大气的编程
文章目录
- 大气的编程
- complex例子
- 创建一个类需要注意:
- 标准库(#include)
- 头文件标准形式:
- 声明(类定义)
- 构造函数
- class template (类模板):
- 操作符重载:
- reference(引用):
- const(常量)
- friend(友元)
- inline(内联)
- Singleton(单例)
- static(静态)
- global(全局)
- new(分配)
- delete(释放)
- 复习Complex:
- String例子
- Big Three
- 构造函数(ctor)
- 拷贝构造:
- 拷贝赋值:
- 析构函数:
- cout
- 栈(Stack)& 堆(Heap)
- 类与类关系
- 继承(Inheritance)
- 虚函数(virtual function):
- 复合(Composition)
- 委托(Delegation)
- 委托+继承
- Composite(设计模式)
- Prototype(设计模式)
- 力扣
- 类和节点:
- 动态数组(vector)
- 栈(stack)
- 队列(queue)
- 链表
- 字符串(string)
- 哈希表(unordered_map)
- 二叉树
- 算法小抄笔记
- 第一章(核心套路)
- 1.1 递归和迭代(二叉树)
- 1.2 动态规划
- 1.3 回溯算法(DFS)
- 1.4 BFS(广度优先)
- 1.5 双指针
- 1.6 滑动窗口
- 代码随想录
- 数组:
- 链表:
- 哈希表
- 字符串
- 栈与队列
- 哈希表
- 字符串
- 栈与队列
complex例子
class without pointer member(s)
创建一个类需要注意:
- 数据尽量放在private
- 参数尽量以reference 形式来传输(看情况加const)
- 返回值也应该使用 reference 来传输
- 类的函数或者body 能加入const 尽量加
- 构造函数,应该尽量使用(初始化阶段,赋值阶段区分)
标准库(#include)
#include<iostream> //标准库使用 < >
#include"complex.h" //自己定义的头文件使用 ""
头文件标准形式:
#ifndef __COMPLEX__
#define __COMPLEX__
// #endif
声明(类定义)
布局形式:包含 前置声明,类声明,类定义。

前置声明:就是类似于C的声明。比较简单
类声明:
class complex
{public: //外界可以访问complex(double r = 0, double i = 0) : re(r), im(i) { } //构造函数 :后面为初始化,{ }内为赋值。此时直接初始化为r, i ,不用赋值 速度快complex& operator += (const complex&); //操作符重构造声明 (最后分号结尾的都是声明),采用引用 // 的方式,具体看Referencedouble real() const { return re; }double imag() const { return im; } //内联函数,定义在class 内,const 具体看const 章节private: //外界无法直接访问double re, im;friend complex& __doapl(complex*, const complex&); //声明友元函数具体看 friend 章节
}
// 使用时候
{complex c1(2,1);complex c2; //根据构造函数,未有参数时候,都初始化为0...
}
对于public, private区别,还有一个protected
构造函数
complex(double r = 0, double i = 0) : re(r), im(i) { } //构造函数 :后面为初始化,{ }内为赋值。此时直接初始化为r, i ,不用赋值 速度快
complex(double r = 0, double i = 0)
{re = r;im = i;
} //构造函数,采用赋值的方式进行,速度比初始化方式慢,不够大气
class template (类模板):
(例如上方的数据只能是double的,如果我们想要用int的,就需要再定义一个类,但是百分之90以上都是重复的,所以为了解决这个问题,C++ 引入了 template)
template<typename T> //模板T,定义的时候可以代替
class complex
{public:complex(T r = 0, T i = 0) : re(r), im(i){ }complex& operator += (const complex&); //操作符重构造声明 (最后分号结尾的都是声明),采用引用 // 的方式,具体看ReferenceT real() const { return re; }T imag() const { return im; } //内联函数,定义在class 内,const 具体看const 章节private:T re, im;friend complex& __doapl(complex*, const complex&); //声明友元函数具体看 friend 章节
}
//使用的时候
{complex<double> c1(2.5,1.5);complex<int> c2(2,6);...
