文章目录
- 1.从哪些角度去考虑MySQL的优化
- 2.数据库服务器的选型
- 3.从操作系统层面去优化MySQL数据库
- 3.1.关于CPU方面的优化
- 3.2.关于内存方面的优化
- 3.3.关于磁盘IO方面
- 4.应用端的优化
- 5.数据库系统优化工具
- 6.数据库系统参数优化
- 6.1.最大连接数的优化(max_connections)
- 6.2.暂存连接数(back_log)
- 6.3.非交互等待时间(wait_timeout)和交互等待时间(interactive_timeout)
- 6.5.索引缓冲区大小(key_buffer_size)
- 6.6.查询缓存大小(query_cache_size)
- 6.7.安全计数器(max_connect_errors )
- 6.8.排序线程缓冲区大小(sort_buffer_size)
- 6.9.最大的接收数据包大小(max_allowed_packet)
- 6.10.多表联查缓冲区大小(join_buffer_size)
- 6.11.服务器线程缓存数量(thread_cache_size)
- 6.12.InnoDB存缓冲区大小(innodb_buffer_pool_size)
- 6.13.InnoDB线程的并发数量(innodb_thread_concurrency)
- 6.13.Log Buffer数据写入日志并刷新到磁盘的时间点(innodb_flush_log_at_trx_commit)
- 6.14.数据日志缓冲区的大小(innodb_log_buffer_size)
- 6.15.数据日志文件大小(innodb_log_file_size)
- 6.16.数据日志文件数量(innodb_log_files_in_group)
- 6.17.读缓冲区的大小(read_buffer_size)
- 6.18.随机读缓冲区的大小(read_rnd_buffer_size)
- 6.19.批量插入数据的缓冲区大小(bulk_insert_buffer_size)
- 6.20.Binlog日志的优化
- 6.21.安全参数的优化
- 6.22.主从优化
- 7.优化后的配置文件内容
1.从哪些角度去考虑MySQL的优化
MySQL的优化主要从硬件层面、应用程序层面、数据库层面等三个方面进行优化。
- 存储、主机和操作系统:
- 从主机架构的稳定性、IO的规划和配置、存储使用SSD硬盘,Swap方面的优化、OS内核参数等角度考虑优化。
- 应用程序:
- 从应用程序的稳定性、索引优化、性能优化、SQL语句检索、并发串行读取数据等角度优化。
- 数据库优化:
- 从内存、数据库结构、多实例角度优化。
2.数据库服务器的选型
1)主机方面:
真实的硬件(PC Server): DELL R系列 ,华为,浪潮,HP,联想。
云产品:ECS、数据库RDS、DRDS。
IBM 小型机 P6 570 595 P7 720 750 780 P8 。
2)CPU根据数据库类型
OLTP、OLAP
IO密集型:线上系统,OLTP主要是IO密集型的业务,高并发。
CPU密集型:数据分析数据处理,OLAP,cpu密集型的,需要CPU高计算能力(i系列,IBM power系列)。
CPU密集型: I 系列的,主频很高,核心少。
IO密集型: E系列(至强),主频相对低,核心数量多。
3)内存
建议2-3倍cpu核心数量。
4)磁盘选择
SATA-III SAS Fc SSD(sata) pci-e ssd Flash。
主机 RAID卡的BBU(Battery Backup Unit)关闭。
5)存储
根据存储数据种类的不同,选择不同的存储设备,配置合理的RAID级别(raid5、raid10、热备盘) 。
r0 :条带化 ,性能高
r1 :镜像,安全
r5 :校验+条带化,安全较高+性能较高(读),写性能较低 (适合于读多写少)
r10:安全+性能都很高,最少四块盘,浪费一半的空间(高IO要求)
6)网络
1、硬件买好的(单卡单口)
2、网卡绑定(bonding),交换机堆叠
3.从操作系统层面去优化MySQL数据库
我们优化数据库时,首先从操作系统层面去优化MySQL,可以根据CPU、内存、IO进行分析,从而优化MySQL
3.1.关于CPU方面的优化
系统为每个程序分配CPU时是以时间来片划分的,MySQL运行过程中,我们可以通过Top命令观察CPU的平均使用情况。

