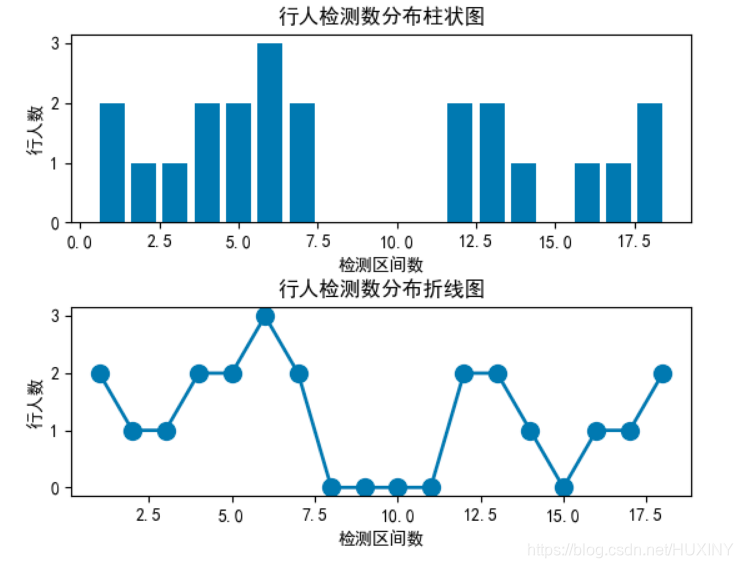
大模型字典中加入特殊字符
在微调大模型的时候会遇到添加特殊字符,例如在微调多轮的数据的时候需要加入人和机器等特殊标识字符,如用这个特殊字符表示人,用这个特殊字符表示机器,从而实现了人机对话。一般在大模型中base字典中不包含这些特殊字符,然后在关于大模型的chat模型中字典会有这几个特殊字符的,只不过每一个大模型的特殊字符表示不一样。接下来我会介绍LLama2-7b模型添加特殊字符。
from transformers import LlamaConfig
from transformers import LlamaForCausalLM
from transformers import LlamaTokenizerpretrain_model_path = "./pretrained_models/chinese-gsllama-2-7B-round-float16"
config = LlamaConfig.from_pretrained(pretrain_model_path)
tokenizer = LlamaTokenizer.from_pretrained(pretrain_model_path)
model = LlamaForCausalLM.from_pretrained(pretrain_model_path, torch_dtype=torch.float16)print("llama-7b 字典大小为: ".format(len(tokenizer)))# 添加特殊字符
tokenizer.add_tokens('<human>')
tokenizer.add_tokens('<assistant>')
print("llama-7b 添加tokens后字典的大小为:",len(tokenizer))
# 修改模型中的embedding和lm_head这两层的维度。
model.resize_token_embeddings(len(tokenizer))config.save_pretrained(output_model_path)
tokenizer.save_pretrained(output_model_path)
model.save_pretrained(output_model_path)
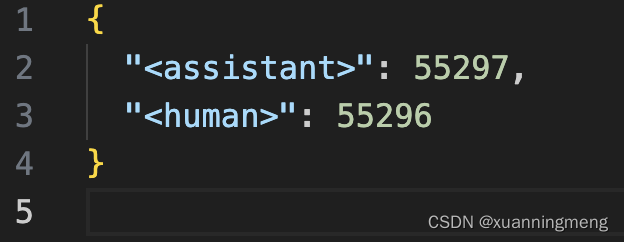
llama2-7b添加了特殊字符,保存后的模型路径下config.json中的vocab_size比原是模型的大了2。同时路径下多了一个added_tokens.json。如下图:
模型推理验证一下llama2-7b原始模型和添加tokens的模型生成是否一样。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
import jsonimport torch
from transformers import LlamaTokenizer
from transformers import LlamaForCausalLM
from transformers import GenerationConfigif __name__ == "__main__":# llama2-7b原始模型路径# pretrain_model_path = "./pretrain_model/chinese-llama-2-7b/"# 添加token后模型路径pretrain_model_path = "./pretrained_model/chinese-llama2-7b-add/"model = LlamaForCausalLM.from_pretrained(pretrain_model_path, device_map="auto", torch_dtype=torch.float32) # tokenizer = LlamaTokenizer.from_pretrained(pretrain_model_path)print("load model and load tokenizer")gene_config = {"pad_token_id": tokenizer.pad_token_id,"bos_token_id": tokenizer.bos_token_id,"eos_token_id": tokenizer.eos_token_id,"max_new_tokens": 128,"temperature": 0.3,"repetition_penalty": 1.06,"do_sample": False}print(gene_config)model.generation_config = GenerationConfig.from_dict(gene_config)# model.generation_config = GenerationConfig.from_pretrained(pretrain_model_path)model.eval()while True:text = input("输入数据>>>")features = tokenizer(text, return_tensors='pt')features = {key: value.to('cuda:0') for key, value in features.items()}position_ids = [i for i in range(len(features['input_ids'][0]))]position_ids = torch.tensor([position_ids], dtype=torch.long).to('cuda:0')print(position_ids)output = model.generate(inputs=features['input_ids'], attention_mask=features["attention_mask"], generation_config=model.generation_config)# print(output)pred = tokenizer.decode(output[0][len(features['input_ids'][0]):], skip_special_tokens=True)print("模型推理>>>", pred)
输入为中国的首都是北京,英国的首都是伦敦,法国的首都是
输出为:
1. llama2-7b 原始模型推理结果
巴黎,意大利的首都是罗马。中国和意大利都是世界四大文明古国之一,两国在历史上有过多次交往,都留下了许多珍贵的历史遗迹。下面就让我们一起来欣赏一下中国和意大利之间的那些历史遗迹吧! 1、长城 长城是中国古代伟大的防御工程,它横贯中国北方地区,东起山海关,西至嘉峪关,全长约6700公里,是世界上最长的城墙。长城始建于春秋战国时期,到秦始皇统一六国后才得以大规模修筑。长城的修建主要是为了抵御北方游牧民族的
2. llama2-7b 添加字符的模型推理结果
巴黎,意大利的首都是罗马。中国和意大利都是世界四大文明古国之一,两国在历史上有过多次交往,都留下了许多珍贵的历史遗迹。下面就让我们一起来欣赏一下中国和意大利之间的那些历史遗迹吧! 1、长城 长城是中国古代伟大的防御工程,它横贯中国北方地区,东起山海关,西至嘉峪关,全长约6700公里,是世界上最长的城墙。长城始建于春秋战国时期,到秦始皇统一六国后才得以大规模修筑。长城的修建主要是为了抵御北方游牧民族的
这里以llama2-7b为例介绍了添加字符的过程,有时候会碰到预训练模型的config.json中的vocab_size的值和tokenizer的字典的值大,可能是由于预训练的时候使用了megatron中的tp导致的,可以先把embedding和lm_header的这两层权重的维度截取到和tokenizer的字典的值一样大再进行添加tokens。以上内容如有表述有误,欢迎指证。