较小的一组标记数据。
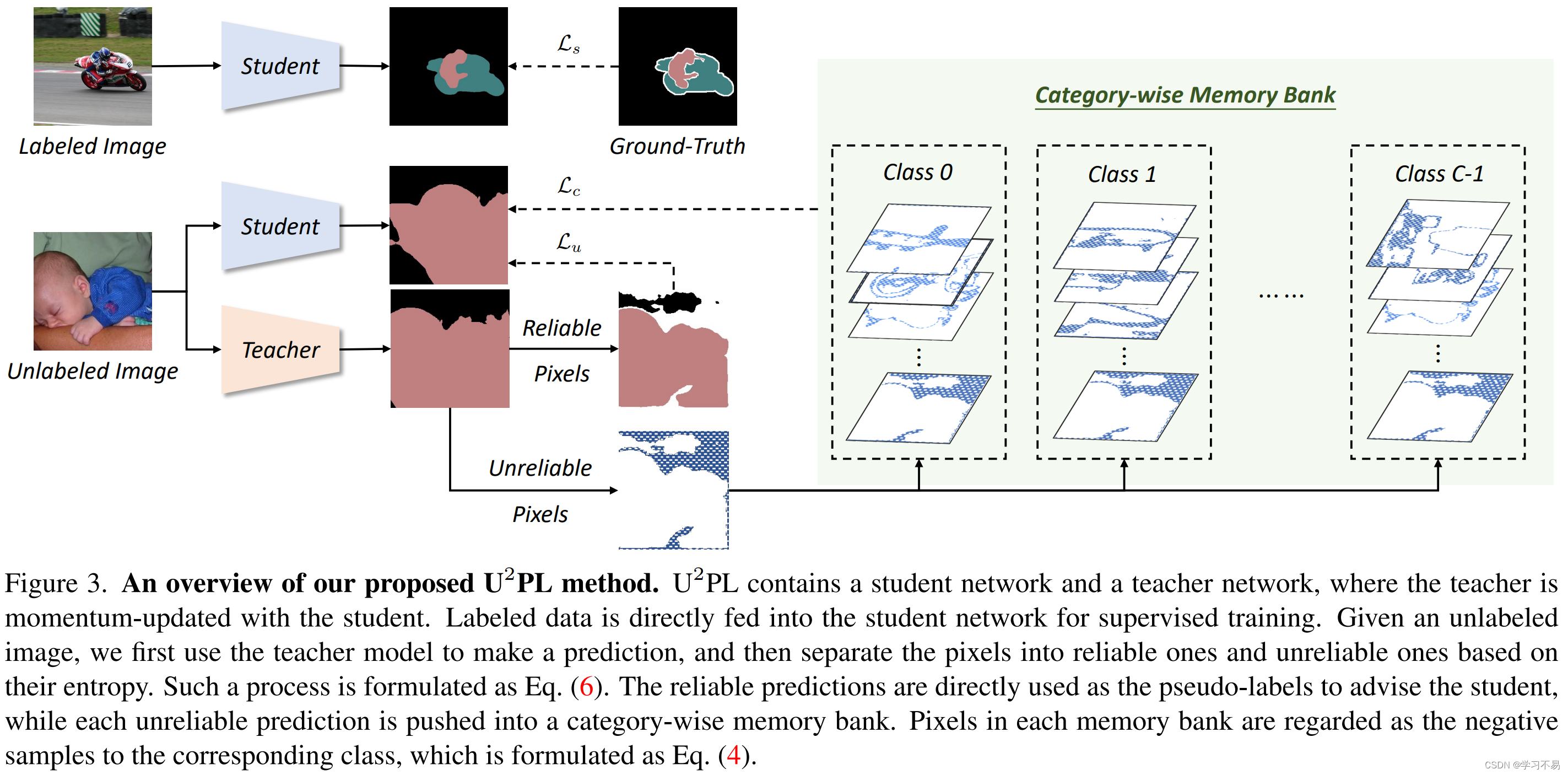
图 3 给出了 U 2 P L U^2PL U2PL 的概述,它遵循典型的自训练框架,具有相同架构的两个模型,分别称为教师和学生。这两个模型仅在更新权重时有所不同。学生模型的权重 θ s \theta_s θs 的更新与通常的做法一致,而教师模型的权重 θ t \theta_t θt 是由学生模型的权重更新的指数移动平均值 (EMA)。每个模型由一个基于 CNN 的编码器 h h h、一个带有分割头 f f f 的解码器和一个表示头 g g g 组成。在每个训练步骤中,我们对 B \mathcal{B} B 个标记图像 B l \mathcal{B}_l Bl 和 B \mathcal{B} B 个未标记图像 B u \mathcal{B}_u Bu 进行同等采样。对于每个标记图像,我们的目标是最小化等式(2)中的标准交叉熵损失。对于每张未标记的图像,我们首先将其带入教师模型并获得预测。然后,基于像素级熵,我们在计算等式(3)中的无监督损失时忽略不可靠的像素级伪标签。这部分内容将在第 3.2 节中详细介绍。最后,我们使用对比损失来充分利用无监督损失中排除的不可靠像素,这将在 Sec.3.3 中介绍。
我们的优化目标是最小化总体损失,可以表示为:
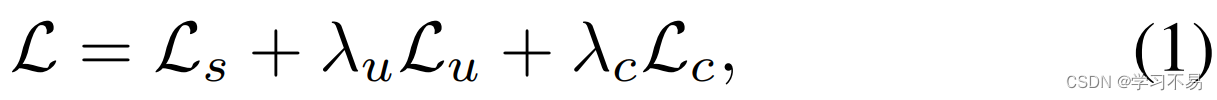
其中 L s \mathcal{L}_s Ls和 L u \mathcal{L}_u Lu分别表示应用于标记图像和未标记图像的监督损失和无监督损失, L u \mathcal{L}_u Lu是充分利用不可靠伪标签的对比损失。 λ u \lambda_u λu 和 λ c \lambda_c λc 分别是无监督损失和对比损失的权重。 L s \mathcal{L}_s Ls 和 L u \mathcal{L}_u Lu 都是交叉熵(CE)损失:
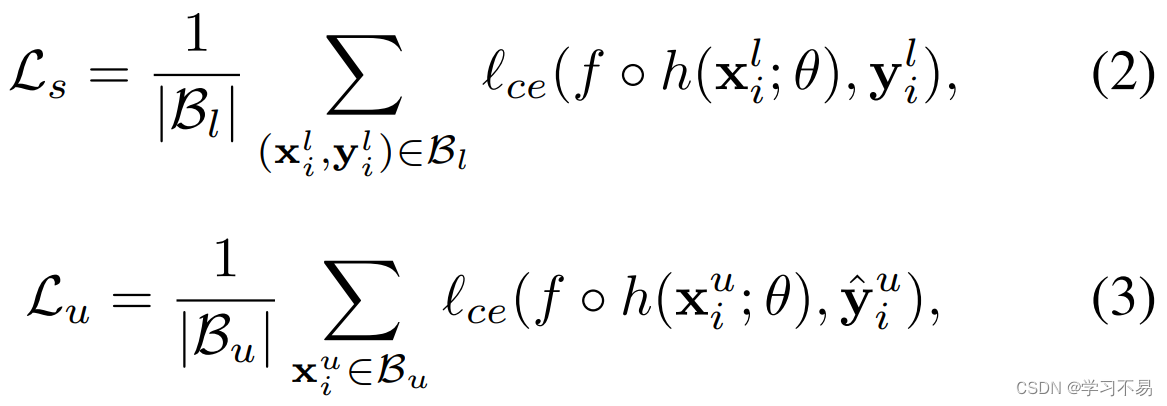
