python进阶
- python语法继续学习
- 数据结构
- 数字
- 字符串
- 列表
- 元组
- 字典
- 面向对象
- 继承
- JSON
- 异常处理try except finally
- Linux命令
- 作业来啦!
- 问题
python语法继续学习
数据结构
数字
Number类型用于存储数值。
1、数学运算math模块及常用函数
菜鸟教程
导入math
代码示例:
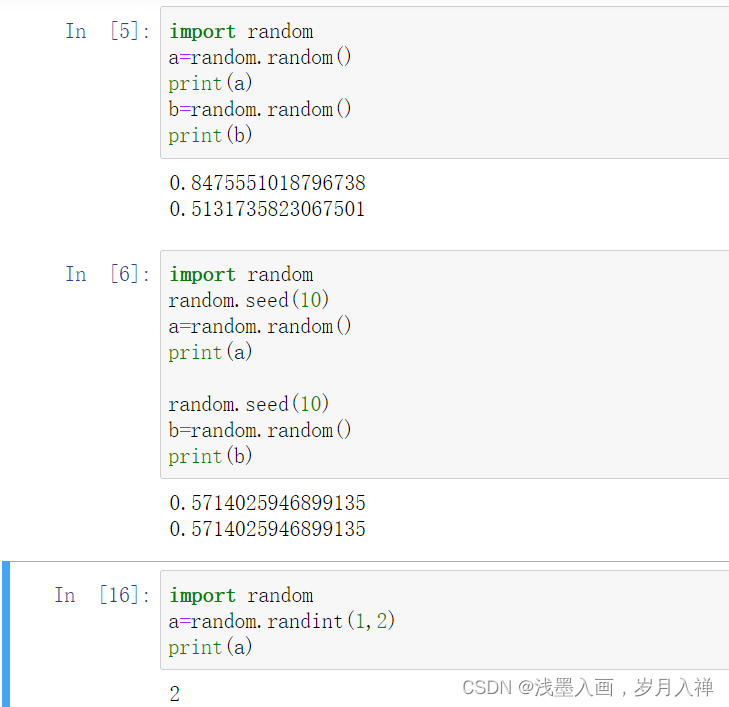
import math
print(math.ceil(4.1)) #返回数字的上入整数
print(math.floor(4.9)) #返回数字的下舍整数
print(math.fabs(-10)) #返回数字的绝对值
print(math.sqrt(9)) #返回数字的平方根
print(math.exp(1)) #返回e的x次幂
执行结果:
5
4
10.0
3.0
2.718281828459045
2、python随机数
导入random
1、random的random()生成一个[0,1)的实数
2、random的seed方法设置相同的种子会生成相同的随机数
3、randint(a,b)生成[a,b]的随机整数
代码示例如下:
字符串
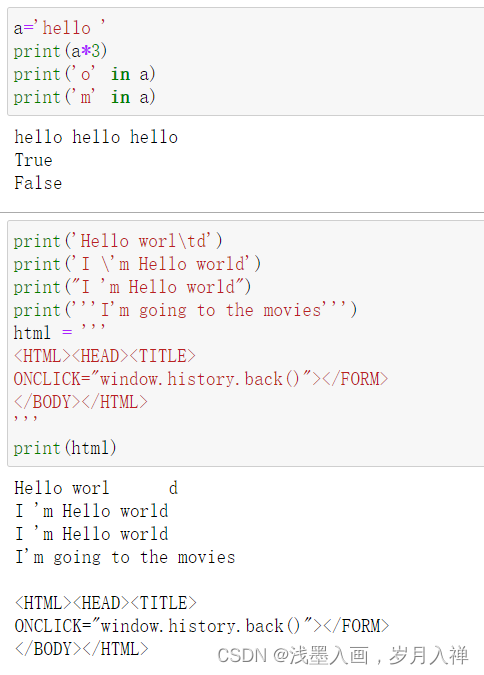
1、字符串重复输出
2、查找字符串是否包含某字符(串) in not in
上次那道包含2020的作业题用in也可以
3、单引号、双引号、三引号及转义
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
三引号:所见即所得
代码示例:
列表
1、查询
让我惊奇的是这段代码
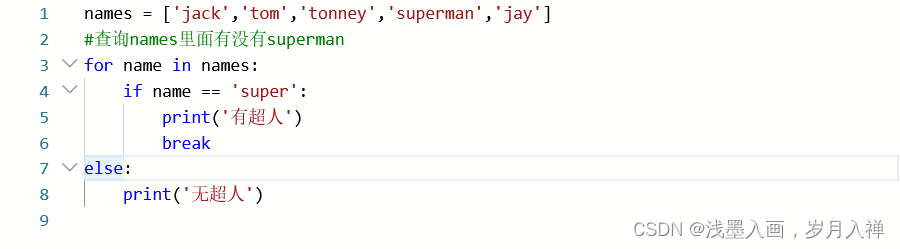
if 和else不在一个档次里面,但是这段代码的执行没有问题,遍历这个列表,有则输出然后停止,没有则打印无超人
2、添加extend函数相当于一个加号
3、修改
根据索引直接使用=赋值修改
或者:
for i in range(len(fruits)):if '香蕉' in fruits[i]:fruits[i] = 'banana'break
print(fruits)
4、删除的三种方法
del和pop根据索引删除,remove根据name删除
del words[1]
words.remove('cat')
words.pop(1)
5、切片

6、sorted函数排序
list=[2, 3, 5, 8, 11, 12, 13, 14, 16, 20]
a=sorted(list)
print(a)
a=sorted(list,reverse=True)
print(a)
[2, 3, 5, 8, 11, 12, 13, 14, 16, 20]
[20, 16, 14, 13, 12, 11, 8, 5, 3, 2]
元组
1、元组步长为-1、-2是反向按照步长输出
2、list可以直接用tuple转元组

3、元组包含一个元素需要加逗号,否则是字符串

4、元组也可以跟字符串一样使用+、*,像列表一样使用一些函数。
比如max min sum len count index in not in
5、元组的拆包与装包问题
#定义一个元组
t3 = (1,2,3)
#将元组赋值给变量a,b,c
a,b,c = t3
#打印a,b,c
print(a,b,c)
1 2 3
当元素个数多,但是定义的变量个数少:先把剩下的装包编程列表,加一个星号
当元素个数少,但是定义的变量个数多:报错喽
字典
1、list可以转为字典 dict方法,前提是列表中的元素都要成对出现