}
function template: 用的是 template , T为一个类。

操作符重载:
c++可以让操作符有新的意义,比如传统的是实数的加减,可以自己定义复数的加减。
inline complex&
__doapl(complex* ths, const complex& r)
{ths->re += r.re;ths->im += r.im;return *ths;
}
inline complex&
complex::operator += (this,const complex& r) //this 可以省略,代表左边的加上赋值的东西
{return __doapl (this, r);
}{complex c1(2,1);complex c2(5);c2 += c1; //this 代表c2
}
reference(引用):
类似于指针(有区别),在C++ 中非常重要的东西。试想变量名称是变量附属在内存位置中的标签,引用当成是变量附属在内存位置中的第二个标签。(但是引用意义类似于指针,使用类似于标签)
inline complex&
__doapl(complex* ths, const complex& r)
{ths->re += r.re;ths->im += r.im;return *ths
}
作为参数:(使用的时候,类似于标签来用),在类型定义后加入&
当传入的参数,在函数中进行了修改,改的是实参。
#include <iostream>
using namespace std;// 函数声明
void swap(int& x, int& y);int main ()
{// 局部变量声明int a = 100;int b = 200;cout << "交换前,a 的值:" << a << endl;cout << "交换前,b 的值:" << b << endl;/* 调用函数来交换值 */swap(a, b);cout << "交换后,a 的值:" << a << endl;cout << "交换后,b 的值:" << b << endl;return 0;
}// 函数定义
void swap(int& x, int& y)
{int temp;temp = x; /* 保存地址 x 的值 */ //直接只用x的值,而指针可能得加*号x = y; /* 把 y 赋值给 x */y = temp; /* 把 x 赋值给 y */return;
}
//输出
交换前,a 的值: 100
交换前,b 的值: 200
交换后,a 的值: 200
交换后,b 的值: 100
作为返回:(使用的时候,类似于标签来用),在函数类型定义后加入&
在某些情况下不可以传输 reference :当 参数作为局部参数,在函数中使用完后,会进行释放,此时传递的引用就不正确,通过 reference 看到不好的东西。
#include <iostream>using namespace std;double vals[] = {10.1, 12.6, 33.1, 24.1, 50.0};double& setValues( int i )
{return vals[i]; // 返回第 i 个元素的引用
}// 要调用上面定义函数的主函数
int main ()
{cout << "改变前的值" << endl;for ( int i = 0; i < 5; i++ ){cout << "vals[" << i << "] = ";cout << vals[i] << endl;}setValues(1) = 20.23; // 改变第 2 个元素setValues(3) = 70.8; // 改变第 4 个元素cout << "改变后的值" << endl;for ( int i = 0; i < 5; i++ ){cout << "vals[" << i << "] = ";cout << vals[i] << endl;}return 0;
}
//输出
改变前的值
vals[0] = 10.1
vals[1] = 12.6
vals[2] = 33.1
vals[3] = 24.1
vals[4] = 50
改变后的值
vals[0] = 10.1
vals[1] = 20.23
vals[2] = 33.1
vals[3] = 70.8
vals[4] = 50
传递着无需知道接受者的情况:
inline complex& __doapl(complex* ths, const complex& r)
{...return *ths
}
const(常量)
const 为constant 的缩写,本意是不变的。
C++ const 允许指定一个语义约束,编译器会强制实施这个约束,允许程序员告诉编译器某值是保持不变的。如果在编程中确实有某个值保持不变,就应该明确使用const,这样可以获得编译器的帮助。
修饰普通变量:
const int a = 7; //将a看作一个常量
int b = a; //正确
a = 8; //error 不能对常量赋值
修饰指针:
修饰指针内容,则内容不可变,修饰指针,则指针不可变,修饰内容和指针,则不都可以改变。
const int *p = 8; // const 位于指针左侧,修饰 *p 不可以改变,但是 p 可以变 (不知道为啥,编译器报错)
int* const p = &a; //修饰指针 p 不能变 但是*p 可以变
修饰参数传递和返回值(返回值时候,用不用无所谓)
void Cpf(const int a)
{cout<<a;// ++a; //a 为常数,这是错误的,a 不能被改变
}
修饰类成员函数:
//例如声明节
double real() const { return re; }
double imag() const { return im; } //内联函数,定义在class 内,const 具体看const 章节
friend(友元)
可以通过友元函数调用对象的private。
inline(内联)
C++ 为了解决一些频繁调用的小函数大量消耗(栈)空间的问题,引如了 inline 修饰符,表示内联函数。(栈是指函数的放置局部数据的(函数内数据)的内存空间。(直接用函数内的命令代替子函数,防止占用内存空间)
inline 仅仅是一个建议,实际是否为内联函数由编译器决定。对于一些复杂的函数,比如带循环,子函数等,不适合作为内联函数。一般定义在头文件中。
定义在类中的成员函数默认都是内联的,如果在类定义时就在类内给出函数定义,那当然最好。如果在类中未给出成员函数定义,而又想内联该函数的话,那在类外要加上 inline,否则就认为不是内联的。
class complex
{ public:complex (double r = 0, double i = 0): re (r), im (i){ }complex& operator += (const complex&);double real () const { return re; } //默认内联double imag () const { return im; } //默认内联private:double re, im;friend complex& __doapl (complex*, const complex&);
};
类外的成员函数内敛:
inline double //类外的内敛函数
imag(const complex& x)
{return x.imag ();
}
Singleton(单例)
一个类仅能创建一个实例,且提供对该实例的全局访问点。(例如日志,计算机任务管理器,仅有一个的东西)
class A
{public:static A& getInstance();setup() { ... }private:A();A(const A& rhs);...
