官方文档https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-partition-function-transact-sql?view=sql-server-ver16
Best Practices
Always keep empty partitions at both ends of the partition range. Keep the partitions at both ends to guarantee that the partition split and the partition merge don’t incur any data movement. The partition split occurs at the beginning and the partition merge occurs at the end. Avoid splitting or merging populated partitions. Splitting or merging populated partitions can be inefficient. They can be inefficient because the split or merge may cause as much as four times more log generation, and may also cause severe locking.
最佳实践
始终在分区范围的两端保留空分区。保留两端的分区,以保证分区拆分和分区合并不会引起任何数据移动。分区拆分发生在开头,分区合并发生在结尾。避免拆分或合并填充的分区。拆分或合并填充的分区可能效率低下。它们可能效率低下,因为拆分或合并可能会导致多达四倍的日志生成,并且还可能导致严重的锁定。
结论
1、 如果分区表对应的分区中最后一个分区还是空分区,即最后一个分区还没有填充数据,则可以很快的对这个分区表的分区函数和分区架构进行扩展,不需要几秒就是一个DLL语句的时间ALTER PARTITION SCHEME 和ALTER PARTITION FUNCTION
2、 如果分区表对应的分区中最后一个分区不是空分区,即最后一个分区已经填充数据,则直接对这个分区表的分区函数和分区架构进行扩展会很麻烦,扩展时间取决于这个分区架构对应的所有表的总计大小,在本人经历案例中,分区架构12表的总计大小1.2TB,直接扩展分区函数和分区架构耗时16天,其中扩展分区函数几乎不耗时,主要耗在扩展分区架构
3、 如果分区表对应的分区中最后一个分区不是空分区,即最后一个分区已经填充数据,如果需要扩展分区,如果历史不怎么更改的话,最好的方法是建立新的数据库文件组和数据库文件和分区函数和分区方案和新的分区表,把原分区表的历史分区数据bcp out\bcp in到新的分区表,再选择一个停机时间窗口,把最后一个分区bcp out\bcp in到新的分区表,再对原表和新的分区名称互改
4、 如果想要分区架构中一个分区对应一个文件组可以按年份增长,则当我们使用CREATE PARTITION SCHEME 创建分区架构时,如果后续有需求需要扩展分区架构,无论怎么执行ALTER PARTITION SCHEME,分区架构对应最后一个文件组不会变的。所以一定不能用未来的年份文件组来作为分区架构的最后一个文件组,否则年份扩展几年后,最后一个文件组原来是未来年份,多年后可能变成以前年份
5、 新增分区,只能一个个区来加,不能一条alter partition function语句一次性增加几个分区范围
6、 如果一个分区存放一个文件,则一般情况下分区架构中文件组的数目比分区函数中的范围数目多1,因为超出分区范围的数据需要分区架构中的最后一个文件组来存放,所以我们扩展的时候,需要先扩展分区架构中文件组再扩展分区函数中的范围
7、 查询某个分区的数据时需要在分区函数PARTITION.FNDate前面加上数据库名,否则会报错Invalidobjectname′PARTITION.FNDate前面加上数据库名,否则会报错Invalid object name 'PARTITION.FNDate前面加上数据库名,否则会报错Invalidobjectname′PARTITION.FNDate’
select * from RayHistory.dbo.RAY_FinalEpsFCHistory where RayHistory.$PARTITION.FNDate(SnapshotDate)=1
现象:
12张表共用了一个partition schema分区方案,12表总计容量大小是1.2TB,分区表的历史数据不会修改,每天新增数据到分区表。这个分区方案关联的分区函数是按年分区,每年的数据都写入到一个指定的文件,这个分区函数最后一个指定的分区边界是2020年,这就导致之后2021、2022…年份的数据都存放在一个默认分区中,也就是2020年之后年份的数据都存放在一个文件中,随着时间的推移该文件越来越大会引发严重的IO问题。