其中 y i l y^l_i yil 表示第 i i i 个标记图像的手工注释掩模标签, y ^ i u \hat{y}^u_i y^iu 是第 i i i 个未标记图像的伪标签。 f ∘ h f \circ h f∘h 是 h h h 和 f f f 的复合函数,这意味着图像首先输入 h h h,然后输入 f f f 以获得分割结果。 L c \mathcal{L}_c Lc 是像素级 InfoNCE [33] 损失,定义为:
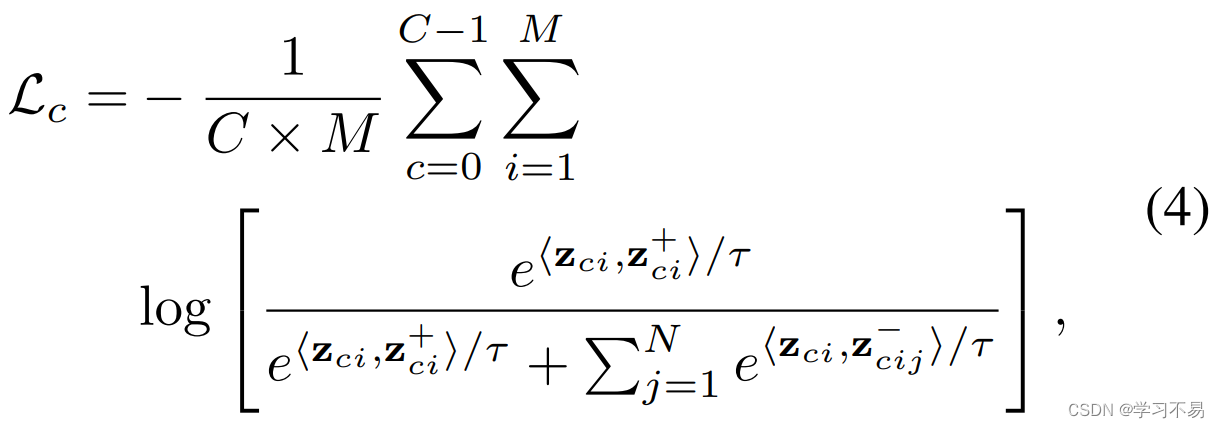
其中 M M M 是锚点像素的总数, z c i z_{ci} zci表示 c c c 类第 i i i 个锚点的表示。每个锚点像素后面跟随一个正样本和 N N N 个负样本,其表示分别为 z c i + z ^+_{ci} zci+ 和 z c i − z ^-_{ci} zci− 。请注意, z = g ∘ h ( x ) z = g \circ h(x) z=g∘h(x),这是表示头的输出。 ⟨ ⋅ , ⋅ ⟩ ⟨·,·⟩ ⟨⋅,⋅⟩ 是两个不同像素的特征之间的余弦相似度,其范围限制在-1到1之间,因此需要温度 τ \tau τ。根据 [29], M M M = 50, N N N = 256, τ \tau τ = 0.5。
3.2 Pseudo-Labeling
为了避免过度拟合不正确的伪标签,我们利用每个像素的概率分布的熵来过滤高质量的伪标签以进行进一步的监督。具体来说,我们将 p i , j ∈ R C p_{i,j} \in \mathbb{R}^C pi,j∈RC 表示为教师模型的分割头针对像素 j j j 处的第 i i i 个未标记图像生成的 softmax 概率,其中 C C C 是类别数。其熵的计算公式为:

其中 p i , j ( c ) p_{i,j}(c) pi,j(c) 是 p i , j p_{i,j} pi,j 在 c c c 个维度上的值。
然后,我们将熵在 α t \alpha_t αt 上的像素定义为训练时期 t t t 的不可靠伪标签。这种不靠谱的伪标签根本不具备监管资格。因此,我们将第 i i i 个未标记图像在像素 j j j 处的伪标签定义为:
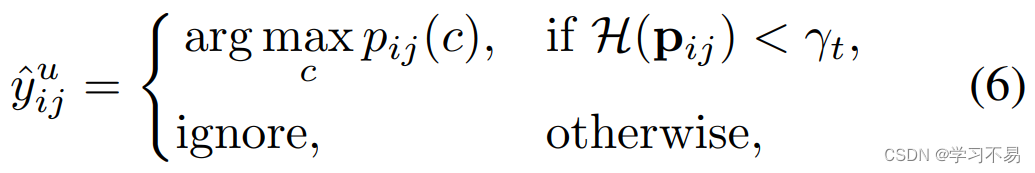
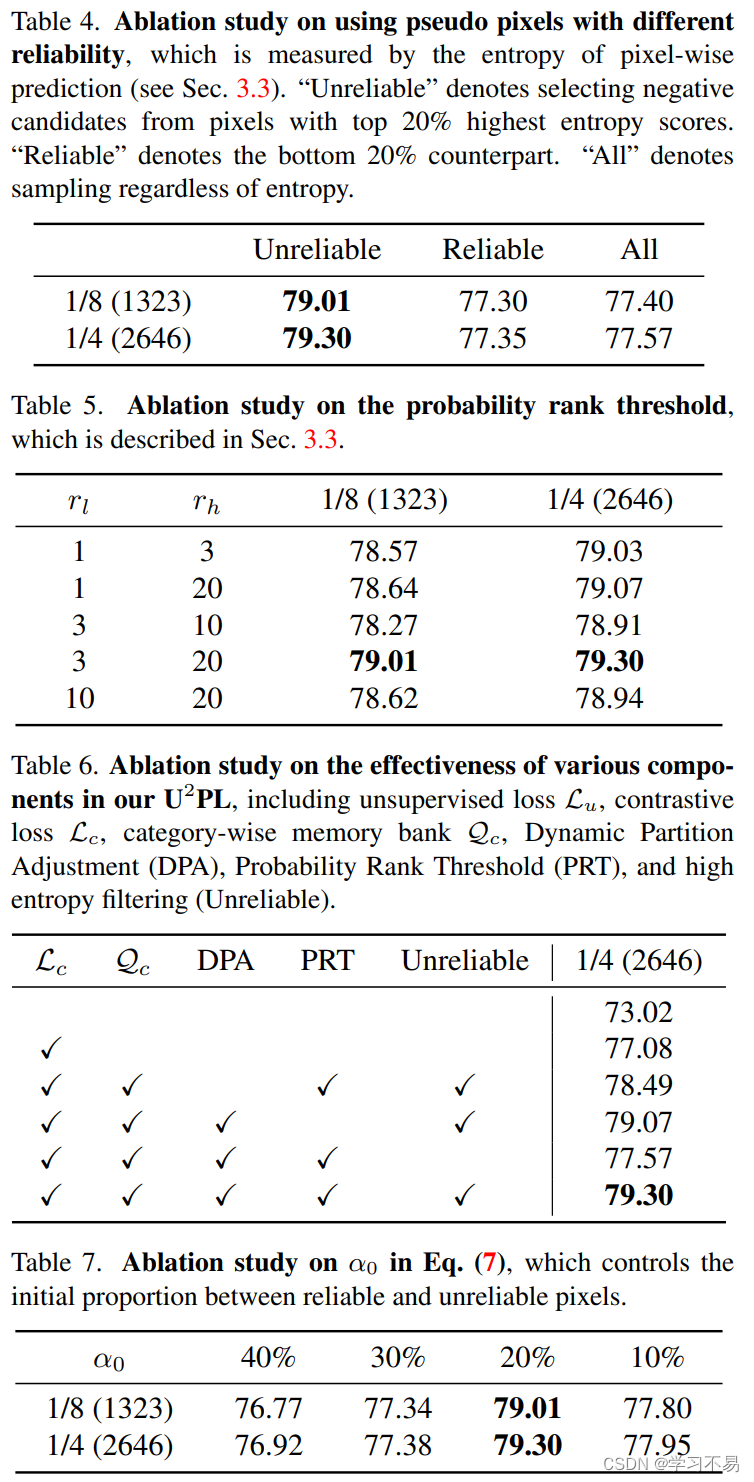