};A& A::getInstance()
{static A a;return a;
}
static(静态)
定义在函数内部,函数作用域结束后不会立马被释放,当程序结束后才会被释放。
在类中:
如果定义的对象没有使用static(Complex c1,c2;),则数据c1,c2将储存在不同的地方,但是类中的成员函数只有一份(比如real())。
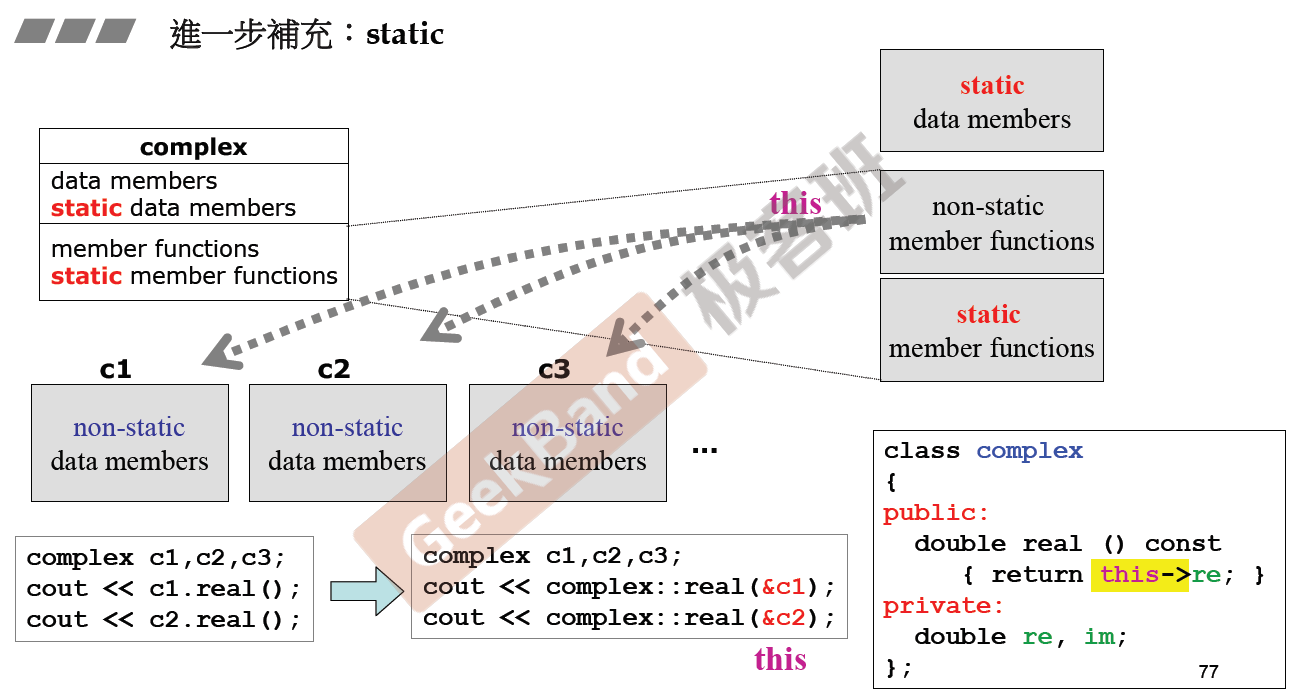
如果定义了static数据,则数据可以被所有的对象使用,是一个固定的。如果定义的是static函数,则函数仅仅可以使用静态数据(例如对静态数据进行修改),此函数无this pointer,不能用其他数据。

global(全局)
类似于static的作用,但是定义在所有函数外,可以被函数调用。
new(分配)
分配内存(类似于C中的malloc)
例如:
Complex* pc = new Complex(1,2); //分配一个pc空间,里面是复数(1,2)
delete(释放)
释放内存(类似于C中的free)
- 先调用析构函数(删除内容)
- 在进行释放(删除指针)
String* ps = new String("hello"); //分配
...
delete ps;
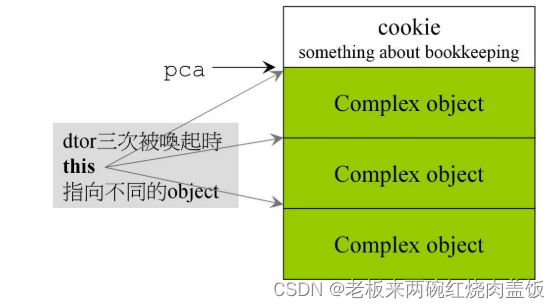
注意:array new 一定呀搭配 array delete
String* p = new String[3]; // 创建一个包含3个string的类
...
delete[] p; //唤起3次dtor(析构函数),再删除指针
复习Complex:
complex.h
#ifndef __COMPLEX__
#define __COMPLEX__
class complex
{public:complex (double r = 0, double i = 0) //构造函数,复习初始化和赋值,这里double是四个字节,传reference: re (r), im (i) //和传value 性质一样{ }complex& operator += (const complex&); //操作符重载,类内函数,不是local 随意返回 referencedouble real () const { return re; } // inline函数double imag () const { return im; }private:double re, im;friend complex& __doapl (complex*, //友元const complex&);
};
#endif
//类外定义
inline complex&
__doapl(complex* ths, const complex& r)
{ths->re += r.re;ths->im += r.im;return *ths;
}
inline complex&
complex::operator += (const complex& r) //+= 定义成了类内的局部函数,省略了this
{return __doapl (this, r);
}
//类外的其他定义
//此时的加法是类外定义的,不是类内函数,如何定义到类内,无法应付复数+实数或者实数+复数,因为类内的都是复数
inline complex //返回是一个local,所以函数定义为value 不能是reference
operator + (const complex& x, const complex& y) //传引用
{return complex(real(x) + real(y), imag(x) + imag(y)); //返回直接按定义的方式,比较大气。real(x)和
} //x.real(),可以研究研究//复数+实数,
inline complex
operator + (const complex& x, double y)
{return complex (real (x) + y, imag (x));
}
//实数+复数
inline complex
operator + (double x, const complex& y)
{return complex (x + real (y), imag (y));
}
// << 操作符
//例如:
complex c1(9, 8);
cout << c1; //可以肯定<<为非成员函数,因此定义,这一行可以用返回值 void
cout << c1 <<endl; // 这边从 c1->cout,endl->结果,因此此时返回值不能为void ,只能为reference os
