传统的向量空间模型(VSM)假设特征项之间相互独立,这与实际情况是不相符的,为了解决这个问题,可以采用文本的分布式表示方式(例如 word embedding形式),通过文本的分布式表示,把文本表示成类似图像和语音的连续、稠密的数据。
这样我们就可以把深度学习方法迁移到文本分类领域了。基于词向量和卷积神经网络的文本分类方法不仅考虑了词语之间的相关性,而且还考虑了词语在文本中的相对位置,这无疑会提升在分类任务中的准确率。 经过实验,该方法在验证数据集上的F1-score值达到了0.9372,相对于原来业务中所采用的分类方法,有20%的提升。

1. 文本的分布式表示:词向量(word embedding)
1.1 介绍
word embedding文本分布式表示方法则是深度学习方法的重要基础
文本的分布式表示(Distributed Representation)的基本思想是将每个词表示为n维稠密,连续的实数向量。
分布式表示的最大优点在于它具有非常强大的表征能力,比如n维向量每维k个值,可以表征k的n次方个概念。
事实上,不管是神经网络的影层,还是多个潜在变量的概率主题模型,都是在应用分布式表示。下图的神经网络语言模型(NNLM)采用的就是文本分布式表示。而词向量(word embedding)是训练该语言模型的一个附加产物,即图中的Matrix C。

Mikolov(2013)发布文章提到词向量的构造方法并发布了简单的word2vec工具包,在语义维度上得到了很好的验证,极大的推动了文本分析的进程。
文本的表示通过词向量的表示方法,把文本数据从高纬度稀疏的神经网络难处理的方式,变成了类似图像、语言的连续稠密数据,这样我们就可以把深度学习的算法迁移到文本领域了。
其中涉及CBOW和Skip-gram两个模型
CBOW:输入特定词的上下文向量,输出是所有词的softmax的概率,训练的目标是使得特定词的softmax概率最大。处理效果更快。
Skip-Gram:输入特定词,输出是所有词的softmax概率,训练目标是使得特定词上下文的对应的词的出现概率最大。经验上一般选择Skip-Gram模型,对于生僻词的处理效果较好。
1.2 模型优化:hierarchical softmax 和negative sampling
因为基于word2vec框架进行模型训练要求语料库非常大,这样才能保证结果的准确性,但随着预料库的增大,随之而来的就是计算的耗时和资源的消耗。那么有没有优化的余地呢?比如可以牺牲一定的准确性来加快训练速度。
hierarchical softmax
该模型使用二叉树来表示词汇表中的所有单词。V字必须是树的叶子单位。可以证明有V−1个内单元。对于每个叶单元,存在从根到该单元的唯一路径;这条路径用来估计由叶单元表示的单词的概率。参见图中的示例树。
这种方法的主要优点是不需要评估神经网络中的W个输出节点来获得概率分布,而只需要评估大约log2(W)个节点。


分层softmax所使用的树结构对性能有相当大的影响。Mnih和Hinton探索了许多构建树形结构的方法,以及对训练时间和最终模型精度的影响。分层softmax使用二叉霍夫曼树,因为它为频繁单词分配短代码,从而快速训练。之前已经观察到,根据频率将单词分组在一起作为一种非常简单的基于神经网络的语言模型加速效果很好。
negative sampling
