多维数组库numpy

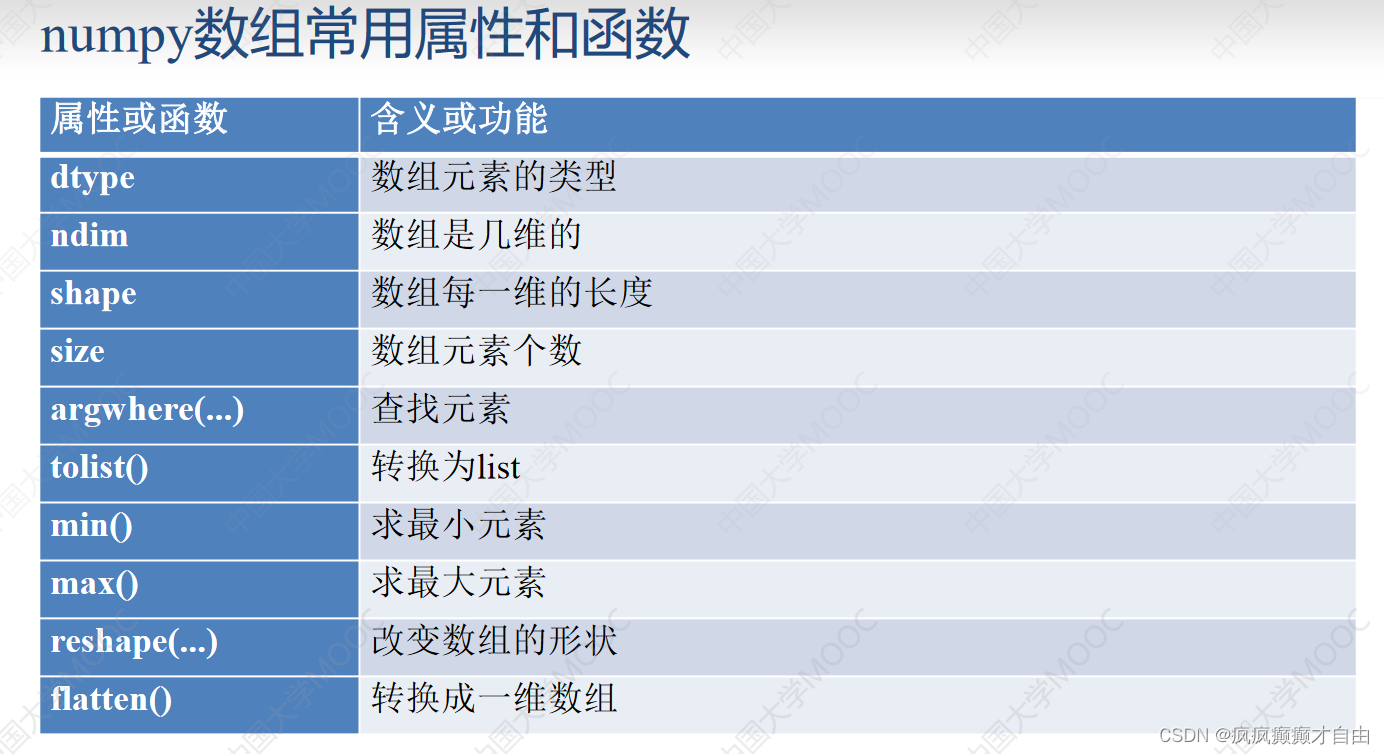
numpy创建数组的常用函数

# numpy数组import numpy as np #以后numpy简写为np
print(np.array([1,2,3])) #>>[1 2 3]
print(np.arange(1,9,2)) #>>[1 3 5 7] 不包括9
print(np.linspace(1,10,4)) #>>[ 1. 4. 7. 10.]