#include <iostream.h> //可以随时+头文件,可以放在函数前面或者头文件最前面
ostream& //传引用 ostream 查手册
operator << (ostream& os, const complex& x)
{return os << '(' << real (x) << ','<< imag (x) << ')';
}
String例子
class with pointer member(s)
创建带指针的类,以string为例。
Big Three
拷贝构造,拷贝赋值,析构函数。

class String
{public:String(const char* cstr = 0);String(const String& str);String& operator = (const String& str);~String();char* get_c_str() const { return m_data; }private:char* m_data;
};
构造函数(ctor)
使用传统的拷贝构造,容易出现两个指针指向同一个位置的情况,导致内存泄漏。上部分叫深拷贝,下部分叫浅拷贝。
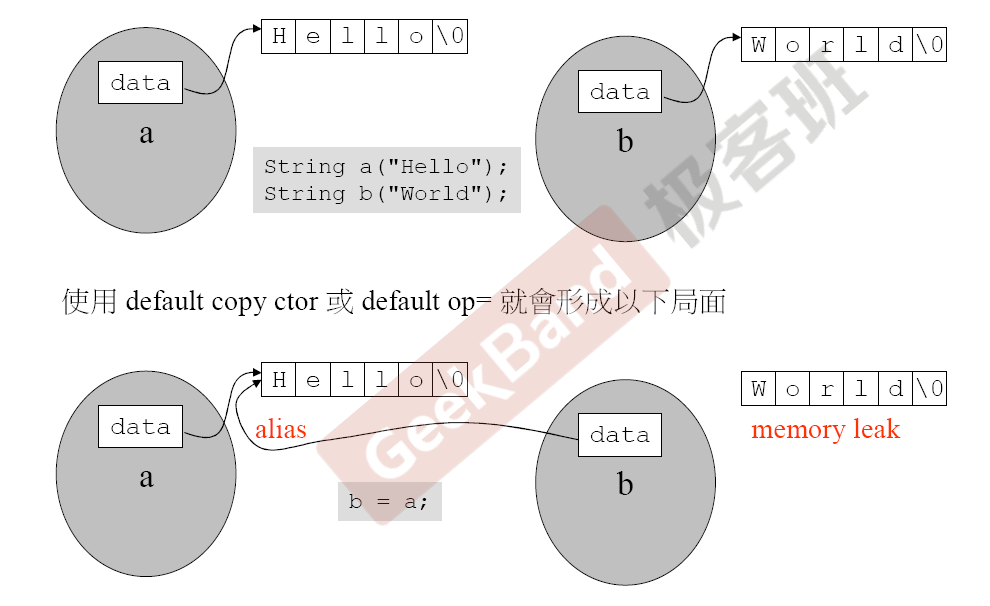
因此,需要重新定义拷贝构造函数,避免其指向同一个地方,利用new开辟新的空间实现。使用了new 就考虑用delete。
inline String::String(const char* cstr = 0)
{if(cstr){m_data = new char[strlen(cstr) + 1];strcpy(m_data, cstr);}else{m_data = new char[1];*m_data = "\0";}
}inline String::~String()
{delete[] m_data;
}
拷贝构造:
直接利用已有的String类来构造一个相同的类。深拷贝
inline String::Sting(const String& str)
{m_data = new char[strlen(str.m_data) + 1]; //直接取另一个对象的隐私数据,兄弟之间互为friend(是兄弟?) strcpy(m_data, str.m_data); //此处同理,如何直接取其隐私数据?
}
{String s1("hello");String s2(s1);// s2 = s1;
}
拷贝赋值:
//出现类似于这样的需求
{s2 = s1; //copy assignment operator
}
拷贝赋值
- 清空s2的内容,对s2进行释放(delete[])
- 重新创建s2,空间为s1大小(new)
- 将s1内容赋值导s2(strcpy)
inline String& String operator = (const String& str)
{if(this == str){ //自我检测,防止自我检测时候,先删除return *this; //this 是一个类指针}delete[] m_data; //步骤:先删除s2内容,在重新分配空间,在赋值。m_data = new char[strlen(str.m_data) + 1];strcpy(m_data, str.m_data);return *this;
}
析构函数:
class中有动态分布的内存(一般由new 创建),则需要设计析构函数,上面的complex中,由于没有动态内存的创建zxJ,因此可以用默认的析构函数(不必再写出来)。 使用了new来创建动态空间,就需要用delete来进行释放。具体看new章节。
inline String::~String()
{delete[] m_data;
}
cout
输出字符串,采用 << 的方式。
#include <iostream.h>
ostream& operator<<(ostream& os, const String& str)
{os << str.get_c_str();return os;
}
//使用的时候
{String s1("hello ");cout << s1;
}
栈(Stack)& 堆(Heap)
栈:存在于作用域(scope)中的一个内存空间。例如创建一个函数,函数本身就会形成一个stack来放置其参数,函数调用结束后,进行释放。
堆:操作系统提供的一个global内存空间,程序可以从中占据若干块(block)进行动态分配。可以使用New进行动态获得,释放的时候也必须使用delete来进行释放。
class Complex{...};
...