分层softmax的另一种替代方法是噪声对比估计(Noise contrast Estimation, NCE),该方法由Gutmann和Hyvarinen提出,并由Mnih和Teh应用于语言建模。NCE假设一个好的模型应该能够通过逻辑回归将数据与噪声区分开来。
因为每次计算全量的负样本计算量比较大,因此进行了负采样,负采样之后对应的损失函数为:

基于层次softmax或者negative sampling优化的cbow或者skip-gram模型,输出的词向量应该是输入层到隐藏层之间的词向量
1.3 模型训练
model = Word2Vec(sentences=topics_list, iter=5, size=128, window=5, min_count=0, workers=10, sg=1, hs=1, negative=1, seed=128, compute_loss=True)其对应的模型参数有很多,主要的有:sentences:训练模型的语料,是一个可迭代的序列corpus_file:表示从文件中加载数据,和sentences互斥size:word的维度,默认为100,通常取64、128、256等;较大的size值需要更多的训练数据,但可以产生更好(更准确)的模型。 合理的size数值介于在几十到几百之间。 如果你拥有的数据较少,那就把维度值设置小一点,这将在一定程度上减少模型的过拟合,尽量提高模型的表现效果。window:滑动窗口的大小,默认值为5。当前词和预测词之间的最大距离,如果设得较小,那么模型学习到的是词汇间的组合性关系(词性相异),比如“苹果”和“好红”,“主席”和“伟大”,后者对前者是一种修饰关系;如果设置得较大,会学习到词汇之间的聚合性关系(词性相同),比如“伟大”和“注明”、“可爱”和“卡哇伊”。如果文本够大可以设置的大一点如8~10。min_count:word次数小于该值被忽略掉,默认值为5seed:用于随机数发生器workers:使用多少线程进行模型训练,默认为3iter: i模型训练时在整个训练语料库上的迭代次数,假如参与训练的文本量较少,就需要把这个参数调大一些.
默认值为5。min_alpha=0.0001sg:1 表示 Skip-gram;0 表示 CBOW;默认为0。其中Skip-gram适合复杂数据类型hs:1 表示 hierarchical softmax; 0 表示negative softmax;默认为0。hierarchical softmax通常比负采样(Negative Sampling)方法需要更多的计算资源和时间。negative:0 表示不采用,1 表示采用,建议值在 5-20 表示噪音词的个数,默认为51.4 效果衡量
当训练Word2Vec模型时,将其中的参数compute_loss设置为True,则可计算训练Word2Vec模型时所得到的损失(Training Loss),它可以衡量模型的训练质量。
实例化并训练Word2Vec模型:
model_with_loss = gensim.models.Word2Vec(sentences, min_count=1, compute_loss=True, hs=0, sg=1, seed=2019) # 获得训练的损失值
training_loss = model_with_loss.get_latest_training_loss()
