背景
软件工程里一个重要的指标就是“可用的软件”,敏捷宣言里也同样告诉我们“工作的软件高于详尽的文档”,那“可用的软件”、“工作的软件”意味着什么呢?在我的理解里,可以经历用户 “千锤百炼”的软件就是一个“可用的软件”。曾经听到过这样的说法:“一个有Bug的软件怎么能叫软件呢?”虽然这话在我们业内人士听起来有些可笑,但是这就是使用软件用户最真实的需求。所以如何在提高代码质量,最大程度地减少软件中的Bug同时,平衡软件迭代速度与交付效率是我今天想跟大家讨论的问题。
我有幸在两种完全不同风格的项目上进行过交付,让我们且称之为项目A和项目B。
项目A是一个客户为主导的巨大项目组,管理为明确纵向层级管理,横向开发团队来自于不同的供应商,并且采用瀑布式开发,由另一个事业部进行测试反馈,部门墙极其严重。
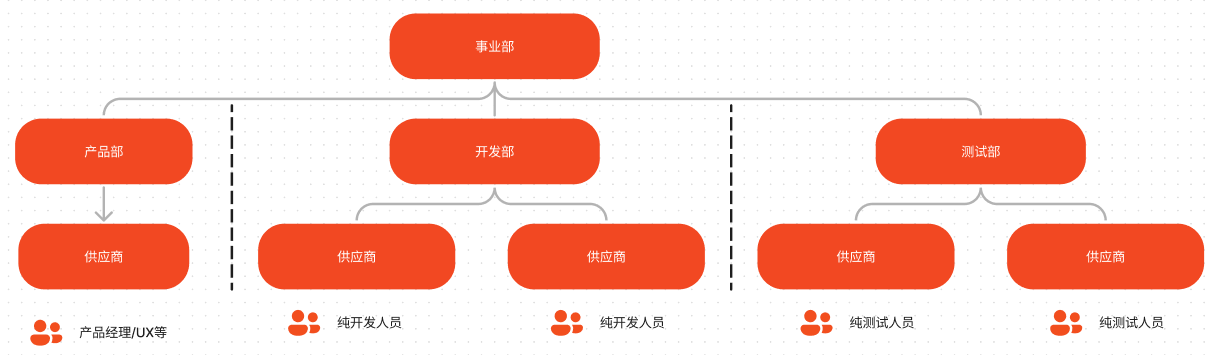
项目B则是一个由业务主导,每个敏捷团队有对应相关的业务领域,客户则是和供应商共同组成一个个敏捷团队,共同达成业务目标。

好了,完成了简单的背景介绍,我就要来说说下面的故事了。
故事
总览
首先,假设我们所需要达到的目标是由一个个大大小小功能(颜色模组)组成一个完整的软件,为了达到我们的交付目标,我们需要将每个功能进行开发,测试,将功能模块进行累加,最终获得一个完整而达标的软件。

同时两个项目都使用了大致相同的开发流程,为了保证质量,项目中都有基础的代码审计,CI/CD,应用测试,用户测试,等基本质量保证,软件开发的基础流程如下图。

在这种基础流程都相近的情况下,每个环节在不同架构下执行的的方式却有巨大的差异。
在讨论项目A的流程前,让我们先看看我们熟知的敏捷开发是怎么保证质量的:
项目B的情况
项目b的每一个小敏捷团队将业务需求从路径图(Roadmap)拆解下来,落到各大的业务功能的Epic中,再拆解成具有小的业务价值的用户故事,最后再落到每个具有开发意义的任务,注意,这里提的一直是业务价值,我们还没有开始讨论如何进入开发。
Epic 更多是独立且较大的目标,用于我们识别在关键时间点需要实现的大型业务目标。而用户故事则是一个简短的描述、一个用于表达用户或客户的需求的角色和一个用于描述需求的价值或期望结果的价值陈述,在用户故事中比较关键描述是关于此价值点的**“静态““动态”与“非常态**“,静态更多的是对价值点的描述,在To C中往往是静态设计图(UI)的描述,动态则是交互,系统间的交互或者功能的用户旅程(UX),而非常态则是描述系统在错误或者误差情况下的表现,以确保当前的价值点在绝大多数情况下得以运行(AC)。最终用户故事将被团队中的技术领导拆解成可以单独执行的开发任务,最终没个独立的开发任务可以由不同的开发人员执行。
在一个大型的价值目标被拆解成了Epic->用户故事->开发任务的过程中需要全团队的多轮确认,多轮确认确保所有人达成统一共识 ,在最大的程度上解决沟通差带来的不确定性。最终需要通过迭代计划会议在团队内部对价值达成共识后,才会进行项目开发。

