[python刷题模板] 珂朵莉树 ODT (基于支持随机访问的跳表)
- 一、 算法&数据结构
- 1. 描述
- 2. 复杂度分析
- 3. 常见应用
- 4. 常用优化
- 二、 模板代码
- 0. 区间推平(lg),单点询问(lg) CF292E. Copying Data
- 1. 区间推平,区间询问最小值
- 2. 区间推平,区间查询最大值
- 3. 不存在区间推平,只有区间加,区间询问最大值(不该用珂朵莉)
- 5. 区间推平,区间询问最大值
- 6. 单点赋值,合并区间(不该用珂朵莉)
- 三、其他
- 四、更多例题
- 五、参考链接
一、 算法&数据结构
1. 描述
我曾写过一篇基于SortedList的珂朵莉模板,在CF上宣告弃用。 [python刷题模板] 珂朵莉树 ODT (20220928弃用)
- 原因是做了CF上一道题,过不了。究其原因是assign操作时del tree[begin:end]的复杂度太高。
- SortedList实现是每块最大2000的分块List,当每次只删1个值时,块内操作需要O(2000),块外是O(n/2000)。
- 因此我试了下手撕跳表,这里需要注意:要实现跳表的随机化访问和删除(即快速访问第k大的数)
- 以下部分是原文,把SortedList部分改掉,如果要看基于SortedList实现,可以通过上边的链接去看旧文。
- 而且SortedList在很多OJ上不支持,可以选择手动把源码拷贝到代码里,挺麻烦。
- 目前测试来看,跳表写法在力扣上的表现不如SortedList,应该是数据较弱的原因。
- 另外缺点是码量较高,毕竟手撕跳表+珂朵莉,好在可以直接复制模板,两三百行
- 在网络上搜了很久没怎么找到珂朵莉树的python实现,自己写一个。
- 由于python没有有序容器(除SortedList,del复杂度不满足需求),因此自己实现一个。
- 这里选择了码量较少,可以支持随机访问的跳表。
- 珂朵莉树是建立在数据随机的情况下的一个乱搞算法。
- 当操作中有大量
区间赋值动作,尤其是大区间赋值,会把这个区间的值推平,并且将原本这里边的很多小区间合并。 - 如果数据随机,可以预见合并区间后,保留下来的区间不会很多。
- 那么查询区间如果不大,只需要处理几个区间即可。
- 底层用有序列表储存,c++set是红黑树,所以珂朵莉树也算树,
但python的sortedlist是list套list。。。可能名不副实了。不再使用SortedList,改为手撕随机化访问跳表。- 如果有心造数据卡珂朵莉树是可能实现的,数据不保证随机,大范围赋值少,查询多。
- 但这种的可以做特判,因为如果大范围赋值少,那数据范围应该小,没准可以暴力。
2. 复杂度分析
- 在随机数据下,珂朵莉树可达到O(nloglogn)
- split,珂朵莉熟的核心操作,在pos位置切割区间,返回以pos为左端点的区间。O(lgn).