dict3 = dict([('name','杨超越'),('weight',45)])
print(dict3)
#{'name': '杨超越', 'weight': 45}
一些函数如下:
2、items()取键值
dict5 = {'杨超越':165,'虞书欣':166,'上官喜爱':164}
print(dict5.items())
for key,value in dict5.items():print(key+','+str(value))
#dict_items([('杨超越', 165), ('虞书欣', 166), ('上官喜爱', 164)])
#杨超越,165
#虞书欣,166
#上官喜爱,164
3、values()取所有的值
results = dict5.values()
print(results)
#dict_values([165, 166, 164])
4、keys()取所有的键
names = dict5.keys()
print(names)
#dict_keys(['杨超越', '虞书欣', '上官喜爱'])
5、使用pop和del根据键删除
del dict1['杨超越']
dict1.pop('杨超越')
面向对象
继承
class Person: def __init__(self,name):self.name = nameprint ('调用父类构造函数')def eat(self):print('调用父类方法')class Student(Person): # 定义子类def __init__(self):print ('调用子类构造方法')def study(self):print('调用子类方法')s = Student() # 实例化子类
s.study() # 调用子类的方法
s.eat() # 调用父类方法
'''调用子类构造方法
调用子类方法
调用父类方法
'''
JSON
json是一种轻量级数据交换格式
dumps将python对象编码为json字符串
dumps概述:
可选的参数:
sort_keys=True表示按照字典排序(a到z)输出;
indent参数,代表缩进的位数;
separators参数的作用是去掉,和:后面的空格,传输过程中数据越精简越好。
使用实例:
import json
data = [ { 'b' : 2, 'd' : 4, 'a' : 1, 'c' : 3, 'e' : 5 } ]
json = json.dumps(data, sort_keys=True, indent=4,separators=(',', ':'))
print(json)
'''[{"a":1,"b":2,"c":3,"d":4,"e":5}
]
'''
loads解码json数据
import json
jsonData = '{"a":1,"b":2,"c":3,"d":4,"e":5}'
text = json.loads(jsonData) #将string转换为dict
print(text)
异常处理try except finally
捕获的异常有很多种…
try:fh = open("/home/aistudio1/data/testfile01.txt", "w")fh.write("这是一个测试文件,用于测试异常!!")
except IOError:print('Error: 没有找到文件或读取文件失败')
else:print ('内容写入文件成功')fh.close()
如果data是存在的,那么如果没有是会创建的,否则抛出IO异常
finally中的内容退出try时总会执行的
try:f = open("/home/aistudio1/data/testfile02.txt", "w")f.write("这是一个测试文件,用于测试异常!!")
