“Inter-fractional portability of deep learning models for lung target tracking on cine imaging acquired in MRI-guided radiotherapy”
2024年 期刊 Physical and Engineering Sciences in Medicine 医学4区
没资源,只读了摘要,用的是U-net、attention U-net 和nested U-net进行跟踪。采用了两种训练策略(均匀训练策略和自适应训练策略)。用DSC和95th HD距离来评估不同策略、不同模型之间的跟踪效果。baseline是一个OBT算法(onboard algorithm),对6名病人来说,OBT实现的平均DSC=0.68±0.16,与OBT相比,均匀训练的三种DL model的DSC提高了17.0−19.3%,基于自适应训练的模型的DSC提高了24.7− 25.7%。
感想:很好奇U-net是怎么执行跟踪的。应该是直接用U-net对肺部进行分割,然后逐帧分割,得到一个分割的annotation,再和ground truth进行比较。
“Learning-based algorithms for vessel tracking: A review”
2021年 期刊 COMPUTERIZED MEDICAL IMAGING AND GRAPHICS 医学2区
介绍了基于机器学习方法和深度学习方法的血管跟踪方案。其实就是
机器学习的部分没咋看,深度学习的跟踪方案部分看得细一点:
- 端到端的跟踪方案(将特征提取和像素分类统一集成到网络模型中)、2-step跟踪方案(DNN用于提取血管特征,ML method用于像素分类)。
- 对于端到端的跟踪方案,其实就是在特征提取之后加入两个及以上的神经元以解决分类或回归问题。
- 对于2-step 跟踪方案,CNN将输入图像映射为位于输入和跟踪结果之间的中间表示;例如,概率图、几何先验和其它特征图。之后,传统的跟踪方法(ML)可以应用于这些学习到的特征,例如仅仅只是一个简单的阈值处理。
However, the scaling operation of the pooling layer is considered to rapidly reduce the already extremely limited information contained in the potentially small patch, causing the classification to be more exigent.
这里说的有点道理,差点忘了这一点。文中还提到有一个工作提出了NOPOOL architecture,效果也还行。
- 还提到了很多基于U-net开展的工作,一般的U-net可能无法提取一些微小血管,因为这种特征积累受到U-net深度的限制。
- 训练策略,共分为:预处理、采样策略、损失函数的制定
- 评估标准:
- 基于重叠程度的指标(准确度、灵敏度、特异性、精确率、召回率、DSC、HD)
- 基于分类的指标(AUC)
感想:感觉和我们的工作还是有点区别,具有一定的参考性,以后可以回来再看看。
“MRI-guided adaptive radiotherapy for liver tumours: visualising the future”
2020年 期刊 LANCET ONCOLOGY 医学肿瘤学1区
本综述概述了 MRI 引导放射治疗在转移性和原发性肝癌方面当前和未来的应用。其中,文章着重提到了一种名为立体定向放射治疗(stereotactic body radiotherapy,SBRT)的技术,并且
reported significant benefits in all relevant clinical outcomes with SBRT compared with conventionally fractionated daily lung treatments.
文中还提到,磁共振成像的最小margin size为2mm,不知道有什么用:
To determine the correct margin size, sources of error or uncertainty have been considered, including MRI geometric distortion, MRI-to-radiation isocentre, multileaf collimator position error, and uncertainties associated with voxel size and tracking. As independent variables, the sum of the square of these uncertainties might be combined, which leads to a minimum margin of 2 mm.
