目录
- 1 基本概念
- 1.1 时间轴Timeline
- 1.2 文件管理
- 1.3 索引Index
- 2 存储类型
- 2.1 计算模型
- 2.1.1 批式模型(Batch)
- 2.1.2 流式模型(Stream)
- 2.1.3 增量模型(Incremental)
- 2.2 查询类型(Query Type)
- 2.3 Copy On Write
- 2.4 Merge On Read
- 2.5 COW和MOR对比
- 3 数据写操作流程
- 3.1 UPSERT 写流程
- 3.1.1 Copy On Write
- 3.1.2 Merge On Read
- 3.2 INSERT 写流程
- 3.2.1 Copy On Write
- 3.2.2 Merge On Read
1 基本概念

Hudi 提供了Hudi 表的概念,这些表支持CRUD操作,可以利用现有的大数据集群比如HDFS做数据文件存储,然后使用SparkSQL或Hive等分析引擎进行数据分析查询。
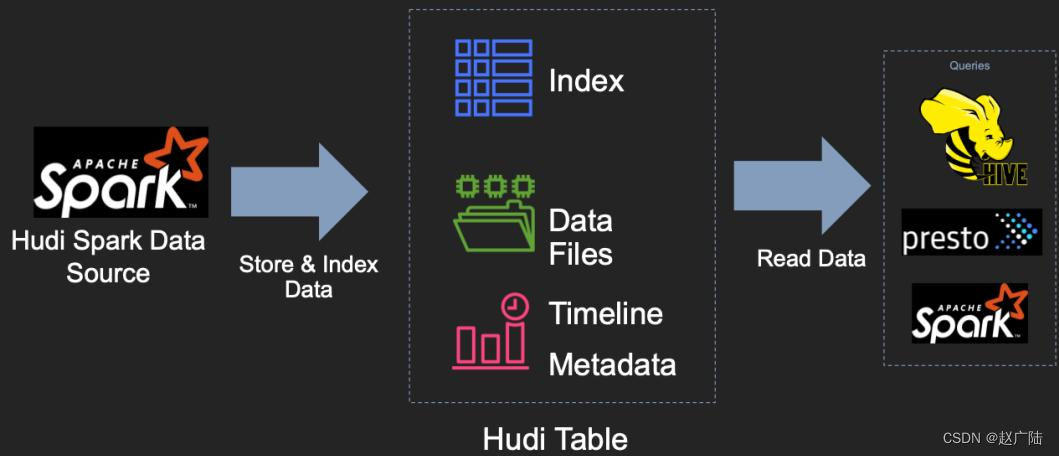
Hudi表的三个主要组件:1)、有序的时间轴元数据,类似于数据库事务日志。2)、分层布局的数据文件:实际写入表中的数据;3)索引(多种实现方式):映射包含指定记录的数据集。
1.1 时间轴Timeline
Hudi 核心是在所有的表中维护了一个包含在不同的即时(Instant)时间对数据集操作(比如新增、修改或删除)的时间轴(Timeline),在每一次对Hudi表的数据集操作时都会在该表的Timeline上生成一个Instant,从而可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据。