{Complex c1(1,2); //存在栈中,离开函数自动释放Complex* p = new Complex(3);//动态分配创建于堆中,函数结束后不会消失。
}
类与类关系
继承(Inheritance)
可以基于一个类来创建另一个类。基类和派生类。基类比如是动物,派生类可以是猫、狗等。is a 的关系。
// 基类
class Animal {// eat() 函数// sleep() 函数
};//派生类
class Dog : public Animal { //继承的方式 在类定义后面加上 :public 基类名// bark() 函数
};
一般继承搭配 虚函数 使用。
虚函数(virtual function):
继承包括了 数据,函数都可以被继承。函数被继承调用权。
是否重新定义可以分为 非虚函数,虚函数,纯虚函数。

例如上面的例子,父类为Shape,里面三个函数:
objectID()为ID形状的ID ,是每个形状的一个号码,不需要定义。
error():继承,每个形状出错的时候提示的出错类型,你可以自己定义。
draw():画出来。因为每个形状都不一样,所以需要必须定义,以方便画出来。 可以在父类中定义说明,然后等到子类继承的时候子类写。(Template Method)。对于设计框架具有很好的效果。可以先写一个框架,然后子类继承框架去补充。
复合(Composition)
一个类中放了另一个类。例如:queue中定义了一个deque的对象。复合的方式用的数值,而不是指针。has-a关系。

定义queue可以直接使用deque。例如deque有100个功能,queue只有deque中的6中功能。因此可以利用deque再重新定义一个类。
在构造和释放过程中,构造时候:由内而外(如先deque后queue);释放时候:由外到内(先释放queue再释放deque)。
委托(Delegation)
最出名。类似于复合的方式,只是复合的方式用指针。(一般C++习惯把指针的传递也称为reference)。

左边定义的只提供一个数据接口,具体的函数实现都要通过右边的类来实现。所以具有“编译防火墙”之称。
委托+继承
Composite(设计模式)
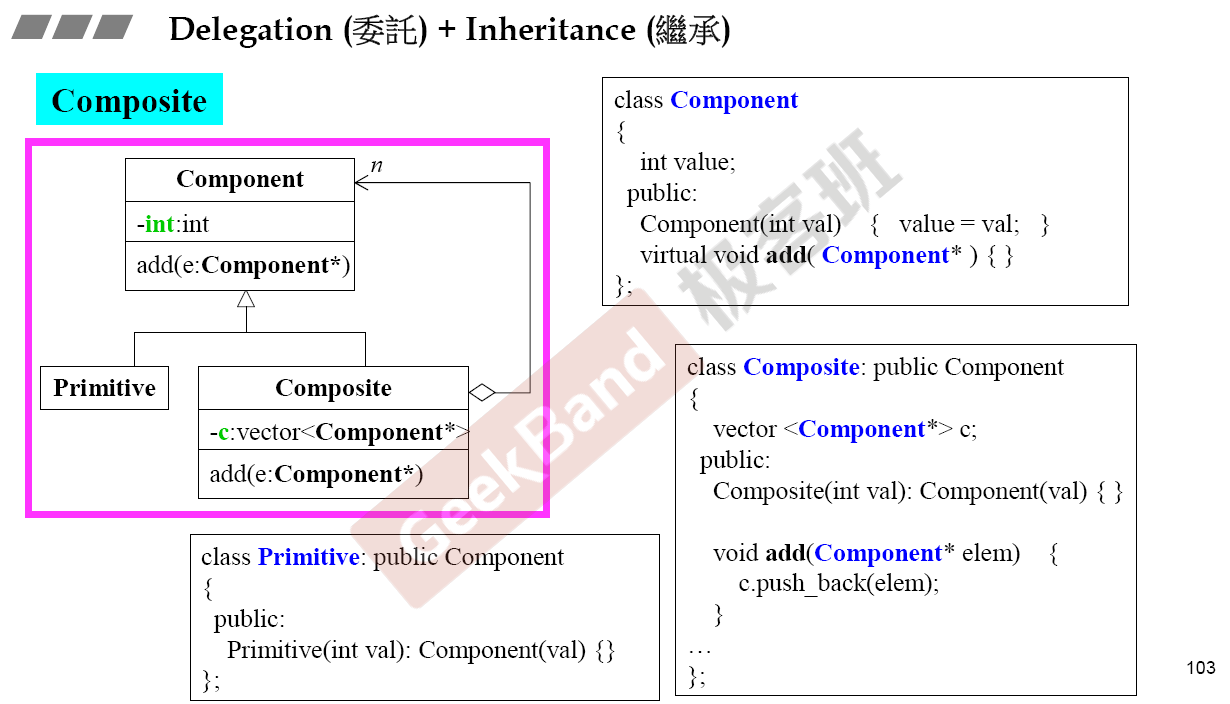
Prototype(设计模式)
力扣
类和节点:
class Name{
private:struct Node{int data;Node *next;};Node *p;
public://构造函数Name(){}//void xxx(){}
}
动态数组(vector)
由标准库封装地数组,可以扩容,缩容,比C中地 int[] 更高级
int n=7, m=8;//初始化一个空数组
vector<int> nums;//初始化一个大小为n的数组nums,默认元素都是0
vector<vector<int>> vec; //二维
vector<int> nums(n);
// 初始化,并赋值为0
vector<int> nums(n, 0);
//初始化一个元素为
nums.begin();
nums.end();
fill(nums.begin(), nums.end(), 0); // 所有空间赋值为0
// 一些函数bool empty() // nums.empty() 判断是否为空
size_type size() // nums.size() 返回数组中元素的个数(最好返回到一个int变量)
reference back() //nums.back() 返回数组最后一个元素的引用
void push_back(const value_type& val) //在数组后面插入val nums.push_back(val);
void pop_back() //nums.pop_back() 删除尾部元素# include<string>
std::string to_string(int value); # 功能:将数字常量转换为字符串; 返回值:转换好的字符串
栈(stack)
使用标准库的栈时, 应包含相关头文件,在栈中应包含头文件: #include< stack > 。定义:stack< int > s;
# #include <stack>
# 定义
stack< int > s;# 函数
s.empty() // 如果栈为空,则返回true
s.size() // 返回栈中元素个数
s.top() // 返回栈顶部元素,不删除
s.pop() // 弹出栈顶元素,但不返回其值
s.push() // 将元素压入栈顶
例:用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
class CQueue {
private:stack<int> stack1, stack2;
public:CQueue() {}void appendTail(int value) {stack1.push(value);}int deleteHead() {if (!stack2.empty()){int temp = stack2.top();stack2.pop();return temp;;}else{while(!stack1.empty()){stack2.push(stack1.top());stack1.pop();}}if (stack2.empty()){return -1;}else{int temp = stack2.top();stack2.pop();return temp;}}