改进需求:
需要扩展分区,把分区函数和分区方案从2021扩展到2030年,新建数据文件组和数据库文件,按年份从2021开始建立到到2030,每年数据存放到一个数据文件,隔年数据库文件存放到不同磁盘,有下面三个方案,综合考虑下来还是采用了方案3,建立新的分区函数\分区方案\数据库文件组数据库文件,再建立新的空分区表(分区表名_new)关联新的分区函数\分区方案\数据库文件组数据库文件,新的空分区表建立和原来分区表一样的主键索引等,在工作日把原来分区表的历史数据bcp out\bcp in到新表,再在停机时间窗口把在原来分区表改名为分区表_archive并把分区表名_new改名为分区表,再把分区表_archive当前分区数据bcp out\bcp in到分区表
四种方案的优劣

方案1
新增2021到2030年的10个数据库文件组和10个数据库文件,扩展分区函数到2030年并扩展分区架构到2030并将分区架构关联到新建的文件组
优点:
1、不需要建立新的表
2、12张表一起同时完成
缺点:
1、12张表在维护期间任何一张表都无法读写
2、所有表数据总计1.2TB,维护时间窗口太长,需要16天
脚本:增加数据库文件组
ALTER DATABASE [RayHistory] ADD FILEGROUP [FG_2021]
…
ALTER DATABASE [RayHistory] ADD FILEGROUP [FG_2031]
脚本:增加数据文件匹配新增的数据库文件组
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATA_2021’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATA_2021.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FG_2021]
…
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATA_2030’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATA_2030.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FG_2030]
脚本:扩展分区
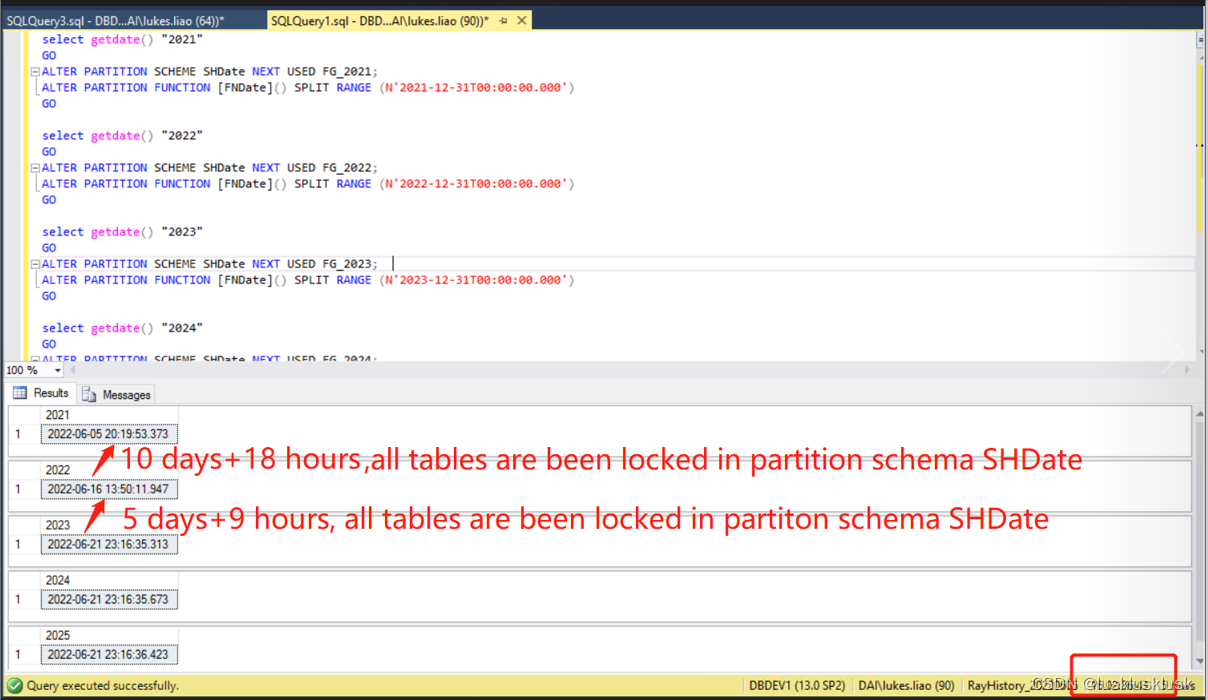
ALTER PARTITION SCHEME SHDate NEXT USED FG_2021; --不怎么耗时
alter PARTITION FUNCTION FNDate SPLIT RANGE (N’2021-12-31T00:00:00.000’)–最耗时,耗时10.5天
ALTER PARTITION SCHEME SHDate NEXT USED FG_2022; --不怎么耗时
alter PARTITION FUNCTION FNDate SPLIT RANGE (N’2022-12-31T00:00:00.000’)–最耗时,耗时5.5天
…
ALTER PARTITION SCHEME SHDate NEXT USED FG_2030; --不怎么耗时
alter PARTITION FUNCTION FNDate SPLIT RANGE (N’2030-12-31T00:00:00.000’) --不怎么耗时
备注:正在执行alter partition时,该partition上的所有表都会被锁定,执行select * from table with(nolock)都会被堵塞,锁类型是LCK_M_SCH_S,和该partition无关的表不受影响
方案2
新建数据库文件组和数据库文件到2030,创建新的分区方案和分区函数到2030,并将分区架构关联分区函数并将分区架构关联到新建的数据库文件,再把原分区表在线转换成非分区表,再把这些已经转换为非分区的表转为分区表,管理新的分区方案
优点:
1、不需要建立新的表
2、转换分区表到非分区表的过程中可以在线操作,表不会被锁可以读写
3、在操作一张的表时候,其他11张表不受影响
缺点:
1、需要12个停机时间窗口,12表需要一张张表来做
2、转换非分区表到分区表的过程中表会被锁,不可以读写
3、所有表数据总计1.2TB,维护时间窗口太长,总计需要25天,比如最大的表从分区表转换为非分区表就需要2天,再从非分区表转换为分区表需要5天
脚本:新数据库文件组
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_old]
…
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_2020]
…
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_2031]
