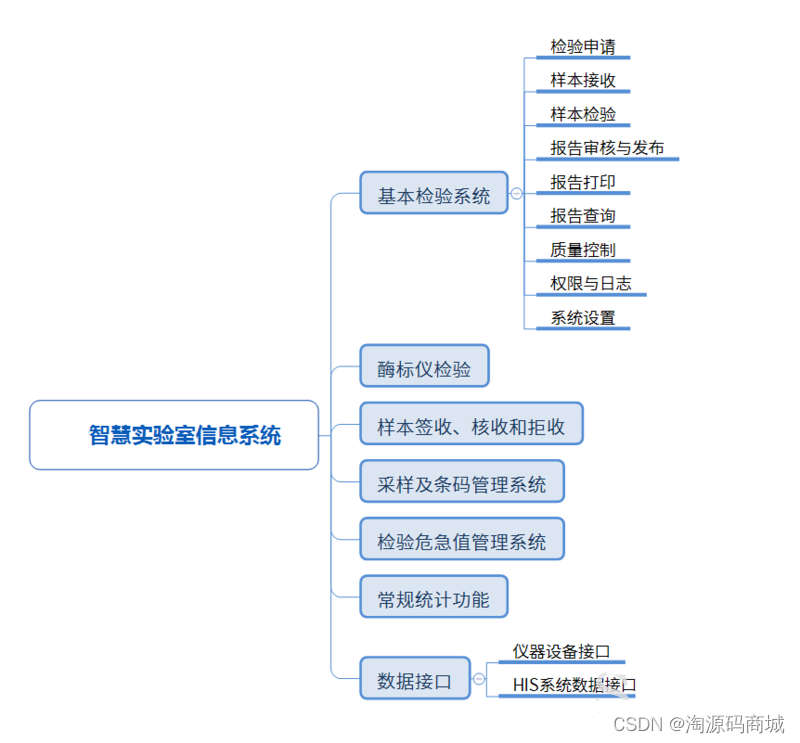
前言
我们在开发网页时,经常会遇到一种情况——在一个页面对页面初始状态进行了修改(如已请求到的数据、表单数据、滚动高度等等),跳转到另外一个页面之后再返回到原页面(路由回退),原页面需要保持原先的状态不变。但如果不做额外处理,往往会出现原页面历史状态丢失、被重置为初始状态的情况。
SPA 与 MPA
1. SPA(单页应用)
这种情况常见会出现在 SPA 中,因为 SPA 是使用单页来模拟多页,页面跳转时并没有请求一个新的页面应用,所以 SPA 在路由跳转时会丢失历史页面的普通状态。
2. MPA(多页应用)
是否在 MPA 中就不会出现这种情况了呢?也不尽其然。
在多年以前,互联网上全都是些简单的 MPA 应用,一个页面就是一个 html 文件,一个网站就是一组 html。而一个页面的所有数据,就都在这个 html 文件(或者其他资源文件)中,在浏览器获取到 html 等资源文件的时候,也就随之获取到了数据。这种情况下,不会出现路由跳转导致丢失数据的情况,而滚动高度会被浏览器保存,所以只有一些表单等用户输入的信息会丢失。
但是,随着前端技术的发展和潮流的变化,更多复杂的情况出现了,比如无限下拉滚动加载数据,比如 h5 移动端常见的数据使用 ajax 加载,带来了更多的变化。
数据使用 ajax 加载,意味着数据与 html 的完全解耦。这种情况下,即使是 MPA ,也会出现路由跳转导致数据丢失的情况。
因为这种情况在移动端很常见,部分 Android 浏览器与大多数 IOS 浏览器针对这一现象做了额外的优化,在路由跳转后仍保留原页面资源,这样就避免了路由跳转导致原页面数据丢失。
各平台情况
1. PC 端
各种 PC 端浏览器历史悠久,基本都没有做额外优化,只会保存滚动高度。
但是对于这种情况,参考主流网站与用户习惯,页面往往不会直接跳转(window.location.href),而是打开新的标签页(window.open),这样问题就不存在了。
2. 移动端
上面也提到了,部分 Android 浏览器与大多数 IOS 浏览器针对这一现象做了额外的优化,在路由跳转后仍保留原页面资源,这样就避免了路由跳转导致原页面数据丢失。
3. 移动端 APP 内 WebView
参考主流 APP,在 APP 内使用 WebView 打开网页时,往往会在页面跳转时,新开一个 WebView。这样通过打开多个 WebView,来模拟原生页面路由跳转的体验。
总结
针对 MPA ,大部分情况下有简单的解决方法/平台自动优化,而 SPA 在各平台路由跳转都会丢失状态。所以我们主要分析处理 SPA 的问题。
SPA 解决思路
1.全局数据:将页面数据全都放在全局,这样不论页面如何跳转,数据都不会丢失。1.使用 redux/mobx 等状态管理方案2.数据保存于全局变量中
2.页面长留(keep-alive): 对于 SPA 应用,可以在页面跳转时,不卸载页面组件,而是将页面设置为不可见,等到回退到该页面时将页面设置为可见。1.react-keep-alive/react-keeper 等方案2.Vue 的 keep-alive 组件
3.存取数据:页面跳转时将数据储存起来,等到回退到该页面时将数据取出放入状态中。页面长留方案
react-keep-alive
- 不基于 React Router,因此可以在任何需要缓存的地方使用它。* 因为并不是使用
display: none | block来控制的,所以可以使用动画。* 通过 React.createPortal API 实现了这个效果。react-keep-alive有两个主要的组件<Provider>和<KeepAlive>;<Provider>负责保存组件的缓存,并在处理之前通过React.createPortalAPI 将缓存的组件渲染在应用程序的外面。缓存的组件必须放在<KeepAlive>中,<KeepAlive>会把在应用程序外面渲染的组件挂载到真正需要显示的位置。react-keeper
实现基于重写路由库,提供一套新的 React Router
存取数据方案
由于业务上的需求,我们实现了一套基于存取数据的页面状态保存方案:
存取数据有以下问题需要思考:
1.如何建立页面和数据的映射关系?2.数据的垃圾回收机制?其实这两个问题有一定的交集,如果我们建立了页面和数据的映射关系,针对目前路由的状态,如果某个页面并不是可后退到的页面,就可以清除该页面的数据。
1. 页面的 key
我们可以发现,React Router 在路由跳转时,对每一个页面(除首页外)都有唯一的 window.history.state.key ,所以可以使用该值作为每个页面和该页面数据的 key,将数据存放在一个全局的 map 中。
2. 历史路由栈
对于浏览器的路由栈(history 对象),我们并没有办法直接获取到其中的详细路由信息。那么怎么办呢?我们可以用 js 维护一份本应用内的历史路由栈。
基于 react-router-dom 的 history:
- 初始化时:将当前页面的 historyInfo 推入 historyStack* 使用 history.listen,当路由变化时,在 historyStack 中入栈出栈。* ⚠️注意的问题1.history.listen 无法区分浏览器的前进/后退按钮操作,都会被识别为 POP 后退解决方案:通过 historyStack 中有无当前页面的 key 来判断前进/后退
