multiprocessing
官网地址:https://docs.python.org/3/library/multiprocessing.html#
1.Pool
2.Process
3.set_start_method
- spawn
- fork
- forkserver
4.Exchanging objects between processes
- Queues
- Pipes
5.Synchronization between processes
- Lock
6.Sharing state between processes
- Shared memory: Value or Array
- Server process: Manager
7.Using a pool of workers
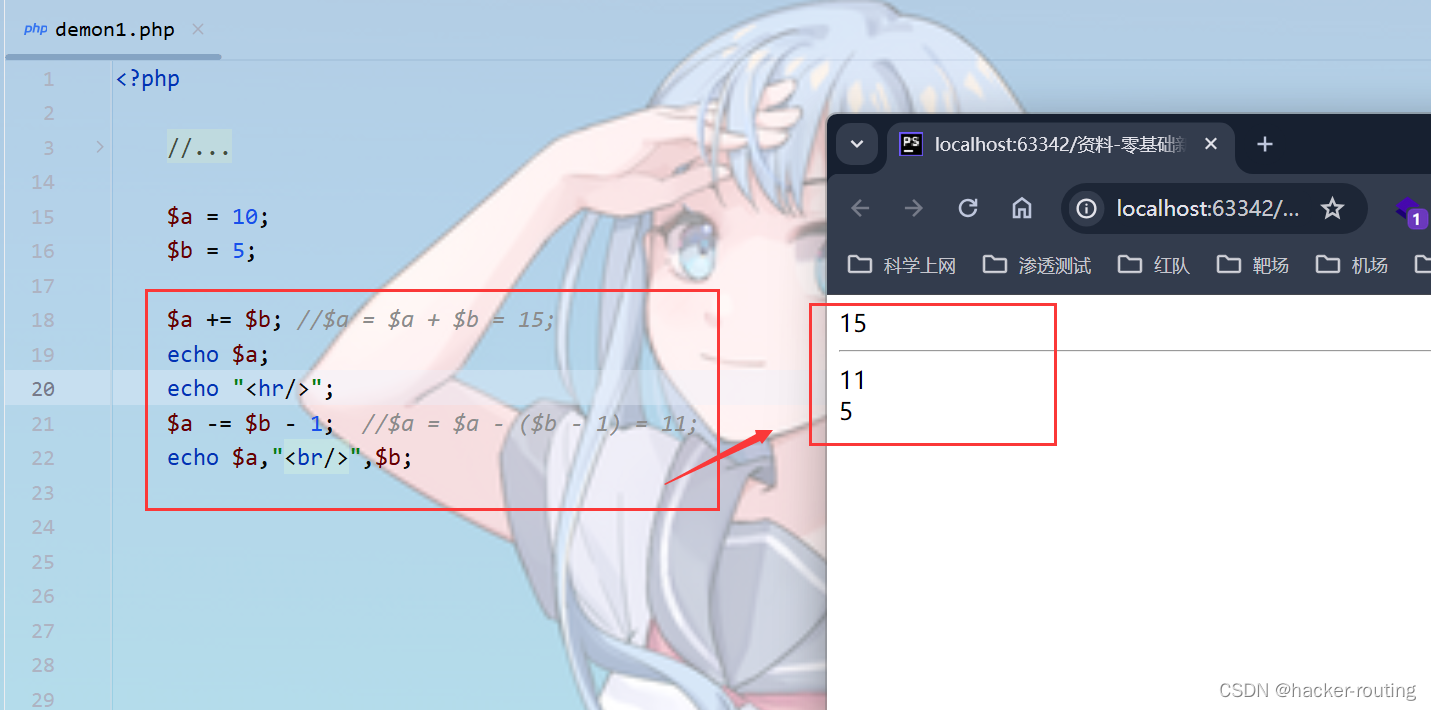
from multiprocessing import Pool, TimeoutError
import time
import osdef f(x):return x*xif __name__ == '__main__':# start 4 worker processeswith Pool(processes=4) as pool:# print "[0, 1, 4,..., 81]"print(pool.map(f, range(10)))
8.示例:多线程翻译
创建多个线程同时调用gpt4翻译,(gpt4调用代码没有贴出来,请自行封装)核心是多线程代码。
import logging.config
import multiprocessing
import os
import time
from datetime import datetimeimport openpyxl
import yamlfrom shenmo.TUnit import TUnit
from shenmo.app_utils import identify_language
from shenmo.os_utils import get_current_file_names, get_tree_file_names
from shenmo.pat_api_utils import call_strategy_api# 定义常量:最大线程数
MAX_THREAD_COUNT = 10
MAX_SAVE_COUNT = 100
SYSTEM_MSG = 'You are a professional game translator and your task is to translate the text in the game. Chinese ' \'translated into {}. The output includes only the translation.'def setup_logging(default_path="logging.yaml", default_level=logging.INFO, env_key="LOG_CFG"):path = default_pathvalue = os.getenv(env_key, None)if value:path = valueif os.path.exists(path):with open(path, "r") as f:config = yaml.load(f, Loader=yaml.FullLoader)logging.config.dictConfig(config)else:logging.basicConfig(level=default_level)def worker(in_queue, out_queue, language_type):while True:task = in_queue.get()if task is None: # sentinel value indicating to exitbreak# 翻译内容t1 = time.time()system_msg = SYSTEM_MSG.format(language_type)translated_value = call_strategy_api(task.get_original_text(), system_msg)t2 = time.time()# 设置耗时task.set_cost_ms(t2 - t1)if translated_value.startswith("Error:") or translated_value.startswith("Request failed:"):task.set_error_msg(translated_value)else:task.set_translated_text(translated_value)out_queue.put(task)def save_file_then_rename(origin_file_name, wb):tmp_file_name = origin_file_name + ".tmp"# 保存文件wb.save(tmp_file_name)# 删除原文件os.remove(origin_file_name)# 重命名临时文件os.rename(tmp_file_name, origin_file_name)def print_statistics(error_count, processed_count, task_count, t1):t2 = time.time()logging.info("-" * 50)logging.info(f"已处理{processed_count}条,,异常{error_count}条,总共{task_count}条,进度:{(processed_count + error_count) / task_count:.2%},已耗时:{t2 - t1:.2f}秒。