脚本:新数据文件
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_old’, FILENAME = N’I:\DEFAULT.DATA\RayHistory_FNDATANEW_old.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_old]
…
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_2020’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATANEW_2020.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_2020]
…
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_2030’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATANEW_2030.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_2030]
脚本:新建分区函数
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’, N’2009-12-31T00:00:00.000’, N’2010-12-31T00:00:00.000’, N’2011-12-31T00:00:00.000’, N’2012-12-31T00:00:00.000’, N’2013-12-31T00:00:00.000’, N’2014-12-31T00:00:00.000’, N’2015-12-31T00:00:00.000’, N’2016-12-31T00:00:00.000’, N’2017-12-31T00:00:00.000’, N’2018-12-31T00:00:00.000’, N’2019-12-31T00:00:00.000’, N’2020-12-31T00:00:00.000’, N’2021-12-31T00:00:00.000’, N’2022-12-31T00:00:00.000’, N’2023-12-31T00:00:00.000’, N’2024-12-31T00:00:00.000’, N’2025-12-31T00:00:00.000’, N’2026-12-31T00:00:00.000’, N’2027-12-31T00:00:00.000’, N’2028-12-31T00:00:00.000’, N’2029-12-31T00:00:00.000’, N’2030-12-31T00:00:00.000’)
脚本:新建分区架构
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_old], [FGNEW_2008], [FGNEW_2009], [FGNEW_2010], [FGNEW_2011], [FGNEW_2012], [FGNEW_2013], [FGNEW_2014], [FGNEW_2015], [FGNEW_2016], [FGNEW_2017], [FGNEW_2018], [FGNEW_2019], [FGNEW_2020], [FGNEW_2021], [FGNEW_2022], [FGNEW_2023], [FGNEW_2024], [FGNEW_2025], [FGNEW_2026], [FGNEW_2027], [FGNEW_2028], [FGNEW_2029], [FGNEW_2030], [Primary])
脚本:表转换为非分区表
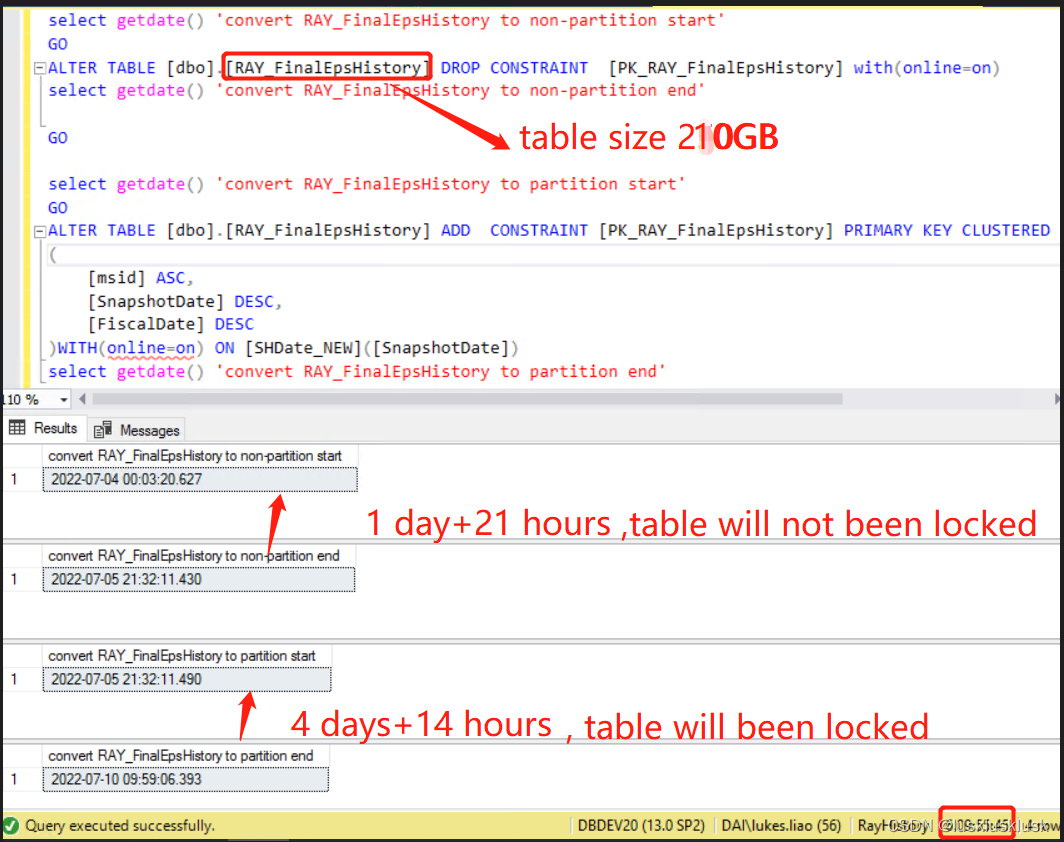
select getdate() ‘convert RAY_FinalEpsFCHistory to non-partition start’
GO
ALTER TABLE [dbo].[RAY_FinalEpsFCHistory] DROP CONSTRAINT [PK_RAY_FinalEpsFCHistory] with(online=on)
备注:以上过程不锁表
GO
select getdate() ‘convert RAY_FinalEpsFCHistory to non-partition end’
脚本:非分区表转换为分区表关联新的分区架构
select getdate() ‘convert RAY_FinalEpsFCHistory to partition start’
GO
ALTER TABLE [dbo].[RAY_FinalEpsFCHistory] ADD CONSTRAINT [PK_RAY_FinalEpsFCHistory1] PRIMARY KEY CLUSTERED