- id:空闲的CPU时间片占比。
- wa:CPU用来等待的时间片占比。
- MySQL服务器wa占比较高,很有可能是有大并发事务在运行、全表扫描、锁等,因为wa状态是等待的时间片占比,MySQL服务器是在内存中操作数据的,从磁盘读取数据到内存,如果一次性读取大量的数据,CPU可能就会处于等待中。
- 由MySQL引起的wa高的原因可能是:锁、IO、索引。
- us:用户程序工作所占用的时间片占比,这个值越大说明都是服务再使用CPU,并没有造成CPU的浪费。
- sy:内核工作花费的CPU时间片占比,当系统版本越可靠,只有在系统启动的时候才会消耗CPU占比,系统启动完成后,几乎不会占用CPU,当sy占比很高时,就可能由系统存在Bug、中病毒、高并发连接、锁造成。
也可以按1查看每个CPU核心的分别使用情况。
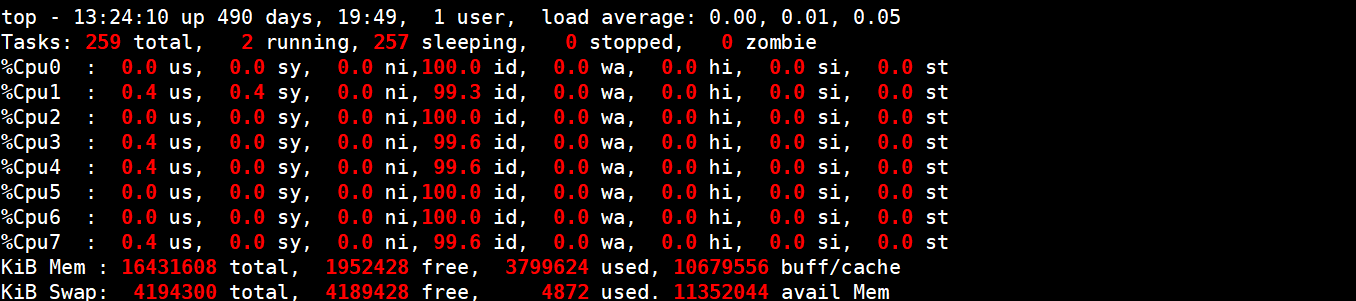
系统中的计算(程序运行数据处理)和控制(申请资源释放资源)属于有效的CPU工作时间片,等待IO属于无效的CPU工作时间片。
在生产环境中,我们要判断CPU的多核心有没有被充分的利用,当并发参数设置不合理时,就会导致CPU的核心使用不均匀。
3.2.关于内存方面的优化
关于内存方面的优化也是很重要的,关于系统的内存使用,我们还可以在Top命令中看到,对于数据库服务器,主要关注availMem剩余内存,和buff/cache的内存使用。

由于MySQL的数据处理都是在内存中进行的,因此MySQL自己就对内存方面做出了优化,开启了回收策略。
但是在操作系统层面,CentOS系统会开启Swap交换分区,当CentOS7系统的内存使用率达到70%的时候就会使用Swap分区,但是Swap分区非常慢,性能很差,Swap本身就是硬盘中的空间,因此优化MySQL服务器时,建议将Swap关闭,不使用Swap。
echo 0 >/proc/sys/vm/swappinessvim /etc/sysctl.conf
vm.swappiness=0sysctl -p 这个参数决定了Linux是倾向于使用swap,还是倾向于释放文件系统cache。在内存紧张的情况下,数值越低越倾向于释放文件系统cache。
当然,这个参数只能减少使用swap的概率,并不能避免Linux使用swap。
修改MySQL的配置参数innodb_flush_method,开启O_DIRECT模式这种情况下,InnoDB的buffer pool会直接绕过文件系统cache来访问磁盘,但是redo log依旧会使用文件系统cache。值得注意的是,Redo log是覆写模式的,即使使用了文件系统的cache,也不会占用太多
3.3.关于磁盘IO方面
通过以下命令可以分析磁盘IO的性能,首先写入一个1G的文件,然后观察IO的状态。
# dd if=/dev/zero of=/tmp/bigfile bs=1M count=1024
记录了1024+0 的读入
记录了1024+0 的写出
1073741824字节(1.1 GB)已复制,1.06451 秒,1.0 GB/秒# iostat -dm 1
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 104.00 0.00 52.00 0 52
dm-0 104.00 0.00 52.00 0 52
dm-1 0.00 0.00 0.00 0 0#获取IO的使用率时以M为单位显示,每秒刷新1次
一般情况下,IO要和CPU参照对比分析,CPU高的情况下,IO也会很高,如果CPU的wait很高,IO很低,那么有可能就是磁盘出问题,如果CPU的sys很高,IO很低,那么可能就是数据库层面出问题,可能是锁,需要进一步的分析和判断。
也可以使用vmsta命令分析系统的内存、swap、io、system、cpu的使用情况。

IO调度策略的优化:
centos 7 默认是deadline
cat /sys/block/sda/queue/scheduler#临时修改为deadline(centos6)
echo deadline >/sys/block/sda/queue/scheduler
vi /boot/grub/grub.conf
更改到如下内容:
kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quietIO :raidno lvm,lvm对于数据库安全性略低ext4或xfsssdIO调度策略