进入开发任务后每个阶段,参考下图:

我们可以看到4重质量保证:
- 结对编程:两个人的脑子总比一个人想的全。(其他好处不用赘述)
- 团队中的代码版本差异识别:每对Pair的代码在一天结束时会被整个开发团队审核(当然可以提高代码质量了)
- 代码审计:当对应开发任务 - PR(每笔代码)完成后,会被整个团队提意见(我听过比较离谱的就是:Our PR is waiting for more comments),修正完成后代码才会进入测试阶段。
- 测试: 最后的最后,才会进行测试,整个测试则是由小团队内部完成,在没有测试的情况下,“非常态”的AC就是整个测试的通过条件。
再这样一轮一轮的开发任务到用户故事的价值交付后,又组成了一个Epic价值交付,最终通过Bug Bash的方式最后确认价值以达到交付标准,我们可以上线整个Epic用于用户的检验。
总结一下敏捷开发的特点:
- 业务 -> 开发 -> 测试由一个全职能敏捷团队完成
- 大多数内容由团队内部确定
- 由上向下“顺时针“开发
- 尽可能的小型功能,快速迭代
- 小型逆时针回调细节确认
- 业务导向:业务决定质量
用图来表示最终内建的结果,在最终快要上线时,经过团队内质量把控后仅与实际有极少差距,仅需要在日常使用中进行基础运维即可达到我们的价值目标:

项目A的情况
这时候让我们再来看项目A,系统被产品部门完成设计后,交予开发部门进行任务划分,每个开发团队承担不同的功能开发任务,每个功能点再由单独开发人员进行开发并自行测试(本地),最后由客户方进行功能验收后(功能展示+代码审核),代码合入主线进行转测。
说到这儿,举个例子,产品部门提供了本次需要交付的20个功能的设计图,开发团队把设计图分给交付团队(大多由供应商组成),团队成员小王负责对其中一张设计图(类似于一个Epic)的功能进行开发,开发完成后开验收会议,对代码和功能进行审核验证,进入测试流程。所以开发阶段归纳下来的话,如图

这样乍一看确实没有什么问题,开发流程中的各种实践也在做,那这种项目研发模式问题出在哪儿呢?这个时候我们看项目A的关键质量保证动作:测试。
项目A的测试步骤:

先抛结论,在测试阶段,80%时间用于确定问题+定位问题(标红)。所以我们可以着重讨论一下这两个阶段。
确认问题: 在确认问题阶段, 往往由测试组发起,通过层层追溯,可以追溯到开发人员(也就是小王),跟小王确认表现层的“静态”/“动态”/“非常态”问题后,测试顺利成章地建立一个问题工单,并分配给小王,宣告此单插在了小王头上,小王需要修正再找测试回归。乍一看又没什么问题,是个好流程,但是执行起来此流程会出现:
-
因为测试标准中有较多主观的感官感受,导致在跟开发确认问题时经常出现主观问题,此时需要产品介入,并用主观感受进行判定。(缺少用户旅程细节)
举例:(一个电话拉会)“小王,我觉得这个页面帧数好低,你要优化一下。”“啊???”(此处省略battle的10分钟)终于电话给了产品,产品一句话:“是帧数有点低啊!小王,这你得改”“…”
-
需要产品介入的场景往往流程会变得极长。测试在做测试中,会考虑很多“非常态“问题,在非常态问题中,往往会导致”静态“”动态“的变更,然后经过工单追踪,产品组漫长的重新设计,然后再由开发进行更改。
-
当存在“扯皮”问题,又是另外一副光景。
举例:测试打电话给小王,小王说“这不是我的问题,你找xx团队的小李 ”,小李接上电话,“这是你小王开发的啊”…(再次省略battle时间)最终问题很有可能上升到客户方确定问题边界,这样1个小时就过去了。
-
开发的专注思考时间被切碎。在转测后,需要大量地确认问题,也就是跟测试打电话,测试往往是发现问题第一时间就会确认问题,这样导致开发人员每天专注于代码工作的时间被切碎,效率直接下降。
定位问题: 定位问题同样占据了开发人员的大量时间,总体来说:
- 大量追溯代码:确认问题后,有时会需要确定整个功能代码中的问题点,问题很难定位,尤其遇到比较棘手的概率,性能问题需要对整个代码进行回顾与重构。
- 涉及他方代码:当在长时间确认问题后,问题有时会涉及他人代码,比如框架代码,他人功能代码,硬件代码,这时候需要你找到相关人(打电话),解释,最终把工单走到他人名下(当然没人愿意接单,长时间Battle在所难免)。
- 定位到无法修改的问题:当然在这里又有专门的流程做这件事,问题就出现在因为团队间的互相的部门/信任墙,需要长流程(COC:需求变更会议)来共同确认问题,需要引入大量具有决策权的角色:另外团队的架构师,产品经理,测试经理,还有可怜的小王。最终一个无法修改的工单往往需要2周或者更多的时间进行关闭。
- 流程反复:当出现 确认问题->定位问题->确认问题->定位问题…这个如此反复的流程时,对开发和测试的神经都是一个极大的考验。
后续的修改流程往往较为顺利,但是也会出现一个工单反复无法通过回归的问题,这毕竟是少数,也不是我们主要探讨的范畴。项目在强流程驱动下最终的结果就是:
所有人每天都在加班,所有人每天都在增加流程以确保质量,所有人都很痛苦,当然这里包括小王。
用图来表示开发结束后的状态,空隙区域代表不确定问题,空隙部分需要测试->开发->产品逆流程更改