其中 γ t \gamma_t γt 表示第 t t t 个训练步骤的熵阈值。我们将 γ t \gamma_t γt 设置为 α t \alpha_t αt 对应的分位数,以限制具有最高 α t \alpha_t αt 熵的不可靠像素,即 γt=np.percentile(H.flatten(),100*(1-αt)),其中 H H H 是每像素熵图。我们在伪标记过程中采用以下调整策略以获得更好的性能。
动态分区调整。 在训练过程中,伪标签逐渐趋于可靠。基于这种直觉,我们在每个时期用线性策略调整不可靠像素的比例 α t \alpha_t αt:
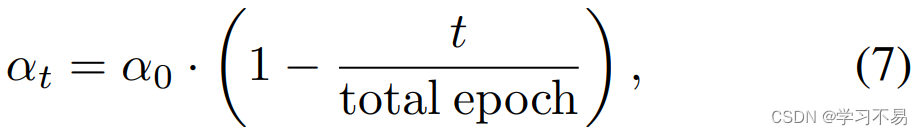
其中 α 0 \alpha_0 α0是初始比例,设置为20%, t t t 是当前的训练周期。
自适应权重调整。 在获得可靠的伪标签后,我们将它们纳入等式(3)中的无监督损失中。该损失的权重 λ u \lambda_u λu 定义为当前小批量中熵小于阈值 γ t \gamma_t γt 的像素百分比乘以基本权重 η \eta η 的倒数:

其中 1 ( ⋅ ) \mathbb{1}(·) 1(⋅) 是指示函数, η \eta η 设置为 1。
3.3 Using Unreliable Pseudo-Labels
在半监督学习任务中,丢弃不可靠的伪标签或减少其权重被广泛用于防止模型性能下降[5,6,38,42,44,51]。我们遵循这种直觉,根据等式(6)过滤掉不可靠的伪标签。
然而,这种对不可靠伪标签的蔑视可能会导致信息丢失。显然,不可靠的伪标签可以提供更好区分的信息。例如,图2中的白色十字就是典型的不可靠像素。它的分布表明模型区分人员类别和摩托车类别的不确定性。然而,这个分布也证明了模型不会将该像素区分为汽车类、火车类、自行车类等的确定性。这种特征为我们提供了提出 U 2 P L U^2PL U2PL 使用不可靠的伪标签进行半监督语义分割的主要见解。
U 2 P L U^2PL U2PL 的目标是利用不可靠的伪标签信息进行更好的区分,这与最近流行的区分表示的对比学习范式不谋而合。但由于半监督语义分割任务中缺乏标记图像,我们的 U 2 P L U^2PL U2PL 建立在更复杂的策略上。 U 2 P L U^2PL U2PL 具有三个组成部分,称为锚像素、正候选像素和负候选像素。这些分量是从某些集合中以采样的方式获得的,以减轻巨大的计算成本。接下来,我们将介绍如何选择: (a) 锚点像素(查询); (b) 每个anchor的正样本; (c) 每个锚点的负样本。