history.listen((historyInfo: HistoryInfo, historyAction: HistoryAction) => {// ...if (historyAction === 'POP') {// 点击浏览器前进后退时,historyAction均为POP,所以要判断是否是前进let isGoForward = false;if (historyInfo.key) {const have = historyStack.find((h) => h.key === historyInfo.key);if (!have) {isGoForward = true;}}if (isGoForward) {historyStack.push(historyInfo);} else {historyStack.pop();}}// ...});``````2.点击浏览器刷新按钮进行刷新操作,会导致 app 重启,丢失路由栈数据解决方案:页面刷新时,history.state.key 不会变。所以在卸载时储存 historyStack 数据,初始化时取数据,并用 history.state.key 判断是否是刷新。(为什么不直接用 history.state 储存 historyStack 数据?因为unload事件中无法使用 history.replaceState 修改 history.state,只能在 beforeunload 事件中;而在 ios Safari 中,beforeunload 事件无法正常生效)/** * 处理浏览器刷新导致 historyStack 丢失的问题 */if (isBrowser) {// 取数据try {const storageHistoryStack = JSON.parse(sessionStorage.getItem(HISTORY_STACK) || ‘’,) as HistoryInfo[] | undefined;const length = storageHistoryStack?.length;if (length &&length > 1 &&storageHistoryStack[length - 1].key === getPageKey()) {for (const historyInfo of storageHistoryStack) {historyStack.push(historyInfo);}}} catch (e) {}// 页面离开时存数据window.addEventListener(‘unload’, () => {if (historyStack.length > 1) {sessionStorage.setItem(HISTORY_STACK,JSON.stringify(historyStack, [‘pathname’, ‘search’, ‘key’]),);}});}// 未获取到刷新前的 historyStack,正常初始化if (historyStack.length < 1) {historyStack.push({pathname: window.location.pathname.slice(baseUrl.length),search: window.location.search,key: getPageKey(),});} ```3. 数据回收
- 基于历史路由栈,因为都是使用 pageKey,从 pageDataMap 中获取所有的 pageKey,再对比 历史路由栈 historyStack 中的 key,得到 historyStack 中不存在的 key ,从 pageDataMap 中清除对应数据* 回收时机:当页面后退或者替换时( POP 和 REPLACE),意味着会有页面数据需要被回收4. 其他
- 针对我们项目需要,还融合了类似于 redux 的状态管理方案* 额外的对滚动高度的恢复为什么使用 SPA 模拟方案而不直接使用多层 webview?
1.主要原因:应用内存占用。在我们的业务场景中,经常出现较深的路由层级,线上数据的最深层级可达 10,如果使用 webview 会占用较大内存,导致 crash 率飞速上升2.其他原因:大量数据需要同步、端外页面跳转回退的兼容性总结
我们还是更倾向于使用 MPA ,MPA 对于各平台的情况,都有着简单的处理方式来解决路由跳转时的页面状态保存这一问题。
飞速上升2.其他原因:大量数据需要同步、端外页面跳转回退的兼容性总结
我们还是更倾向于使用 MPA ,MPA 对于各平台的情况,都有着简单的处理方式来解决路由跳转时的页面状态保存这一问题。
使用 SPA 并处理路由跳转时的页面状态保存,常见的使用 redux 等状态管理方案,而上文介绍的存取数据的方案提供了另外一种探索,以供参考。









![[仅需1步]企业微信群机器人[0基础接入][java]](https://img-blog.csdnimg.cn/a8ad3cbdc7144d879c43793d2ea72211.png)