除了照射剂量带来的危害之外,肿瘤、肝脏、附近肠道或胃的运动以及解剖结构的日常变化都会使得问题变得更复杂。
传统的方法主要是基于CT图像提出针对上述问题的解决方案:抑制呼吸运动、考虑肿瘤运动和使用跟踪替代标记物等。然而,这些方法让然导致输送剂量的不确定性,以及不允许实时调整辐射剂量。
文章还总结了磁共振引导放疗的挑战:
- 首先,磁共振图像引导治疗离不开必要的基础设施。该基础设施包括无金属治疗库、相对昂贵的硬件以及经验丰富的物理学家、放射治疗师和医生的深入参与。
- 基于 MRI 的治疗还容易受到伪影带来的特定限制,包括环绕、拉链和金属伪影,以及与患者运动相关的运动伪影问题。除此之外,还有几何失真问题。
感想:感觉这篇文章偏科普性,仔细读完之后能够对磁共振引导放疗研究领域有较为基础的认知。到时候写论文可以在里面找内容对Introduction部分进行补充。
“Neural-network based autocontouring algorithm for intrafractional lung-tumor tracking using Linac-MR”
2015年 期刊 MEDICAL PHYSICS 医学2区 核医学3区
本文提出了一种基于脉冲耦合神经网络(PCNN)的自动轮廓算法,用于分次内的肺部肿瘤跟踪(同时输出肺部肿瘤的位置和形状)。
这个PCNN是什么?百度百科中提到:与BP神经网络和Kohonen神经网络相比,PCNN不需要学习或者训练,能从复杂背景下提取有效信息,具有同步脉冲发放和全局耦合等特性,其信号形式和处理机制更符合人类视觉神经系统的生理学基础。
不需要学习或训练?看了一下《脉冲耦合神经网络原理及其应用》这本书,并没有对PCNN的原理有什么深入了解。
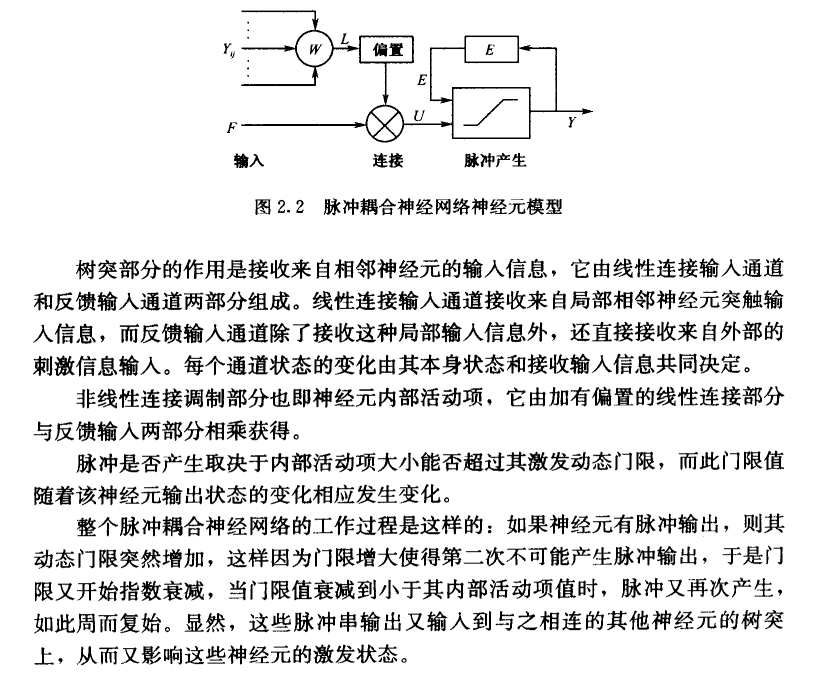
算法流程:
预处理
-
疗前MR扫描:扫描得到的MR图像序列被用作训练集。
-
初始帧勾画:对于算法的初始化,需要人工勾画初始帧ROI的轮廓 R O I s t d ROI_{std} ROIstd,以及其预期最大运动范围——“ B a c k g r o u n d Background Background”(通过在几个呼吸周期内观察来自治疗前MR图像的肿瘤运动的最大延伸来确定)。除此之外,选择呼吸期间受运动伪影影响最小的单个 R O I s t d ROI_{std} ROIstd(通常在呼气阶段结束时),并将其称为 R O I r e p ROI_{rep} ROIrep(在后续步骤中使用)。
-
参数优化:在实际进行自动勾画之前,必须优化patient-based的自动勾画参数,从而使得自动勾画的轮廓最接近人工勾画除的轮廓(这也是自动勾画算法的优化目标)。基于训练集,以DSC值作为训练指标(更大的DSC平均值,更小的DSC方差)。对PCNN的所有参数组合进行一个类似于网格搜索。
主算法
预处理过程完成后,主算法应用于每个分次内MR图像以自动勾画肿瘤轮廓。这是一个自动化过程,不需要用户进一步输入。
-
背景提取:在步骤2中提前确定了“ B a c k g r o u n d Background Background”,因此,在步骤4中,对于每一个输入的MR图像,都基于确定好的 B a c k g r o u n d Background Background二值掩码来提取背景区域的像素(做交运算),从而得到“背景区域”。这是由于本算法是基于一个前提:肿瘤将驻留在背景区域内。
-