(
[msid] ASC,
[SnapshotDate] DESC,
[FiscalDate] DESC
)WITH(online=on) ON SHDate_NEW
备注:以上过程,开始不锁表,期间有段时间会锁表
GO
select getdate() ‘convert RAY_FinalEpsFCHistory to partition end’
方案3
新建数据库文件组和数据库文件到2030,创建新的分区方案和分区函数到2030,并将分区架构关联分区函数并将分区架构关联到新建的数据库文件,创建新的空分区表关联新的分区方案,新的空分区表创建和分区表一样的索引,新的空分区表名称为分区表名_new,拷贝分区表历史分区数据2021-01-01之前的数据到分区表名_new,当所有的历史分区数据都拷贝完成后,请求一个业务停止的时间窗口,在这个时间窗口内再把分区表改名为分区表_archive,把分区表名_new改名为分区表名,再把分区表_archive当前分区数据库拷贝到分区表名
优点:
1、12张表都不会被锁
2、可以在平时工作日一点点地把历史数据(2021年之前的数据)拷贝到新表
3、在维护窗口时间内,可以正常访问新表的历史数据(2021年之前的数据)
4、停机时间窗口最短,总计大概需要20小时
缺点:1、需要建立12张新表
2、20个小时的停机时间窗口需要分配成12个小的停机时间窗口,一个停机时间窗口操作1张表,因为12张需要一张张表来操作
3、在某张表的停机时间窗口中 ,无法访问该表的2021-2022年的数据
步骤
1、新建数据库文件组和数据库文件到2030,创建新的分区方案和分区函数到2030,并将分区架构关联分区函数并将分区架构关联到新建的数据库文件
2、创建新的空分区表关联新的分区方案,新的空分区表名称为分区表名_new
3、新的空分区表创建和分区表一样的索引,索引压缩为data_compresssion
4、拷贝原来分区表历史分区数据2021-01-01之前的数据到新的分区表名
5、当所有的历史分区数据都拷贝完成后,请求一个业务停止的时间窗口,在这个时间窗口内再把原来的分区表改名为分区表_archive,把新的分区改名为原来的分区表
6、再把分区表_archive当前分区数据库拷贝到分区表
脚本:新建数据库文件组
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_old]
…
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_2020]
…
ALTER DATABASE [RayHistory] ADD FILEGROUP [FGNEW_2031]
脚本:新建数据库文件
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_old’, FILENAME = N’I:\DEFAULT.DATA\RayHistory_FNDATANEW_old.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_2007]
…
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_2020’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATANEW_2020.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_2020]
…
ALTER DATABASE [RayHistory] ADD FILE ( NAME = N’FNDATANEW_2031’, FILENAME = N’T:\DEFAULT.DATA\RayHistory_FNDATANEW_2031.ndf’ , SIZE = 1024000KB , FILEGROWTH = 1024000KB ) TO FILEGROUP [FGNEW_2031]
脚本:新建分区函数
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’, N’2009-12-31T00:00:00.000’, N’2010-12-31T00:00:00.000’, N’2011-12-31T00:00:00.000’, N’2012-12-31T00:00:00.000’, N’2013-12-31T00:00:00.000’, N’2014-12-31T00:00:00.000’, N’2015-12-31T00:00:00.000’, N’2016-12-31T00:00:00.000’, N’2017-12-31T00:00:00.000’, N’2018-12-31T00:00:00.000’, N’2019-12-31T00:00:00.000’, N’2020-12-31T00:00:00.000’, N’2021-12-31T00:00:00.000’, N’2022-12-31T00:00:00.000’, N’2023-12-31T00:00:00.000’, N’2024-12-31T00:00:00.000’, N’2025-12-31T00:00:00.000’, N’2026-12-31T00:00:00.000’, N’2027-12-31T00:00:00.000’, N’2028-12-31T00:00:00.000’, N’2029-12-31T00:00:00.000’, N’2030-12-31T00:00:00.000’)