};/*** Your CQueue object will be instantiated and called as such:* CQueue* obj = new CQueue();* obj->appendTail(value);* int param_2 = obj->deleteHead();*/
队列(queue)
先进先出FIFO,在队尾添加元素,在队头删除元素。
#include<queue>//定义一个整数型的队列
queue<int> q;//内部函数 类似于栈(stack)
q.empty(); //判断队列是否为空
q.size(); // 输出队列元素个数
q.pop(); //删除队列首元素但不返回其值
q.push(); //在队尾压入新元素
q.back(); //返回队列尾元素的值,但不删除该元素
q.front(); //返回队首元素的值,但不删除该元素
链表
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/// 创建每个节点的时候要用 或者 直接赋值的方式ListNode *temp = new ListNode;//单项列表反转
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/class Solution {
public:ListNode* reverseList(ListNode* head) {ListNode *pre = nullptr;ListNode *cur = head;while(cur){ListNode *temp = cur->next;cur->next = pre;pre = cur;cur = temp;}return pre;}
};// 判断节点相同 直接用 curA == curB 就可以了
字符串(string)
初始化
string s; string s = "abc";
成员函数
string 与 vector 成员函数名字很像size_t size(); // 返回字符串得长度bool empty(); // 判断是否是空的void push_back(char c); //尾部插入字符cvoid pop_back(); //删除尾部字符//str截取
string substr(size_t pos, size_t len); //返回从索引pose开始,长度为len的字符串
// s.substr(0, len)//str插入
string insert(位置,长度,插入的字符);
//s.insert(s.end(), 8, '0')// 扩充字符串s的大小
s.resize(s.size() + count * 2); //将原来的大小增加到 s.size() + count * 2// 删除第i个元素, 复杂度为n,中间有平移操作
s.erase(s.begin() + i);// 反转字符串 s.begin()为s的开头的指针, s.end()为s末尾的指针并加1.
reverse(s.begin(), s.end()); // 将字符串全部反转 区间[s.begin(), s.end()]// 交换
swap(s[i],s[j]); //替换两个元素的位置// 是否是字母,小写,大写 s.isalpha() islower(), isupper()// str转换成数字int(10进制)
int stoi (const string& str, size_t* idx = 0, int base = 10);
// str: 输入字符串 // idx从字符串的第几个开始索引 //base字符串是几进制的// 加入头文件 #include <stdlib.h>
string = "1010"
int b = stoi(str, 0, 2); //将字符串 str 从 0 位置开始到末尾的 2进制转换为十进制
int a = stoi(str); //将整个的str转换为10进制// int t0 str
string = to_string(int)
// str to int
#include<cstring>
int a = stoi(str)
自动遍历
// unordered_map<char, int> mapping;
for(auto& c : s){++mapping[it];
}
将s中的每一个字符当作一个键,值为此此字符出现的次数。
以每个c 遍历s
哈希表(unordered_map)
//初始化一个key为string, value 为 int数组 的哈希表
unordered_map<string, vector<int>> mapping;//函数 size_type size() //mapping.size() 返回键对值得个数bool empty() //mapping.empty() 是否为空size_type count(const key_type& key) //判断是否含有key 键size_type erase(const key_type& key) //清除key键// 将s中的每一个字符当作一个键,值为此此字符出现的次数。以每个c 遍历s
unordered_map<char, int> mapping;
for(auto& c : string){++mapping[it];
}// 遍历map
for (auto& iter : mappin) {iter.first; //keyiter.second; //value
}//迭代器
for (auto iter=umap.begin(); iter != umap.end(); ++iter) {iter.first; // keyiter.second; //value
}
二叉树
前,中,后序遍历!