提前规划好以上所有问题,减轻MySQL优化的难度。
4.应用端的优化
开发很有可能会写一些烂SQL,作为运维一定要注意开发写的烂SQL,可以上线SQL审核平台,严格审核开发提交的SQL。
避免业务逻辑错误,避免锁争用,需要我们DBA深入业务,或者要和开发人员\业务人员配合实现。
5.数据库系统优化工具
| 工具 | 作用 |
|---|---|
| show status | 查看MySQL服务器状态信息 |
| show variables | 查看MySQL系统参数 |
| show index | 查看索引信息 |
| show processlist | 查看当前数据库中的线程信息 |
| show slave status | 查看从库的状态 |
| show engine innodb status | 查看InnoDB的状态 |
| desc /explain | 分析SQL的执行过程 |
| slowlog | 慢日志 |
| pt系列(pt-query-digest、pt-osc、pt-index) | 监控mysql服务器 |
| mysqlslap | 基准测试工具 |
| sysbench | 多线程性能测试工具 |
| information_schema | 通过MySQL自带的视图分析 |
| performance_schema | 通过MySQL自带的视图分析 |
| sys | 通过MySQL自带的视图分析 |
6.数据库系统参数优化
6.1.最大连接数的优化(max_connections)
MySQL配置最大连接数的参数是max_connections,如果服务器的并发请求量比较大,可以去调高这个值,当然是要在服务器能够承受的压力下,去调整这个参数的值,随着连接数越来越多,MySQL会为每个连接提供缓冲区,就会导致开销越来越多的内存,对于连接数这个值不能随便去调高。
再调整最大连接数之前,先使用压测工具,测试一下MySQL服务器可以承载多少个并发连接:
mysqlslap --defaults-file=/etc/my.cnf \
--concurrency=100 --iterations=1 --create-schema='db_1' \
--query="select * from db_1.t1000w where k2='FGCD'" engine=innodb \
--number-of-queries=200 -uroot -p123 -verbose--concurrency=100:并发连接数
--number-of-queries=200:请求次数压测工具在使用过程中,如果并发连接数达到了服务器的极限,就会报错to manay connection,此时就需要对连接数进行优化。
设置最大连接数的依据:我们可以观察当前数据库中的连接数,然后在观察系统设置的最大连接数,从而进行合理的调整。
#默认情况下数据库的连接数是151个,生产环境中建议调整到1k-2k,当然也要根据服务器硬件资源去调整。
mysql>select @@max_connections;
+-------------------+
| @@max_connections |
+-------------------+
| 151 |
+-------------------+
1 row in set (0.00 sec)#当前数据库的连接数
root@localhost localhost 14:42:34 (none)>show status like 'Max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 1 |
+----------------------+-------+
设置最大连接数的方法:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
Max_connections=1024补充:1.开启数据库时,我们可以临时设置一个比较大的测试值2.观察show status like 'Max_used_connections';变化3.如果max_used_connections跟max_connections相同,那么就是max_connections设置过低或者超过服务器的负载上限了,低于10%则设置过大.