- 之后所有动作都要包含两个split
- 更新assign,O(log2n)
- 查询query, O(lgn)+O©,c是区间内节点数,但c应该小所以速度很客观。
- 所有的query都是暴力操作。
- 找到这个区间所有节点,然后再算。
具体复杂度分析见知乎-珂朵莉树的复杂度分析
3. 常见应用
注意,这类题通常正解是线段树,但珂朵莉在特定情况下吊打正解。
这个特定情况是指:操作中存在大量assign碾平操作。
如果操作中不存在assign,请尽量不要用珂朵莉。(但数据弱的话也没准)
- 区间赋值,区间询问最大最小值。
- 区间赋值,区间询问第K小。
- 区间赋值,区间询问求和
- 区间赋值,区间询问n次方和(一般会有mod)。
这些操作全部暴力处理,因为我们认为:- 在随机数据下,大量区间被合并,询问的区间里不会有太多节点。
4. 常用优化
最大的优化是从SortedList改为手撕跳表。
- 由于实现了下标访问,但每次下标访问都是一次lg,因此在跳表中实现了
bisect_left_kvp方法,直接返回需要下标和两个相邻节点,避免多次lg。 - 从元组变成结构体,这样就可以直接修改。而且在结构体里实现小于运算。
- split时,本应删除原节点,加入两个节点。但实际上插入的左节点和原节点只差了一个右边界,因此可以直接修改。
- split生成时调用节点的解包函数,好写还快一点。
- 由于存在大量node,slot必须写;main中加入gc.disable(),实测不加TLE。
- 跳表的max_level设置成20即可,因为nlgn的题一般n<=2e5
- 下标取值时实现切片,方便操作。del暂时没写切片删除,理论上在均摊下每次操作应该是lg,因此先不写了。如果实现的话,单次切片删除最坏应该是n+lgn,但均摊依然是lg
二、 模板代码
0. 区间推平(lg),单点询问(lg) CF292E. Copying Data
CF292E. Copying Data

这题要区间推平,我只会线段树和珂朵莉,而线段树常数太大需要zkw。
import sys
from collections import *
from itertools import *
from math import *
from array import *
from functools import lru_cache
import heapq
import bisect
import random
import io, os
from bisect import *if sys.hexversion == 50924784:sys.stdin = open('cfinput.txt')RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())MOD = 10 ** 9 + 7"""https://codeforces.com/problemset/problem/292/E输入 n(≤1e5) 和 m (≤1e5),两个长度都为 n 的数组 a 和 b(元素范围在 [-1e9,1e9] 内,下标从 1 开始)。
然后输入 m 个操作:
操作 1 形如 1 x y k,表示把 a 的区间 [x,x+k-1] 的元素拷贝到 b 的区间 [y,y+k-1] 上(输入保证下标不越界)。
操作 2 形如 2 x,输出 b[x]。
输入
5 10
1 2 0 -1 3
3 1 5 -2 0
2 5
1 3 3 3
2 5
2 4
2 1
1 2 1 4
2 1
2 4
1 4 2 1
2 2
输出
0
3
-1
3
2
3
-1
"""MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.v# 1714 ms
def solve(n, m, a, b, qs):INF = infst = ODT(0, 10 ** 10, INF)ans = []for q in qs:if q[0] == 1:x, y, k = q[1] - 1, q[2] - 1, q[3]st.assign(y, y + k - 1, x - y)elif q[0] == 2:i = q[1] - 1d = st.query_point(i)if d < INF:ans.append(a[i + d])else:ans.append((b[i]))print('\n'.join(map(str, ans)))if __name__ == '__main__':import gc; # 注意gc不写会TLEgc.disable()n, m = RI()a = RILST()b = RILST()q = []for _ in range(m):q.append(RILST())solve(n, m, a, b, q)1. 区间推平,区间询问最小值
例题: 715. Range 模块
本题实测,基于跳表不如基于SortedList,可能是数据弱吧。但是比线段树快一些。
这题当然可以线段树,套一下板就行。
珂朵莉树实测比线段树快3倍。
当然最佳方案是有序列表合并拆分线段。
import gc;gc.disable()
MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 lgn """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.vdef query_min(self,l,r):""" 查找x,y区间的最小值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return min(node.v for node in self.tree[begin:end])class RangeModule:def __init__(self):self.tree = ODT(1,10**9,0)def addRange(self, left: int, right: int) -> None:self.tree.assign(left,right-1,1)def queryRange(self, left: int, right: int) -> bool:return 1 == self.tree.query_min(left,right-1)def removeRange(self, left: int, right: int) -> None:self.tree.assign(left,right-1,0)
2. 区间推平,区间查询最大值
链接: 729. 我的日程安排表 I
book是给区间全赋值1,区间操作前检查是否这个区间有非0的值,sum或者max都可以。
线段树也可以,珂朵莉树快一点,表现依然弱于SortedList。
import gc;gc.disable()
MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 lgn """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.vdef query_min(self,l,r):""" 查找x,y区间的最小值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return min(node.v for node in self.tree[begin:end])def query_max(self,l,r):""" 查找x,y区间的最大值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return max(node.v for node in self.tree[begin:end])class MyCalendar:def __init__(self):self.odt = ODT(0,10**9,0)def book(self, start: int, end: int) -> bool:if self.odt.query_max(start,end-1) == 1:return Falseself.odt.assign(start,end-1,1)return True
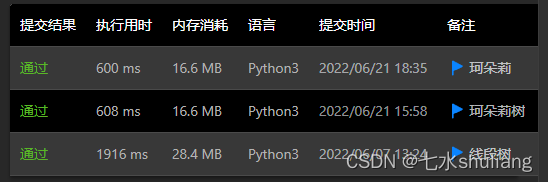
3. 不存在区间推平,只有区间加,区间询问最大值(不该用珂朵莉)
链接: 731. 我的日程安排表 II
这题没有assign本不该用珂朵莉做,但这个数据比较弱,确实能过,而且吊打线段树。
由于是求区间内一个超过1的数,因此可以区间查询时,提前退出。
import gc;gc.disable()
MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 lgn """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.vdef query_min(self,l,r):""" 查找x,y区间的最小值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return min(node.v for node in self.tree[begin:end])def query_max(self,l,r):""" 查找x,y区间的最大值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return max(node.v for node in self.tree[begin:end])# 以下操作全是暴力,寄希望于这里边元素不多。def add_interval(self,l,r,val):"""区间挨个加"""tree = self.treebegin = self.split(l)end = self.split(r+1)for i in range(begin,end):tree[i].v += valdef query_has_greater_than(self,l,r,val):"""查找x,y区间是否有大于val的数""" begin = self.split(l)end = self.split(r+1)return any(node.v>val for node in self.tree[begin:end])class MyCalendarTwo:def __init__(self):self.odt = ODT(0,10**9,0)def book(self, start: int, end: int) -> bool:if self.odt.query_has_greater_than(start,end-1,1) :return Falseself.odt.add_interval(start,end-1,1)return True
5. 区间推平,区间询问最大值
链接: 699. 掉落的方块
优化维护最大值思路类似上题。
但是存在赋值,因此可以珂朵莉,实测效率和线段树差不多。
import gc;gc.disable()
MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 lgn """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.v# 以下操作全是暴力,寄希望于这里边元素不多。def query_min(self,l,r):""" 查找x,y区间的最小值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return min(node.v for node in self.tree[begin:end])def query_max(self,l,r):""" 查找x,y区间的最大值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return max(node.v for node in self.tree[begin:end])def add_interval(self,l,r,val):"""区间挨个加"""tree = self.treebegin = self.split(l)end = self.split(r+1)for i in range(begin,end):tree[i].v += valdef query_has_greater_than(self,l,r,val):"""查找x,y区间是否有大于val的数""" begin = self.split(l)end = self.split(r+1)return any(node.v>val for node in self.tree[begin:end])
class Solution:def fallingSquares(self, positions: List[List[int]]) -> List[int]:odt = ODT(1,10**9,0) ans = []m = 0for l,d in positions:h = odt.query_max(l,l+d-1)odt.assign(l,l+d-1,h+d)m = max(m,h+d)ans.append(m)return ans6. 单点赋值,合并区间(不该用珂朵莉)
链接: 352. 将数据流变为多个不相交区间
实际上是线段合并。
注意合并时,访问了整个跳表里所有数据,注意写法是切片。
import gc;gc.disable()
MAX_LEVEL = 20 # 建议设置成lg(n),n是数据长度,20满足1e6,32满足1e10。由于跳表复杂度lgn,所以通常n<2e5,20就够
P_FACTOR = 0.25def random_level() -> int:lv = 1while lv < MAX_LEVEL and random.random() < P_FACTOR:lv += 1return lvclass SkiplistNode:__slots__ = 'val', 'forward', 'nb_len'def __init__(self, val: int, max_level=MAX_LEVEL):self.val = valself.forward = [None] * max_levelself.nb_len = [1] * max_leveldef __str__(self):return str(f'{self.val},{self.forward},{self.nb_len}')def __repr__(self):return str(f'{self.val},,{self.nb_len}')class Skiplist:def __init__(self, nums=None):self.head = SkiplistNode(-1)self.level = 0self._len = 0if nums:for i in