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode(int x) : val(x), left(NULL), right(NULL) {}* };*/
#124
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。路径和 是路径中各节点值的总和。给你一个二叉树的根节点 root ,返回其 最大路径和 。
#99
给你二叉搜索树的根节点 root ,该树中的两个节点被错误地交换。请在不改变其结构的情况下,恢复这棵树。
算法小抄笔记
第一章(核心套路)
1.1 递归和迭代(二叉树)
前,中,后序遍历。 分别代表。
递归 怎末表示(画递归树)
1.2 动态规划
递归和遍历。
重叠子问题: 建立数组或者哈希表来 实现“备忘录” “DP table”等。防止计算之前计算过的操作。
最优子结构: 符合最优子结构,也就是递推关系,要相互独立。求 第11次的时候用第10次,且不会改变第10次的数据。这样就是 子结构。
状态转移: 如何从第11次 如何从之前的次数中表示。 第n次,变化的n,可以作为状态。
递归一般是 “从大到小”,“从顶至下”。 画递归树
迭代 一般从“从小到大”,“从底至顶”。
例子:斐波那契数列,凑零钱,青蛙跳台 等
1.3 回溯算法(DFS)
动态规划是回溯算法的特殊情况,当动态规划中找不到 最优子结构和状态转移(例如:全排列,N皇后问题,让遍历所有的排列顺序),这就很难找到状态转移方程。因此采用回溯算法。
实际上回溯就是遍历决策树的所有情况。考虑3个因素:
路径:已经做出的选择
选择列表: 当前可以做出的选择
结束条件: 到达决策树的底部,无法选择了
回溯算法是DFS (deep first search)
//回溯算法的基本框架//定义递归函数
void backtrack(路径, 选择列表){//一般到底部了if 满足条件: //一般是到达底部, (路径==选择列表) result.add(路径)return;//过程for 选择:选择列表:0 if 选择不合法:continue;1 做选择(加入路径) // 把当前的结果加入路径中2 backtrack(路径,选择列表) //回溯3 撤销选择(撤销路径) // 撤销1 中加入的路径。
}
1.4 BFS(广度优先)
Broad First Search! 广度优先类似于一张图,刚开始一个点,像四周扩散。 一般用 队列。来实现。每次将一个节点的扩散节点都加入队列。然后一个个遍历删除。
一般是为了解决 在搜索过程中,最小的问题,最少步数,最短距离。
框架:
// 计算从start 到 target的最小距离
int BFS(Node start, Node target){Queue<int> q; // 核心数据构造 (队列)Set<Node> visited; // 避免走回头路 是个mapq.push(start); //将起始节点加入队列visited.push(start); //观察过了int step = 0; // 记录扩散的步数while(q not empty){int sz = q.size();// 将当前队列的点进行扩散if(int i=0; i<sz; i++){Node cur = q.pop(); //弹出一个节点// 判断是否找到目标if(cur == target){return step;}// 将这个点的扩散加入队列for(Node x: cur.children){if(x in visited){continue;}q.push(x);visited.push(x); //这个点被参观过} }// 扩散次数加一step++; }
}/*
队列q核心,
visited主要是为了避免走回头路,大部分是必须的,但像二叉树这种结构,没走子节点到父节点的指针,因此可以省略visited
*/
可以考虑双向BFS等。哪个子节点少了,搜索哪个。
1.5 双指针
双指针一类是 “快慢指针”, 一类是 “左右指针”。
快慢指针:主要解决链表的问题,比如链表判断是否有环,链表中间,或者倒数第几个位置。
左右指针:主要解决数组(字符串)的问题,比如二分查找(搜索)等。
// 快慢指针 的应用
// 主要是一个快指针(一次跨一个节点),一个慢指针(一次一个节点)// 例如判断是否有环, 有环的情况下,快指针会等于慢指针。框架如下:bool hascycle(ListNode head){ListNode fast, slow;fast = head;slow = head;while(fast != nullptr && fast.next != nullptr){fast = fast.next.next; // 一次2个节点slow = slow.next; // 一次一个节点if(fast == slow){return true;}}return false;
}// 左右指针的应用 (用在已经排好序的数组上了)
// 二分查找,两数之和,反转数组。int binarySearch(int[] nums, int target){int left = 0;int right = nums.length - 1; //注意while(left <= right){int mid = left + (right - left)/2;if(nums[mid] == target){return mid;}else if (nums[mid] > target){right = mid - 1;}else if(nums[mid] < target){left = mid + 1;}}return -1;
}/*********************************************************************/
// 寻找一个数,这个数在数组里有重复,需要找到最左边的,可以加一个if条件。
int left_bound(int[] nums, int target){int left = 0;int right = nums.length - 1; //注意while(left <= right){int mid = left + (right - left)/2;else if (nums[mid] > target){right = mid - 1;}else if(nums[mid] < target){left = mid + 1;}else if (nums[mid] == target){right = mid - 1;}}if(left >= nums.length){return -1; // 这是目标比所有的值都大}if(nums[left] != target){return -1; // 数组中没有目标(1,2,4),target =3 情况}return nums[left];
}
1.6 滑动窗口
一个比较难的双指针技巧:滑动窗口技巧。
细节来讲:就是维护一个窗口,不断滑动,最终更新答案。
模板:
/* 滑动窗口算法框架 */
/* 给两个字符串S和T,请在S种找到包含T的全部字母的最短子串,如果没有则返回空,假设答案唯一 。*/// 相当于不考虑 s有 t中没有的。void slidingWindow(string s, string t){unordered_map<char, int> need, window;for(char c:t) need[c]++; //将T存入一个map种,value都是1.int left = 0; right = 0;int valid = 0;while(right < s.size()){// 将C移入窗口字符char c = s[right];// 右移窗口right++;// 进行窗口内数据的更新···; // 窗口右移更新操作// 判断左侧窗口是否要收缩while(window needs shrink){// d 是将移除窗口的字符char d = s[left];// 左移窗口left++;// 对窗口内的数据进行一系列更新 ···; // 窗口左移更新操作 }}