锚点像素。 在训练期间,我们对当前小批量中出现的每个类的锚像素(查询)进行采样。我们将 c c c 类的所有标记候选锚像素的特征集表示为 A c l \mathcal{A}^l_c Acl ,
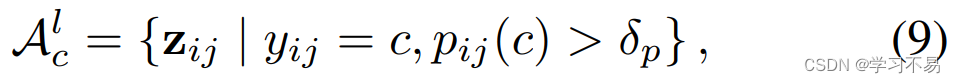
其中 y i j y_{ij} yij 是标记图像 i i i 的第 j j j 个像素的真实值, δ p \delta_p δp 表示特定类别的正阈值,并根据 [29] 设置为 0.3。 z i , j z_{i,j} zi,j 表示标记图像 i i i 的第 j j j 个像素的表示。对于未标记的数据,对应的 A c u \mathcal{A}^u_c Acu 可以计算为:
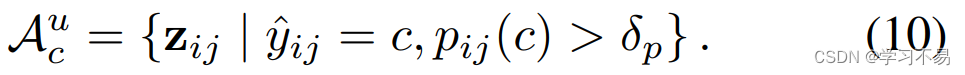
它与 A c l \mathcal{A}^l_c Acl 类似,唯一的区别是我们使用基于方程(6)的伪标签 y ^ i j \hat{y}_{ij} y^ij 而不是手工标注的标签,这意味着合格的锚像素是可靠的,即 H ≤ γ t \mathcal{H} \leq \gamma_t H≤γt。因此,对于 c c c 类,所有合格锚点的集合为:

阳性样本。 对于来自同一类的所有锚点,正样本是相同的。它是所有可能锚点的中心:
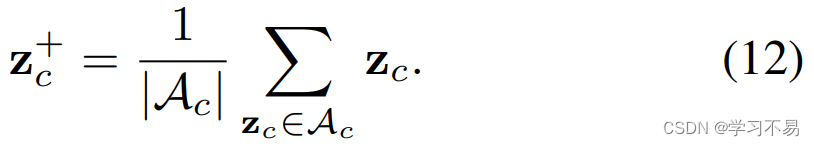
阴性样本。 我们定义一个二元变量 n i j ( c ) n_{ij}(c) nij(c) 来标识图像 i i i 的第 j j j 个像素是否有资格成为 c c c 类负样本。
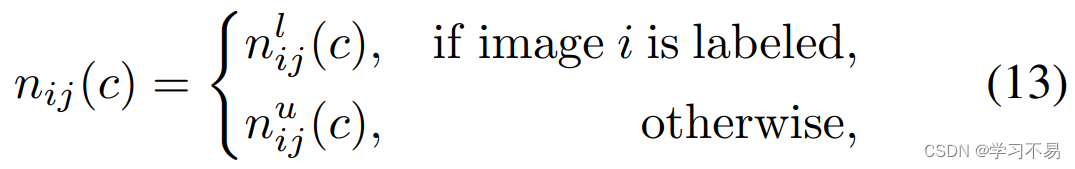
其中 n i j l ( c ) n^l_{ij}(c) nijl(c) 和 n i j u ( c ) n^u_{ij}(c) niju(c) 分别是标记图像 i i i 和未标记图像 i i i 的第 j j j 个像素是否有资格成为 c c c 类负样本的指标。