nums:self.add(i)def __len__(self):return self._lendef find(self, target: int) -> bool: # 判断target是否存在cur = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:cur = cur.forward[i]cur = cur.forward[0]# 检测当前元素的值是否等于 targetreturn cur is not None and cur.val == targetdef index(self, target: int) -> int: # 在数据中找到target第一次出现的位置,找不到就返回-1cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while cur.forward[i] and cur.forward[i].val < target:idx += cur.nb_len[i]cur = cur.forward[i]# idx -= 1cur = cur.forward[0]# 检测当前元素的值是否等于 targetif cur is None or cur.val != target:return -1return idxdef bisect_left(self, target) -> int: # 返回第一个插入位置curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_right(self, target) -> int: # 返回最后一个插入位置(本方法未经严格测试curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val <= target:idx += curr.nb_len[i]curr = curr.forward[i]return idxdef bisect_left_kvp(self, target): # 返回下标,当前下标的值,前一个下标的值curr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 target 的元素while curr.forward[i] and curr.forward[i].val < target:idx += curr.nb_len[i]curr = curr.forward[i]return idx, curr.forward[0].val if idx < self._len else None, curr.valdef __getitem__(self, index):if isinstance(index, slice):start, stop, step = index.indices(self._len)if step == 1 and start < stop:ans = []cur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= start:idx += cur.nb_len[i]cur = cur.forward[i]p = startwhile p < stop and cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]p += 1return ansif start < stop:return self.__getitem__[slice(start, stop, 1)][index]if stop < start:return self.__getitem__[slice(start + 1, stop + 1, -step)][::-1]else:if index >= self._len or index + self._len < 0:raise Exception(f'index out of range: {index}')if index < 0:index += self._lencur = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当本层位置+前向长度小于目标位置时,在同层右移while cur.forward[i] and idx + cur.nb_len[i] <= index:idx += cur.nb_len[i]cur = cur.forward[i]return cur.forward[0].valdef __delitem__(self, index):if index >= self._len or index + self._len < 0:raise Exception(f'index out of range {index}')if index < 0:index += self._lenupdate = [None] * MAX_LEVELcurr = self.headidx = 0for i in range(self.level - 1, -1, -1):# 当同层位置+前向长度小于目标位置时,在同层右移while curr.forward[i] and idx + curr.nb_len[i] <= index:idx += curr.nb_len[i]curr = curr.forward[i]update[i] = currcurr = curr.forward[0]self._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1else:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1def add(self, num) -> None:self._len += 1update = [self.head] * MAX_LEVELcur_idx = [0] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素if i < self.level - 1 and not cur_idx[i]:cur_idx[i] = cur_idx[i + 1]while curr.forward[i] and curr.forward[i].val < num:# cur_idx[i] += curr.forward[i].nb_len[i]cur_idx[i] += curr.nb_len[i]curr = curr.forward[i]update[i] = curridx = cur_idx[0] + 1# print(cur_idx,idx)lv = random_level()self.level = max(self.level, lv)new_node = SkiplistNode(num, lv)for i in range(lv):# 对第 i 层的状态进行更新,将当前元素的 forward 指向新的节点old = update[i].nb_len[i] + 1update[i].nb_len[i] = idx - cur_idx[i]new_node.nb_len[i] = old - update[i].nb_len[i]new_node.forward[i] = update[i].forward[i]update[i].forward[i] = new_nodefor i in