6.2.暂存连接数(back_log)
暂存连接数的配置参数是back_log,也是与连接数相关的一个参数,主要的功能是当数据库的连接数达到max_connections时,再提供一些额外的连接数,例如当并发连接数达到了1024,暂存连接数设置了100个,当达到了1024时,会再分配100个连接,不至于在客户端报错。
不过这个参数一般很少设置,主要都在最大连接数中设置。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
back_log=1024
6.3.非交互等待时间(wait_timeout)和交互等待时间(interactive_timeout)
非交互等待时间的配置参数是wait_timeout,指的是MySQL在关闭一个非交互式的连接之前所需要等待的时间,也就是说一个连接多长时间内不操作就断开。
交互等待时间的配置参数是interactive_timeout,指的是交互模式下多长时间不操作就断开。
这两个时间都不建议设置的太长或者太短,太长造成一个连接存在的时间太长,太短会导致频繁的断开。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
interactive_timeout=120
wait_timeout=3600
6.5.索引缓冲区大小(key_buffer_size)
索引缓冲区大小的参数是key_buffer_size,通过这个参数可以决定索引处理的速度,尤其是索引读的速度,主要是在内存中加大索引的缓冲区大小。
这个参数与myisam表有点关系,不过最主要的还是在InnoDB引擎下,当使用多表联查、子查询、union时此参数会在内存中创建临时表,而不会去磁盘中创建临时表,当SQL执行完毕后,自动清理临时表。
对于临时表有两种创建方式,一种是在内存中创建,就与key_buffer_size参数有关,另一种是在磁盘中创建,在磁盘中创建效率低,因此在优化MySQL时,一定要设置这个参数。
设置key_buffer_size参数时,我们可以先看一下当前数据库中临时表都是在哪里创建的:
mysql> show status like "created_tmp%";
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 0 | #磁盘中创建的临时表个数
| Created_tmp_files | 6 | #临时文件个数,无关
| Created_tmp_tables | 1 | #内存中创建的临时表个数
+-------------------------+-------+
key_buffer_size参数的大小到底设置成多少合适呢?其实也有有依据的,我们按照一个公式来计算:
-
计算内存临时表的占比
- Created_tmp_tables/(Created_tmp_disk_tables + Created_tmp_tables)X100%
- 1/(1+0)*100=100%
- 用内存临时表除内存临时表+磁盘临时表,最终就可以得到内存临时表的占比,按照我们的环境内存临时表的占比是100%,占比越高性能越强。
- Created_tmp_tables/(Created_tmp_disk_tables + Created_tmp_tables)X100%
-
计算磁盘临时表的占比
- Created_tmp_disk_tables/(Created_tmp_disk_tables + Created_tmp_tables) X100%
- 0/(0+1)*100%=0%
- 用磁盘临时表除磁盘临时表+内存临时表,最终就可以得到磁盘临时表的占比,按照我们的环境内存临时表的占比是0%,占比越低性能越强。
当我们再设置
key_buffer_size参数时,可以进行微调,一次加2M,观察内存临时表的占比,一般占比在5%~10%以内,就说明我们key_buffer_size这个参数的值给到位了。 - Created_tmp_disk_tables/(Created_tmp_disk_tables + Created_tmp_tables) X100%
另外我们可以对内存临时表的占比进行zabbix监控,当占比超过10%时是就告警,然后我们再去微调key_buffer_size参数的大小,需要注意的是mysqldump在备份的时候会在磁盘中创建很多临时表,一定要避开备份时刻的监控,否则就会频繁告警说内存临时表的占比超过了10%。
设置key_buffer_size参数:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
key_buffer_size=64M
6.6.查询缓存大小(query_cache_size)
查询缓存的配置参数是query_cache_size,作用就是对于同样的查询语句,完整一次查询后,第二次查询直接从缓冲区中读取结果,目前已经不怎么使用了,因为有缓存数据库redis,可以简单了解一下。
查询缓存参数设置的依据主要判断下面几个参数的状态值:
mysql> show status like "%Qcache%";
+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 1031360 |
| Qcache_hits | 0 |
| Qcache_inserts | 0 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2002 |
