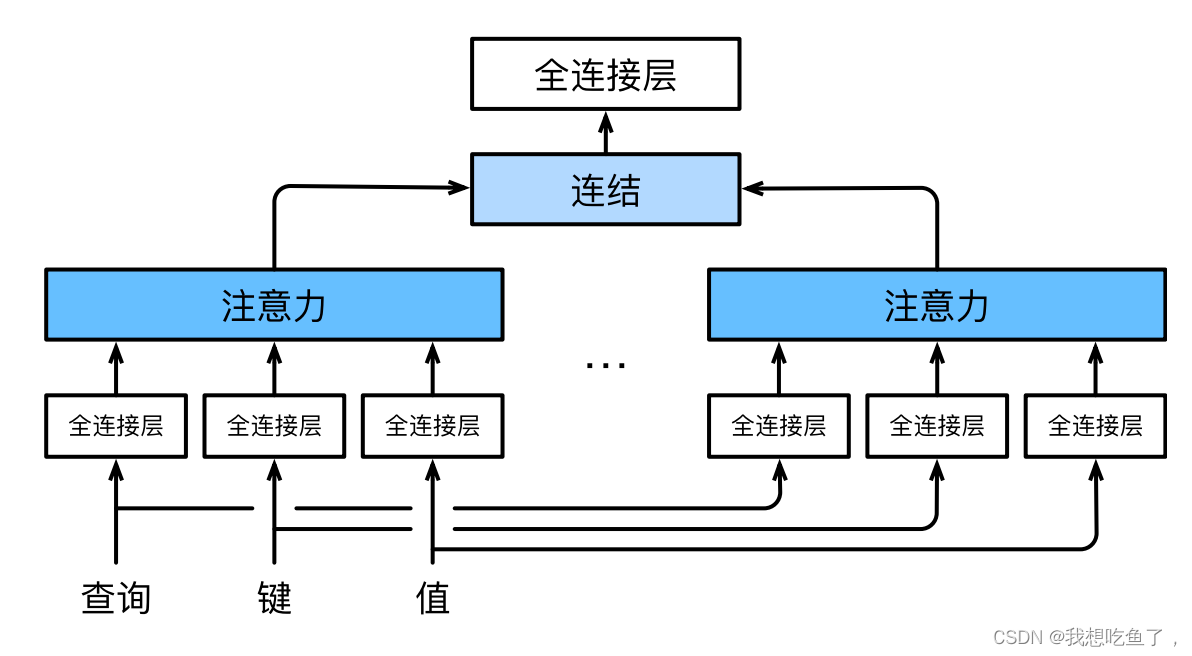
终于到变形金刚了,他的主要特征在于多头自注意力的使用,以及摒弃了rnn的操作。
目录
1.原理
2.多头注意力
3.逐位前馈网络FFN
4.层归一化
5.残差连接
6.Encoder
7.Decoder
8.训练
9.预测
1.原理
主要贡献:1.纯使用attention的Encoder-Decoder;2.Encoder与Decoder都有n个transformer块;3.每个块使用多头自注意力、层归一化、逐位前馈网络
原理图如下图所示:
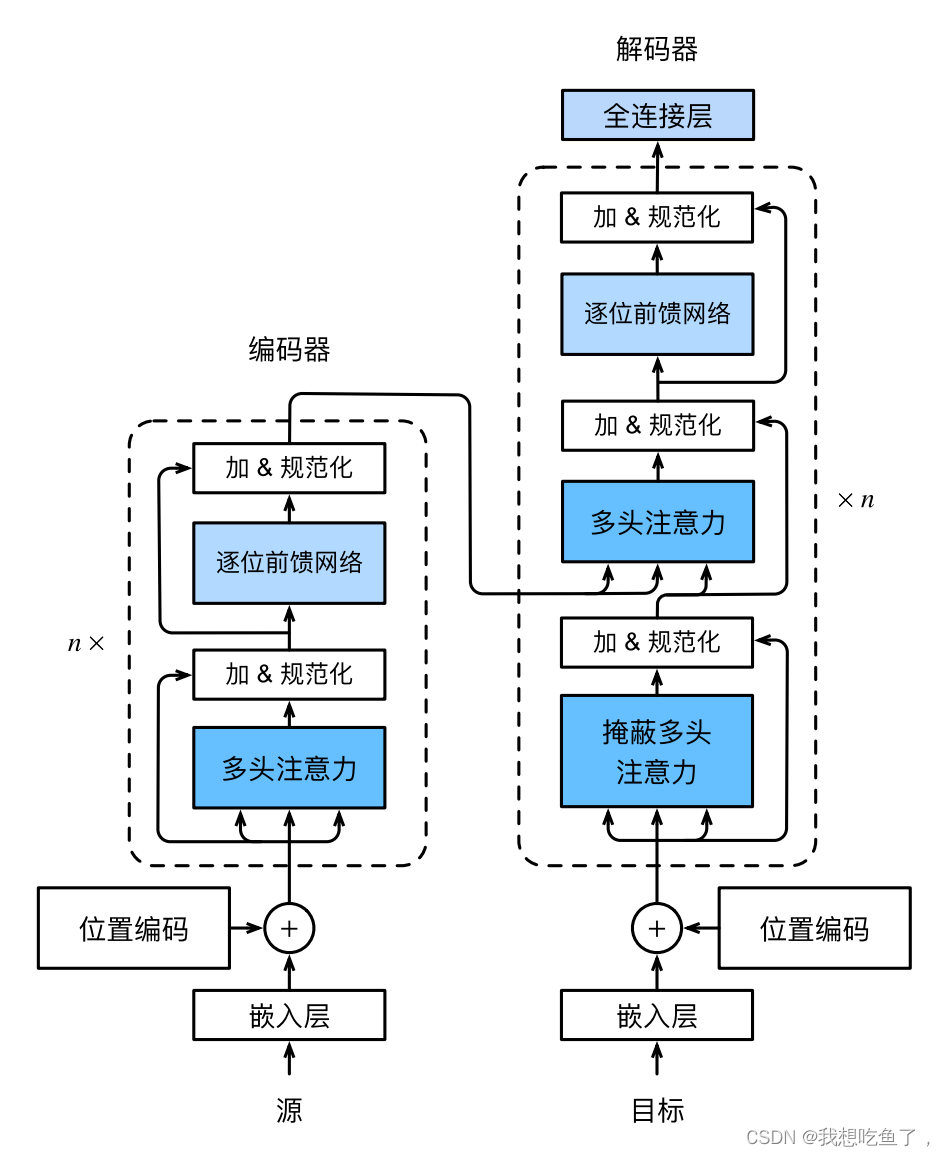
Decoder掩蔽多头注意力:Decoder输出预测时,不应该考虑该元素之后的元素(模拟真实预测),计算Xi输出是,假设当前序列长度为i。对于(Xi+1,Xi+1)...的k-v忽略。
2.多头注意力
通过FC将qvk映射到不同的dimension,使用n个独立的注意力池化层,再合并各个头的输出,在经过FC拿到想要的最终维数
#@save
class MultiHeadAttention(nn.Module):"""多头注意⼒"""def __init__(self, key_size, query_size, value_size, num_hiddens,num_heads, dropout, bias=False, **kwargs):super(MultiHeadAttention, self).__init__(**kwargs)self.num_heads = num_headsself.attention = d2l.DotProductAttention(dropout)self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward(self, queries, keys, values, valid_lens):# queries,keys,values的形状:# (batch_size,查询或者“键-值”对的个数,num_hiddens)# valid_lens 的形状:# (batch_size,)或(batch_size,查询的个数)# 经过变换后,输出的queries,keys,values 的形状:# (batch_size*num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)queries = transpose_qkv(self.W_q(queries), self.num_heads)keys = transpose_qkv(self.W_k(keys), self.num_heads)values = transpose_qkv(self.W_v(values), self.num_heads)if valid_lens is not None:# 在轴0,将第⼀项(标量或者⽮量)复制num_heads次,# 然后如此复制第⼆项,然后诸如此类。valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)# output的形状:(batch_size*num_heads,查询的个数,# num_hiddens/num_heads)output = self.attention(queries, keys, values, valid_lens)# output_concat的形状:(batch_size,查询的个数,num_hiddens)output_concat = transpose_output(output, self.num_heads)return self.W_o(output_concat) 避免有几个多头就写n个for-loop:把原本(bs,q,h)拆成(bs*n,q,h/n),本质是原本单个h的self.attention复制成了n个h/n的self.attention
W_q(queries)--(bs,q,h)--qkv--(bs*n,q,h/n)
映射输入q,k,v的都一样,都是通过grad的反向梯度下降玄学分工。类似于GoogLenet里面的分很多块最后再concat。
3维可直接送到attention中P290,注意self.attention的输出形状与query一致。
下面的transpose_output是你想qkv操作,最终返回(bs,q,h),本质是将n个h/n进行concat,实现多个多注意头拼接操作。
#@save