except IOError:print('Error: 没有找到文件或读取文件失败')
finally:print('关闭文件')f.close()
Error: 没有找到文件或读取文件失败
关闭文件
Linux命令
pwd显示当前目录
ls显示该目录下所有文件
cd work到work目录下
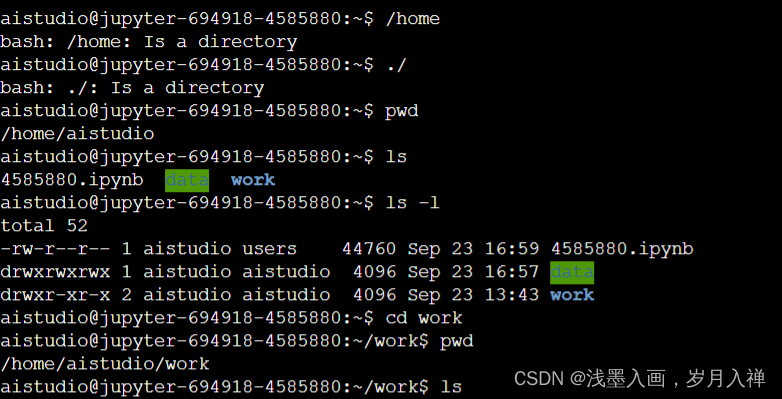
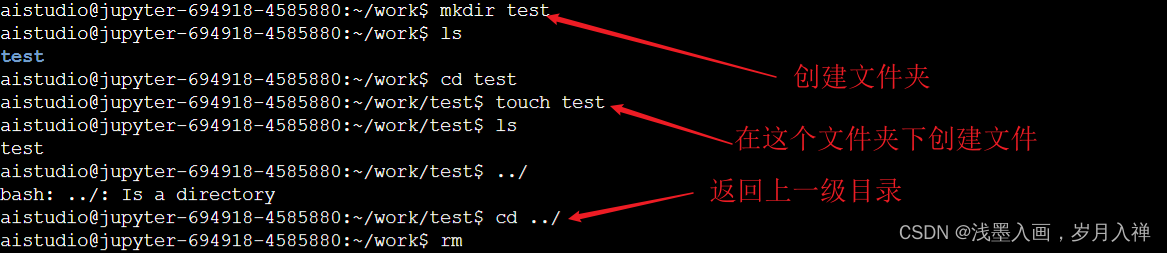
mkdir test创建test文件夹
rm -rf test强制删除
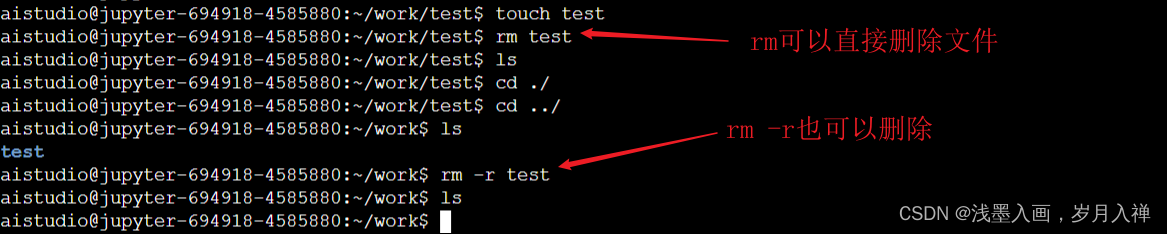
rm test也可以删除
目录一般不能删除,删除就是强制删除
rm -rf xxx删除:-r是递归处理,就是一层一层的删;-f是强制删除。
touch test创建文件

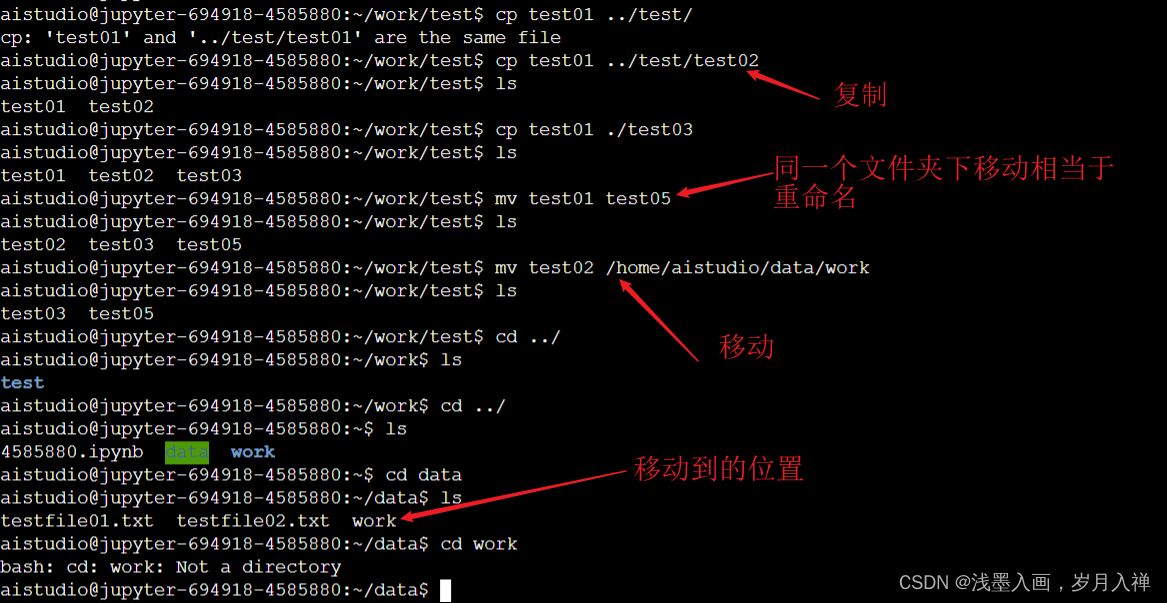
