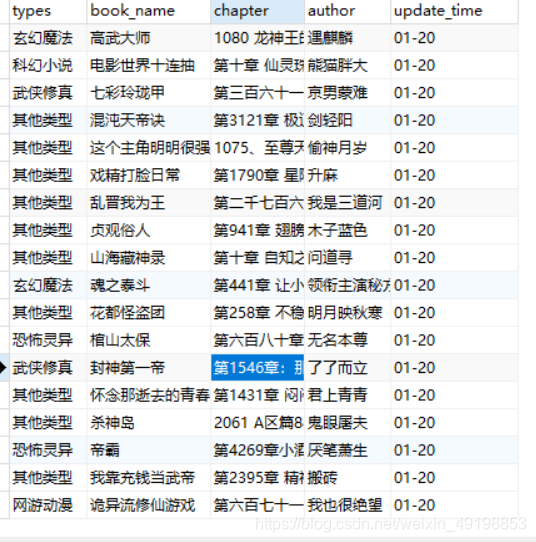
爬取顶点小说网站首页内容
最近更新区 类型 书名 章节 作者名 更新日期
import requests
import re
source = requests.get('https://www.23us.com/').content.decode('gbk')
a = '<li><p class="ul1">\[(.*?)\]《<a class="poptext" href=".*?" target="_blank">(.*?)
dome = re.compile(a)
lists = dome.findall(source)
for a,b,c,d,e in lists:print(a,b,c,d,e,)

将爬取的数据上传至数据库
在数据库中创建一个新表
import requests
import re
import pymysql
conn = pymysql.connect(host='127.0.0.1',user ='root', password ='',database ='xiaoshuo',charset='utf8')
cursor = conn.cursor()
source = requests.get('https://www.23us.com/').content.decode('gbk')
a = '<li><p class="ul1">\[(.*?)\]《<a class="poptext" href=".*?" target="_blank">(.*?)</a>》</p><p class="ul2"><a href=".*?" target="_blank">(.*?)</a></p><p>(.*?)</p>(.*?)</li>'
dome = re.compile(a)
lists = dome.findall(source)
for a,b,c,d,e in lists:sql = 'insert into xiaoshuo(types,book_name,chapter,author,update_time) values("{}","{}","{}","{}","{}")'.format(a,b,c,d,e)cursor.execute(sql)conn.commit()
conn.close()
![[转] ASP.NET 开发 WAP 网站](http://images.csdn.net/syntaxhighlighting/outliningindicators/none.gif)