总结
说了这么多细节,我想现在跳出来问“为什么会出现这样的问题?”这个问题我也想留个大家做一点思考,我做了一些简单而又主观的总结,放在这里:
- 共识缺失:当大家都在自己的职能部门做自己的工作时,往往会主观地做这件事儿,当这件事儿在后续流转时,没有通过一个整体共识的话,往往需要从底端流程不断向上确认达成共识。
- 大规模“逆时针”回调:因为整体共识由测试发起,加上部门墙重,往往导致从测试->开发->产品的逆时针开发流程,代码重构与返工的工作量极大。
- 价值产出慢:当最终功能在大量回调时,价值产出很慢,导致验证慢,最终导致逆向反馈增加。
- 流程决定质量:还是由测试流程来确定质量的情况下,在产品只进行Happy Pass的情况下,所有人的弥合质量的成本都在成倍增加。
看完了项目A和项目B的整体, 我们最后再来聊聊效率,我们发现,在同等的质量要求下,敏捷效率反而高很多,在流程更短的情况下却交付出了同样质量很高的产品,最后我们通过对比总结一下,为什么敏捷在保证质量的同时还能有更高的效率?
| 敏捷团队 | 职能团队 |
| 业务决定质量 | 流程决定质量 |
| 回调(重构)路径短 | 回调(重构)路径长 |
| 快速产出价值并验证价值 | 慢速产出价值验证价值慢 |
| 团队成员共同决策->快速达成共识 | 单一角色决策->长流程确认共识 |
| 专注手头工作 | 分散精力处理流程 |
| 团队凝聚力强 | 职能部门间不信任 |
| 开心 | 痛苦 |
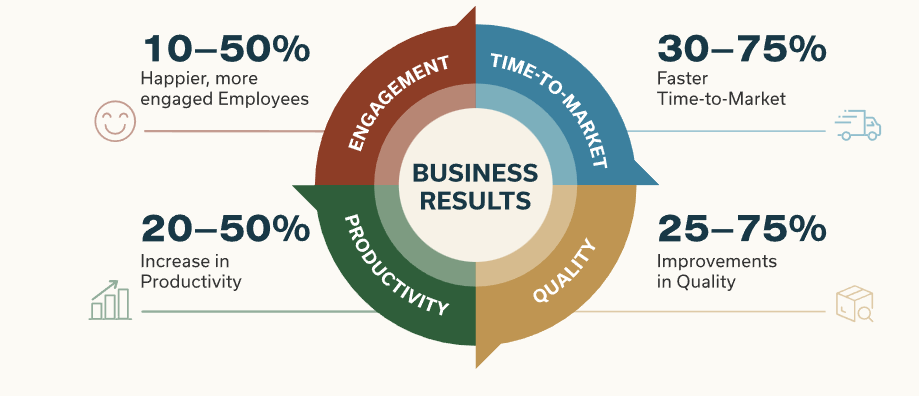
图片来源:SAFe
我们暂且停在这儿,我要引用SAFe中的一张图来结束我今天的阐述,也在用实例回答:“为什么企业要做大规模敏捷?”
我想答案是:质量高,效率快,大家都开心。
参考资料:
SAFe:How the Scaled Agile Framework® Benefits Organizations
SAFe for Lean Enterprises - Scaled Agile Framework
SAFe Lean-Agile Principles - Scaled Agile Framework
A Complete Guide About Scaled Agile Framework (SAFe)? - DZone
文/Thoughtworks 曾雪松
原文链接:https://insights.thoughtworks.cn/large-scale-agile-ensures-quality-and-efficiency/