对于第 i i i 个标记图像, c c c 类的合格负样本应该是: (a) 不属于 c c c 类; (b) 难以区分 c c c 类及其真实类别。因此,我们引入像素级类别顺序 O i j = a r g s o r t ( p i j ) \mathcal{O}_{ij} = argsort(p_{ij}) Oij=argsort(pij)。显然,我们有 O ( a r g m a x p i j ) = 0 \mathcal{O}(argmaxp_{ij}) = 0 O(argmaxpij)=0 和 O ( a r g m i n p i j ) = ( C − 1 ) \mathcal{O}(argminp_{ij}) = (C - 1) O(argminpij)=(C−1)。
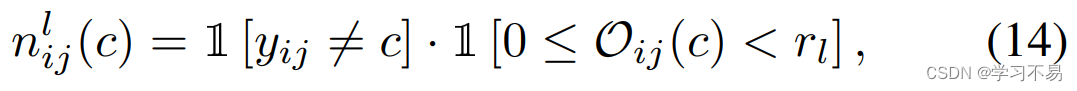
其中 r l r_l rl 是低等级阈值,设置为3。这两个指标分别反映特征(a)和(b)。
对于第 i i i 个未标记图像, c c c 类的合格负样本应该: (a) 不可靠; (b) 可能不属于 c c c 类;(c) 不属于最不可能的类别。类似地,我们也用 O i j \mathcal{O}_{ij} Oij 来定义 n i j u ( c ) n^u_{ij}(c) niju(c):

其中 r h r_h rh 是高等级阈值,设置为20。最后, c c c 类负样本集合为
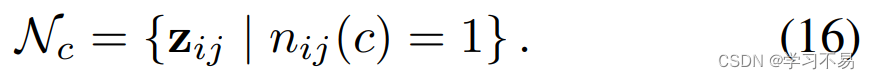
按类别存储库。 由于数据集的长尾现象,某些特定类别的负候选在小批量中极其有限。为了保持稳定的负样本数量,我们使用类别存储体 Q c \mathcal{Q}_c Qc(先进先出队列)来存储 c c c 类的负样本。
最后,使用不可靠伪标签的整个过程如算法1所示。锚点的所有特征都附加到梯度,因此来自学生,而正样本和负样本的特征来自老师。

4 Experiments
4.1 Setup