同时,可以高效地只查询更改前的文件(如在某个Instant提交了更改操作后,仅query某个时间点之前的数据,则仍可以query修改前的数据)。
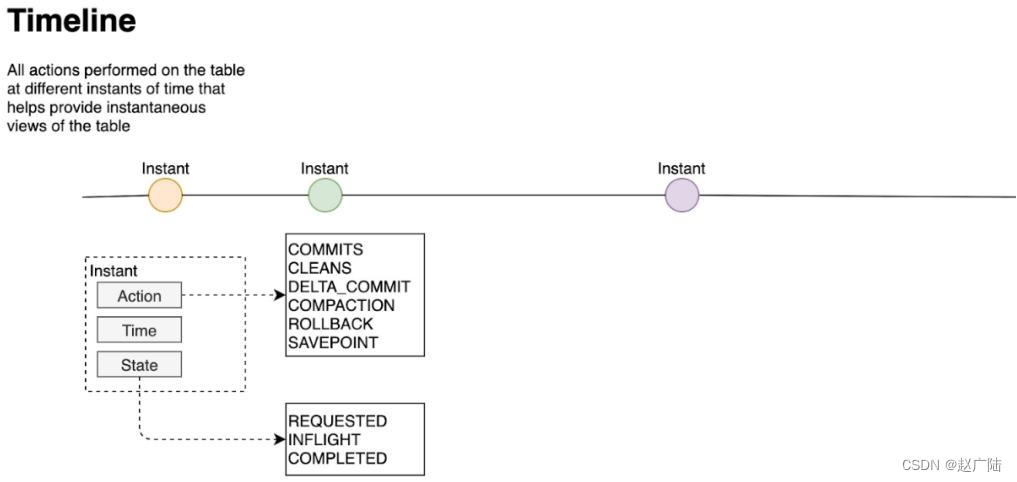
Timeline 是 Hudi 用来管理提交(commit)的抽象,每个 commit 都绑定一个固定时间戳,分散到时间线上。在 Timeline 上,每个 commit 被抽象为一个 HoodieInstant,一个 instant 记录了一次提交 (commit) 的行为、时间戳、和状态。HUDI 的读写 API 通过 Timeline 的接口可以方便的在 commits 上进行条件筛选,对 history 和 on-going 的 commits 应用各种策略,快速筛选出需要操作的目标 commit。
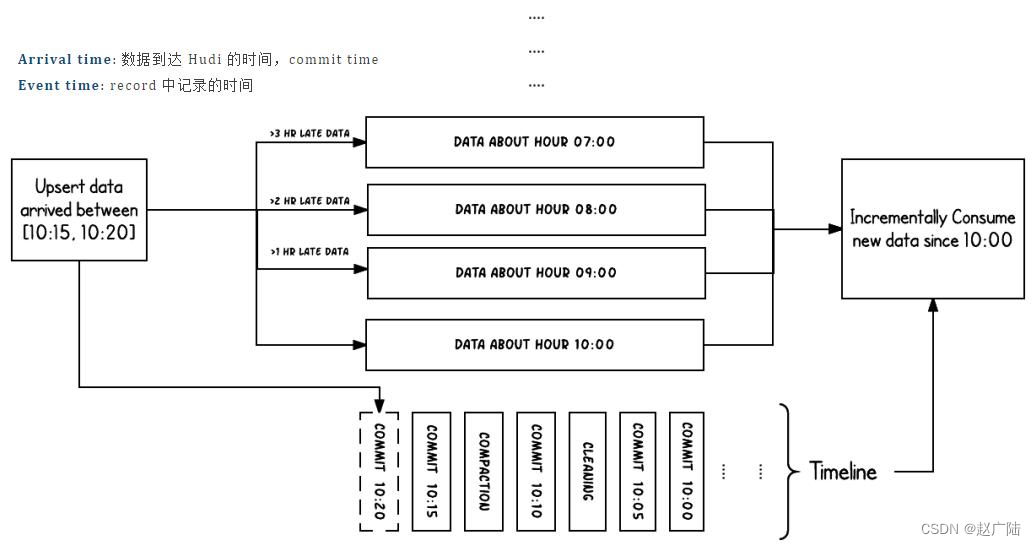
上图中采用时间(小时)作为分区字段,从 10:00 开始陆续产生各种 commits,10:20 来了一条 9:00 的数据,该数据仍然可以落到 9:00 对应的分区,通过 timeline 直接消费 10:00 之后的增量更新(只消费有新 commits 的 group),那么这条延迟的数据仍然可以被消费到。
时间轴(Timeline)的实现类(位于hudi-common-xx.jar中),时间轴相关的实现类位于org.apache.hudi.common.table.timeline包下.