| Qcache_queries_in_cache | 0 |
| Qcache_total_blocks | 1 |
+-------------------------+---------+---------------------状态说明--------------------
Qcache_free_blocks:缓存中相邻内存块的个数。如果该值显示较大,则说明Query Cache 中的内存碎片较多了,FLUSH QUERY CACHE会对缓存中的碎片进行整理,从而得到一个空闲块。
注:当一个表被更新之后,和它相关的cache
blocks将被free。但是这个block依然可能存在队列中,除非是在队列的尾部。可以用FLUSH QUERY CACHE语句来清空free blocksQcache_free_memory:Query Cache 中目前剩余的内存大小。通过这个参数我们可以较为准确的观察出当前系统中的Query Cache 内存大小是否足够,是需要增加还是过多了。Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越理想。Qcache_inserts:表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert到查询缓存中。这样的情况的次数越多,表示查询缓存应用到的比较少,效果也就不理想。当然系统刚启动后,查询缓存是空的,这很正常。Qcache_lowmem_prunes:
多少条Query因为内存不足而被清除出QueryCache。通过“Qcache_lowmem_prunes”和“Qcache_free_memory”相互结合,能够更清楚的了解到我们系统中Query Cache 的内存大小是否真的足够,是否非常频繁的出现因为内存不足而有Query 被换出。这个数字最好长时间来看;如果这个数字在不断增长,就表示可能碎片非常严重,或者内存很少。(上面的free_blocks和free_memory可以告诉您属于哪种情况)Qcache_not_cached:不适合进行缓存的查询的数量,通常是由于这些查询不是 SELECT 语句或者用了now()之类的函数。Qcache_queries_in_cache:当前Query Cache 中cache 的Query 数量;
Qcache_total_blocks:当前Query Cache 中的block 数量;。
Qcache_hits / (Qcache_inserts+Qcache_not_cached+Qcache_hits) 90/ 10000 0 90如果出现hits比例过低,其实就可以关闭查询缓存了。使用redis专门缓存数据库Qcache_free_blocks 来判断碎片
Qcache_free_memory + Qcache_lowmem_prunes 来判断内存够不够
Qcache_hits 多少次命中 Qcache_hits / (Qcache_inserts+Qcache_not_cached+Qcache_hits)
此参数的设置方法:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
query_cache_type=1
query_cache_size=256M
query_cache_limit=32M
6.7.安全计数器(max_connect_errors )
安全计数器的参数是max_connect_errors ,它负责阻止过多尝试失败的客户端以防止暴力破解密码等情况,当超过指定次数,mysql服务器将禁止host的连接请求,直到mysql服务器重启或通过flush hosts命令清空此host的相关信息 max_connect_errors的值与性能并无太大关系。
修改/etc/my.cnf文件,在[mysqld]下面添加如下内容
max_connect_errors=2000
6.8.排序线程缓冲区大小(sort_buffer_size)
排序线程缓冲区大小的参数是sort_buffer_size ,当数据库中有很多的排序SQL时,建议设置此参数,加大排序缓冲区的大小。
排序缓冲区的大小并不是越大越好,这个参数是会话级别的参数,一个请求进来就会占用一个排序缓冲区,此参数的值设置的过大可能会消耗系统的内存资源,例如500个请求,排序缓冲区的大小为20M,那么就会消耗500*20=10G的内存。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
sort_buffer_size=2 0M
6.9.最大的接收数据包大小(max_allowed_packet)
最大接收数据包大小的参数是max_allowed_packet,这个参数非常重要,在服务器端和备份端都需要配置,这个参数值给不到位,当有大数据量、大数据包的情况下,就会无法写入,当然也要根据实际情况进行设置。
该参数值的大小必须设置成1024的倍数。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
max_allowed_packet=32M
6.10.多表联查缓冲区大小(join_buffer_size)
