目录
一、jsoup的使用
1.概述
2.主要功能
3.快速入门
4.数据准备
二、Selenium
1.概述
2.使用
三、Selenium配合jsoup获取数据
四、爬虫准则
五、Selenium+jsoup+mybatis实现数据保存
1.筛选需要的数据
2.创建一个表,准备存储数据
手写?不存在的
一、jsoup的使用
1.概述
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
2.主要功能
-
从URL,文件或字符串中刮取并解析HTML
-
查找和提取数据,使用DOM遍历或CSS选择器
-
操纵HTML元素,属性和文本
-
根据安全的白名单清理用户提交的内容,以防止XSS攻击
-
输出整洁的HTML
3.快速入门
-
引入jsoup坐标
-
然后就可以直接开整了
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.17.2</version>
</dependency>Java
public static void main(String[] args) throws IOException {Document doc = Jsoup.connect("https://www.baidu.com").get();String title = doc.title();System.out.println("Title is: " + title);
}参数设置
Document doc = Jsoup.connect("http://example.com").data("query", "Java").userAgent("Mozilla").cookie("auth", "token").timeout(3000).post();结束,使用就是这么快
使用需要的知识
-
Java基础
-
html三剑客基础【知道是干啥的就行】(html/css/javascript)
-
jQuery基础
4.数据准备
我这里主要是为了获取数据,更深入的知识可自行网上查阅,我就不写了
Element类方法详解 - jsoup - 文档中心 - 技术客 (sunjs.com)
-
首先准备一个网址:我用的jd的
笔记本 - 商品搜索 - 京东热卖 (jd.com)
-
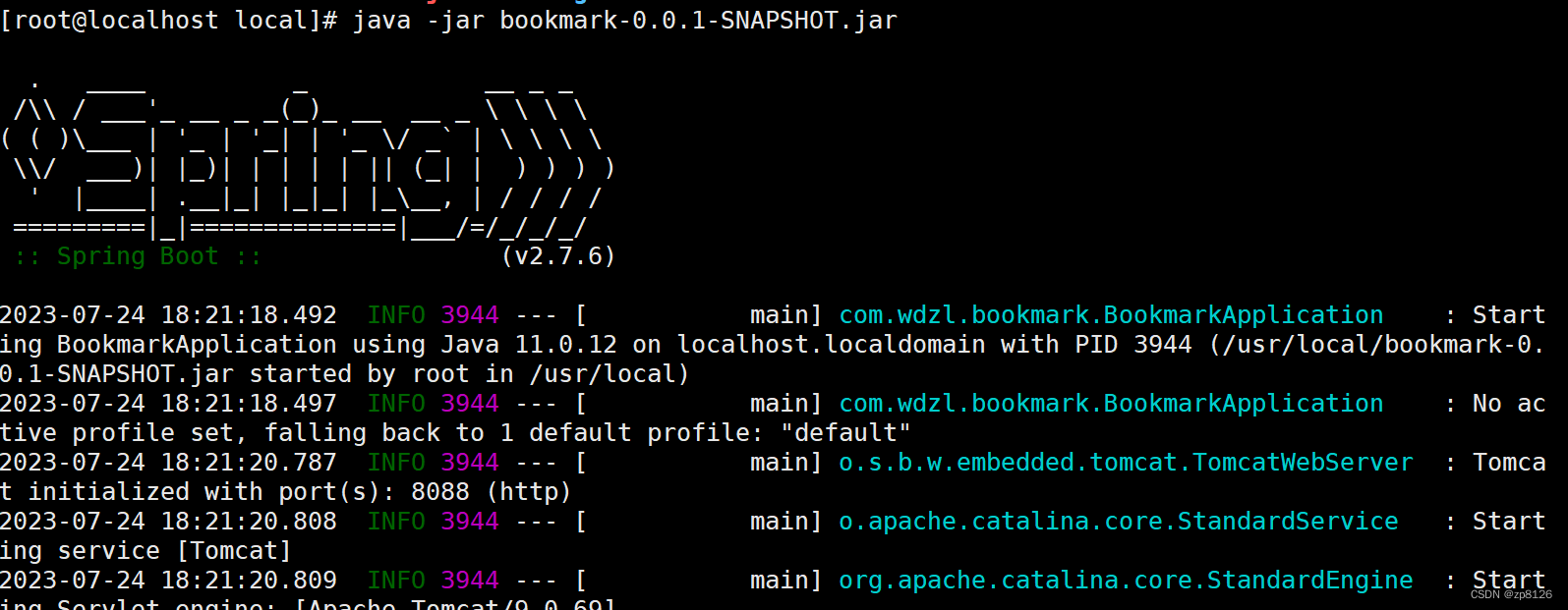
回到Java程序,运行一次,看看有数据不
String s = "笔记本";final String encode = URLEncoder.encode(s);
Document doc = null;try {doc = Jsoup.connect("https://re.jd.com/search?keyword="+encode).userAgent("Mozilla").timeout(5000).get();} catch (IOException e) {e.printStackTrace();}System.out.println(doc);输出如下图即可:

-
打开网页,f12或鼠标右键点击检查,选择要获取数据容器/元素的位置