1.2 文件管理
Hudi将DFS上的数据集组织到基本路径(HoodieWriteConfig.BASEPATHPROP)下的目录结构中。数据集分为多个分区(DataSourceOptions.PARTITIONPATHFIELDOPT_KEY),这些分区与Hive表非常相似,是包含该分区的数据文件的文件夹。
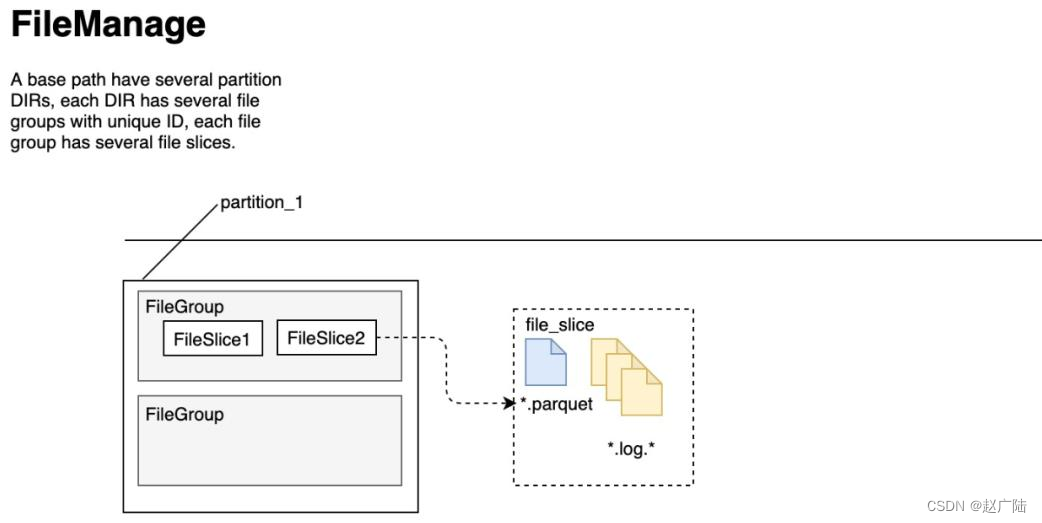
在每个分区内,文件被组织为文件组,由文件id充当唯一标识。每个文件组包含多个文件切片,其中每个切片包含在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),该文件包含自生成基本文件以来对基本文件的插入/更新。
■一个新的 base commit time 对应一个新的 FileSlice,实际就是一个新的数据版本。
■Hudi 的每个 FileSlice 中包含一个 base file (merge on read 模式可能没有)和多个 log file (copy on write 模式没有)。
■每个文件的文件名都带有其归属的 FileID(即 FileGroup Identifier)和 base commit time(即 InstanceTime)。通过文件名的 group id 组织 FileGroup 的 logical 关系;通过文件名的 base commit time 组织 FileSlice 的逻辑关系。
■Hudi 的 base file (parquet 文件) 在 footer 的 meta 去记录了 record key 组成的 BloomFilter,用于在 file based index 的实现中实现高效率的 key contains 检测。只有不在 BloomFilter 的 key 才需要扫描整个文件消灭假阳。
■Hudi 的 log (avro 文件)是自己编码的,通过积攒数据 buffer 以 LogBlock 为单位写出,每个 LogBlock 包含 magic number、size、content、footer 等信息,用于数据读、校验和过滤。
Hudi采用MVCC(多版本并发控制)设计,其中压缩操作将日志和基本文件合并以产生新的文件切片,而清理操作则将未使用的/较旧的文件片删除以回收DFS上的空间。
1.3 索引Index
Hudi通过索引机制提供高效的Upsert操作,该机制会将一个RecordKey+PartitionPath组合的方式作为唯一标识映射到一个文件ID,而且,这个唯一标识和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。
Hudi内置了4类(6个)索引实现,均是继承自顶层的抽象类HoodieIndex而来,如下注意:
■全局索引:指在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,也使得更删的消耗随着表的大小增加而增加(O(表的大小)),更适用于是小表。
■非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路径,但由此同时大幅提高了效率,因为索引查询复杂度成了O(更删的记录数量)且可以很好地应对写入量的扩展。
Hoodie key (record key + partition path) 和 file id (FileGroup) 之间的映射关系,数据第一次写入文件后保持不变,所以,一个 FileGroup 包含了一批 record 的所有版本记录。Index 用于区分消息是 INSERT 还是 UPDATE。
■BloomFilter Index(布隆过滤器索引)