多表联查缓冲区的大小设置参数是join_buffer_size,和sort_buffer_size参数的概念差不多,join_buffer_size参数是给多表联查设置缓冲区大小,此参数也是会话级别,一个会话进来就会占用一定的缓冲区大小,根据需求按需设置。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
join_buffer_size=2M
6.11.服务器线程缓存数量(thread_cache_size)
服务器线程缓存数量的参数是thread_cache_size,通过这个参数可以在缓存中保存线程的数量。
默认情况下,当连接断开后,客户端启动的线程会在缓存中释放,新的客户端连接后再启动新的线程,这样一来会消耗一定的CPU资源。
通过thread_cache_size参数可以设置在缓存中保留多少个客户端启动的线程数量,当客户端断开连接后,不会再将启动的线程销毁,而是缓存在内存中,下一个客户端连接后,直接使用缓存中的线程,通过这个值,可以来改善系统的性能。
对于thread_cache_size参数的设置规则,官方给出的建议是1G内存配置8个,2G配置16个,3G配置32个,以此类推,但是也不建议使用官方给出的规则,还需要根据自己的数据库服务器进行配置。
设置thread_cache_size参数时,可以将以下几个指标的值作为参考依据,从而分析此参数设置多少个缓存的线程合适。
mysql> show status like 'threads_%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 8 |
| Threads_connected | 2 |
| Threads_created | 4783 |
| Threads_running | 1 |
+-------------------+-------+Threads_cached:代表当前此时此刻线程缓存中有多少空闲线程。
Threads_connected:代表当前已建立连接的数量,因为一个连接就需要一个线程,所以也可以看成当前被使用的线程数。
Threads_created:代表从最近一次服务启动,已创建线程的数量,如果发现Threads_created值过大的话,表明MySQL服务器一直在创建线程,这也是比较耗cpu SYS资源,可以适当增加配置文件中thread_cache_size值。
Threads_running :代表当前激活的(非睡眠状态)线程数。并不是代表正在使用的线程数,有时候连接已建立,但是连接处于sleep状态。
当我们对thread_cache_size参数设置了个数后,可以通过zabbix监控观察一段时间内Threads_created指标的值,如果很稳定的情况下,就说明我们设置的参数是没问题的,如果Threads_created指标的值很不稳定,那我们就需要再调整thread_cache_size参数的值。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
thread_cache_size=32
6.12.InnoDB存缓冲区大小(innodb_buffer_pool_size)
设置InnoDB缓冲区大小的参数是innodb_buffer_pool_size,指定InnoDB使用的缓冲区大小,在这个缓冲区中会包含数据和索引。
这个参数是非常重要的,可以将物理内存的70%都分片给InnoDB缓冲区,最大到80%,不使用官方的90%,因为数据库中还有其他的东西会用到缓冲区,对于一个新的业务来说,这个缓冲区大小可以设置为50%的物理内存,后期数据量增大后再扩容。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_buffer_pool_size=2048M
或者
innodb_buffer_pool_size=8G
6.13.InnoDB线程的并发数量(innodb_thread_concurrency)
设置InnoDB线程并发数量的参数是innodb_thread_concurrency,默认值为0表示不限制,此参数只在大事务并发的场景下才应用。
在官方文档中,对于innodb_thread_concurrency参数的使用,也给出了一些建议,在一个MySQL服务器中,如果用户并发的线程数量小于64,建议设置innodb_thread_concurrency参数的值为0,如果在数据库中工作负载一直较为严重甚至偶尔达到顶峰,建议设置innodb_thread_concurrency值为128,并且持续观察,不断降低这个参数值,直到发现最佳性能的并发数。
例如,假设系统通常有40到50个用户,但定期的数量增加至60,70,甚至200。你会发现,性能在80个并发用户设置时表现稳定,如果高于这个数,性能反而下降。在这种情况下,建议设置innodb_thread_concurrency参数为80,以避免影响性能。如果你不希望InnoDB使用的虚拟CPU数量比用户线程使用的虚拟CPU更多(比如20个虚拟CPU),建议通过设置innodb_thread_concurrency 参数为这个值(也可能更低,这取决于性能体现),如果你的目标是将MySQL与其他应用隔离,你可以l考虑绑定mysqld进程到专有的虚拟CPU。但是需要注意的是,这种绑定,在myslqd进程一直不是很忙的情况下,可能会导致非最优的硬件使用率。在这种情况下,你可能会设置mysqld进程绑定的虚拟 CPU,允许其他应用程序使用虚拟CPU的一部分或全部。在某些情况下,最佳的innodb_thread_concurrency参数设置可以比虚拟CPU的数量小。定期检测和分析系统,负载量、用户数或者工作环境的改变可能都需要对innodb_thread_concurrency参数的设置进行调整。