print(training_loss)1.5 一起用于分类的模型
1.5.1 传统的文本分类方法:
- 基本上大部分机器学习方法都在文本分类领域有所应用。
- 例如:Naive Bayes,KNN,SVM,集合类方法,最大熵,神经网络等等。
1.5.2 深度学习文本分类方法
- 卷积神经网络(TextCNN)
- 循环神经网络(TextRNN)
- TextRNN+Attention
- TextRCNN(TextRNN+CNN)
1.5.3 Word2vec+CNN
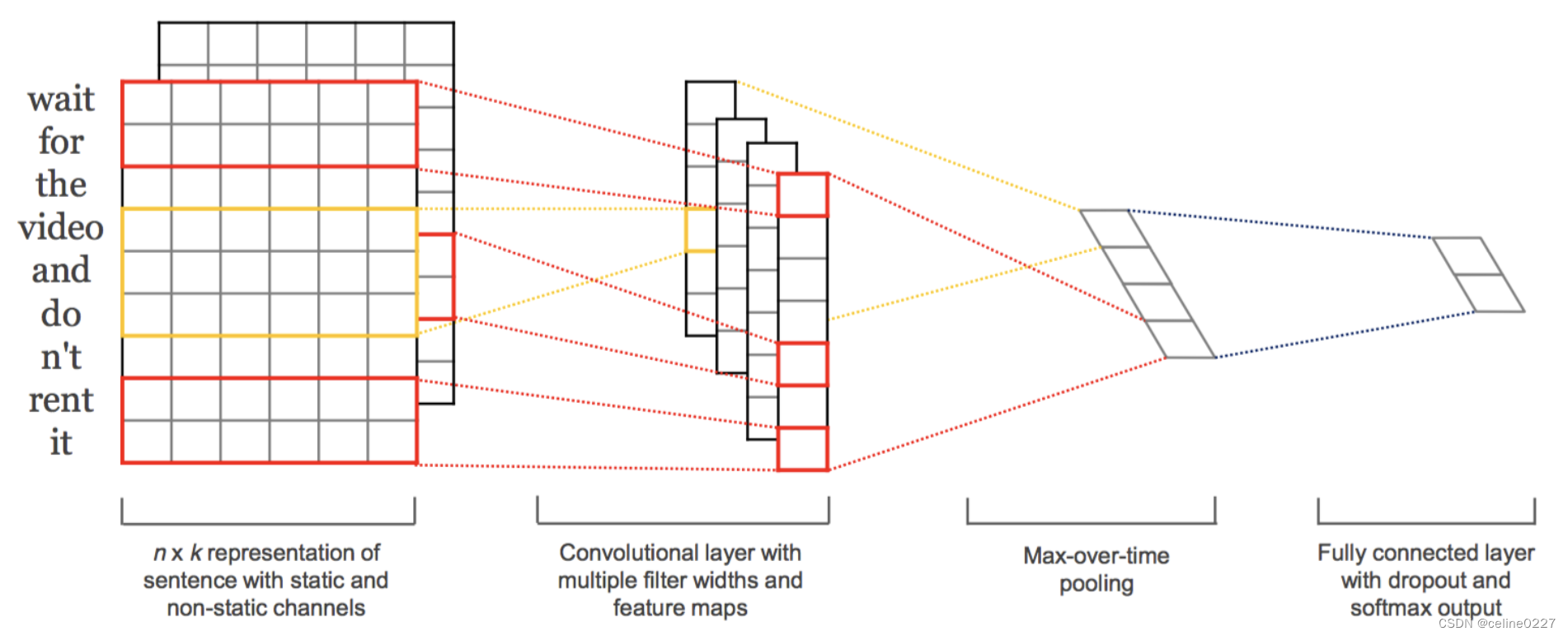
A. 模型结构
在短文本分析任务中,由于句子句长长度有限、结构紧凑、能够独立表达意思,使得CNN在处理这一类问题上成为可能,主要思想是将ngram模型与卷积操作结合起来。参考Chen (2015)进行分析。
A1. 输入层
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数。
也可以先通过word2vec生成词向量。
A2. 第一层卷积层
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h ×k ,其中 h 表示纵向词语的个数,而 k 表示word vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。
A3. 池化层
接下来的池化层,文中用了一种称为Max-over-timePooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值,即一个一维的向量。
A4. 全连接+softmax层
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。
B. 训练方案
在倒数第二层的全连接部分上使用Dropout技术,Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了,它是为了防止模型过拟合。同时对全连接层上的权值参数给予L2正则化的限制,这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
在样本处理上使用minibatch方式来降低一次模型拟合计算量,使用shuffle_batch的方式来降低各批次输入样本之间的相关性(在机器学习中,如果训练数据之间相关性很大,可能会让结果很差、泛化能力得不到训练、这时通常需要将训练数据打散,称之为shuffle_batch)。
C. 参数调整——参考Zhang and Wallace (2015)
C1.调参实验结论:
- 由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,造成模型在数据集上的结果有一定的浮动,如准确率(accuracy)能达到1.5%的浮动,而AUC则有3.4%的浮动;
- 词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
- Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
- Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