保存文件中...")logging.info("-" * 50)class Translator:def __init__(self, file_name):self.file_name = file_namedef translate(self):in_queue = multiprocessing.Queue()out_queue = multiprocessing.Queue()# 打开Excel文件wb = openpyxl.load_workbook(self.file_name)# 选择sheet页“多语言翻译”sheet = wb.active# 循环遍历第2列,过滤前2行for row in sheet.iter_rows(min_row=2, max_row=sheet.max_row):# 第一列不为空,第二列为空if (row[0].value is not None and row[0].value.strip() != "") and (row[1].value is None or row[1].value.strip() == ""):row_num = row[1].roworg_value = row[0].valuetUnit = TUnit(row_num, org_value)# 将tUnit放入队列in_queue.put(tUnit)# in_queue长度task_count = in_queue.qsize()identify_language_type = identify_language(self.file_name)logging.info(f"文件[{self.file_name}]装载完成,语言类型:{identify_language_type},共{task_count}条翻译任务,创建{MAX_THREAD_COUNT}个线程,任务即将开始...")t1 = time.time()# Create and start worker processesprocesses = []for _ in range(MAX_THREAD_COUNT):process = multiprocessing.Process(target=worker, args=(in_queue, out_queue, identify_language_type))process.start()processes.append(process)# 已处理的任务数量processed_count = 0error_count = 0# out_queue存在数据时,不断取出数据for _ in range(task_count):out = out_queue.get(block=True)if out.get_error_msg() is not None:error_count += 1logging.error(f"[{processed_count}/{task_count}]第{out.get_row_number()}行,翻译失败:{out.get_original_text()} -> {out.get_error_msg()},耗时:{out.get_cost_ms():.2f}秒。")else:processed_count += 1logging.info(f"[{processed_count}/{task_count}]第{out.get_row_number()}行,翻译成功:{out.get_original_text()} -> {out.get_translated_text()},耗时:{out.get_cost_ms():.2f}秒。")translate_text = out.get_translated_text()sheet.cell(row=out.get_row_number(), column=2).value = translate_text# 每处理100条,保存一次文件if processed_count % MAX_SAVE_COUNT == 0:print_statistics(error_count, processed_count, task_count, t1)save_file_then_rename(self.file_name, wb)if processed_count % MAX_SAVE_COUNT != 0:print_statistics(error_count, processed_count, task_count, t1)save_file_then_rename(self.file_name, wb)wb.close()logging.info(f"所有翻译任务处理完毕。")# 处理完毕,退出# Add sentinel values to signal the worker processes to exitfor _ in range(MAX_THREAD_COUNT):in_queue.put(None)logging.info("已发送线程退出信号,等待线程退出...")# Wait for all processes to finishfor process in processes:process.join()logging.info(f"所有线程已退出。")