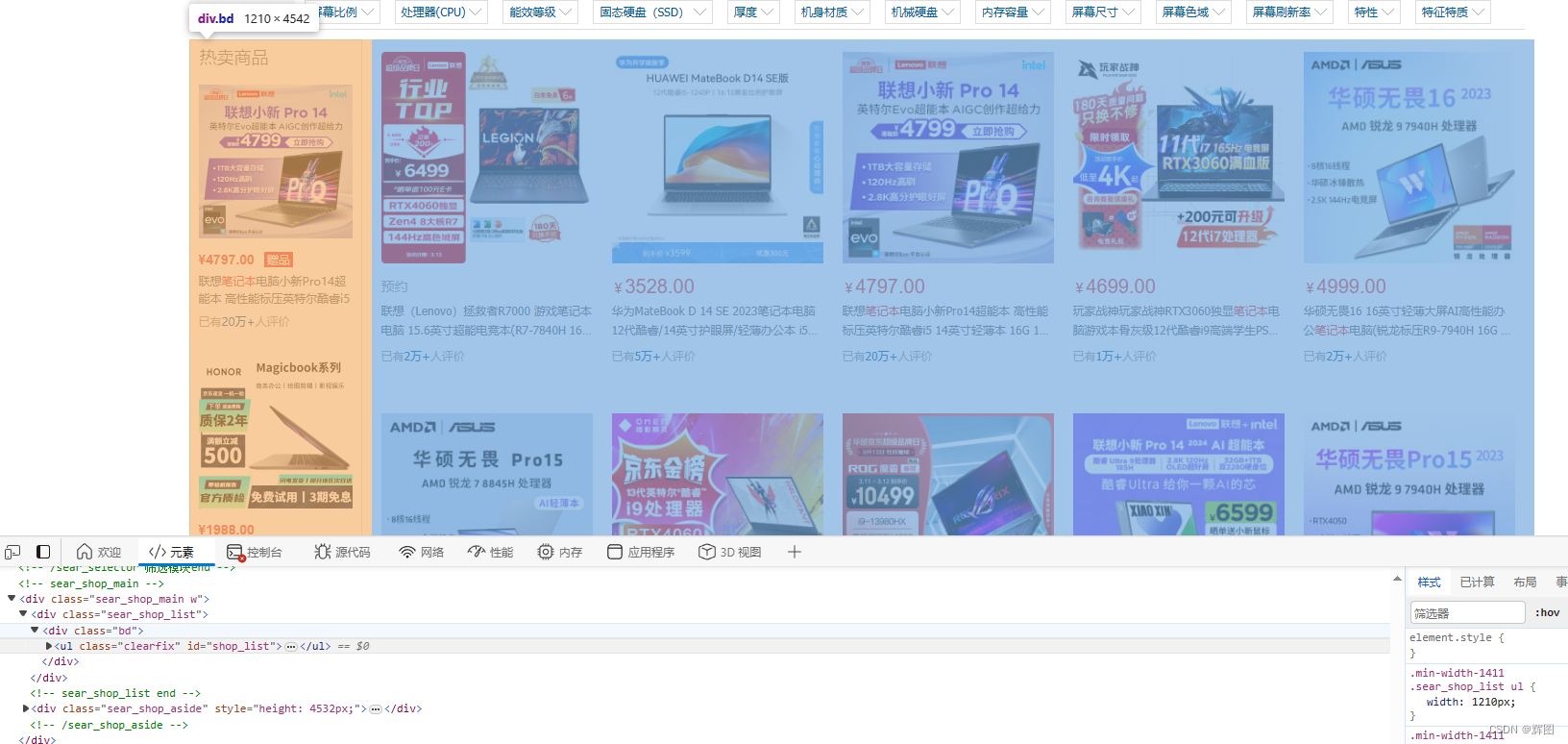
-
之后分析html代码,根据类名/标签名/id等缩小范围即可
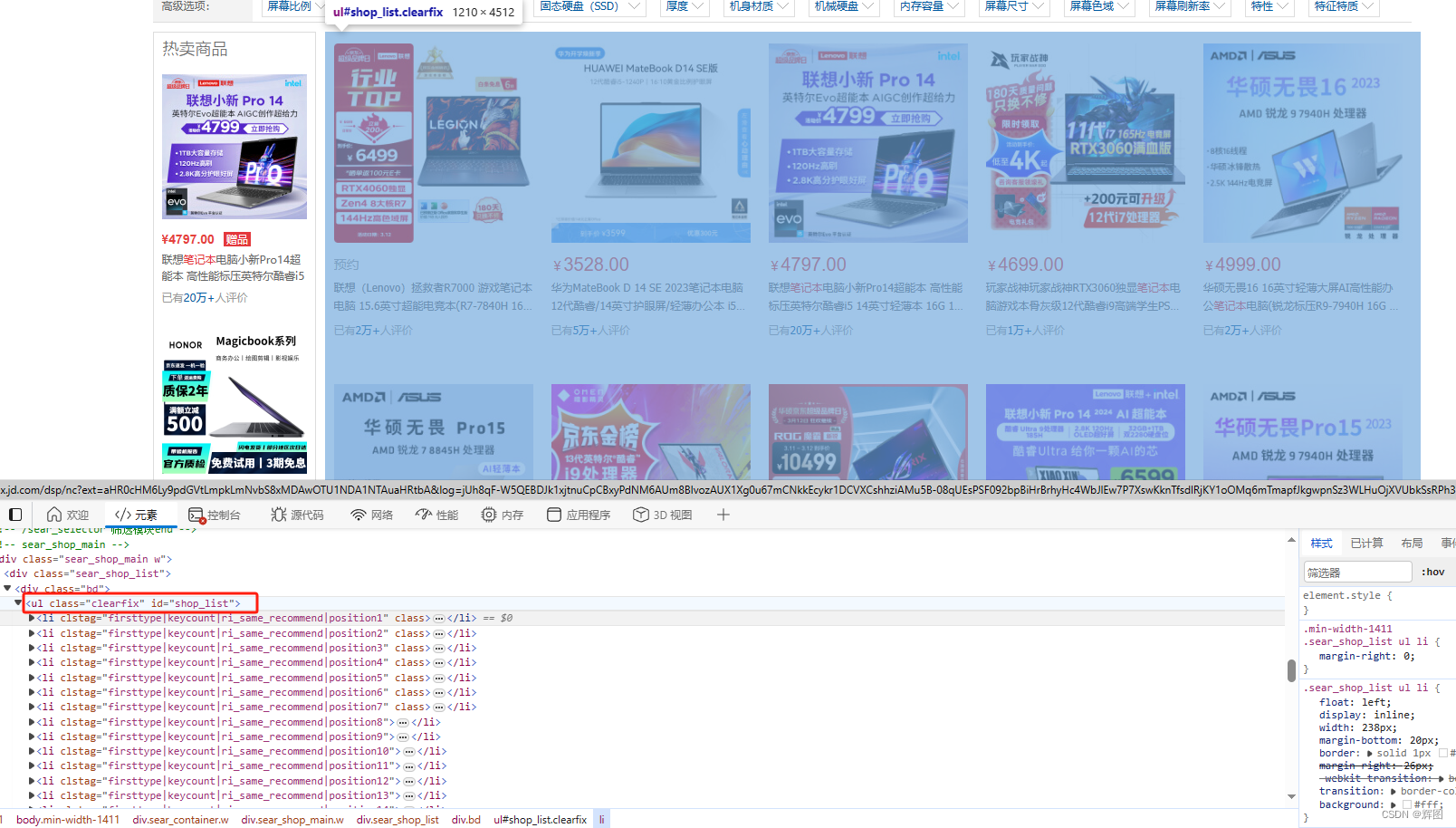
-
回到Java代码,选择一下标签输出看一下
final Element shopList = doc.getElementById("shop_list");
System.out.println(shopList);
-
发现是个空数据,由于jsoup只能爬取静态页面,所以需要借助另外一个工具了
拓展:
数据并不是不存在,它只是在js里
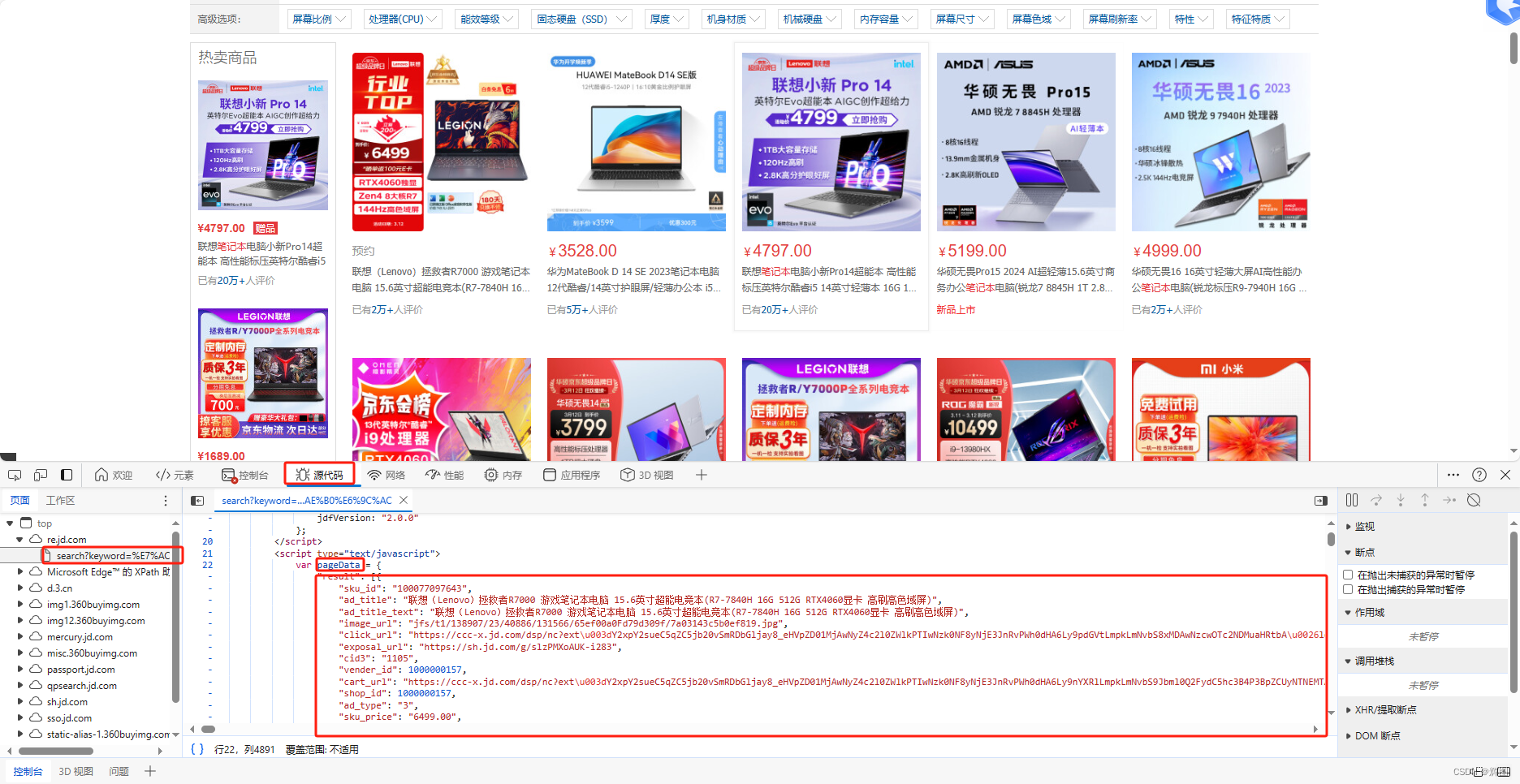
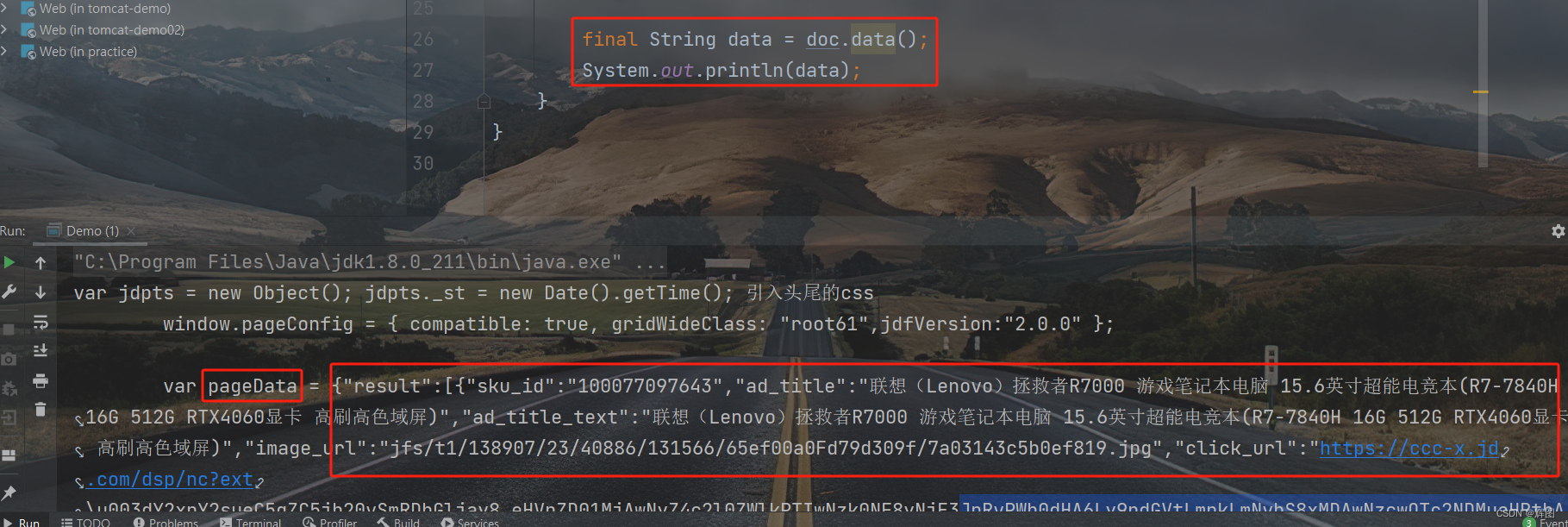
如果不嫌麻烦的话可以使用data()方法获取到,但是后续处理很麻烦,就不写了
二、Selenium
这是测试方向的,但别说真好用,这个我没咋学过,只会一点,有时间研究研究~
1.概述
Selenium是一系列基于Web的自动化工具,提供一套测试函数,用于支持Web自动化测试。函数非常灵活,能够完成界面元素定位、窗口跳转、结果比较。
具有如下特点:
-
多浏览器支持
-
如IE、Firefox、Safari、Chrome、Android手机浏览器等。
-
-
支持多语言
-
如Java、C#、Python、Ruby、PHP等。
-
-
支持多操作系统
-
如Windows、Linux、IOS、Android等。
-
-
开源免费
-
官网:Selenium
-
2.使用
-
引入Selenium依赖坐标
-
根据不同浏览器下载不同的驱动(有些可能需要点魔法)
-
设置浏览器驱动
-
我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,将“存放浏览器驱动”目录添加到Path的值中。
-
-
验证浏览器是否能启动成功
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.0.0</version>
</dependency>验证浏览器
public static void main(String[] args) {
// WebDriver driver = new ChromeDriver(); //Chrome浏览器
// WebDriver driver = new FirefoxDriver(); //Firefox浏览器WebDriver driver = new EdgeDriver(); //Edge浏览器
// WebDriver driver = new InternetExplorerDriver(); // Internet Explorer浏览器
// WebDriver driver = new OperaDriver(); //Opera浏览器
// WebDriver driver = new PhantomJSDriver(); //PhantomJSSystem.out.println(driver);}如果报错还会给最新的驱动下载地址,这很nice!