Dataset. PASCAL VOC 2012 [16] 数据集是一个标准语义分割基准,具有 20 个对象语义类别和 1 个背景类别。训练集和验证集分别包括 1, 464 和 1, 449 张图像。继[11,23,44]之后,我们使用 SBD [20] 作为具有 9、118 个附加训练图像的增强集。由于 SBD [20] 数据集是粗略注释的,PseudoSeg [51] 仅将标准的 1, 464 个图像作为整个标记集,而其他方法 [11, 23] 将所有 10, 582 个图像作为候选标记数据。因此,我们在经典集(1, 464 个候选标记图像)和混合器集(10, 582 个候选标记图像)上评估我们的方法。 Cityscapes [12] 是一个为城市场景理解而设计的数据集,由 2, 975 个带有精细注释掩模的训练图像和 500 个验证图像组成。对于每个数据集,我们在 1/2、1/4、1/8 和 1/16 分区协议下将 U 2 P L U^2PL U2PL 与其他方法进行比较。
Network Structure. 我们使用在 ImageNet [13] 上预训练的 ResNet-101 [21] 作为主干网,使用 DeepLabv3+ [8] 作为解码器。分割头和表示头都由两个 Conv-BN-ReLU 块组成,其中两个块都保留特征图分辨率,第一个块将通道数减半。分割头可以看作是像素级分类器,将ASPP模块输出的512维特征映射到 C C C 类中。表示头将相同的特征映射到 256 维表示空间中。
Evaluation. 遵循以前的方法 [17,23,34,49],图像被中心裁剪为 PASCAL VOC 2012 的固定分辨率。对于城市景观,以前的方法应用滑动窗口评估,我们也是如此。然后我们采用交并集的平均值(mIoU)作为评估这些裁剪图像的指标。所有结果都是在 Cityscapes [12] 和 PASCAL VOC 2012 [16] 的验证集上测量的。消融研究是在 1/4 和 1/8 分区协议下的搅拌机 PASCAL VOC 2012 [16] val 集上进行的。
Implementation Details. 对于搅拌机和经典 PASCAL VOC 2012 数据集的训练,我们使用随机梯度下降(SGD)优化器,初始学习率为 0.001,权重衰减为 0.0001,裁剪大小为 513 × 513,批量大小为 16,训练周期为 80。对于 Cityscapes 数据集的训练,我们还使用随机梯度下降(SGD)优化器,初始学习率为 0.01,权重衰减为 0.0005,裁剪大小为 769 × 769,批量大小为 16,训练周期为 200。