肿瘤的大致位置确定:尽管已经将分割和搜索的区域从全局图像缩小成了背景区域,但是背景区域中仍然包含大量不需要的解剖结构。
这一步需要将背景区域和 R O I r e p ROI_{rep} ROIrep作为输入,对这两者应用快速归一化互相关。最大相关系数所在的坐标即代表test img中的背景区域内的大概肿瘤位置(每个MR图像中的肿瘤形状会不断发生变化,而所选的 R O I r e p ROI_{rep} ROIrep保持不变,因此这个坐标并不一定对应着真正的肿瘤质心)。
在得到最大相关系数所在位置的坐标后,需要基于这个坐标提取背景区域中的特定部分:对 R O I r e p ROI_{rep} ROIrep掩膜应用形态扩张(扩张三倍),这会将掩模的边界扩大三个像素。以便扩张后的 R O I r e p ROI_{rep} ROIrep 掩模的面积足够大以涵盖呼吸期间的肿瘤体积/形状变化。之后,将扩张后的 R O I r e p ROI_{rep} ROIrep 掩模对应的背景部分提取出来,以作为目标最有可能在的位置。
-
提取目标轮廓:
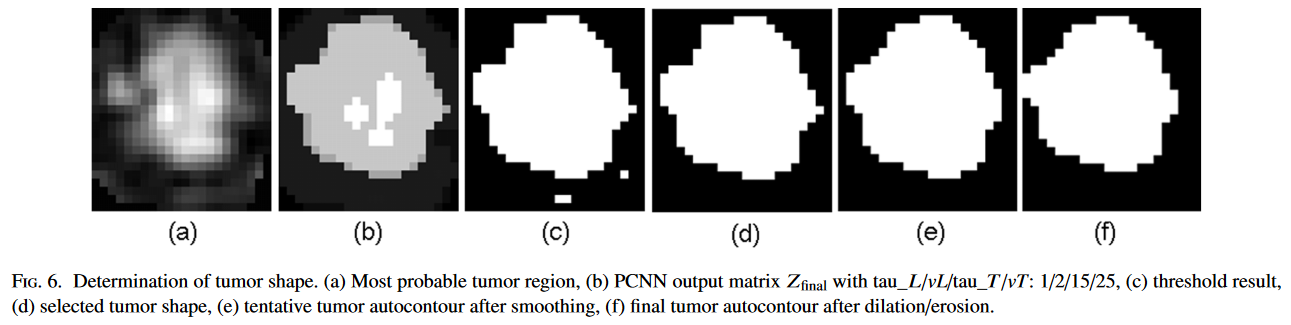
- 将PCNN应用于第5步中输出的区域(图a),以改善对比度,得到图b;
- 应用otsu法,基于图b得到二值化图像图c;
- 算法仅选择肿瘤形状并拒绝其他像素簇,得到图d;
- 应用高斯核进行图像平滑得到图e;
- 应用形态学操作得到最终的图f。
评估指标:
- DSC
- 豪斯多夫距离
- 质心像素误差
结果:
- 对于体模数据,mean DSC=0.95-0.96,mean HD=2.61-2.82mm, Δ d c e n t r o i d \Delta d_{centroid} Δdcentroid=0.68-0.93mm。
- 对于in-vivo数据,mean DSC=0.87-0.92,mean HD=3.12-4.35mm, Δ d c e n t r o i d \Delta d_{centroid} Δdcentroid=1.03-1.35mm。
感想:感觉这篇文章提出的方法鲁棒性不强,因为其算法流程中充斥了太多固定、机械的步骤。尽管其用了PCNN,但是该网络模型在整个算法流程中只占了很小的一部分。参考意义不大,果然还是得读近五年的论文。
“Stability of conventional and machine learning-based tumor auto-segmentation techniques using undersampled dynamic radial bSSFP acquisitions on a 0.35 T hybrid MR-linac system”
2021年 期刊 MEDICAL PHYSICS 医学2区 核医学3区
本研究基于动态平衡稳态自由进动(dynamic balanced steady-state free-precession,简称bSSFP,一种序列技术)成像序列,实现了在0.35T MRI-linac系统上的肿瘤跟踪。
关于什么是bSSFP,可以参考这篇磁共振序列之bSSFP序列。
关于文中提到的k空间欠采样,GPT的回答如下:
k空间欠采样(k-space undersampling)是一种在磁共振成像(MRI)中采集数据时使用的技术,它涉及到在k空间(一个频率空间,用于通过傅里叶变换重建MRI图像)中不完全填充所有数据点。在标准MRI扫描中,通常会收集k空间中的每一个数据点来生成高质量的图像。然而,这个过程可能比较耗时。