▲新增 records 找到映射关系:record key => target partition
▲当前最新的数据 找到映射关系:partition => (fileID, minRecordKey, maxRecordKey) LIST (如果是 base files 可加速)
▲新增 records 找到需要搜索的映射关系:fileID => HoodieKey(record key + partition path) LIST,key 是候选的 fileID
▲通过 HoodieKeyLookupHandle 查找目标文件(通过 BloomFilter 加速)
■Flink State-based Index(基于状态Index)
▲HUDI 在 0.8.0 版本中实现的 Flink witer,采用了 Flink 的 state 作为底层的 index 存储,每个 records 在写入之前都会先计算目标 bucket ID,不同于 BloomFilter Index,避免了每次重复的文件 index 查找。
2 存储类型
Hudi提供两类型表:写时复制(Copy on Write,COW)表和读时合并(Merge On Read,MOR)表,主要区别如下:
■对于 Copy-On-Write Table,用户的 update 会重写数据所在的文件,所以是一个写放大很高,但是读放大为 0,适合写少读多的场景。
■对于 Merge-On-Read Table,整体的结构有点像 LSM-Tree,用户的写入先写入到 delta data 中,这部分数据使用行存,这部分 delta data 可以手动 merge 到存量文件中,整理为 parquet 的列存结构。

2.1 计算模型
Hudi 是 Uber 主导开发的开源数据湖框架,所以大部分的出发点都来源于 Uber 自身场景,比如司机数据和乘客数据通过订单 Id 来做 Join 等。在 Hudi 过去的使用场景里,和大部分公司的架构类似,采用批式和流式共存的 Lambda 架构,从延迟,数据完整度还有成本 三个方面来对比一下批式(Batch)和流式(Stream)计算模型的区别。
2.1.1 批式模型(Batch)
批式模型就是使用 MapReduce、Hive、Spark 等典型的批计算引擎,以小时任务或者天任务的形式来做数据计算。
■延迟:小时级延迟或者天级别延迟。这里的延迟不单单指的是定时任务的时间,在数据架构里,这里的延迟时间通常是定时任务间隔时间 + 一系列依赖任务的计算时间 + 数据平台最终可以展示结果的时间。数据量大、逻辑复杂的情况下,小时任务计算的数据通常真正延迟的时间是 2-3 小时。
■数据完整度:数据较完整。以处理时间为例,小时级别的任务,通常计算的原始数据已经包含了小时内的所有数据,所以得到的数据相对较完整。但如果业务需求是事件时间,这里涉及到终端的一些延迟上报机制,在这里,批式计算任务就很难派上用场。
■成本:成本很低。只有在做任务计算时,才会占用资源,如果不做任务计算,可以将这部分批式计算资源出让给在线业务使用。但从另一个角度来说成本是挺高的,比如原始数据做了一些增删改查,数据晚到的情况,那么批式任务是要全量重新计算。
2.1.2 流式模型(Stream)
流式模型,典型的就是使用 Flink 来进行实时的数据计算。
■延迟:很短,甚至是实时。
■数据完整度:较差。因为流式引擎不会等到所有数据到齐之后再开始计算,所以有一个 watermark 的概念,当数据的时间小于 watermark 时,就会被丢弃,这样是无法对数据完整度有一个绝对的报障。在互联网场景中,流式模型主要用于活动时的数据大盘展示,对数据的完整度要求并不算很高。在大部分场景中,用户需要开发两个程序,一是流式数据生产流式结果,二是批式计算任务,用于次日修复实时结果。