# linespace(x,y,n),创建一个由区间[x,y]的n-1等分点构成的一维数组,包含x和yprint(np.random.randint(10,20,[2,3]))
#>>[[12 19 12]
#>> [19 13 10]]print(np.random.randint(10,20,5)) #>>[12 19 19 10 13]
a = np.zeros(3)
print(a) #>>[ 0. 0. 0.]
print(list(a)) #>>[0.0, 0.0, 0.0]
# 列表每个元素之间有一个逗号隔开a = np.zeros((2,3),dtype=int) #创建一个2行3列的元素都是整数0的数组
print(a)numpy数组常用属性和函数
# numpy数组常用属性和函数import numpy as np
b = np.array([i for i in range(12)])
#b是[ 0 1 2 3 4 5 6 7 8 9 10 11]
print(b)a = b.reshape((3,4)) #转换成3行4列的数组,b不变
print(len(a)) #>>3 a有3行
print(a.size) #>>12 a的元素个数是12
print(a.ndim) #>>2 a是2维的
print(a.shape) #>>(3, 4) a是3行4列
print(a.dtype) #>>int32 a的元素类型是32位的整数
L = a.tolist() #转换成列表,a不变
print(L)
#>>[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]]
b = a.flatten() #转换成一维数组
print(b) #>>[ 0 1 2 3 4 5 6 7 8 9 10 11 ]numpy数组元素的增删

# numpy添加数组元素import numpy as np
a = np.array((1,2,3)) #a是[1 2 3]
b = np.append(a,10) #a不会发生变化
print(a)
print(b) #>>[ 1 2 3 10]
print(np.append(a,[10,20])) #>>[ 1 2 3 10 20]
c = np.zeros((2,3),dtype=int) #c是2行3列的全0数组
print(np.append(a,c)) #>>[1 2 3 0 0 0 0 0 0]
print(np.concatenate((a,[10,20],a)))
#>>[ 1 2 3 10 20 1 2 3]
print(np.concatenate((c,np.array([[10,20,30]]))))
#c拼接一行[10,20,30]得新数组
print(np.concatenate((c,np.array([[1,2],[10,20]])),axis=1))
#c的第0行拼接了1,2两个元素、第1行拼接了10,20两个新元素后得到新数素# numpy删除数组元素import numpy as np
a = np.array((1,2,3,4))
b = np.delete(a,1) #删除a中下标为1的元素,a不会改变
print(b) #>>[1 3 4]
b = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print("b删除前:\n",b,"\nb删除后:")print("按行删除:\n", np.delete(b,1,axis=0)) #删除b的第1行得新数组print("按列删除:\n", np.delete(b,1,axis=1)) #删除b的第1行得新数组#>>[[ 1 2 3 4]
#>> [ 9 10 11 12]]
print(np.delete(b,1,axis=1)) #删除b的第1列得新数组
print(np.delete(b,[1,2],axis=0)) #删除b的第1行和第2行得新数组
print(np.delete(b,[1,3],axis=1)) #删除b的第1列和第3列得新数组在numpy数组中查找元素
- np.argwhere( a ):返回非0的数组元组的索引,其中a是要索引数组的条件。
- np.where(condition) 当where内只有一个参数时,那个参数表示条件,当条件成立时, where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式。
# 在numpy数组中查找元素import numpy as np
a = np.array((1,2,3,5,3,4))
print("a: ", a)pos = np.argwhere(a==3) #pos是[[2] [4]]
print(pos)
# np.argwhere( a ):返回非0的数组元组的索引,其中a是要索引数组的条件。a = np.array([[1,2,3],[4,5,2]])
print(2 in a) #>>True
pos = np.argwhere(a==2) #pos是[[0 1] [1 2]]
print(pos)b = a[a>2] #抽取a中大于2的元素形成一个一维数组
print(b) #>>[3 4 5]
a[a > 2] = -1 #a变成[[ 1 2 -1] [-1 -1 2]]