通过欠采样k空间,即选择性地只采集部分数据点,可以显著减少数据采集所需的时间,从而加快成像速度。这对于需要快速扫描的应用场合特别有用,比如在需要减少因患者或器官移动而产生的伪影时,或者在进行功能性MRI(fMRI)或动态成像时。
通过欠采样k空间数据以加快成像速度,同时利用bSSFP序列的高信噪比和高对比度优势来尽可能减少因欠采样而引入的图像质量下降。
还是来更多地关注如何通过算法实现跟踪的吧。
本研究比较了两种不同的算法:U-net和B-spline(一种可变形图像配准),输入均为128×128像素的图像,输出为二值掩模。
数据增强:高度偏移 = 10%,宽度偏移 = 5%,旋转范围 = 5°,剪切范围 = 10°。
U-net:相较于原论文中提出的模型,在编码器部分的每次最大池化(max-pooling)操作之后,以及在解码器部分的每次concatenation操作之后,添加了0.5的dropout层。除此之外,还在每个卷积层后添加了BN层。
B-spline:B-spline跟踪是通过多步骤过程实现的。首先,对于cine-MRI序列的每一帧,通过互相关评估 10 个参考图像中最相似的帧。其次,B 样条算法计算这两个图像之间的非刚性变形图。最后,将该图应用于参考图像的手动轮廓,以实现当前帧的轮廓。
关于什么是B-spline,可以参考这篇简单粗暴:B-样条曲线入门。虽然还是没看太懂。
测试框架:使用10张手动分割的图像作为训练集来训练U-net和确定B-spline的参数(是不是有点少?)。并且使用5-fold交叉验证来得出模型的性能。
评价指标:
- DSC
- 豪斯多夫距离
- 平均轮廓距离(mean contour distance) M C D = m a x ( m c d ( A , B ) , m c d ( B , A ) ) MCD=max(mcd(A,B),mcd(B,A)) MCD=max(mcd(A,B),mcd(B,A)), m c d ( A , B ) = m e a n a ∈ A ( m i n b ∈ B ( ∣ ∣ a − b ∣ ∣ ) ) mcd(A,B)= \mathop{mean}\limits_{a\in A}(\mathop{min}\limits_{b\in B}(||a-b||)) mcd(A,B)=a∈Amean(b∈Bmin(∣∣a−b∣∣))。
结果:

感想:感觉没什么参考性。而且没看太懂,包含的医学领域术语和概念太多。
“Deep learning-based markerless lung tumor tracking in stereotactic radiotherapy using Siamese networks”
2023年 期刊 MEDICAL PHYSICS 医学2区 核医学3区
本文章主要介绍了在立体定向放疗(SBRT)中,基于Siamese网络,实现在使用**容积弧形调强放射治疗(VMAT)**技术进行放疗时对肺部肿瘤的无标记实时跟踪。
关于VMAT,可以参考这篇容积调强放射治疗(VMAT),就是一种放疗技术。和SBRT一样。
然后基于这两种放疗技术,通过CT(断层扫描技术)扫描,医生可以获得肿瘤及其周围重要器官的精确位置信息。CT扫描是一种X射线成像技术,能够提供身体内部的横截面图像。CT扫描过程中使用的X射线就是kV级别的X射线。也就是说,文中提到的kv图像就是CT图像。(这里是医学方面的概念,理解了有助于读懂本文)