range(lv, self.level):update[i].nb_len[i] += 1def discard(self, num: int) -> bool:update = [None] * MAX_LEVELcurr = self.headfor i in range(self.level - 1, -1, -1):# 找到第 i 层小于且最接近 num 的元素while curr.forward[i] and curr.forward[i].val < num:curr = curr.forward[i]update[i] = currcurr = curr.forward[0]if curr is None or curr.val != num: # 值不存在return Falseself._len -= 1for i in range(self.level):if update[i].forward[i] != curr:update[i].nb_len[i] -= 1# breakelse:# 对第 i 层的状态进行更新,将 forward 指向被删除节点的下一跳update[i].nb_len[i] += curr.nb_len[i] - 1update[i].forward[i] = curr.forward[i]# 更新当前的 levelwhile self.level > 1 and self.head.forward[self.level - 1] is None:self.level -= 1return Truedef __str__(self):cur = self.headans = []while cur.forward[0]:ans.append(cur.forward[0].val)cur = cur.forward[0]return str(ans)def __repr__(self):return self.__str__()class ODTNode:__slots__ = ['l', 'r', 'v']def __init__(self, l, r, v):self.l, self.r, self.v = l, r, vdef __lt__(self, other):return self.l < other.ldef jiebao(self):return self.l, self.r, self.vdef __str__(self):return str(self.jiebao())def __repr__(self):return str(self.jiebao())class ODT:def __init__(self, l=0, r=10 ** 9, v=0):# 珂朵莉树,声明闭区间[l,r]上所有的值都是v# l可以从0开始,r可以不建议大于1e18,因为py会变成大数运算# 注意v赋初值# 以后都用手撕的跳表做了self.tree = Skiplist([ODTNode(l, r, v)])def __str__(self):return str(self.tree)def split(self, pos):""" 在pos位置切分,返回左边界l为pos的线段下标 lgn """tree = self.treep, v1, v2 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v1.l == pos:return pl, r, v = v2.jiebao()v2.r = pos - 1# tree.pop(p)# tree.add(ODTNode(l,pos-1,v))tree.add(ODTNode(pos, r, v))return pdef assign(self, l, r, v):""" 把[l,r]区域全变成val lgn """tree = self.treebegin = self.split(l)end = self.split(r + 1)for _ in range(begin, end):del tree[begin]tree.add(ODTNode(l, r, v))def query_point(self, pos):""" 单点查询pos位置的值 lgn """tree = self.treep, v, v1 = tree.bisect_left_kvp(ODTNode(pos, 0, 0))if p != len(tree) and v.l == pos:return v.vreturn v1.v# 以下操作全是暴力,寄希望于这里边元素不多。def query_min(self,l,r):""" 查找x,y区间的最小值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return min(node.v for node in self.tree[begin:end])def query_max(self,l,r):""" 查找x,y区间的最大值 暴力lgn+lgn+ lgnlgn(期望) """ begin = self.split(l)end = self.split(r+1)return max(node.v for node in self.tree[begin:end])def add_interval(self,l,r,val):"""区间挨个加"""tree = self.treebegin = self.split(l)end = self.split(r+1)for i in range(begin,end):tree[i].v += valdef query_has_greater_than(self,l,r,val):"""查找x,y区间是否有大于val的数""" begin = self.split(l)end = self.split(r+1)return any(node.v>val for node in self.tree[begin:end])# 以下操作全是暴力,寄希望于这里边元素不多。def query_all_intervals(self):tree = self.treelines = []l = r = -1for node in tree[:] :if node.v == 0:if l != -1:lines.append([l,r]) l = -1else:if l == -1:l = node.l r = node.rreturn linesclass SummaryRanges:def __init__(self):self.odt = ODT(0,10**4+1,0)def addNum(self, val: int) -> None:self.odt.assign(val,val,1)def getIntervals(self) -> List[List[int]]:return self.odt.query_all_intervals()# Your SummaryRanges object will be instantiated and called as such:
# obj = SummaryRanges()
# obj.addNum(val)
# param_2 = obj.getIntervals()
三、其他
- lc上的数据很弱,跳表写法不如SortedList,但CF不是。
四、更多例题
- 待补充
五、参考链接
- 链接: 知乎-算法学习笔记(15): 珂朵莉树