print(a)
numpy数组的切片
numpy数组的切片是“视图”,是原数组的一部分,而非一部分的拷贝
# numpy数组的切片是“视图”,是原数组的一部分,而非一部分的拷贝import numpy as np
a = np.arange(8) #a是[0 1 2 3 4 5 6 7]
b = a[3:6] #注意,b是a的一部分
print(b) #>>[3 4 5]
c = np.copy(a[3:6]) #c是a的一部分的拷贝
b[0] = 100 #会修改a
print(a) #>>[ 0 1 2 100 4 5 6 7]
print(c) #>>[3 4 5] c不受b影响
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]])
print("a:\n", a)b = a[1:3,1:4] #b是>>[[ 6 7 8] [10 11 12]]
print("b:\n", b)数据分析库pandas
Pandas 属于 Python 第三方数据处理库,它基于 NumPy 构建而来,主要用于数据的处理与分析。我们知道对于机器学习而言数据是尤为重要,如果没有数据就无法训练模型。Pandas 提供了一个简单高效的 DataFrame 对象(类似于电子表格),它能够完成数据的清洗、预处理以及数据可视化工作等。除此之外,Pandas 能够非常轻松地实现对任何文件格式的读写操作,比如 CSV 文件、json 文件、excel 文件。(小伟学长:第三节 基本人工智能工具的介绍与使用 · 语雀)
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Pandas 主要的数据结构是 Series(一维)与 DataFrame(二维)
Series是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据,轴标签统称为索引.。
Pandas会默然用0到n-1来作为series的index,但也可以自己指定index(可以把index理解为dict里面的key)。
Series的使用
import pandas as pd
s = pd.Series(data = [80, 90, 100], index = ['Chinese', 'Math', 'English'])
# pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
# Pandas 主要的数据结构是 Series(一维)与 DataFrame(二维)print(s)for x in s:print(x, end = ' ') # x是data,不输出index
print("#####################")print(s['Chinese'], s[1])
print(s[0:2]['Math'])
print(s['Math':'English'][1])
for i in range(len(s.index)): #>>语文 数学 英语print(s.index[i],end = " $ ")
print('')
s['体育'] = 110 #在尾部添加元素,标签为'体育',值为110
s.pop('Math') #删除标签为'数学’的元素
s2 = s._append(pd.Series(120,index = ['政治'])) #不改变s
# pandas在0.20.0后移除这个append方法,你可以使用 _append 来替换append。print(s2['Chinese'],s2['政治']) #>>80 120
print(list(s2)) #>>[80, 100, 110, 120]print("s:\n", s)
print(s.sum(),s.min(),s.mean(),s.median())
#>>290 80 96.66666666666667 100.0 输出和、最小值、平均值、中位数
print(s.idxmax(),s.argmax()) #>>体育 2 输出最大元素的标签和下标DataFrame的使用
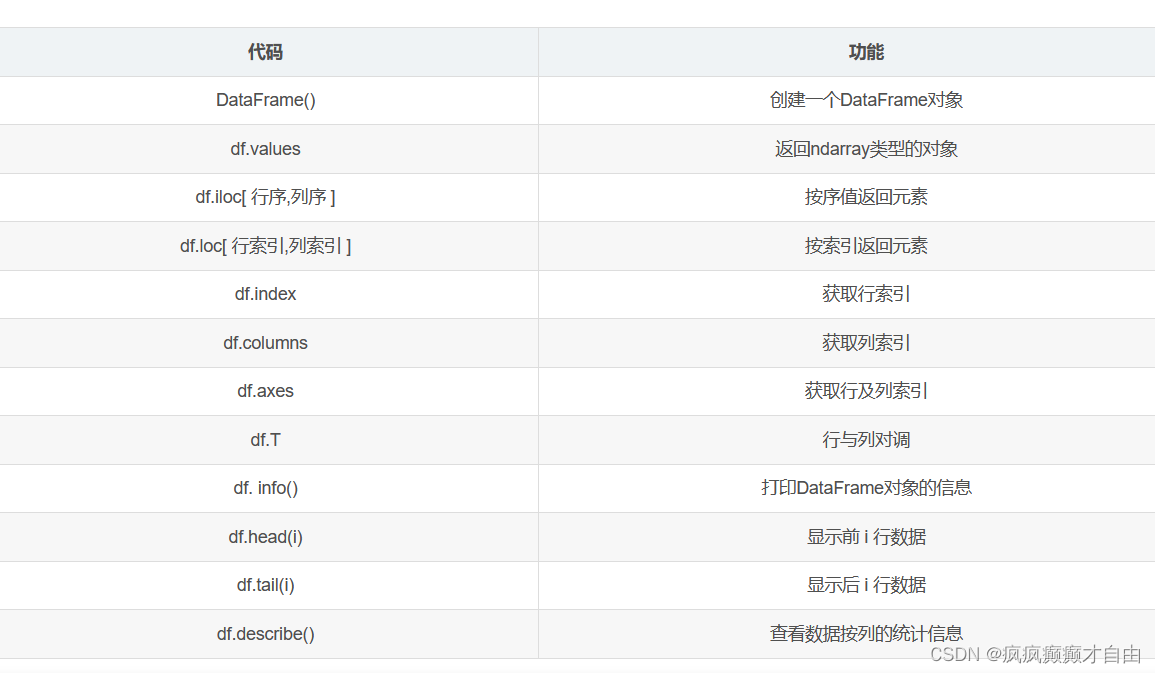
DataFrame是带行列标签的二维表格,它的每一列都是一个Series
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
【参考文章】:Pandas DataFrame的基本属性详解_pd.dataframe()有哪些参数-CSDN博客
DataFrame的构造和访问
# DataFrame的构造和访问
# DataFrame是带行列标签的二维表格,它的每一列都是一个Seriesimport pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
#输出对齐方面的设置scores = [['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]
names = ['刘一哥','王二姐','张三妹','李四弟']
courses = ['性别','语文','数学','英语']
df = pd.DataFrame(data=scores,index = names,columns = courses)
# pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)print("df:")
print(df)print("df.values:")
print(df.values)
print("**************")print(df.values[0][1],type(df.values))#>>108 <class 'numpy.ndarray'>
print(list(df.index)) #>>['刘一哥', '王二姐', '张三妹', '李四弟']
print(list(df.columns)) #>>['性别', '语文', '数学', '英语']
print(df.index[2],df.columns[2]) #>>张三妹 数学
s1 = df['语文'] #s1是个Series,代表'语文'那一列
print("语文那一列:")
print(s1)print(s1['刘一哥'],s1[0]) #>>108 108 刘一哥语文成绩
print(df['语文']['刘一哥']) #>>108 列索引先写
s2 = df.loc['王二姐'] #s2也是个Series,代表“王二姐”那一行
print(s2['性别'],s2['语文'],s2[2])
#>>女 115 87 王二姐的性别、语文和数学分数
DataFrame的切片:
#DataFrame的切片:
#iloc[行选择器, 列选择器] 用下标做切片
#loc[行选择器, 列选择器] 用标签做切片
#DataFrame的切片是视图
df2 = df.iloc[1:3] #行切片,是视图,选1,2两行
df2 = df.loc['王二姐':'张三妹'] #和上一行等价
print(df2)df2 = df.iloc[:,0:3] #列切片(是视图),选0、1、2三列
df2 = df.loc[:,'性别':'数学'] #和上一行等价
print(df2)df2 = df.iloc[:2,[1,3]] #行列切片
df2 = df.loc[:'王二姐',['语文','英语']] #和上一行等价
print(df2)df2 = df.iloc[[1,3],2:4] #取第1、3行,第2、3列
df2 = df.loc[['王二姐','李四弟'],'数学':'英语'] #和上一行等价
print(df2)
DataFrame的分析统计
# DataFrame的分析统计print("---下面是DataFrame的分析和统计---")
print(df.T) #df.T是df的转置矩阵,即行列互换的矩阵
print(df.sort_values('语文',ascending=False)) #按语文成绩降序排列
# sort_values(....inplace=True,axis=1....) 则原地排序,将各列排序print(df.iloc[:, 1:].sum()['语文'],df.iloc[:, 1:].mean()['数学'],df.iloc[:, 1:].median()['英语'])
# >>435 85.5 101.0 语文分数之和、数学平均分、英语中位数
print(df.iloc[:, 1:].min()['语文'],df.iloc[:, 1:].max()['数学'])
#>>100 115 语文最低分,数学最高分print(df.iloc[:, 1:].max(axis = 1)['王二姐']) #>>115 王二姐的最高分科目的分数
print(df['语文'].idxmax()) #>>王二姐 语文最高分所在行的标签
print(df['数学'].argmin()) #>>2 数学最低分所在行的行号
print(df.loc[(df['语文'] > 100) & (df['数学'] >= 85)])
DataFrame的修改和增删
# DataFrame的修改和增删print("---下面是DataFrame的增删和修改---")
df.loc['王二姐','英语'] = df.iloc[0,1] = 150 #修改王二姐英语和刘一哥语文成绩df['物理'] = [80,70,90,100] #为所有人添加物理成绩这一列
df.insert(1,"体育",[89,77,76,45]) #为所有人插入体育成绩到第1列
df.loc['李四弟'] = ['男',100,100,100,100,100] #修改李四弟全部信息
df.loc[:,'语文'] = [20,20,20,20] #修改所有人语文成绩
df.loc['钱五叔'] = ['男',100,100,100,100,100] #加一行
df.loc[:,'英语'] += 10 #>>所有人英语加10分
df.columns = ['性别','体育','语文','数学','English','物理'] #改列标签
print(df)删除函数是axis=0表示行,axis = 1表示列。
除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行。
链接:axis = 0,axis = 1到底表示按行计算还是按列计算-CSDN博客
df.drop( ['体育','物理'],axis=1, inplace=True) #删除体育和物理成绩