脚本:新建分区架构
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007], [FGNEW_2008], [FGNEW_2009], [FGNEW_2010], [FGNEW_2011], [FGNEW_2012], [FGNEW_2013], [FGNEW_2014], [FGNEW_2015], [FGNEW_2016], [FGNEW_2017], [FGNEW_2018], [FGNEW_2019], [FGNEW_2020], [FGNEW_2021], [FGNEW_2022], [FGNEW_2023], [FGNEW_2024], [FGNEW_2025], [FGNEW_2026], [FGNEW_2027], [FGNEW_2028], [FGNEW_2029], [FGNEW_2030], [FGNEW_2031])
脚本:bcp out和bcp in历史数据从原表到新表
bcp out
bcp "select * from RayHistory.dbo.RAY_FinalEpsFCHistory where KaTeX parse error: Undefined control sequence: \BCP at position 46: …=1" queryout L:\̲B̲C̲P̲\RAY_FinalEpsFC…PARTITION.FNDate’,需要在PARTITION.FNDate前面加上数据库名,比如RayHistory.PARTITION.FNDate前面加上数据库名,比如RayHistory.PARTITION.FNDate前面加上数据库名,比如RayHistory.PARTITION.FNDate(SnapshotDate)
bcp “select * from RayHistory.dbo.RAY_FinalEpsFCHistory where RayHistory.KaTeX parse error: Undefined control sequence: \MARKETDATA at position 77: …1'" queryout R:\̲M̲A̲R̲K̲E̲T̲D̲A̲T̲A̲.DATA\RAY_Final…PARTITION.FNDate(SnapshotDate)=1 and SnapshotDate>‘2001-12-31’” queryout R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2.txt -S DBPROD68\MARKETDATA -n -T -k -e R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2_error_in.log>R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2_log.log
bcp “select * from RayHistory.dbo.RAY_FinalEpsFCHistory where RayHistory.$PARTITION.FNDate(SnapshotDate)=2” queryout R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p2.txt -S DBPROD68\MARKETDATA -n -T -k -e R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p2_error_in.log>R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p2_log.log
备注:–n,本机格式
bcp in
bcp RayHistory.dbo.RAY_FinalEpsFCHistory_NEW in R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_1.txt -S DBPROD68\MARKETDATA -n -T -k -b 10000 -e R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_1_error_out.log>>R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_1_log.log