在所有实验中,解码器的学习率是主干网的十倍。我们在训练过程中使用 Poly 调度来衰减学习率: l r = l r b a s e ∙ ( 1 − i t e r t o t a l _ i t e r ) 0.9 lr = lr_{base} \bullet (1 - \frac{iter}{total\_ iter})^{0.9} lr=lrbase∙(1−total_iteriter)0.9 。
4.2 Comparison with Existing Alternatives
我们将我们的方法与以下最近的半监督语义分割方法进行比较:Mean Teacher (MT) [39]、CCT [34]、GCT [24]、PseudoSeg [51]、CutMix [17]、CPS [11]、PC2Seg [49] ,AEL [23]。为了公平比较,我们重新实现了 MT [39]、CutMix [46]。对于 Cityscapes [12],我们还重现了 CPS [11] 和 AEL [23]。 所有结果都配备相同的网络架构(DeepLabv3+ 作为解码器,ResNet-101 作为编码器)。值得注意的是,经典的 PASCAL VOC 2012 数据集和搅拌机 PASCAL VOC 2012 数据集仅在训练集上有所不同。他们的验证集与普通验证集相同,有 1, 449 张图像。
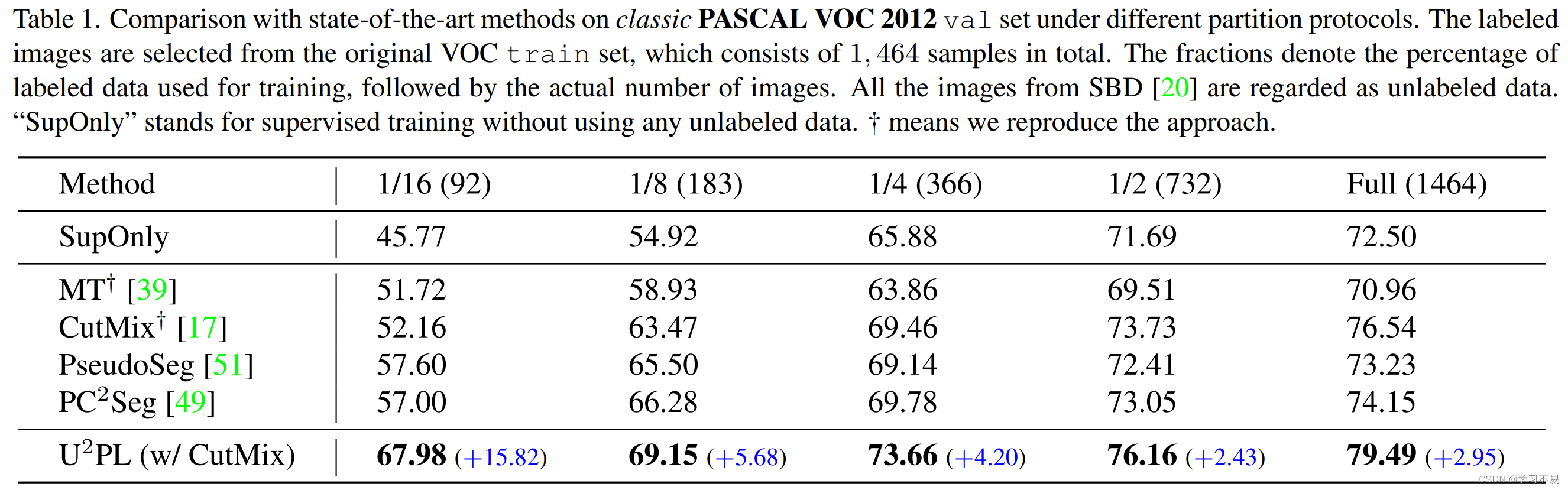
经典 PASCAL VOC 2012 数据集的结果。 表 1 将我们的方法与经典 PASCAL VOC 2012 数据集上的其他最先进的方法进行了比较。在 1/16、1/8、1/4 和 1/2 分区协议下, U 2 P L U^2PL U2PL 的性能分别优于监督基线 +22.21%、+14.23%、+7.78% 和 +4.47%。为了公平比较,我们只列出了在经典 PASCAL VOC 2012 上测试的方法。我们的方法 U 2 P L U^2PL U2PL 在所有分区协议下均优于 P C 2 S e g PC^2Seg PC2Seg +10.98%、+2.87%、+3.88% 和 +3.11%(在 1/16、1/8 下) 、 1/4 和 1/2 分区协议。即使在完全监督下,我们的方法也比 PC2Seg 高出 +5.34%。