文件复制:cp test01 ./test/
cp test01 test04
移动 mv test01 test05:相当于文件重命名
mv test05 ./test/转移
.表示当前路径
压缩:
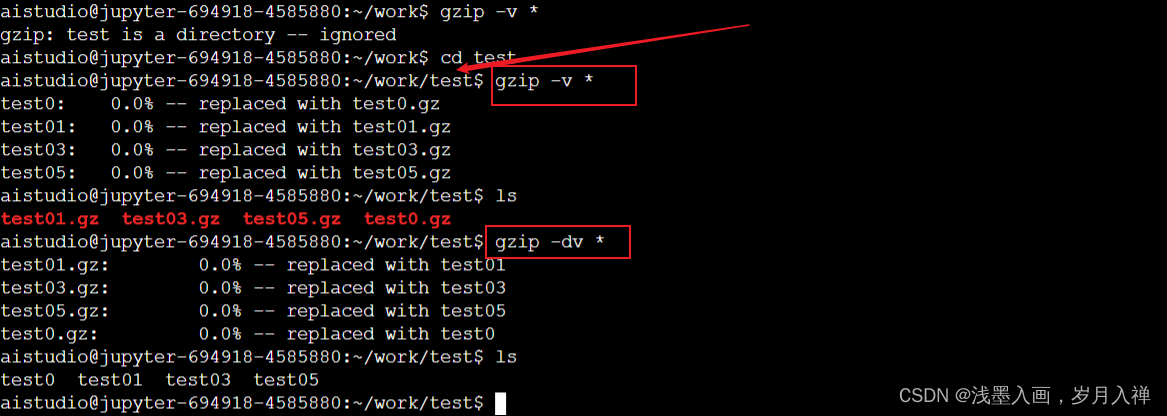
gzip
linux压缩文件中最常见的后缀名即为.gz,gzip是用来压缩和解压.gz文件的
-d或--decompress或--uncompress:解压文件;
-r或--recursive:递归压缩指定文件夹下的文件(该文件夹下的所有文件被压缩成单独的.gz文件);
-v或--verbose:显示指令执行过程。
注:gzip命令只能压缩单个文件,而不能把一个文件夹压缩成一个文件(与打包命令的区别)。
gzip -v(显示压缩过程) *(所有)
gzip只能压缩单个文件,不能压缩路径
解压缩:gzip -dv test02