■成本:很高。因为流式任务是常驻的,并且对于多流 Join 的场景,通常要借助内存或者数据库来做 state 的存储,不管是序列化开销,还是和外部组件交互产生的额外 IO,在大数据量下都是不容忽视的。
2.1.3 增量模型(Incremental)
针对批式和流式的优缺点,Uber 提出了增量模型(Incremental Mode),相对批式来讲,更加实时;相对流式而言,更加经济。
增量模型,简单来讲,是以 mini batch 的形式来跑准实时任务。Hudi 在增量模型中支持了两个最重要的特性:
■Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,可以往 Hive 中写入增量数据,而不是每次进行完全的覆盖。(Hudi 自身维护了 key->file 的映射,所以当 upsert 时很容易找到 key 对应的文件)
■Incremental Query:增量查询,减少计算的原始数据量。以 Uber 中司机和乘客的数据流 Join 为例,每次抓取两条数据流中的增量数据进行批式的 Join 即可,相比流式数据而言,成本要降低几个数量级。
在增量模型中,Hudi 提供了两种 Table,分别为 Copy-On-Write 和 Merge-On-Read 两种。
2.2 查询类型(Query Type)
Hudi能够支持三种不同的查询表的方式(Snapshot Queries、Incremental Queries和Read Optimized Queries),具体取决于表的类型。
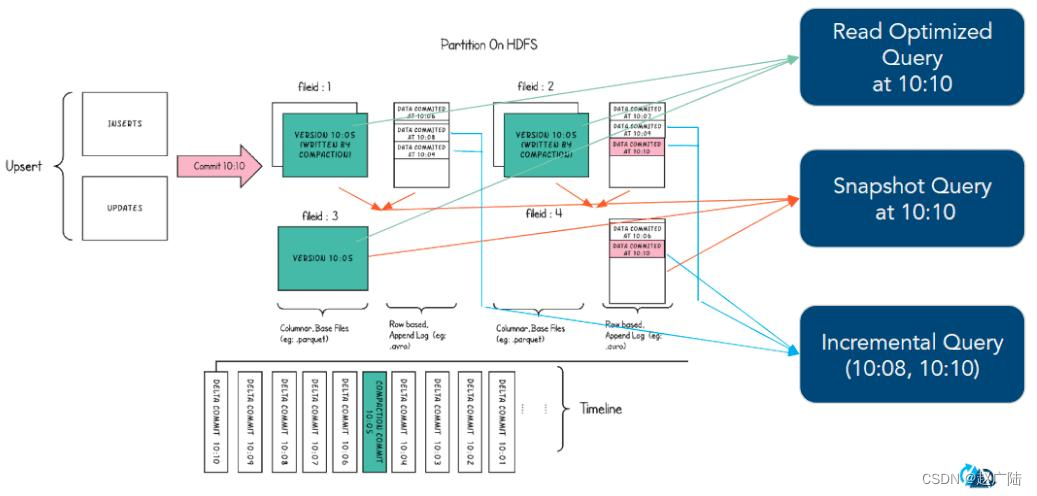
■类型一:Snapshot Queries(快照查询)
▲查询某个增量提交操作中数据集的最新快照,会先进行动态合并最新的基本文件(Parquet)和增量文件(Avro)来提供近实时数据集(通常会存在几分钟的延迟)。
▲读取所有 partiiton 下每个 FileGroup 最新的 FileSlice 中的文件,Copy On Write 表读 parquet 文件,Merge On Read 表读 parquet + log 文件
■类型二:Incremental Queries(增量查询)
▲仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个Instant)作为条件,来查询此条件之后的新数据。
▲可查看自给定commit/delta commit即时操作以来新写入的数据。有效的提供变更流来启用增量数据管道。
■类型三:Read Optimized Queries(读优化查询)
▲直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。并保证与非Hudi列式数据集相比,具有相同的列式查询性能。
▲可查看给定的commit/compact即时操作的表的最新快照。
▲读优化查询和快照查询相同仅访问基本文件,提供给定文件片自上次执行压缩操作以来的数据。通常查询数据的最新程度的保证取决于压缩策略
2.3 Copy On Write
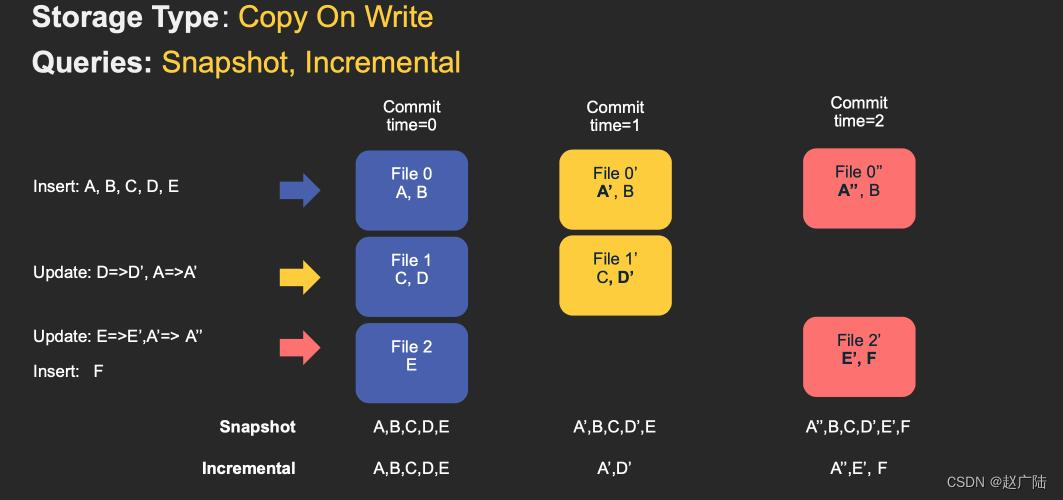
简称COW,顾名思义,它是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是最近的完整副本,这类似Mysql 的MVCC的思想。
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
■优点:读取时,只读取对应分区的一个数据文件即可,较为高效;
■缺点:数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。由于耗时,读请求读取到的数据相对就会滞后;