df.drop( '王二姐',axis = 0, inplace=True) #删除 王二姐那一行
print(df)用pandas读excel文档,读取的每张工作表都是一个DataFrame
# 用pandas读excel文档,读取的每张工作表都是一个DataFrameimport pandas as pdpd.set_option('display.unicode.east_asian_width',True)dt = pd.read_excel(r"D:\桌面\excel.xlsx",sheet_name=[0], index_col=0)#读取第0和第1张工作表df = dt[0] #dt是字典,df是DataFrame
print(df.iloc[0,0]) #>>4080 4080
print(df)不想写了,把郭炜老师的讲义截屏下来,后面想深入学习再来看。



pandas读写csv文件

matplotlib
绘制基本直方图
matplotlib.pyplot.figure():
- Create a new figure, or activate an existing figure.
- 功能: 创建一个新的图形 或激活一个已有的图形
- **注意: 若不添加描述,默认图形描述为figure1; **
函数原型 subplot(nrows, ncols, index, **kwargs),一般我们只用到前三个参数,将整个绘图区域分成 nrows 行和 ncols 列,而 index 用于对子图进行编号。
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号

【参考链接】python matplotlib fig = plt.figure() fig.add_subplot()-CSDN博客
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
注:
ax.set系列函数 的语法与 plt 等效
ax.set_ylabel() plt.ylabel()
ax.set_xlabel() plt.xlabel()
ax.set_xticks() plt.xticks()
绘制基本直方图:
# 绘制基本直方图import matplotlib.pyplot as plt #以后 plt 等价于 matplotlib.pyplot
from matplotlib import rcParams
'''
rcParams 是 Matplotlib 库中的一个字典对象,用于存储和管理全局的默认参数配置。
在 Matplotlib 中,可以通过修改 rcParams 中的参数值来改变图形的默认行为。这些参数包括
图形的颜色、线型、线宽、字体样式、图像分辨率等。
rcParams 的全称是“runtime configuration parameters”,它在运行时控制着 Matplotlib 的行为。
通过修改 rcParams 中的参数,您可以自定义 Matplotlib 的默认设置,使其符合您的需求,
而无需在每个图形绘制时都手动指定这些参数。
'''rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体ax = plt.figure().add_subplot() #建图,获取子图对象ax
'''
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号
'''ax.bar(x = (0.2,0.6,0.8,1.2),height = (1,2,3,0.5), width = 0.1)
#x表示4个柱子中心横坐标分别是0.2,0.6,0.8,1.2
#height表示4个柱子高度分别是1,2,3,0.5
#width表示柱子宽度0.1'''
ax.bar(x, height, width, bottom, align)
该函数的参数说明,如下表所示:
x 一个标量序列,代表柱状图的x坐标,默认x取值是每个柱状图所在的中点位置,或者也可以是柱状图左侧边缘位置。
height 一个标量或者是标量序列,代表柱状图的高度。
width 可选参数,标量或类数组,柱状图的默认宽度值为 0.8。
bottom 可选参数,标量或类数组,柱状图的y坐标默认为None。
algin 有两个可选项 {“center”,“edge”},默认为 ‘center’,该参数决定 x 值位于柱状图的位置。
该函数的返回值是一个 Matplotlib 容器对象,该对象包含了所有柱状图。
'''
ax.set_title ('我的直方图') #设置标题
'''
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
'''plt.show()
绘制横向直方图:
barh(y, width, height=0.8, left=None, *, align='center', **kwargs)
matplotlib.pyplot.barh()绘制的都是水平条形图
y,width,height与bar()里的x,height,width相反
left等同于bar()里的bottom 不同的时left作用于x轴,bottom作用于y轴
其他参数作用与bar()参数一致