-d是解压,v就是显示解压过程
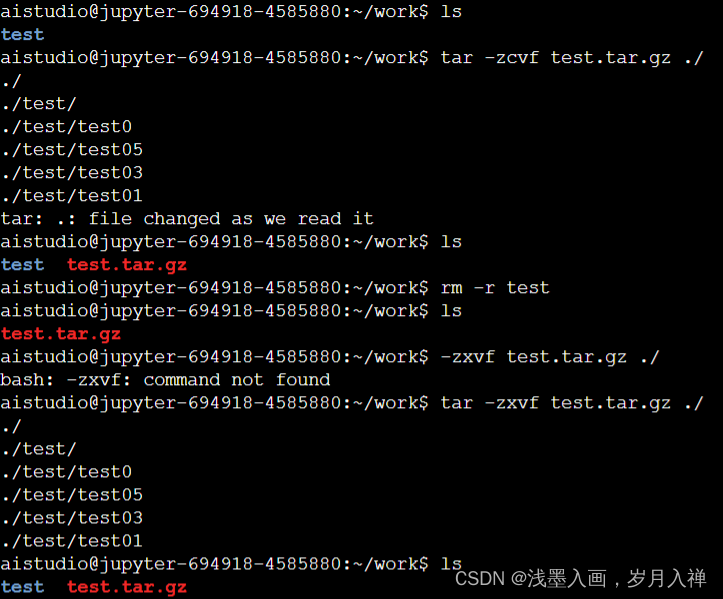
tar
在打包的同时进行压缩
tar -zcvf test.tar.zip ./
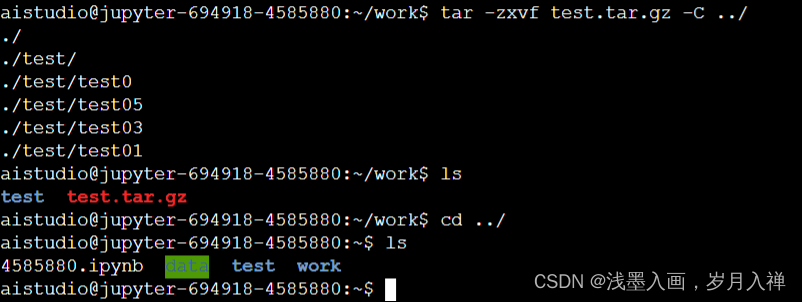
tar -zxvf test.tar.zip -C …/
解压到上一层
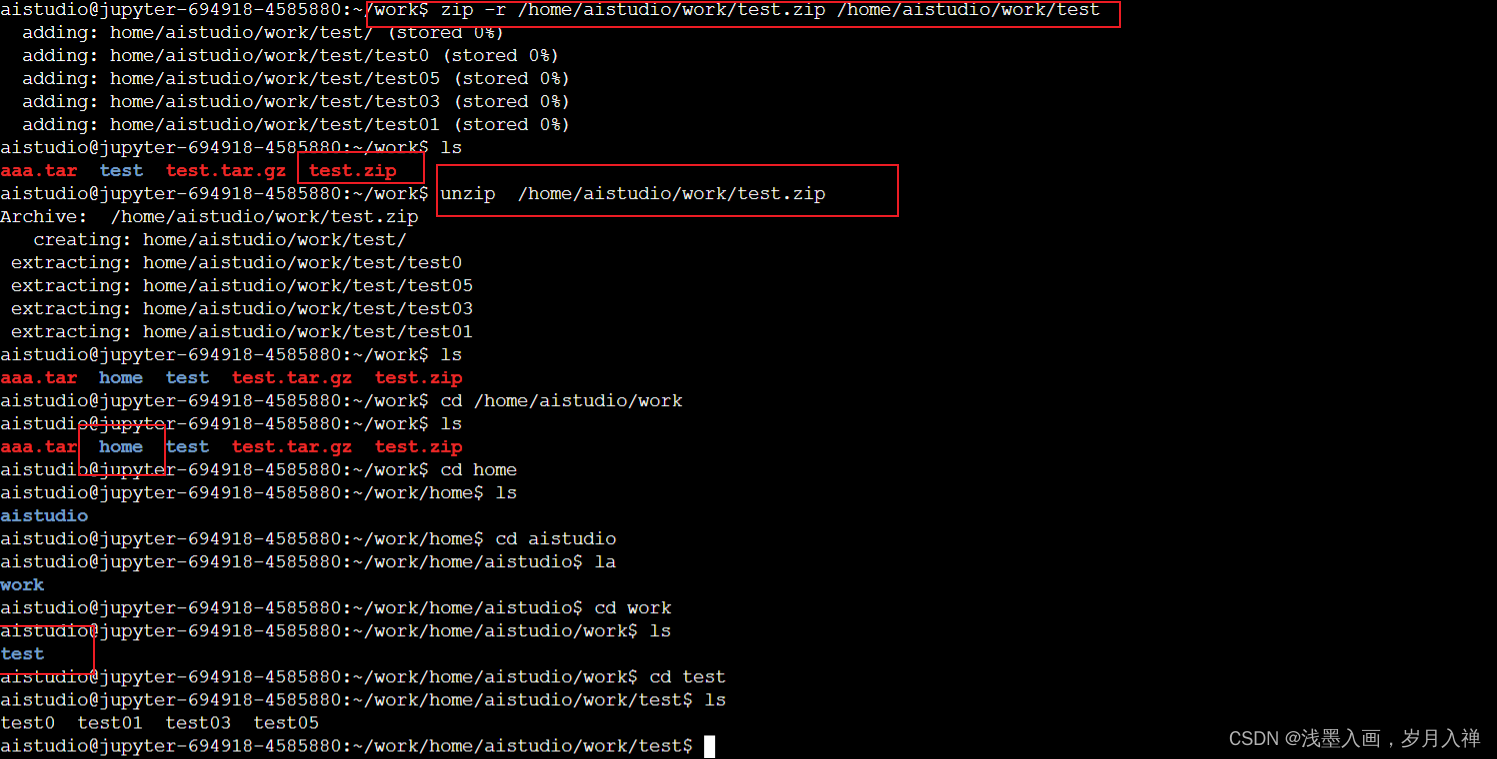
zip和unzip
zip -v test.zip test02
unzip test.zip -d …/data
上一层的data文件夹下
vi编辑:
touch test01
vi test01编辑,按下i进入输入模式(也称为编辑模式),
按下ESC 按钮回到一般模式Ø按下:wq储存后离开vi
esc shift冒号
wq!保存退出
qw不保存退出
有啥用以后再说吧,,,,,
作业来啦!
爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,并进行保存的过程。
Python为爬虫的实现提供了工具:
request模块:requests是python实现的简单易用的HTTP库
BeautifulSoup库:Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,支持python标准库中的HTML解析器,还支持一些第三方的解析器,其中有lxml
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup, “lxml”),推荐使用lxml作为解析器,因为效率更高。
发送请求:requests
解析:BeautifulSoup
json保存
爬取:headers模仿浏览器,不让对方以为是爬虫,不会被反爬虫误伤
发送请求
浏览器查看用户代理:
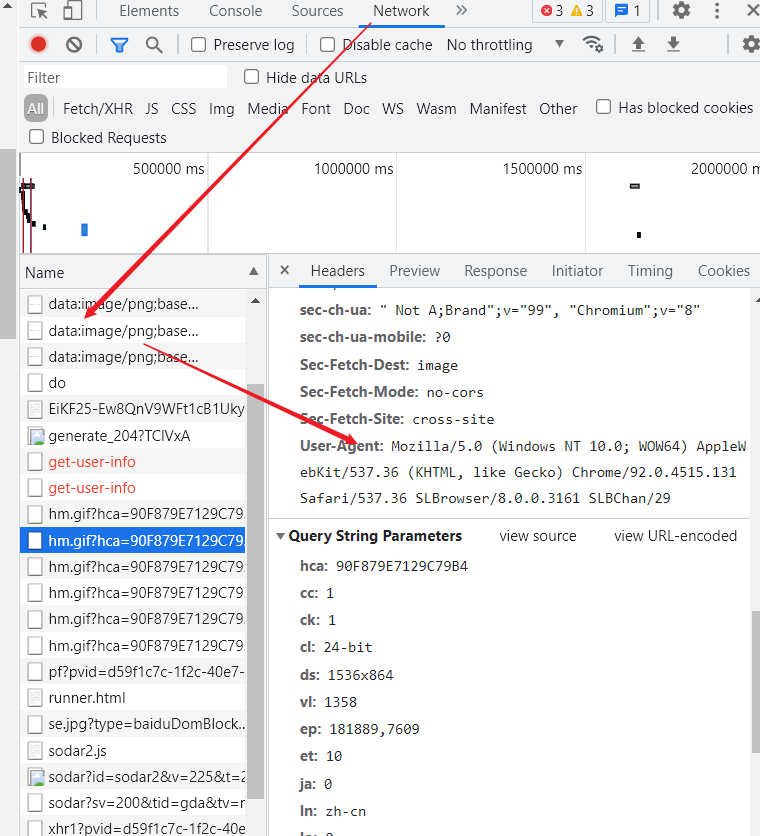
不得不说,这个真的好用
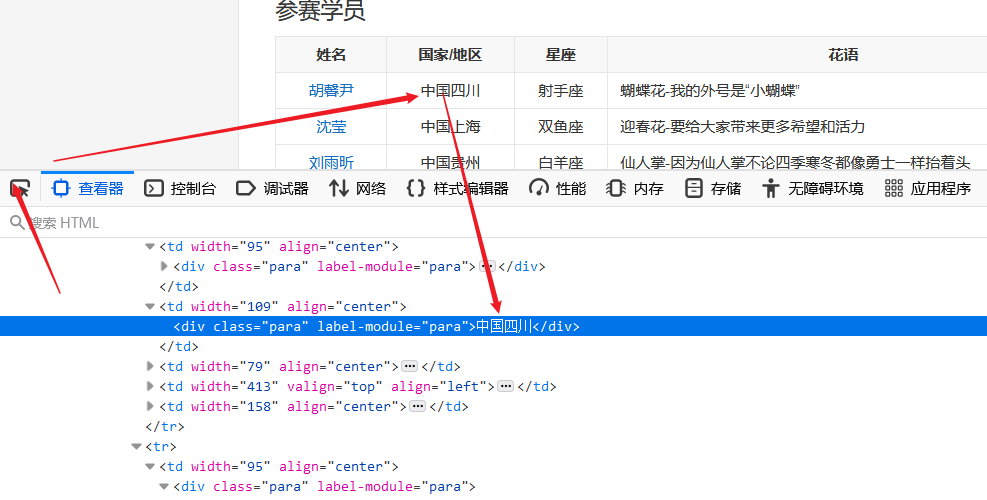
题目:使用Python来爬取百度百科中《青春有你2》所有参赛选手的信息。
我写的:
我就写了下边那个三里面的,还把一二的一些错改了改而已(卑微)
人家的:
1、爬取百度百科中《青春有你2》中所有参赛选手信息,返回页面数据
import json
import re
import requests
import datetime
from bs4 import BeautifulSoup
import os
def crawl_wiki_data():headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}url='https://baike.baidu.com/item/青春有你第二季' try:response = requests.get(url,headers=headers)print(response.status_code)#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串soup = BeautifulSoup(response.text,'lxml')#返回的是class为table-view log-set-param的<table>所有标签#tables = soup.find_all('table',{'class':'table-view log-set-param'})tables = soup.find_all('table',{'log-set-param':'table_view'})crawl_table_title = "参赛学员"for table in tables: #对当前节点前面的标签和字符串进行查找table_titles = table.find_previous('div').find_all('h3')for title in table_titles:if(crawl_table_title in title):return table except Exception as e:print(e)
table=crawl_wiki_data()
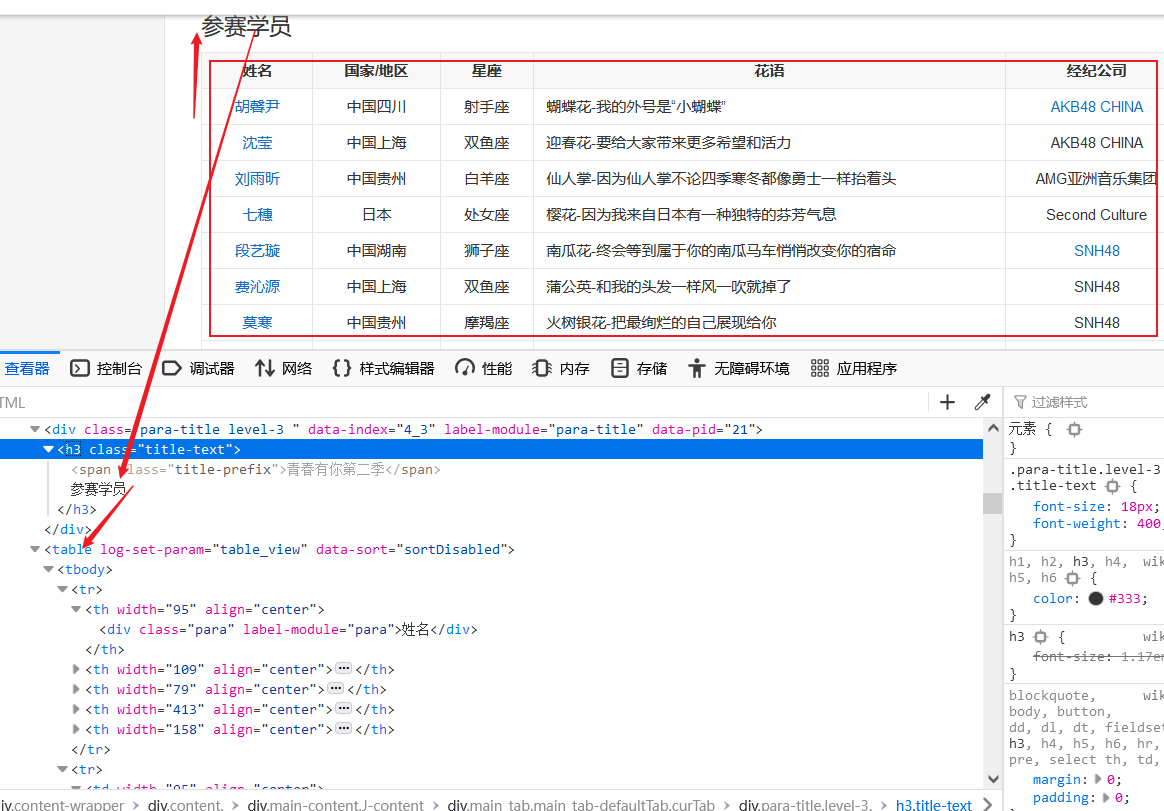
2、对爬取的页面数据进行解析,并保存为JSON文件