驱动版本一致后运行

开始挨个解决异常信息
首先第一个:访问给的网址
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See SLF4J Error Codes for further details.
翻译一下

添加依赖
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.11</version></dependency>运行,第一个问题解决

第二个问题:

jdk11的有另外一种解决方案,我这用的jdk8的,11的可自行搜一下
EdgeOptions edgeOptions = new EdgeOptions();edgeOptions.addArguments("--remote-allow-origins=*");WebDriver driver = new EdgeDriver(edgeOptions);之后,所有问题解决,开始使用~
测试代码:
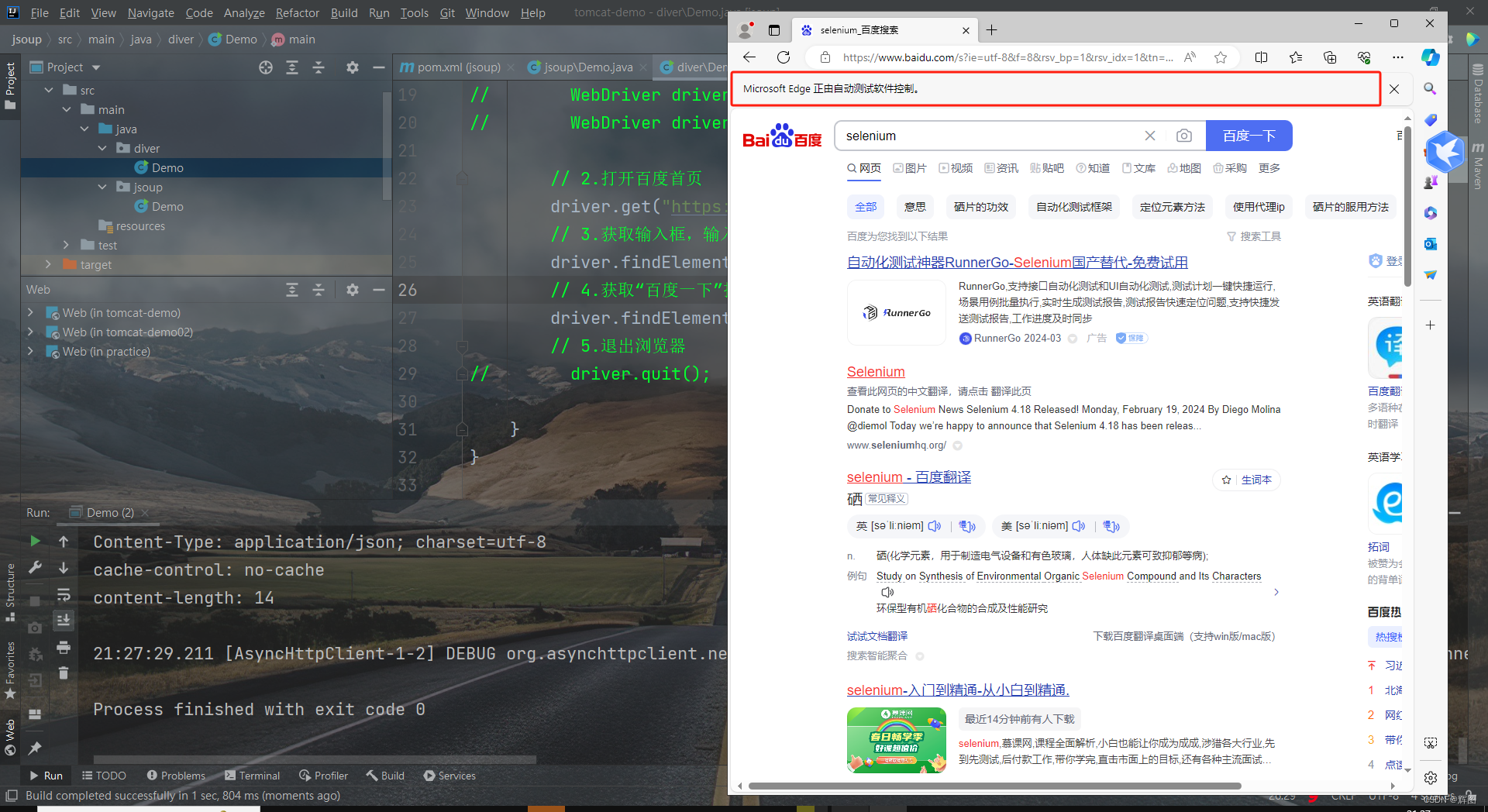
EdgeOptions edgeOptions = new EdgeOptions();edgeOptions.addArguments("--remote-allow-origins=*");WebDriver driver = new EdgeDriver(edgeOptions);// 2.打开百度首页driver.get("https://www.baidu.com");// 3.获取输入框,输入seleniumdriver.findElement(By.id("kw")).sendKeys("selenium");// 4.获取“百度一下”按钮,进行搜索driver.findElement(By.id("su")).click();// 5.退出浏览器//driver.quit();运行:完美,到这一步后后面就非常简单了~
三、Selenium配合jsoup获取数据
java代码
Scanner scanner = new Scanner(System.in);
System.out.println("请输入要搜索的内容");
final String s = "笔记本";
final String encode = URLEncoder.encode(s);
EdgeOptions edgeOptions = new EdgeOptions();
edgeOptions.addArguments("--remote-allow-origins=*");
//创建浏览器窗口
WebDriver edgeDriver = new EdgeDriver(edgeOptions);
edgeDriver.get("https://re.jd.com/search?keyword="+encode);
//动态网站数据填充比较慢,需要延迟才可以拿到数据,一般网不差3到5s就差不多了
Thread.sleep(5000);
//获取页面数据
final String pageSource = edgeDriver.getPageSource();
//将字符串转为document对象