# 绘制横向直方图import matplotlib.pyplot as plt #以后 plt 等价于 matplotlib.pyplot
from matplotlib import rcParams
'''
rcParams 是 Matplotlib 库中的一个字典对象,用于存储和管理全局的默认参数配置。
在 Matplotlib 中,可以通过修改 rcParams 中的参数值来改变图形的默认行为。这些参数包括
图形的颜色、线型、线宽、字体样式、图像分辨率等。
rcParams 的全称是“runtime configuration parameters”,它在运行时控制着 Matplotlib 的行为。
通过修改 rcParams 中的参数,您可以自定义 Matplotlib 的默认设置,使其符合您的需求,
而无需在每个图形绘制时都手动指定这些参数。
'''# rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体ax = plt.figure().add_subplot() #建图,获取子图对象ax
'''
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号
'''ax.barh(y = (0.2,0.6,0.8,1.2),width = (1,2,3,0.5), height = 0.1)
'''
barh(y, width, height=0.8, left=None, *, align='center', **kwargs)matplotlib.pyplot.barh()绘制的都是水平条形图y,width,height与bar()里的x,height,width相反left等同于bar()里的bottom 不同的时left作用于x轴,bottom作用于y轴其他参数作用与bar()参数一致
'''ax.set_title ('我的直方图') #设置标题
'''
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
'''plt.show()
绘制堆叠直方图
# 绘制堆叠直方图import matplotlib.pyplot as plt
ax = plt.figure().add_subplot()
labels = ['Jan', 'Feb', 'Mar', 'Apr']
num1 = [20, 30, 15, 35] #Dept1的数据
num2 = [15, 30, 40, 20] #Dept2的数据
cordx = range(len(num1)) #x轴刻度位置
rects1 = ax.bar(x = cordx, height=num1, width=0.5, color='red',label="Dept1")
rects2 = ax.bar(x = cordx, height=num2, width=0.5, color='green',label="Dept2", bottom=num1)
# ax.bar(x, height, width, bottom, align)ax.set_ylim(0, 100) #y轴坐标范围
ax.set_ylabel("Profit") #y轴含义(标签)
ax.set_xticks(cordx) #设置x轴刻度位置,也就是在坐标轴下多出来的一竖
ax.set_xticklabels(labels) #设置x轴刻度下方文字
ax.set_xlabel("In year 2020") #x轴含义(标签)
ax.set_title("My Company") #设置图像名
'''
ax.set系列函数 的语法与 plt 等效
ax.set_ylabel() plt.ylabel()
ax.set_xlabel() plt.xlabel()
ax.set_xticks() plt.xticks()
'''ax.legend(loc = 2) #在右上角显示图例说明
'''
ax.legend()作用:在图上标明一个图例,用于说明每条曲线的文字显示
legend()有一个loc参数,用于控制图例的位置。 比如 plot.legend(loc=2) ,
这个位置就是4象项中的第二象项,也就是左上角。 loc可以为1,2,3,4 这四个数字。
'''plt.show()绘制对比直方图(有多组数据)
# 绘制对比直方图(有多组数据)import matplotlib.pyplot as plt
ax = plt.figure(figsize=(10,5)).add_subplot()#建图,获取子图对象ax
ax.set_ylim(0,400) #指定y轴坐标范围
ax.set_xlim(0,80) #指定x轴坐标范围#以下是3组直方图的数据
x1 = [7, 17, 27, 37, 47, 57] #第一组直方图每个柱子中心点的横坐标
x2 = [13, 23, 33, 43, 53, 63] #第二组直方图每个柱子中心点的横坐标
x3 = [10, 20, 30, 40, 50, 60]
y1 = [41, 39, 13, 69, 39, 14] #第一组直方图每个柱子的高度
y2 = [123, 15, 20, 105, 79, 37] #第二组直方图每个柱子的高度
y3 = [124, 91, 204, 264, 221, 175]rects1 = ax.bar(x1, y1, facecolor='red', width=3, label = 'Iphone')