注意,研究中使用的是patient-specific的模型(与在大量可能患者的训练数据上训练单一广义模型的常用策略不同,这是为了解决患者间和肿瘤间差异(例如肿瘤大小、形状、位置、运动)的问题。))。每一个patient-specific的模型都是基于4D-CT扫描生成的合成数据(DRR)进行训练,并在临床数据上进行测试。由于缺乏带有ground truth的KV图像数据集(kV图像是指在放射治疗和影像学中使用的一种X射线图像,其名称来源于使用的X射线束的电压,以千伏特(kV)为单位。与高能量的MV(兆伏特)X射线相比,kV X射线具有较低的能量。kV图像通常用于患者定位、肿瘤和组织的成像以及治疗过程中的实时监控。),因此在一个3D打印的体模数据上对模型进行了评估,同时也在六名患者的临床数据上(kv图像)对模型进行了评估。对每个patient-specific模型,使用80%的DRRs训练,20%用于验证。
对了,由于Siamese网络是在DRR上进行训练,然后在kv图像上进行测试,会存在一个问题,即训练集和测试集的图像质量是完全不同的。关于模型在kv图像上的有效性,原文中进行了解释:
Due to differences in terms of contrast, image resolution and noise between DRRs (training data) and kV images (inference data), a CNN trained on DRRs might not be able to extract representative features from kV images, to locate the tumor. In the case of Siamese networks, a CNN extracts features from both the search image (cropped from the current frame) and a template image containing the tumor (cropped from previous frame(s)). On kV images, even if the network cannot extract the most representative features because it was trained on DRRs, if the tumor is present in the template image,then the feature maps obtained from the template and search images are very similar in the tumor area. Therefore, instead of locating the tumor based only on the search image’s feature maps, the model identifies the features that are most similar to the ones extracted from the template image and assigns the location to the tumor. This approach should make the task of locating the tumor in kV images easier, when the model is trained on DRRs.
