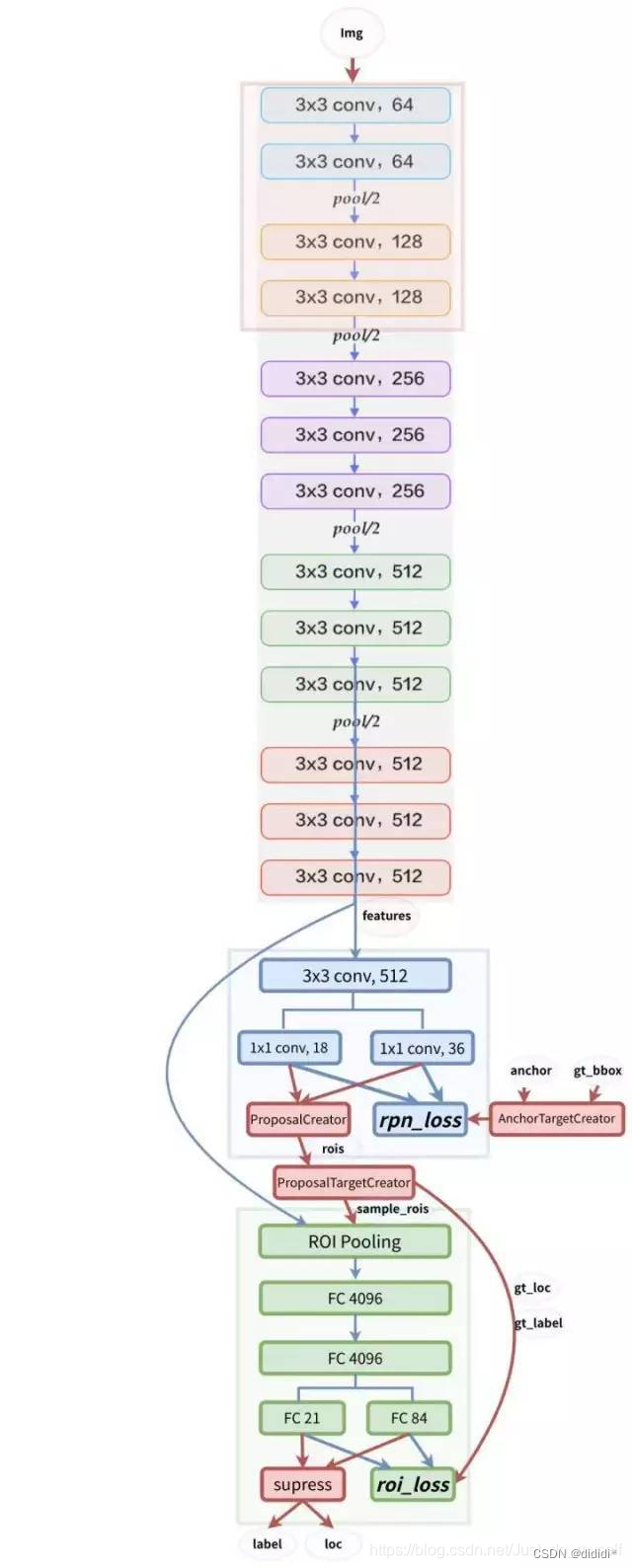
全连接层太大
导致占用内存、占用计算带宽、很容易过拟合
NiN块
1.一个卷积层后跟着两个全连接层
2.步幅1,无填充,输出形状跟卷积层输出一样
3.起到全连接层的作用
NiN架构
1.无全连接层
2.交替使用NiN块和步幅为2的最大池化层,逐步减小高宽和增大通道数
3.最后使用全局平均池化层得到输出,其输入通道数是类别数
总结
1.NiN块使用卷积层加两个1X1卷积层,后者对每个像素增加了非线线性
2.NiN使用全局平均池化层来替代VGG和AlexNet中的全连接层,不容易过拟合,更少的参数个数
NiN代码实现
NiN块(定义函数)
import torch
from torch import nn
from d2l import torch as d2ldef nin_block(in_channels, out_channels, kernel_size, strides, padding):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
NiN模型
net = nn.Sequential(nin_block(1, 96, kernel_size=11, strides=4, padding=0),nn.MaxPool2d(3, stride=2),nin_block(96, 256, kernel_size=5, strides=1, padding=2),nn.MaxPool2d(3, stride=2),nin_block(256, 384, kernel_size=3, strides=1, padding=1),nn.MaxPool2d(3, stride=2),nn.Dropout(0.5),# 标签类别数是10nin_block(384, 10, kernel_size=3, strides=1, padding=1),nn.AdaptiveAvgPool2d((1, 1)),# 将四维的输出转成二维的输出,其形状为(批量大小,10)nn.Flatten())
创建一个数据样本来查看每个块的输出形状。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Sequential output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Sequential output shape: torch.Size([1, 384, 12, 12])
MaxPool2d output shape: torch.Size([1, 384, 5, 5])
Dropout output shape: torch.Size([1, 384, 5, 5])
Sequential output shape: torch.Size([1, 10, 5, 5])
AdaptiveAvgPool2d output shape: torch.Size([1, 10, 1, 1])
Flatten output shape: torch.Size([1, 10])
使用Fashion-MNIST来训练模型。
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.786, train acc 0.733, test acc 0.738
1070.3 examples/sec on cuda:0