final Document parse = Jsoup.parse(pageSource);
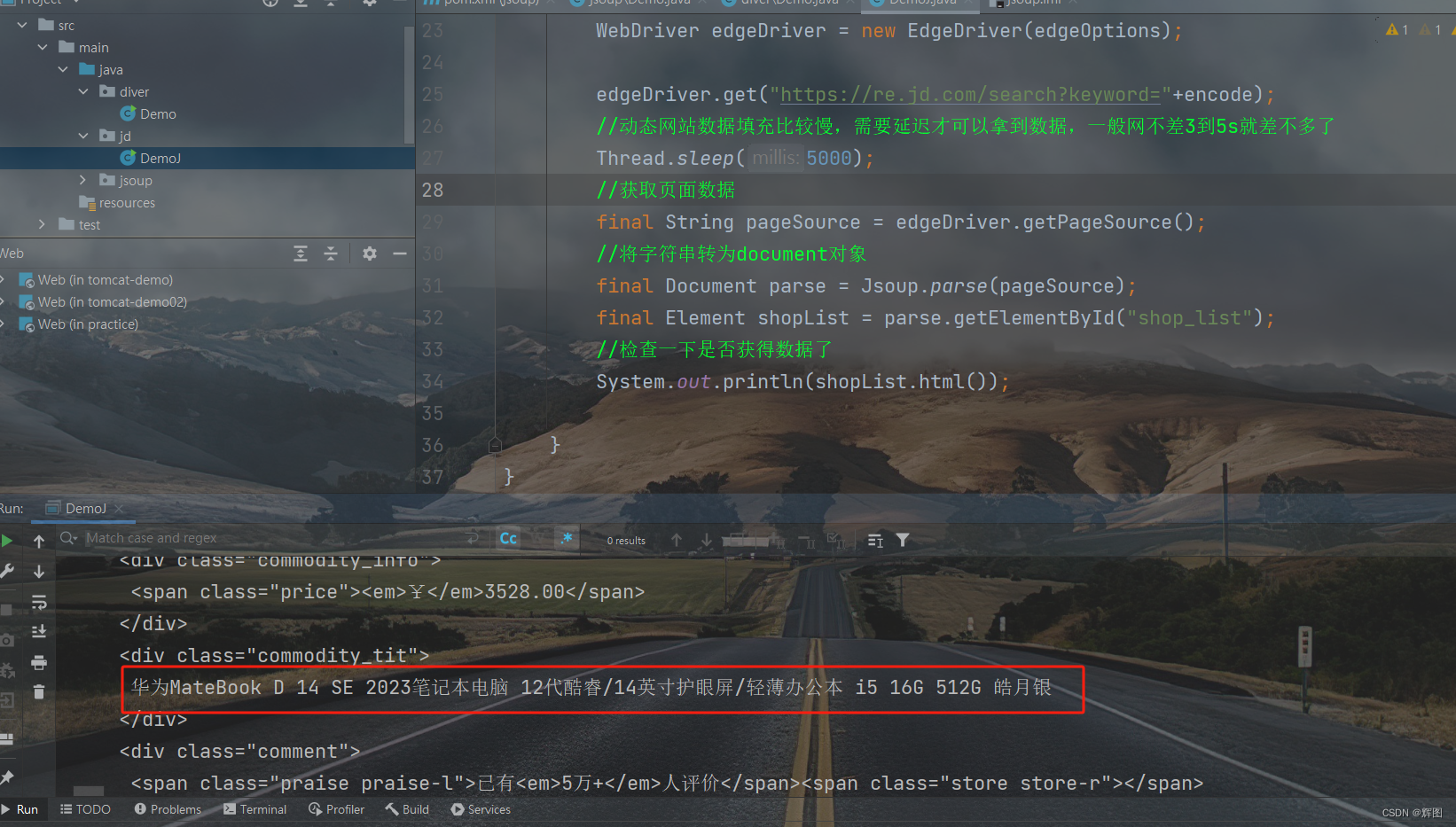
final Element shopList = parse.getElementById("shop_list");
//检查一下是否获得数据了
System.out.println(shopList.html());数据有了~
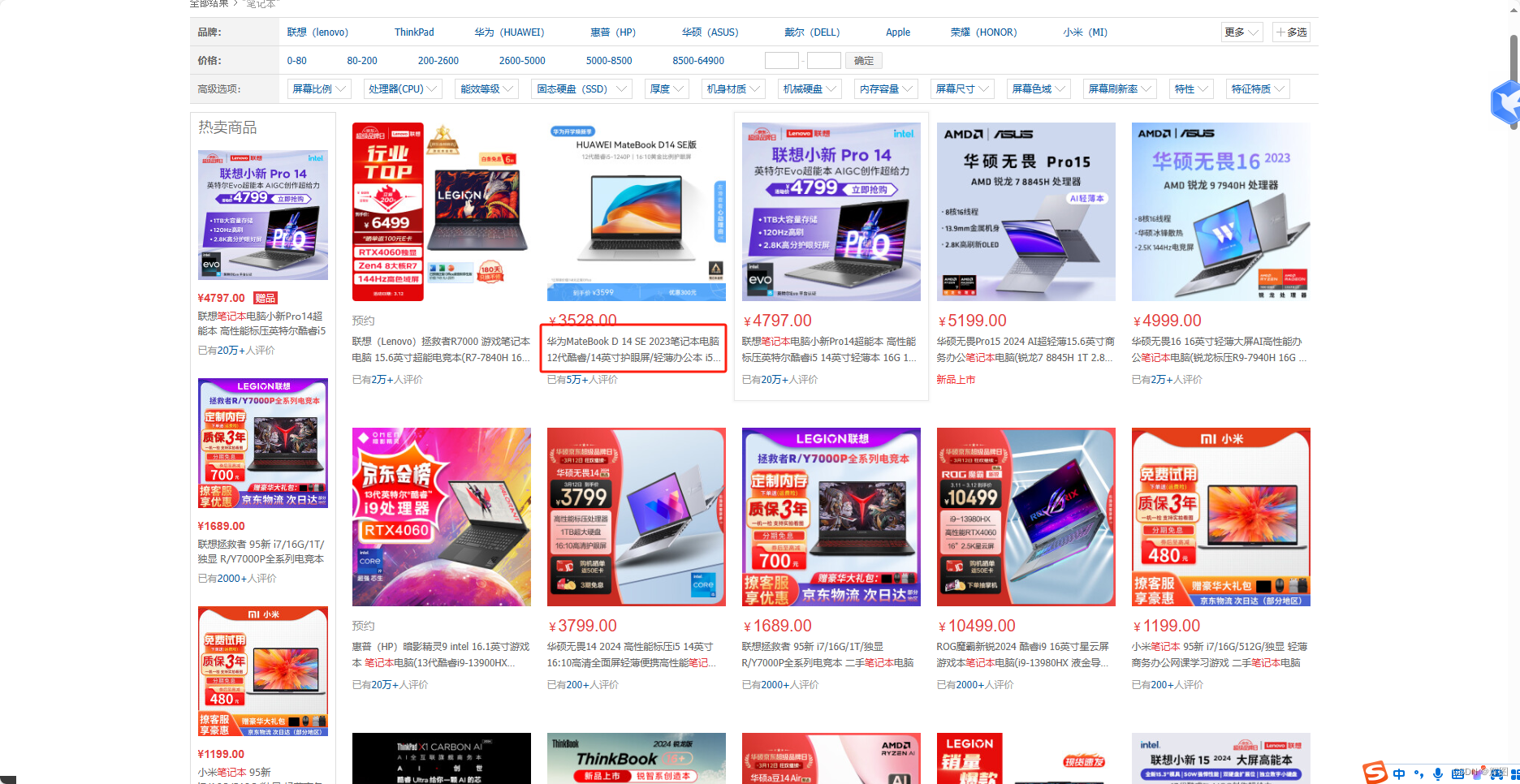
推荐先直接把获取到的html数据持久化到本地~,爬的次数多了会被监视的~
四、爬虫准则
- 爬虫访问频次要控制,别把对方服务器搞崩溃了
- 涉及到个人隐私的信息不要也不能爬
- 突破网站的反爬措施,后果很严重,如果你被监视了,最好不要尝试突破反爬措施
- 遵守robot.txt----(Robots协议)
五、Selenium+jsoup+mybatis实现数据保存
1.筛选需要的数据
Scanner scanner = new Scanner(System.in);System.out.println("请输入要搜索的内容");final String s = "笔记本电脑";final String encode = URLEncoder.encode(s);EdgeOptions edgeOptions = new EdgeOptions();edgeOptions.addArguments("--remote-allow-origins=*");//创建浏览器窗口WebDriver edgeDriver = new EdgeDriver(edgeOptions);edgeDriver.get("https://re.jd.com/search?keyword="+encode);//动态网站数据填充比较慢,需要延迟才可以拿到数据,一般网不差3到5s就差不多了Thread.sleep(5000);//获取页面数据final String pageSource = edgeDriver.getPageSource();//将字符串转为document对象final Document parse = Jsoup.parse(pageSource);final Element shopList = parse.getElementById("shop_list");final Elements li = shopList.children();System.out.println("----------------------------------------------------------------------------");// //div[@class='sear_container w']/div[2]/div/div/div/ul/li/*li.html()还有俩部分,一个是pic,一个是li_cen_botli_cen_bot再分3个,commodity_info商品信息(价格);commodity_tit:商品标题;comment:评论*/ArrayList<String> images = new