- 1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
- 正则化的作用微乎其微。
C2.建议
- 使用non-static版本的word2vec或者GloVe要比单纯的one-hot representation取得的效果好得多;
- 为了找到最优的过滤器(Filter)大小,可以使用线性搜索的方法。通常过滤器的大小范围在1-10之间,当然对于长句,使用更大的过滤器也是有必要的;
- Feature Map的数量在100-600之间;
- 可以尽量多尝试激活函数,实验发现ReLU和tanh两种激活函数表现较佳;
- 使用简单的1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式;
- 当发现增加Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率;
- 为了检验模型的性能水平,多次反复的交叉验证是必要的,这可以确保模型的高性能并不是偶然。
D. 做文本分类的例子
1.6 优缺点
常规的优缺点就不多赘述,强调一下容易忽略的点:
Word2Vec可以在线训练,当有了新的数据,就可以直接在原来已经训练好的模型上接着训练,而不用从头再来,后续可以不断加入新的语句(经过文本预处理)来提升模型的表现效果
word2vec缺点:只学习位置信息,不学习语义信息。word2vec存在最大的问题就是由于它是静态词向量表示导致不能表示一词多义的情况,举个例子“苹果”一词,在果蔬的句子中表示的就是水果的含义,要是在高科技产品句子中表示的就是“苹果”公司。但是word2vec的静态词向量表示只能表示同一种形式。
2. BERT
2.1 介绍
BERT 代表 Transformers 的双向编码器表示,使它们能够理解复杂的细微差别和上下文依赖性,从而使人类交流变得丰富而有意义。
为什么BERT很重要?想象一句话:“她小提琴拉得很漂亮。”传统的语言模型会从左到右处理这个句子,忽略了乐器(“小提琴”)的身份影响整个句子的解释这一关键事实。然而,BERT 明白单词之间的上下文驱动关系在推导含义方面发挥着关键作用。它抓住了双向性的本质,使其能够考虑每个单词周围的完整上下文,彻底改变了语言理解的准确性和深度。
2.2 BERT 是如何工作的?
BERT 的核心由称为 Transformer 的强大神经网络架构提供支持。该架构采用了一种称为自注意力的机制,允许 BERT 根据每个单词的前后上下文来衡量其重要性。这种上下文意识使 BERT 能够生成上下文化的词嵌入,即考虑单词在句子中的含义的表示。这类似于 BERT 阅读并重新阅读句子以深入了解每个单词的作用。
BERT 需要以它可以理解的方式准备和结构化文本。我们将探讨 BERT 预处理文本的关键步骤,包括标记化、输入格式和掩码语言模型 (MLM) 目标。
2.2.1 标记化:将文本分解为有意义的块
BERT 需要将文本分解为称为标记的更小的单元。但这里有一个不同之处:BERT 使用 WordPiece 标记化。它将单词分成更小的部分,比如把“running”变成“run”和“ning”。这有助于处理棘手的单词,并确保 BERT 不会迷失在不熟悉的单词中。
示例:原文:“ChatGPT 令人着迷。” WordPiece 标记:[“Chat”、“##G”、“##PT”、“is”、“fascinating”、“.”]