def transpose_qkv(X, num_heads):"""为了多注意⼒头的并⾏计算⽽变换形状"""# 输⼊X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,# num_hiddens/num_heads)X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)X = X.permute(0, 2, 1, 3)# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,# num_hiddens/num_heads)return X.reshape(-1, X.shape[2], X.shape[3])#@save
def transpose_output(X, num_heads):"""逆转transpose_qkv函数的操作"""X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)3.逐位前馈网络FFN
torch中的Linear只会对最后一个维度当作是特征维进行计算,所以输入的是三维,输出的改变也只有在最后一维改变,所以叫ffn,其本质其实就是mlp。
#@save
class PositionWiseFFN(nn.Module):"""基于位置的前馈⽹络"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):return self.dense2(self.relu(self.dense1(X)))4.层归一化
因为T的有效长度不一,所以用层归一化更稳定。见下图:
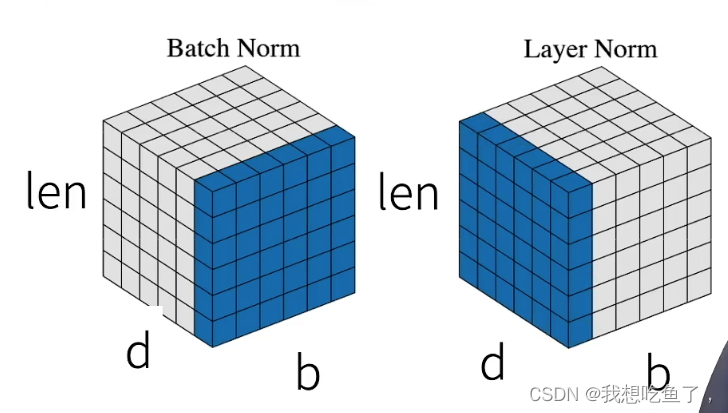
b是bs,d是序列维数,可以理解为有效步长T的valid_len
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和⽅差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))'''
layer norm: tensor([[-1.0000, 1.0000],[-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward0>)
batch norm: tensor([[-1.0000, -1.0000],[ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward0>)
'''如上,可见层归一化是对每个样本(行)变成u=0;std=1。对同一个样本example,同一个feature,不同的diemsion做归一化。
5.残差连接
Y为transformer的输出,X为原始输入。
#@save
class AddNorm(nn.Module):"""残差连接后进⾏层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)注意,残差相加连接,必须维度与里面的维数全都一样才行,且相加也不会导致形状变化!!
6.Encoder
编码块
#@save
class EncoderBlock(nn.Module):"""transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens) # ffn_num_output设置的是num_hiddensself.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y)) 总结一下,transformer的encoder的输出与输入的形状一致,不会改变输入的形状,容易使用n块叠加
原因:1.self.attention里面的qkv都是X,输出与query一致,所以不会改变形状,还是X;2.addnorm是加法操作,tensor只有维度与维数一摸一样才能相加,且不会改变形状;3.ffn里面的ffn_num_output最后设置的是num_hiddens,与输入的X相一致,所以ffn也不会改变形状
#@save
class TransformerEncoder(d2l.Encoder):"""transformer编码器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因为位置编码值在-1和1之间,# 因此嵌⼊值乘以嵌⼊维度的平⽅根进⾏缩放,# 然后再与位置编码相加。X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self.attention_weights = [None] * len(self.blks)for i, blk in enumerate(self.blks):X = blk(X, valid_lens)self.attention_weights[i] = blk.attention.attention.attention_weightsreturn X7.Decoder