数据集生成:
- 对于每个病人,生成的CT数据集为10个原始CT+80个变形后CT=90个3D-CT扫描,对于体模数据,贼为1张原始CT+89个变形后CT=90个。
- 使用DeepDRR来生成训练和验证数据集。
- 对于每个患者/模型,从总共90个3D-CT扫描中,随机选择72个(80%)进行训练,其余18个(20%)用于验证。对每个CT扫描,生成720个DRR,最终生成51840个DRR用于训练和12960个用于验证。
比较了基于Siamese网络的方法和基于模板匹配的方法(RTR):
-
基于模板匹配的方法(RTR):通过使用归一化互相关,将各个kV图像与先前采集的体积CT数据生成的2D模板进行匹配。
-
基于Siamese网络的方法:
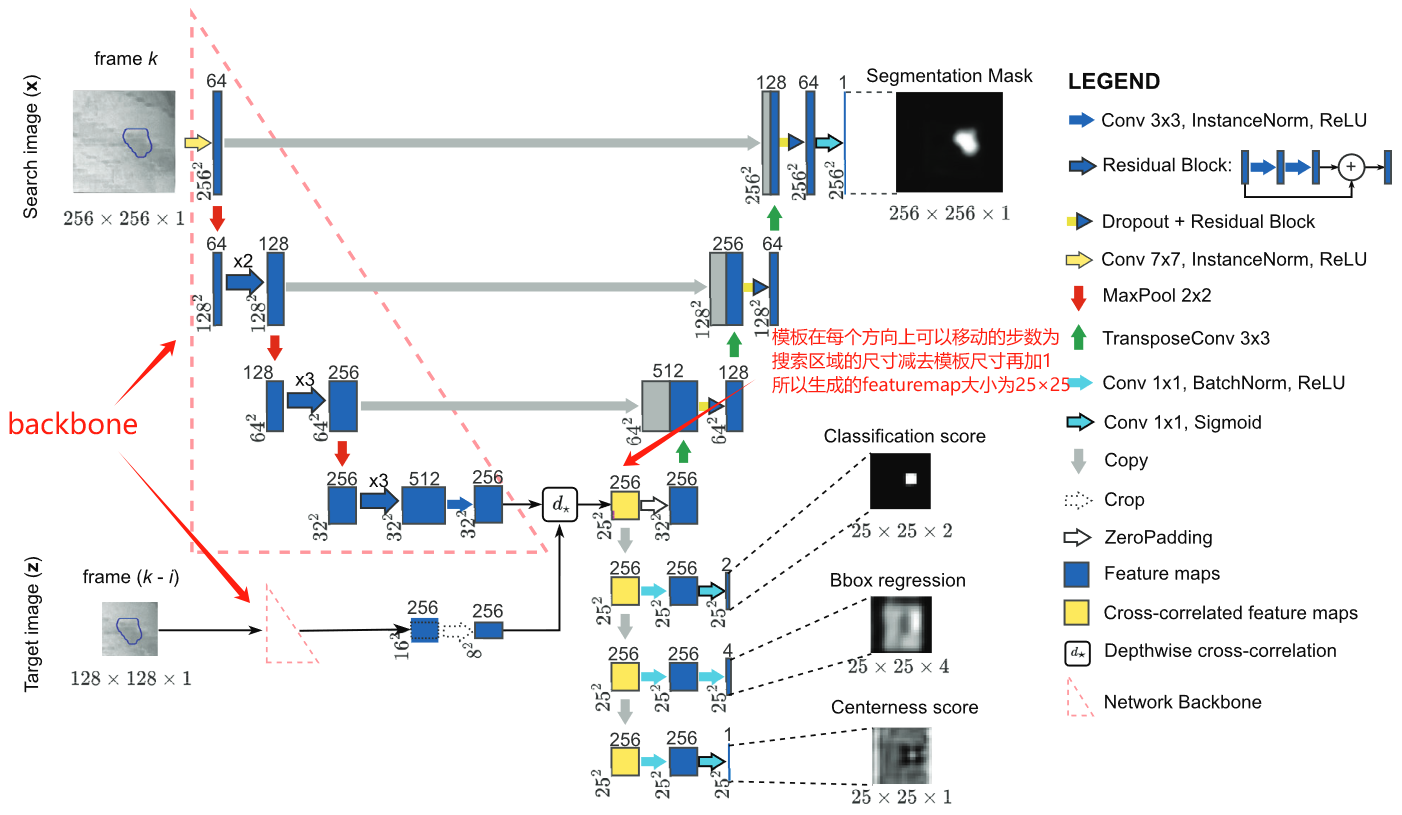
- 对于每个病人,使用了数据增强。
- Anchor-Free的方式设计网络,即,不通过调整预定义锚框的位置和长宽比来预测边界框,而是直接生成它。
- 有四个输出,分割输出(Mask R-CNN中提到分割任务可以提高目标检测的性能)、分类输出、BB回归、中心头输出,对每个输出头,单独使用一个损失函数( L c l a s s \mathcal{L}_{class} Lclass和 L m a s k \mathcal{L}_{mask} Lmask使用focal loss, L b o x \mathcal{L}_{box} Lbox使用Distance-IOU loss, L c e n e r \mathcal{L}_{cener} Lcener使用MSE),最终的损失为所有损失之和。