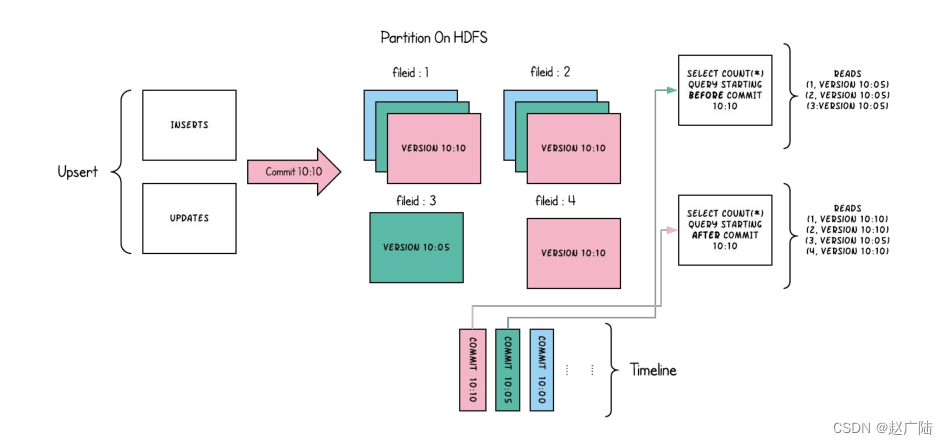
对于这种 Table,提供了两种查询:
■Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。
■Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。
COW表主要使用列式文件格式(Parquet)存储数据,在写入数据过程中,执行同步合并,更新数据版本并重写数据文件,类似RDBMS中的B-Tree更新。
■1)、更新update:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
■2)、读取read:在读取数据集时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景。
Copy On Write 类型表每次写入都会生成一个新的持有 base file(对应写入的 instant time) 的 FileSlice。用户在 snapshot 读取的时候会扫描所有最新的 FileSlice 下的 base file。
2.4 Merge On Read
简称MOR**,新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。**读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。下图演示了MOR的两种数据读写方式。
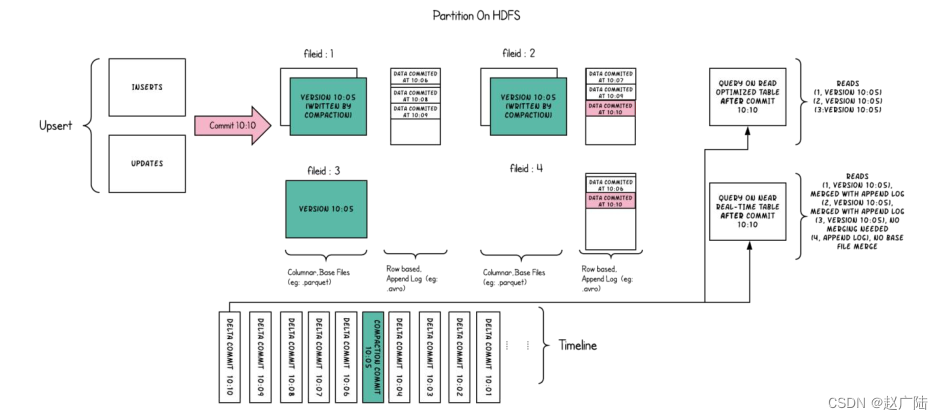
MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。
■优点:由于写入数据先写delta log,且delta log较小,所以写入成本较低;
■缺点:需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并;
对于这类 Table,提供了三种查询:
■Snapshot Query: 查询最近一次 snapshot 的数据,也就是最新的数据。这里是一个行列数据混合的查询。
■Incrementabl Query:用户需要指定一个 commit time,然后 Hudi 会扫描文件中的记录,过滤出 commit_time > 用户指定的 commit time 的记录。这里是一个行列数据混合的查询。
■Read Optimized Query: 只查存量数据,不查增量数据,因为使用的都是列式文件格式,所以效率较高。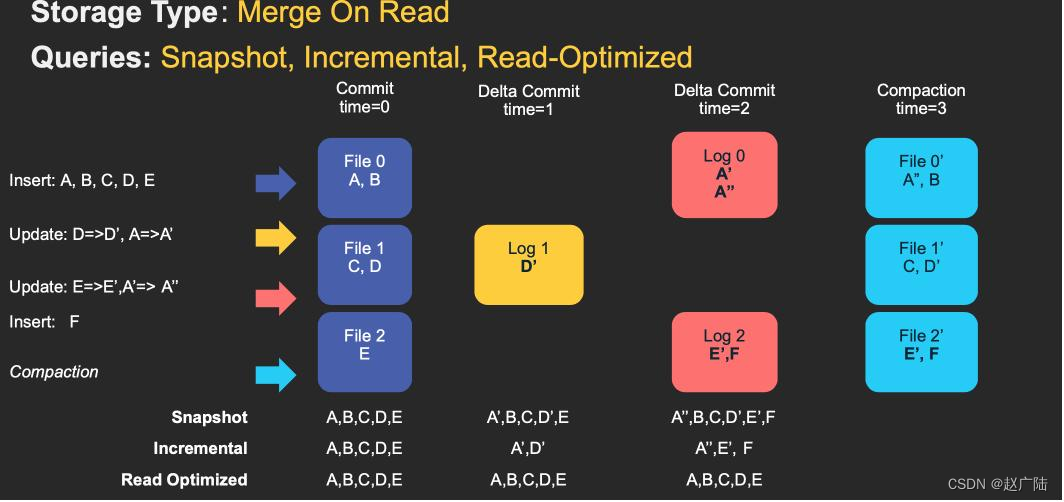
MOR表是COW表的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。在更新记录时,类似NoSQL中的LSM-Tree更新。
■1) 更新:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,最后创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。
■2) 读取:在读取数据集时,需要先将增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
2.5 COW和MOR对比
对于写时复制(COW)和读时合并(MOR)writer来说,Hudi的WriteClient是相同的。
■COW表,用户在 snapshot 读取的时候会扫描所有最新的 FileSlice 下的 base file。