个人建议设置innodb_thread_concurrency参数的依据:当前CPU使用均匀的情况下,不需要调整此参数值,观察连接数有没有达到顶峰,根据情况从少到多进行调整,比如先设置并发数为8,持续观察后再进行调整。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_thread_concurrency=0
6.13.Log Buffer数据写入日志并刷新到磁盘的时间点(innodb_flush_log_at_trx_commit)
innodb_flush_log_at_trx_commit 参数主要控制InnoDB将Log Buffer中的数据写入日志文件并刷新到磁盘的时间点,取值分别是0/1/2三个。
- 取值0:表示当前事务提交时,不写入日志文件,而是每秒钟将Log Buffer中的数据写入到日志文件,并刷新到磁盘一次。
- 取值1:每次事务的提交,都写入到日志文件一次,并刷新到磁盘,确保事务落盘。
- 取值2:每次事务提交触发写入日志文件的动作,但每秒完成一次刷新磁盘的操作。
实际测试发现,该值对插入数据的速度影响非常大,设置为2时插入10000条记录只需要2秒,设置为0时只需要1秒,而设置为1时则需要229秒。因此,MySQL手册也建议尽量将插入操作合并成一个事务,这样可以大幅提高速度。
根据MySQL官方文档,在允许丢失最近部分事务的危险的前提下,可以把该值设为0或2。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_flush_log_at_trx_commit=1
6.14.数据日志缓冲区的大小(innodb_log_buffer_size)
设置日志缓冲区的大小的参数是innodb_log_buffer_size,此参数主要设置日志文件占用的内存大小,以M为单位,缓冲区大能提高性能,对于较大的事务,可以增大缓冲区大小。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_log_buffer_size=128M
6.15.数据日志文件大小(innodb_log_file_size)
innodb_log_file_size此参数是设置数据日志文件的大小,以M为单位,更大的设置可以提高性能。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_log_file_size=100M
6.16.数据日志文件数量(innodb_log_files_in_group)
为了提高性能,MySQL可以循环方式将日志文件写入到多个文件,推荐设置为3。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_log_files_in_group=3
6.17.读缓冲区的大小(read_buffer_size)
读缓冲区大小的设置参数是read_buffer_size,对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。和 sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
read_buffer_size=1M
6.18.随机读缓冲区的大小(read_rnd_buffer_size)
随机读(查询操作)缓冲区大小的设置参数是read_rnd_buffer_size。
当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySql会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySql会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
注:顺序读是指根据索引的叶节点数据就能顺序地读取所需要的行数据。随机读是指一般需要根据辅助索引叶节点中的主键寻找实际行数据,而辅助索引和主键所在的数据段不同,因此访问方式是随机的。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
read_rnd_buffer_size=1M
6.19.批量插入数据的缓冲区大小(bulk_insert_buffer_size)
批量插入数据缓冲区大小是参数是bulk_insert_buffer_size,可以有效提高插入效率。
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
bulk_insert_buffer_size=8M
6.20.Binlog日志的优化
对于Binlog日志的优化主要在于以下几个参数:
log-bin=/data/mysql-bin
binlog_cache_size=2M #为每个session分配的内存,在事务过程中用来存储二进制日志的缓存, 提高记录bin-log的效率。没有什么大事务,dml也不是很频繁的情况下可以设置小一点,如果事务大而且多,dml操作也频繁,则可以适当的调大一点。前者建议是--1M,后者建议是:即 2--4M
max_binlog_cache_size=8M #表示的是binlog能够使用的最大cache内存大小