}
/* /* 给两个字符串S和T,请在S种找到包含T的全部字母的最短子串,如果没有则返回空,假设答案唯一 。*/ */int checkInclude(string s, string t){unordered_map<char, int> need, window;for(char c:t) need[c]++;int left,right,start,len;int valid = 0;left = 0;right = 0;start = 0;len = s.size()+1;while(right < s.size()){char c = s[right];right++;if(need.count[c]){ window[c]++; //把满足的字符插入到window中if(window[c] == need[c]){valid++; // 如果是第一次来,就把valid++;有效的字符数量}}while(valid == need.size()){ //如果有效地字符 满足了要求,此时更新左边的指针,让其往右走,看看有没有更优的选择if(right - left < len){start = left;len = right - left;}char d = s[left];left++;if(need.count(d)){if(need[d] == window[d]){valid--;}window[d]--;}}}return if(len > s.size())? ' ': s.substr(start,len);
}
代码随想录
数组:
1. 二分法 1. 基础二分法(左闭右闭, 左闭右开的区别)2. 某个数最左,最右边界,如何设计2. 快慢指针1. 数组的内存连续,比如删除重复的元素,如何空间复杂度是O(1).3. 滑动窗口1. 一般用于求某个子序列什么的(比如是否包含xx,满足xxx)2. 窗口内应该满足什么条件,窗口右边如何增加,窗口左边如何增加。
链表:
-
链表的定义 如何定义一个链表:
// definition for single-linked list struct ListNode{int val;ListNode* next;ListNode() : val(0), next(nullptr){}ListNode(int x) : val(x), next(nullptr){} };// 链表不能有size ,索引起来很慢,但是增删方便 -
虚拟头节点(不用另外处理头节点了)
ListNode* dummy = new ListNode(); dummy->next = head; -
双指针法
反转链表,删除倒数元素
-
迭代法
反转链表。
哈希表
-
哈希表基础
#include<unordered_map> // 头文件 unordered_map<int, int> map1; // key 为int, val也是int// 内联函数 size_type size(); //mapping.size() 返回键对值得个数bool empty(); //mapping.empty() 是否为空size_type count(const key_type& key); //判断是否含有key 键size_type erase(const key_type& key); //清除key键// 将string 或者 vector 加入到哈希表中 unordered_map<char, int> mapping; for(auto& c : string){++mapping[it]; }// 哈希表遍历 // 遍历map for (auto& iter : mappin) {iter.first; //keyiter.second; //value }
字符串
- 字符串的存储和数组类似
连续,删除麻烦。
- 双指针
由于是连续的存储,删除起来麻烦。在增,删方面可以考虑双指针,类似于数组。
反转的时候也可以考虑双指针。如果要求空间复杂度,第一个想到的就是双指针。
-
反转的灵活运用
有些东西 可以通过反转实现,或者反转再反转。得到想要的结果,比如 单词倒叙等。
-
KMP算法,
匹配子串问题(待学习)。
栈与队列
-
栈与队列的定义
stack<int> stack1; queue<int> stack1; -
栈与队列互构
```c++
// 两个栈->一个队列
// 一个队列-> 栈(用循环的操作)
```
-
栈相关的题目
- 对对碰
- 克服重复
- 判断括号
- 递归的思想
-
队列相关
- 队列相关比较难比如(滑动窗口最大值,前K个高频),用的都是特殊的数据结构。
lptr){}
ListNode(int x) : val(x), next(nullptr){}
};
// 链表不能有size ,索引起来很慢,但是增删方便
- 队列相关比较难比如(滑动窗口最大值,前K个高频),用的都是特殊的数据结构。
-
虚拟头节点(不用另外处理头节点了)
ListNode* dummy = new ListNode(); dummy->next = head; -
双指针法
反转链表,删除倒数元素
-
迭代法
反转链表。
哈希表
-
哈希表基础
#include<unordered_map> // 头文件 unordered_map<int, int> map1; // key 为int, val也是int// 内联函数 size_type size(); //mapping.size() 返回键对值得个数bool empty(); //mapping.empty() 是否为空size_type count(const key_type& key); //判断是否含有key 键size_type erase(const key_type& key); //清除key键// 将string 或者 vector 加入到哈希表中 unordered_map<char, int> mapping; for(auto& c : string){++mapping[it]; }// 哈希表遍历 // 遍历map for (auto& iter : mappin) {iter.first; //keyiter.second; //value }
字符串
- 字符串的存储和数组类似
连续,删除麻烦。
- 双指针
由于是连续的存储,删除起来麻烦。在增,删方面可以考虑双指针,类似于数组。
反转的时候也可以考虑双指针。如果要求空间复杂度,第一个想到的就是双指针。
-
反转的灵活运用
有些东西 可以通过反转实现,或者反转再反转。得到想要的结果,比如 单词倒叙等。
-
KMP算法,
匹配子串问题(待学习)。
栈与队列
-
栈与队列的定义
stack<int> stack1; queue<int> stack1; -
栈与队列互构
```c++
// 两个栈->一个队列
// 一个队列-> 栈(用循环的操作)
```
- 栈相关的题目
- 对对碰
- 克服重复
- 判断括号
- 递归的思想
- 队列相关
- 队列相关比较难比如(滑动窗口最大值,前K个高频),用的都是特殊的数据结构。