解码块:有两个attention,一个是掩蔽多头自注意力,,一个是编码器-解码器注意力,以及逐位前馈网络ffn。
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout)def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]# 训练阶段,输出序列的所有词元都在同⼀时间处理,# 因此state[2][self.i]初始化为None。# 预测阶段,输出序列是通过词元⼀个接着⼀个解码的,# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表⽰if state[2][self.i] is None:key_values = Xelse:key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_valuesif self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens的开头:(batch_size,num_steps),# 其中每⼀⾏是[1,2,...,num_steps]dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:dec_valid_lens = None# ⾃注意⼒X2 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, X2)# 编码器-解码器注意⼒。# enc_outputs的开头:(batch_size,num_steps,num_hiddens)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state注意,Y2中的k-v来自encoder的输出。
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, dropout, i))self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):return [enc_outputs, enc_valid_lens, [None] * self.num_layers]def forward(self, X, state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self._attention_weights = [[None] * len(self.blks) for _ in range (2)]for i, blk in enumerate(self.blks):X, state = blk(X, state)# 解码器⾃注意⼒权重self._attention_weights[0][i] = blk.attention1.attention.attention_weights# “编码器-解码器”⾃注意⼒权重self._attention_weights[1][i] = blk.attention2.attention.attention_weightsreturn self.dense(X), state@propertydef attention_weights(self):return self._attention_weights补充:经过dec_x经过解码器形状也不会改变
8.训练
重要的两个参数:h、p(num_heads)
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
训练时,k-v就是dec_x的输入x---自注意力
9.预测
原代码有错,要对predict_seq2seq改一下,把net.decoder直接改成Decoder的class即可。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ',f'bleu {d2l.bleu(translation, fra, k=2):.3f}')'''
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est <unk> ., bleu 0.658
i'm home . => je suis ., bleu 0.432
'''