rects2 = ax.bar(x2, y2, facecolor='green', width=3, label = 'Huawei')
rects3 = ax.bar(x3, y3, facecolor='blue', width=3, label = 'Xiaomi')ax.set_xticks(x3) #x轴在x3中的各坐标点下面加刻度
ax.set_xticklabels(('A1','A2','A3','A4','A5','A6')) #指定x轴上每一刻度下方的文字
ax.legend() #显示右上角三组图的说明def label(ax,rects): #在rects的每个柱子顶端标注数值for rect in rects:height = rect.get_height()ax.text(rect.get_x() + rect.get_width()/2, height+14, str(height),rotation=90) #文字旋转90度
# rect.get_x()获取rect这一条形左边的x坐标的值'''ax.text(x, y, s, fontdict=None, withdash=False, **kwargs):文本注释,只能填写文本 ;x,y:注释的坐标位置(标量)s:注释的内容(字符串) fontdict:重新设置注释内容的文本格式,包括字体颜色、背景大小和颜色、字体大小等(字典)withdash:创建一个替代注释内容“s”的对象,参照英文单词解释,这应该是一个破折号 ;rotation是kwargs中的一个参数rotation: [ angle in degrees| 'vertical'(垂直的) | 'horizontal(水平的)' ] '''label(ax,rects1)
label(ax,rects2)
label(ax,rects3)
plt.show()
绘制折线和散点图
# 绘制折线和散点图import math,random
import matplotlib.pyplot as pltrcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体0def drawPlot(ax):xs = [i / 100 for i in range(1500)] #1500个点的横坐标,间隔0.01ys = [10*math.sin(x) for x in xs]#对应曲线y=10*sin(x)上的1500个点的y坐标ax.plot(xs,ys,"red",label = "Beijing") #画曲线y=10*sin(x)ys = list(range(-18,18))random.shuffle(ys) #将ys打乱ax.scatter(range(16), ys[:16], c = "blue") #画散点ax.plot(range(16), ys[:16], "blue", label="Shanghai") #画折线ax.legend() #显示右上角的各条折线说明ax.set_xticks(range(16)) #x轴在坐标0,1...15处加刻度ax.set_xticklabels(range(16)) #指定x轴每个刻度下方显示的文字ax = plt.figure(figsize=(10, 4),dpi=100).add_subplot() #图像长宽和清晰度(dpi)
drawPlot(ax)
plt.show()饼状图
matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, *, normalize=True, data=None)


参考文章:python绘制饼图的方法详解_python_脚本之家
# 绘制饼图import matplotlib.pyplot as plt
def drawPie(ax):lbs = ('A', 'B', 'C', 'D') #四个扇区的标签sectors = [16, 29.55, 44.45, 10] #四个扇区的份额(百分比)expl = [0, 0.1, 0, 0] #四个扇区的突出程度ax.pie(x=sectors, labels=lbs, explode=expl, autopct='%.2f', shadow=True, labeldistance=1.1,pctdistance = 0.6,startangle = 90)'''matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, *, normalize=True, data=None)'''ax.set_title("pie sample") #饼图标题ax = plt.figure().add_subplot()
drawPie(ax)
plt.show()绘制雷达图(了解)
# 绘制雷达图import matplotlib.pyplot as plt
from matplotlib import rcParams #处理汉字用
