文章的顺序,是本人学习Springboot这个框架的先后顺序
这一篇文章讲解的是如何整合数据库中的数据源
Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池。
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。
Spring Boot 2.0 以上默认使用 Hikari 数据源,可以说 Hikari 与 Driud 都是当前 Java Web 上最优秀的数据源,我们来重点介绍 Spring Boot 如何集成 Druid 数据源,如何实现数据库监控。
先看一下咱们之前按创建的项目是通过是什么连接池来实现数据库的连接,现在使用的是hikari连接池
执行下面代码看一下spring boot默认使用的数据源是那个?
@SpringBootTest
class DemoApplicationTests {@ResourceDataSource dataSource;@Testvoid contextLoads() throws Exception{System.out.println(dataSource.getClass());}
}
一:导入Druid所需要的依赖
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.16</version></dependency>二:接下来:改变数据库的连接池为Druid
在项目配置文件application.yal进行数据源的设置:修改数据源的type
spring:datasource:username: demo1password: 123url: jdbc:mysql://localhost:3306/girls?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource再次执行查看数据源代码:数据源发生改变
![]()
三:配置Druid中常用的数据项:在配置文件继续进行配置
spring:datasource:username: demo1password: 123url: jdbc:mysql://localhost:3306/girls?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8driver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSourceinitialSize: 5minIdle: 5maxActive: 20maxWait: 60000timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: falsepoolPreparedStatements: true#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4jfilters: stat,wall,log4jmaxPoolPreparedStatementPerConnectionSize: 20useGlobalDataSourceStat: trueconnectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500这里的配置内容只是平常经常使用的,还有其他的配置有兴趣的可以去 DruidDataSource这个类去查看一下关于Druid其他的配置
将这些配置,交给容器中进行管理
@Configuration
public class DruidConfig {@ConfigurationProperties(prefix = "spring.datasource") //对应的是配置文件@Bean public DataSource DruidDatasource(){return new DruidDataSource();}
}Druid使用的是log4j进行日志记录:导入依赖
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>jcl-over-slf4j</artifactId><version>1.7.25</version></dependency>到这里关于Druid的基础配置,基本上就已经完成了
接下来,要实现的通过Druid进行后台监控
在定义的DruidConfig配置类,添加后台监控功能的配置
package com.example.demo.Myconfig;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;@Configuration
public class DruidConfig {@ConfigurationProperties(prefix = "spring.datasource")@Beanpublic DataSource DruidDatasource(){return new DruidDataSource();}//实现后台监控功能@Beanpublic ServletRegistrationBean servletRegistrationBean(){ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*"); //servlet配置,向web.xml中对servlet的配置Map<String, String> hashMap = new HashMap<>();System.out.println("1111");hashMap.put("loginUsername","demo1"); //固定账号名和密码key值hashMap.put("loginPassword","123");hashMap.put("allow",""); //允许谁能够访问bean.setInitParameters(hashMap);return bean;}
}
私人定制后台监控管理,交给IOC容器进行管理
进行Druid监控界面:输入http://localhost:8080/druid
默认进入的登录界面
登陆成功:进入到Druid的监控界面
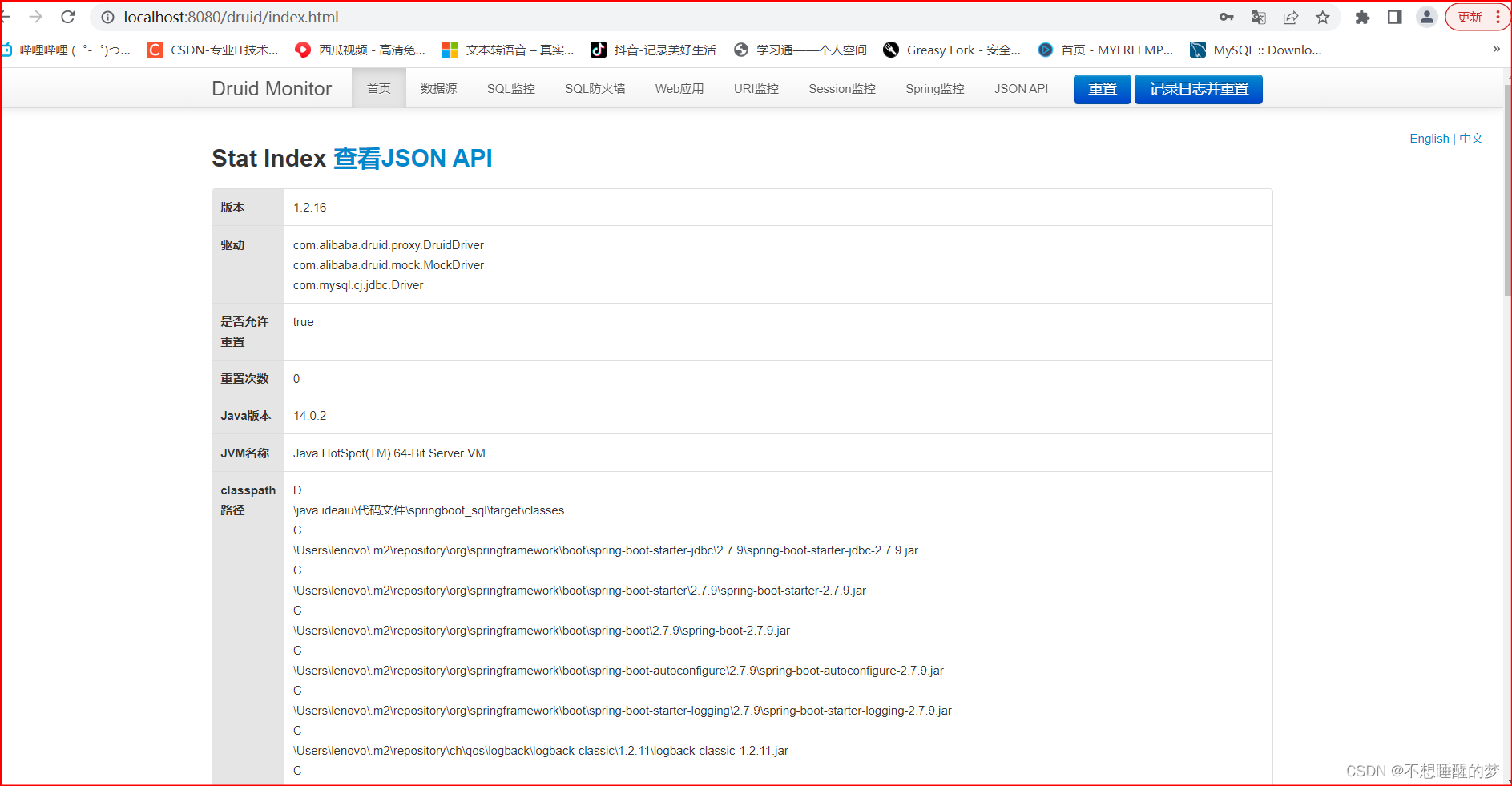
执行增删改查中的查代码,看一下后台监控,是否能够检测到
查代码执行成功

查看后台监控

监控成功
注意:这里使用的log4j日志管理,可能会报错,以防万一添加一个log4j.properties配置文件
在配置文件添加以下配置
log4j.rootLogger=DEBUG, stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
添加完成,就预防log4j出现的问题,问题可能导致监控功能无法正确的实现