bcp RayHistory.dbo.RAY_FinalEpsFCHistory_NEW in R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2.txt -S DBPROD68\MARKETDATA -n -T -k -b 10000 -e R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2_error_out.log>>R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p1_2_log.log
bcp RayHistory.dbo.RAY_FinalEpsFCHistory_NEW in R:\MARKETDATA.DATA\RAY_FinalEpsFCHistory_p2.txt -S DBPROD68\MARKETDATA -n -T -k -b 10000 -e R:\MARKETDATA.DATA\Bcpin_log\RAY_FinalEpsFCHistory\RAY_FinalEpsFCHistory_p2_error_out.log>>R:\MARKETDATA.DATA\Bcpin_log\RAY_FinalEpsFCHistory\RAY_FinalEpsFCHistory_p2_log.log
备注:-b 10000表示每1万行就提交一次
脚本:rename 原表和新表
EXEC sp_rename ‘dbo.RAY_FinalEpsFCHistory’, ‘RAY_FinalEpsFCHistory_archive’;
EXEC sp_rename ‘dbo.RAY_FinalEpsFCHistory_NEW’, ‘RAY_FinalEpsFCHistory’;
脚本:bcp out和bcp in当前分区数据从原表到新表
bcp “select * from RayHistory.dbo.RAY_FinalEpsHistory_archive where RayHistory.$PARTITION.FNDate(SnapshotDate)=15” queryout R:\MARKETDATA.DATA\RAY_FinalEpsHistory_archive_p15.txt -S DBPROD68\MARKETDATA -n -T -k -e R:\MARKETDATA.DATA\Bcpout_log\RAY_FinalEpsHistory\RAY_FinalEpsHistory_archive_p15_error.log>R:\MARKETDATA.DATA\Bcpout_log\RAY_FinalEpsHistory\RAY_FinalEpsHistory_archive_p15_log.log
bcp RayHistory.dbo.RAY_FinalEpsHistory in R:\MARKETDATA.DATA\RAY_FinalEpsHistory_archive_p15.txt -S DBPROD68\MARKETDATA -n -T -k -b 10000 -e R:\MARKETDATA.DATA\Bcpin_log\RAY_FinalEpsHistory\RAY_FinalEpsHistory_archive_p15_error.log>R:\MARKETDATA.DATA\Bcpin_log\RAY_FinalEpsHistory\RAY_FinalEpsHistory_archive_p15_log.log
方案3的一些实践经历
建立分区函数和分区架构时的语句,分区架构中写死一个分区对应一个文件组
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’, N’2009-12-31T00:00:00.000’)
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007], [FGNEW_2008], [FGNEW_2009], [primary])
执行分区合并后,即把2009年的数据和以后的数据合并
ALTER PARTITION FUNCTION FNDate_NEW2022 MERGE RANGE (N’2009-12-31T00:00:00.000’);
分区函数合并后,分区架构也会自动变化,即2009年对应的分区架构文件组自动变成了分区架构创建时最后的文件组primary
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’)