■MOR表,在 READ OPTIMIZED 模式下,只会读最近的经过 compaction 的 commit。

3 数据写操作流程
在Hudi数据湖框架中支持三种方式写入数据:UPSERT(插入更新)、INSERT(插入)和BULK INSERT(写排序)。
■UPSERT:默认行为,数据先通过 index 打标(INSERT/UPDATE),有一些启发式算法决定消息的组织以优化文件的大小
■INSERT:跳过 index,写入效率更高
■BULK_INSERT:写排序,对大数据量的 Hudi 表初始化友好,对文件大小的限制 best effort(写 HFile)
3.1 UPSERT 写流程
由于Hudi中表的类型分为:COW和MOR,所以UPSERT写入数据时,具体流程也是有区别的。
3.1.1 Copy On Write
■第一步、先对 records 按照 record key 去重;
■第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入);
■第三步、对于 update 消息,会直接找到对应 key 所在的最新 FileSlice 的 base 文件,并做 merge 后写新的 base file (新的 FileSlice);
■第四步、对于 insert 消息,会扫描当前 partition 的所有 SmallFile(小于一定大小的 base file),然后 merge 写新的 FileSlice;如果没有 SmallFile,直接写新的 FileGroup + FileSlice;
3.1.2 Merge On Read
■第一步、先对 records 按照 record key 去重(可选)
■第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入)
■第三步、如果是 insert 消息,如果 log file 不可建索引(默认),会尝试 merge 分区内最小的 base file (不包含 log file 的 FileSlice),生成新的 FileSlice;如果没有 base file 就新写一个 FileGroup + FileSlice + base file;如果 log file 可建索引,尝试 append 小的 log file,如果没有就新写一个 FileGroup + FileSlice + base file
■第四步、如果是 update 消息,写对应的 file group + file slice,直接 append 最新的 log file(如果碰巧是当前最小的小文件,会 merge base file,生成新的 file slice)log file 大小达到阈值会 roll over 一个新的
3.2 INSERT 写流程
同样由于Hudi中表的类型分为:COW和MOR,所以INSERT写入数据时,流程也是有区别的。
3.2.1 Copy On Write
■第一步、先对 records 按照 record key 去重(可选);
■第二步、不会创建 Index;
■第三步、如果有小的 base file 文件,merge base file,生成新的 FileSlice + base file,否则直接写新的 FileSlice + base file;
3.2.2 Merge On Read
■第一步、先对 records 按照 record key 去重(可选);
■第二步、不会创建 Index;
■第三步、如果 log file 可索引,并且有小的 FileSlice,尝试追加或写最新的 log file;如果 log file 不可索引,写一个新的 FileSlice + base file