def parse_wiki_data(table_html):'''从百度百科返回的html中解析得到选手信息,以当前日期作为文件名,存JSON文件,保存到work目录下'''bs = BeautifulSoup(str(table_html),'lxml')all_trs = bs.find_all('tr')error_list = ['\'','\"']stars = []for tr in all_trs[1:]:all_tds = tr.find_all('td')star = {}#姓名star["name"]=all_tds[0].text#个人百度百科链接star["link"]= 'https://baike.baidu.com' + all_tds[0].find('a').get('href')#籍贯star["zone"]=all_tds[1].text#星座star["constellation"]=all_tds[2].text#花语,去除掉花语中的单引号或双引号,字符串中含有英文的单双引号报错flower_word = all_tds[3].textfor c in flower_word:if c in error_list:flower_word=flower_word.replace(c,'')star["flower_word"]=flower_word #公司,有的是链接的形式,如果不是,那就是文本if not all_tds[4].find('a') is None:star["company"]= all_tds[4].find('a').textelse:star["company"]= all_tds[4].text stars.append(star)json_data = json.loads(str(stars).replace("\'","\""))print(json_data)#w的意思就是写入with open('work/' + today + '.json', 'w', encoding='UTF-8') as f:json.dump(json_data, f, ensure_ascii=False)
parse_wiki_data(table)
从下标为1的开始,因为第一行是表头
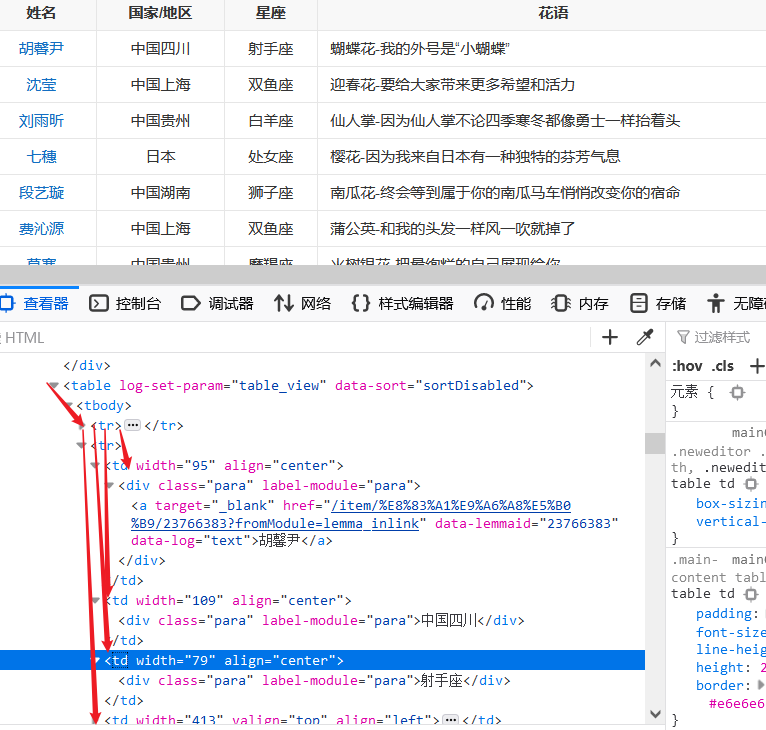
3、爬取每个选手的百度百科图片,并进行保存
def crawl_pic_urls():'''爬取每个选手的百度百科图片,并保存''' with open('work/'+ today + '.json', 'r', encoding='UTF-8') as file:json_array = json.loads(file.read())#将保存的信息转为数组读取出来headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' }pic_urls=[]for star in json_array:name = star['name']print(name)link = star['link']#!!!请在以下完成对每个选手图片的爬取,将所有图片url存储在一个列表pic_urls中!!!#爬取的url是每一个link#try:response = requests.get(link,headers=headers)#向link发送请求print(response.status_code)soup = BeautifulSoup(response.text,'lxml')#1、第一个问题,divs = soup.find_all('div',{'class':'summary-pic'})#返回的是class为summary-pic的所有div标签for div in divs:#获取div下a标签的href,就是图片页的路径,记得加前面的http,不然会报错的href1='https://baike.baidu.com' +div.find('a').get('href')#向a标签的href发送请求,图片页try:response1=requests.get(href1,headers=headers)print(response.status_code)soup1 = BeautifulSoup(response1.text,'lxml')aLabels1=soup1.find_all('a',{'class':'pic-item'})#向class为pic-item的所有a标签发送请求for aLabel in