def drawRadar(ax):pi = 3.1415926labels = ['EQ','IQ','人缘','魅力','财富','体力'] #6个属性的名称attrNum = len(labels) #attrNum是属性种类数,此处等于6data = [7,6,8,9,8,2] #六个属性的值angles = [2*pi*i/attrNum for i in range(attrNum)]#angles是以弧度为单位的6个属性对应的6条半径线的角度angles2 = [x * 180/pi for x in angles]#angles2是以角度为单位的6个属性对应的半径线的角度ax.set_ylim(0, 10) #限定半径线上的坐标范围ax.set_thetagrids(angles2,labels,fontproperties="SimHei" )#绘制6个属性对应的6条半径ax.fill(angles,data,facecolor= 'g',alpha=0.25) #填充,alpha:透明度'''matplotlib.pyplot.fill(*args, data=None, **kwargs)*args:这个参数主要填写有序数对和颜色。每个多边形可以使用x坐标和y坐标构造,只要把这些点连接一起,再把里面的空间进行指定的颜色填充。ax.fill(x, y) # 使用默认的颜色填充一个多边形ax.fill(x, y, “b”) # 使用蓝色填充一个多边形ax.fill(x, y, x2, y2) # 使用默认颜色填充两个多边形ax.fill(x, y, “b”, x2, y2, “r”) # 一个蓝色,一个红色'''rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#处理汉字
ax = plt.figure().add_subplot(projection = "polar") #生成极坐标形式子图
drawRadar(ax)
plt.show()
绘制多层雷达图(了解)
# 绘制多层雷达图import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'pi = 3.1415926
labels = ['EQ','IQ','人缘','魅力','财富','体力'] #6个属性的名称
attrNum = len(labels)
names = ('张三','李四','王五')
data = [[0.40,0.32,0.35], [0.85,0.35,0.30],
[0.40,0.32,0.35], [0.40,0.82,0.75],
[0.14,0.12,0.35], [0.80,0.92,0.35]] #三个人的数据angles = [2*pi*i/attrNum for i in range(attrNum)]
angles2 = [x * 180/pi for x in angles]ax = plt.figure().add_subplot(projection = "polar")
ax.fill(angles,data,alpha= 0.25)
ax.set_thetagrids(angles2,labels)
ax.set_title('三巨头人格分析',y = 1.05) #y指明标题垂直位置
ax.legend(names,loc=(0.95,0.9)) #画出右上角不同人的颜色说明
plt.show()
一个窗口绘制多幅图:
matplotlib.pyplot 模块提供了 subplot2grid(),该函数能够在画布的特定位置创建 axes 对象(即绘图区域)。不仅如此,它还可以使用不同数量的行、列来创建跨度不同的绘图区域。与subplot() 和 subplots() 函数不同,subplot2gird()函数以非等分的形式对画布进行切分,并按照绘图区域的大小来展示最终绘图结果。
plt.subplot2grid(shape, location, rowspan, colspan)参数含义如下:
- shape:把该参数值规定的网格区域作为绘图区域;
- location:在给定的位置绘制图形,初始位置 (0,0) 表示第1行第1列;
- rowsapan/colspan:这两个参数用来设置让子区跨越几行几列。
# 一个窗口绘制多幅图:
#程序中的import、汉字处理及drawRadar、drawPie、drawPlot函数略,见前面程序fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(2,2,1) #窗口分割成2*2,取位于第1个方格的子图
drawPie(ax)ax = fig.add_subplot(2,2,2,projection = "polar")
drawRadar(ax)ax = plt.subplot2grid((2, 2), (1, 0), colspan=2)
#或写成: ax = fig.add_subplot(2,1,2)'''
plt.subplot2grid(shape, location, rowspan, colspan)
参数含义如下:shape:把该参数值规定的网格区域作为绘图区域;location:在给定的位置绘制图形,初始位置 (0,0) 表示第1行第1列;rowsapan/colspan:这两个参数用来设置让子区跨越几行几列。
'''drawPlot(ax)plt.figtext(0.05,0.05,'subplot sample') #显示左下角的图像标题
plt.show()