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007], [FGNEW_2008], [primary])
一个重要的实践结论1:如果想要分区架构中一个分区对应一个文件组可以按年份增长,则当我们使用CREATE PARTITION SCHEME 创建分区架构时,如果后续有需求需要扩展分区架构,无论怎么执行ALTER PARTITION SCHEME,分区架构对应最后一个文件组不会变的。所以一定不能用未来的年份文件组来作为分区架构的最后一个文件组,否则年份扩展几年后,最后一个文件组原来是未来年份,多年后可能变成以前年份,示例如下
创建分区函数和分区架构,按年来分,先只创建了2年的分区,2007到2008年
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’)
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007], [FGNEW_2008], [FGNEW_2009])
2008年底的时候扩展到2011年,则写语句如下
ALTER PARTITION SCHEME [SHDate_NEW] NEXT USED FGNEW_2009
ALTER PARTITION FUNCTION FNDate_NEW SPLIT RANGE (N’2009-12-31T00:00:00.000’)
ALTER PARTITION SCHEME [SHDate_NEW] NEXT USED FGNEW_2010
ALTER PARTITION FUNCTION FNDate_NEW SPLIT RANGE (N’2010-12-31T00:00:00.000’)
ALTER PARTITION SCHEME [SHDate_NEW] NEXT USED FGNEW_2011
ALTER PARTITION FUNCTION FNDate_NEW SPLIT RANGE (N’2011-12-31T00:00:00.000’)
则分区函数和分区架构的创建脚本变成了
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’, N’2009-12-31T00:00:00.000’, N’2010-12-31T00:00:00.000’, N’2011-12-31T00:00:00.000’)
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007],[FGNEW_2008], [FGNEW_2009],[FGNEW_2010],[FGNEW_2011],[FGNEW_2009])
一个重要的实践结论2:新增分区,只能一个个区来加,不能一条alter partition function语句一次性增加几个分区范围
一个重要的实践结论3:如果一个分区存放一个文件,则一般情况下分区架构中文件组的数目比分区函数中的范围数目多1,因为超出分区范围的数据需要分区架构中的最后一个文件组来存放,所以我们扩展的时候,需要先扩展分区架构中文件组再扩展分区函数中的范围
假如分区函数和分区架构的创建语句如下
CREATE PARTITION FUNCTION FNDate_NEW AS RANGE LEFT FOR VALUES (N’2007-12-31T00:00:00.000’, N’2008-12-31T00:00:00.000’)
CREATE PARTITION SCHEME [SHDate_NEW] AS PARTITION [FNDate_NEW] TO ([FGNEW_2007], [FGNEW_2008], [primary])
新增分区到2009年
ALTER PARTITION FUNCTION FNDate_NEW SPLIT RANGE (N’2009-12-31T00:00:00.000’)
报错Warning: The partition scheme ‘FNDate_NEW’ does not have any next used filegroup. Partition scheme has not been changed.
改成如下即可
ALTER PARTITION SCHEME SHDate NEXT USED FGNEW_2009;
ALTER PARTITION FUNCTION FNDate_NEW SPLIT RANGE (N’2009-12-31T00:00:00.000’)
方案4
新建数据库文件组和数据库文件到2030,创建新的分区方案和分区函数到2030,并将分区架构关联分区函数并将分区架构关联到新建的数据库文件,创建新的空分区表关联新的分区方案,新的空分区表创建和分区表一样的索引,新的空分区表名称为分区表名_new
缺点:
1、需要建立12张新表
2、需要修改程序逻辑,在指定的日期部署,以指定日期为分界线,读写指定日期前的数据只能去找原表,读写指定日期后的数据只能去找新表