max_binlog_size=512M #指定binlog日志文件的大小,如果当前的日志大小达到max_binlog_size,还会自动创建新的二进制日志。你不能将该变量设置为大于1GB或小于4096字节。默认值是1GB。在导入大容量的sql文件时,建议关闭sql_log_bin,否则硬盘扛不住,而且建议定期做删除。
binlog_format=row #binlog日志的格式
#双1标准,基于安全的机制
sync_binlog=1 #什么时候刷新binlog到磁盘,每次事务commit都刷新日志到磁盘
innodb_flush_log_at_trx_commit=1 #事务提交写入日志,并刷新到磁盘
expire_logs_days=7 #定义了mysql清除过期日志的时间。
6.21.安全参数的优化
对于MySQL数据库的安全参数主要有Innodb_flush_method参数,这个参数控制InnoDB数据文件以及Redo log的打开、刷写模式,该参数有2个取值:
- fync
- 在数据页需要持久化时,首先将数据写入到OS Buffer中,然后由OS Buffer决定什么时候写入磁盘。
- 在Redo Buffer需要持久时,首先将数据写入OS Buffer中,然后由OS Buffer决定什么时候写入磁盘。
- 但是当
innodb_flush_log_at_trx_commit这个参数设置为1后,日志依旧会在commit后直接写入磁盘。
- O_DIRECT
- 在数据页需要持久化时,直接写入磁盘。
- 在Redo Buffer需要持久时,首先将数据写入OS Buffer中,然后由OS Buffer决定什么时候写入磁盘。
- 但是当
innodb_flush_log_at_trx_commit这个参数设置为1后,日志依旧会在commit后直接写入磁盘。
最安全的模式:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_flush_log_at_trx_commit=1
innodb_flush_method=O_DIRECT
最高性能的模式:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
innodb_flush_log_at_trx_commit=0
innodb_flush_method=fsync
一般情况下,我们都会选择最安全的模式,基于双1标准:
修改/etc/my.cnf文件,在[mysqld]下面添加如下:
sync_binlog=1
innodb_flush_log_at_trx_commit=1
innodb_flush_method=O_DIRECT
6.22.主从优化
#必须开启gtid
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ONslave-parallel-type=LOGICAL_CLOCK #并行复制方式
slave-parallel-workers=16 #并行的线程个数
master_info_repository=TABLE #主从复制集群中主库的配置是在磁盘中的一个文件里master.info,通过此参数可以将其放在表中,使用数据表在一定程度上可以提高性能。
relay_log_info_repository=TABLE #将relaylog的信息记录到表中,默认情况下载磁盘的文件里relay-log.info
relay_log_recovery=ON #在数据
7.优化后的配置文件内容
[mysqld]
basedir=/data/mysql
datadir=/data/mysql/data
socket=/tmp/mysql.sock
log-error=/data/mysql/mysql-err.log
log_bin=/data/mysql/mysql-bin
binlog_format=row
skip-name-resolve
server-id=52
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
max_connections=1024
back_log=128
wait_timeout=60
interactive_timeout=7200
key_buffer_size=16M
query_cache_size=64M
query_cache_type=1
query_cache_limit=50M
max_connect_errors=20
sort_buffer_size=2M
max_allowed_packet=32M
join_buffer_size=2M
thread_cache_size=200
innodb_buffer_pool_size=1024M
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=32M
innodb_log_file_size=128M
innodb_log_files_in_group=3
binlog_cache_size=2M
max_binlog_cache_size=8M
max_binlog_size=512M
expire_logs_days=7
read_buffer_size=2M
read_rnd_buffer_size=2M
bulk_insert_buffer_size=8M
[client]
socket=/tmp/mysql.sock