blender PASCAL VOC 2012 数据集的结果。 表 2 显示了blender PASCAL VOC 2012 数据集的比较结果。在大多数分区协议下,我们的方法 U 2 P L U^2PL U2PL 优于所有其他方法。与基线模型(仅使用监督数据训练)相比,U2PL 在 1/16、1/8、1/4 和 1/2 分区下实现了 +9.34%、+7.46%、+3.50% 和 +3.37% 的所有改进协议分别。与现有的最先进的方法相比,U2PL 在所有分区协议下都超越了它们。特别是在1/8协议和1/4协议下, U 2 P L U^2PL U2PL 优于AEL+1.44%和+1.24%。
城市景观数据集的结果。 表 3 展示了 Cityscapes 验证集上的比较结果。在 1/16、1/8、1/4 和 1/2 分区协议下, U 2 P L U^2PL U2PL 与仅受监督的基线相比,实现了一致的性能增益 +9.16%、+3.95%、+4.08% 和 +1.29%。 U 2 P L U^2PL U2PL 的性能明显优于现有最先进的方法。特别是,在 1/16、1/8、1/4 和 1/2 分区协议下,U2PL 的性能优于 AEL +0.45%、+0.93%、+1.03% 和 +0.11%。
请注意,当标记数据极其有限时,例如,当我们只有 92 个标记数据时,我们的 U 2 P L U^2PL U2PL 大大优于以前的方法(经典 PASCAL VOC 2012 在 1/16 分割下 +10.98%),证明了使用不可靠的数据的效率伪标签。


5 Conclusion
我们提出了一种半监督语义分割框架 U 2 P L U^2PL U2PL,将不可靠的伪标签纳入训练中,该框架优于许多现有的最先进方法,这表明我们的框架为半监督学习研究提供了一种新的有前途的范例。我们的消融实验证明这项工作的见解是相当扎实的。定性结果为其有效性提供了视觉证明,特别是在语义对象或其他模糊区域之间的边界上具有更好的性能。
与全监督方法相比,我们方法的训练非常耗时[7,8,30,36,47],这是半监督学习任务的常见缺点[11,22,23,34,44,49] ]。由于标签的极度缺乏,半监督学习框架通常需要为更高的准确率付出及时的代价。