2.2.2 输入格式:为 BERT 提供上下文
BERT 喜欢上下文,我们以 BERT 理解的方式格式化令牌。我们在开头添加特殊标记,例如 [CLS](代表分类),在句子之间添加 [SEP](代表分离)。我们还分配分段嵌入来告诉 BERT 哪些标记属于哪个句子。
示例:原文:“ChatGPT 令人着迷。”格式化标记:[“[CLS]”、“Chat”、“##G”、“##PT”、“is”、“fascinating”、“.”、“[SEP]”]
2.2.3 掩码语言模型 (MLM) 目标:教授 BERT 上下文
BERT 的秘密在于它理解双向上下文的能力。在训练过程中,句子中的一些单词被屏蔽(用 [MASK] 替换),BERT 学习从上下文中预测这些单词。这有助于 BERT 掌握单词前后的相互关系。
示例:原句:“猫在垫子上。”蒙面句子:“[面具]在垫子上。”
2.2.4 BERT 的架构变化:寻找合适的方案
BERT 有不同的风格,例如 BERT-base、BERT-large 等等。这些变体具有不同的模型大小和复杂性。选择取决于您的任务要求和您拥有的资源。更大的模型可能表现更好,但它们也需要更多的计算能力。
2.3 Self-Attention:BERT 的超能力
对于 BERT 来说。它会查看句子中的每个单词,并根据其他单词的重要性决定应给予多少关注。这样,BERT 就可以专注于相关单词,即使它们在句子中相距很远。
2.3.1 多头注意力:团队合作技巧
BERT 不仅仅依赖于一种观点;它使用多个注意力“头”。将这些负责人视为专注于句子各个方面的不同专家。这种多头方法帮助 BERT 捕获单词之间的不同关系,使其理解更丰富、更准确。
2.3.2 BERT 中的注意力:上下文魔法
BERT 的注意力不仅仅局限于单词之前或之后的单词。它考虑了两个方向!当 BERT 读取一个单词时,它知道它的邻居。通过这种方式,BERT 生成考虑单词整个上下文的嵌入。
2.4 BERT的训练过程
BERT 训练过程包括其预训练阶段、掩码语言模型 (MLM) 目标和下一句预测 (NSP) 目标。
2.4.1 预训练阶段:知识基础
BERT 的旅程从预训练开始,它从大量文本数据中学习。想象一下向 BERT 展示数百万个句子并让它预测缺失的单词。这项练习有助于 BERT 建立对语言模式和关系的扎实理解。
2.4.2 掩码语言模型 (MLM) 目标:填空游戏
在预训练期间,BERT 会得到一些带有掩码(隐藏)单词的句子。然后,它尝试根据周围的上下文来预测那些被屏蔽的单词。这就像填空游戏的语言版本。通过猜测缺失的单词,BERT 可以了解单词之间的相互关系,从而实现其上下文的出色表现。
2.4.3 下一个句子预测(NSP)目标:掌握句子流程
BERT 不仅能理解单词,还能理解单词。它掌握句子的流畅性。在 NSP 目标中,训练 BERT 来预测文本对中一个句子是否在另一个句子之后。这有助于 BERT 理解句子之间的逻辑联系,使其成为理解段落和较长文本的大师。
2.5 BERT 的嵌入
BERT 的强大之处在于它能够以捕获特定上下文中单词含义的方式表示单词。BERT 的嵌入,包括其上下文词嵌入、WordPiece 标记化和位置编码。
2.5.1 词嵌入与上下文词嵌入
将词嵌入视为词的代码词。 BERT 通过上下文词嵌入更进一步。 BERT 不是为每个单词只使用一个代码字,而是根据句子中的上下文为同一个单词创建不同的嵌入。这样,每个单词的表示就更加细致入微,并受到周围单词的影响。
2.5.2 WordPiece 标记化:处理复杂词汇
BERT 的词汇就像一个由称为子词的小块组成的拼图。它使用 WordPiece 标记化将单词分解为这些子词。这对于处理又长又复杂的单词以及处理以前从未见过的单词特别有用。
2.5.3 位置编码:导航句子结构
由于 BERT 以双向方式读取单词,因此它需要知道每个单词在句子中的位置。位置编码被添加到嵌入中,以赋予 BERT 空间感知能力。这样,BERT 不仅知道单词的含义,还知道它们在句子中的位置。
2.6 代码实现
参考文献:
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26.
Rong, X. (2014). word2vec parameter learning explained. arXiv preprint arXiv:1411.2738.
Chen, Y. (2015). Convolutional neural network for sentence classification (Master's thesis, University of Waterloo).
Zhang, Y., & Wallace, B. (2015). A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification. arXiv preprint arXiv:1510.03820.
Sun, C., Qiu, X., Xu, Y., & Huang, X. (2019). How to fine-tune bert for text classification?. In Chinese computational linguistics: 18th China national conference, CCL 2019, Kunming, China, October 18–20, 2019, proceedings 18 (pp. 194-206). Springer International Publishing.