- 目标图像和搜索图像:以ground truth BB中心为中心,在ground truth BB的基础上,裁剪一个 A × A A\times A A×A大小的图像作为目标图像,以及一个 2 A × 2 A 2A\times 2A 2A×2A的图像作为搜索区域。其中, A = ( h + p ) ⋅ ( w + p ) , p = ( h + w ) / 2 A=\sqrt{(h+p)\cdot(w+p)},p=(h+w)/2 A=(h+p)⋅(w+p),p=(h+w)/2(类似于SiamFC)。
- 其它训练参数。
- 训练好的模型大概是30FPS。
- 为了从分类和边界框头生成的输出中获得最终预测结果,进行了后处理:
- 使用centerness score调整了classification score,优先考虑更靠近肿瘤中心的位置。
- 在classification score上使用了余弦窗。(还是不明白怎么使用的)
- 对保留的预测结果进行比例惩罚,以降低与上一帧预测结果相比在大小和比例上存在差异的边界框的权重。(也不懂)
- 最终,模型输出经过后处理后的BB。
- 为了提高模型的鲁棒性,用了Memory management module (MMM)模块(没咋关注,跟算法没太大关系)。
-
模型评价:
- 相关系数:对于临床真实数据,计算了预测的肿瘤轨迹和RPM(呼吸管理系统)得到的位置之间的相关系数。尽管二者之间不是完全线性相关的,但是高CC值也代表了跟踪的成功。
- 对于体模数据,计算了预测坐标和ground truth坐标之间的MAD、RMSE以及图像平面上的最大误差。
-
结果:
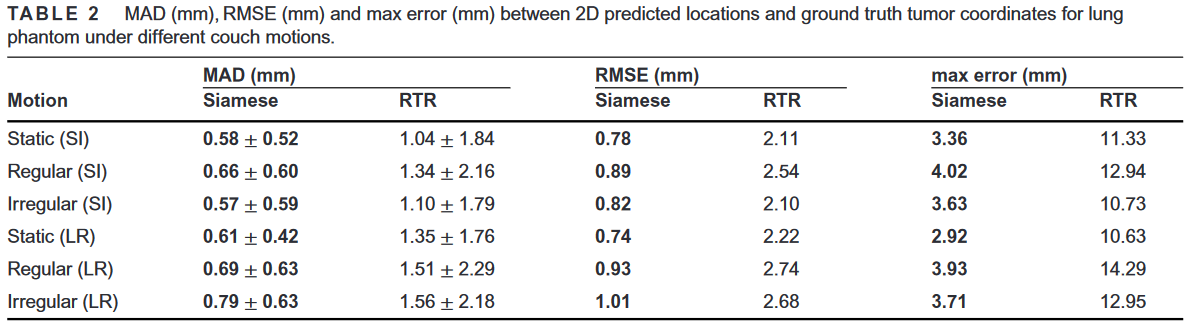
感想:这篇文章还是比较有参考意义。首先确实是基于跟踪算法实现对kv图像中的小目标(肿瘤)无标记跟踪。然后应用了深度学习方法。根据文中内容,该模型也不需要太大的训练资源。尽管模型是patient-specific的,但是仍有一定的参考价值,因为不同病人的数据集确实有很大差别。因此patient-specific确实不失为一种方向。