ArrayList<>();ArrayList<String> prices = new ArrayList<>();ArrayList<String> titles = new ArrayList<>();ArrayList<String> comments = new ArrayList<>();//.get(1).attr("src").substring(2))li.forEach(inner -> {images.add("https:" + inner.getElementsByClass("img_k").attr("src"));titles.add(inner.getElementsByClass("commodity_tit").text());if (inner.getElementsByClass("price").text().length()==0){prices.add("预约");}else{prices.add(inner.getElementsByClass("price").text().substring(1));}comments.add(inner.getElementsByClass("praise praise-l").text());});2.创建一个表,准备存储数据
先随便整一个吧~

加个img_url字段,字段长度如果太小了就自己再改改,有错误自己再调调,有基础这些错误都能自己调了
3.结果
mybatis配置啥的不写了,直接出结果代码了
public class DemoJ {public static void main(String[] args) throws InterruptedException, IOException {Scanner scanner = new Scanner(System.in);System.out.println("请输入要搜索的内容");final String s = "笔记本电脑";final String encode = URLEncoder.encode(s);
EdgeOptions edgeOptions = new EdgeOptions();edgeOptions.addArguments("--remote-allow-origins=*");//创建浏览器窗口WebDriver edgeDriver = new EdgeDriver(edgeOptions);
edgeDriver.get("https://re.jd.com/search?keyword="+encode);//动态网站数据填充比较慢,需要延迟才可以拿到数据,一般网不差3到5s就差不多了Thread.sleep(5000);//获取页面数据final String pageSource = edgeDriver.getPageSource();
//将字符串转为document对象final Document parse = Jsoup.parse(pageSource);final Element shopList = parse.getElementById("shop_list");