if __name__ == "__main__":# 创建文件夹:/export/logs/gpt/cache/if not os.path.exists("logs/"):os.makedirs("logs/")setup_logging()# 允许用户输入线程数量,默认10MAX_THREAD_COUNT = int(input("请输入线程数量(默认10):") or "10")logging.info(f"线程数量:{MAX_THREAD_COUNT}")directory_path = "."file_names_list = get_tree_file_names(directory_path, ".xlsx")logging.info(f"文件序号\t文件名")for file_name in file_names_list:# 打印:数组下标,文件名,语言类型logging.info(f"{file_names_list.index(file_name)}\t{file_name}")index = -1try:index = int(input("请输入要翻译的文件序号:"))except ValueError:index = -2# 检测用户输入的序号合法,执行下面代码if 0 <= index < len(file_names_list):selected_file_name = file_names_list[index]logging.info(f"你选择的文件是:[{index}]{selected_file_name}")translator = Translator(selected_file_name)translator.translate()else:logging.error(f"输入的序号[{index}]不合法,程序即将退出。")# 程序即将退出logging.info("程序即将退出。")# 暂停3秒time.sleep(3)TUnit.py
class TUnit:# 类变量_id_alloc = 0def __init__(self, row_number, original_text):TUnit._id_alloc += 1self._id = TUnit._id_allocself.row_number = row_numberself.original_text = original_textself.translated_text = Noneself.cost_ms = 0self.error_msg = None# get iddef get_id(self):return self._id# getdef get_row_number(self):return self.row_numberdef get_original_text(self):return self.original_textdef get_translated_text(self):return self.translated_text# set translated_textdef set_translated_text(self, translated_text):self.translated_text = translated_textreturn self.translated_text# set cost_msdef set_cost_ms(self, cost_ms):self.cost_ms = cost_msreturn self.cost_msdef get_cost_ms(self):return self.cost_ms# set error_msgdef set_error_msg(self, error_msg):self.error_msg = error_msgreturn self.error_msgdef get_error_msg(self):return self.error_msgdef __str__(self):return f"row_number:{self.row_number}, original_text:{self.original_text}, translated_text:{self.translated_text}, cost_ms:{self.cost_ms}"os_utils.py
import osdef get_tree_file_names(directory, extension):"""获取指定目录下的所有文件(包括子目录):param extension: 文件后缀(扩展名):param directory: 指定目录:return: 文件名列表"""file_names = [] # 用于存储文件名的列表# 遍历目录中的所有文件和子目录for root, dirs, files in os.walk(directory):# 将当前目录下的所有文件添加到列表中for file in files:if file.endswith(extension):file_names.append(os.path.join(root, file))return file_namesdef get_current_file_names(directory, extension):"""获取指定目录下的所有文件(不包括子目录):param directory: 指定目录:param extension: 文件后缀(扩展名):return: 文件名列表"""file_names = [] # 用于存储文件名的列表# 获取指定目录下的所有文件和子目录items = os.listdir(directory)# 遍历所有文件和子目录for item in items:# 构建文件的完整路径item_path = os.path.join(directory, item)# 检查是否是文件if os.path.isfile(item_path):# 检查文件是否以指定后缀结尾if item.endswith(extension):file_names.append(item)return file_namesif __name__ == "__main__":# 测试函数directory_path = "./国际版翻译"file_names_list = get_current_file_names(directory_path, ".xlsx")for file_name in file_names_list:print(file_name)