aLabels1:img=aLabel.find('img').get('src')#a标签下面的img的src属性即为图片的路径pic_urls.append(img)except Exception as e:print(e)except Exception as e:print(e)json_data = json.loads(str(pic_urls).replace("\'","\""))with open('work/' + 'imgsLocation' + '.json', 'w', encoding='UTF-8') as f:json.dump(json_data, f, ensure_ascii=False)
crawl_pic_urls()#!!!根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中!!!#down_pic(name,pic_urls)
4、图片下载
def down_pic(name,pic_urls):'''根据图片链接列表pic_urls, 下载所有图片,保存在以name命名的文件夹中,'''path = 'work/'+'pics/'+name+'/'if not os.path.exists(path):os.makedirs(path)for i, pic_url in enumerate(pic_urls):try:pic = requests.get(pic_url, timeout=15)string = str(i + 1) + '.jpg'with open(path+string, 'wb') as f:f.write(pic.content)print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))except Exception as e:print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))print(e)continuewith open('work/'+ 'imgsLocation' + '.json', 'r', encoding='UTF-8') as file:pic_urls = json.loads(file.read())
down_pic('imgs',pic_urls)
问题
1、Import “requests” could not be resolved from source
问题排查步骤:
(1)命令提示符pip list 查看是否安装了 requests 包
(2)安装 request 包、pip install requests
2、作业的问题有:
(1)可能获取不到div标签,因为有人的百度百科是多义项
(2)有人的百度百科右边没有图片,图片是主页的背景,例如:
3、写代码遇见的问题:
KeyboardInterrupt:应该是自主断开会遇见这个问题
爬取的路径没有http前缀的报错:
Invalid URL '/pic/%E8%83%A1%E9%A6%A8%E5%B0%B9/23766383/1/faf2b2119313b07eca80a7f98785862397dda04426bd?fr=lemma&fromModule=lemma_top-image&ct=single': No schema supplied. Perhaps you meant http:///pic/%E8%83%A1%E9%A6%A8%E5%B0%B9/23766383/1/faf2b2119313b07eca80a7f98785862397dda04426bd?fr=lemma&fromModule=lemma_top-image&ct=single?
另外:
是find_all find还是get要搞清楚
href1='https://baike.baidu.com' +div.find('a').get('href')
table_titles = table.find_previous('div').find_all('h3')
行了,终于结束了!!!