final Elements li = shopList.children();System.out.println("----------------------------------------------------------------------------");
// //div[@class='sear_container w']/div[2]/div/div/div/ul/li/*li.html()还有俩部分,一个是pic,一个是li_cen_botli_cen_bot再分3个,commodity_info商品信息(价格);commodity_tit:商品标题;comment:评论*/ArrayList<String> images = new ArrayList<>();ArrayList<String> prices = new ArrayList<>();ArrayList<String> titles = new ArrayList<>();ArrayList<String> comments = new ArrayList<>();//.get(1).attr("src").substring(2))li.forEach(inner -> {images.add("https:" + inner.getElementsByClass("img_k").attr("src"));titles.add(inner.getElementsByClass("commodity_tit").text());if (inner.getElementsByClass("price").text().length()==0){prices.add("预约");}else{prices.add(inner.getElementsByClass("price").text().substring(1));}comments.add(inner.getElementsByClass("praise praise-l").text());});
String resource = "mybatis-config.xml";InputStream inputStream = Resources.getResourceAsStream(resource);SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
final SqlSession sqlSession = sqlSessionFactory.openSession();final ProductMapper mapper = sqlSession.getMapper(ProductMapper.class);
for (int i = 0; i < images.size(); i++) {mapper.add(titles.get(i),prices.get(i),images.get(i),comments.get(i));}sqlSession.commit();sqlSession.close();}
}
结束
![[QT]自定义的QtabWidget](https://img-blog.csdnimg.cn/direct/52ed24c0306e4ea8a3846f376dfcb375.gif)