一、目标网站:https://www.13400.com/

二、获取最近铃声模块的音频内容

三、涉及库:request、bs4、xpinyin、time
开干!!!!

1.检查网页元素

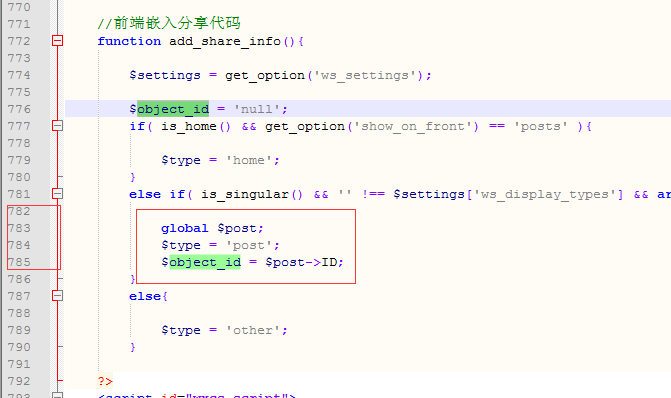
我发现歌曲名字都在div id="tagcd8a824ad1a7c8b52ecdcbc4e2875538"标签下
于是很简单的就取到歌曲名,但是要方便操作,我要把它存在一个列表里
点击一个音乐进去找到下载,检查元素发现这个路径

于是复制到浏览器我发现了竟然直接跳出下载

神奇的是每个路径除了后后面的歌曲缩写不一样,剩下的都一样,于是我找到了歌曲的下载路径

url ="https://www.13400.com/"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"}
#发送请求,获得响应对象
response =requests.get(url,headers=headers)这里的header报头在以下位置
选择network,并选择第一个
看到以下界面,复制指内容

这里我定义了两个列表用来保存歌曲名字
#info,zhongwen用来保存标签内歌曲名字
info=[]
zhongwen = []判断请求是否正常,并获取歌曲名
#判断是否请求正常
if(response.status_code)==200:#页面格式为lxml,创建bs对象bs=BeautifulSoup(response.content.decode("UTF-8"),"lxml")listContent = bs.find("div",attrs={"id":"tagcd8a824ad1a7c8b52ecdcbc4e2875538"})lis=listContent.find_all("li")# print(lis)到这已经取到标签内容,下面将li标签内容存到列表中
for li in lis:#循环将歌名存入列表中方便使用name =li.text#存两份一份用来保存中文名info.append(name)zhongwen.append(name)将中文转换成英文,并且奖所有的-去除,将歌曲与人名之间用-连接
pinyinname=[]pinyinname=infoprint(info)test=[]test = Pinyin()#用于将中文转换成英文for i in range(0,len(info)):pinyinname[i] = test.get_pinyin(info[i])pinyinname[i]=pinyinname[i].replace("-","")pinyinname[i]=pinyinname[i].replace(" ","-")#输出查看英文歌曲表,正常print(pinyinname)#输出查看中文歌曲表,正常print(zhongwen)调试结果

到这步基本就完成取歌曲了,下面开始下载音乐(注释很详细我就不说了)
#循环下载歌曲for i in range(0, len(pinyinname)):#歌曲下载地址经过查看为 "https://m3.8js.net:99/20210522/" + pinyinname[i] + ".mp3" 格式songUrl = "https://m3.8js.net:99/20210522/" + pinyinname[i] + ".mp3"songName = zhongwen[i]# 请求文件地址,获取文件资源,存数据data = requests.get(songUrl, headers=headers)# 将数据文件保存到指定目录with open(r"music/{}.mp3".format(songName), "ab") as file:file.write(data.content)print("正在下载第", i + 1, "首")time.sleep(0.5)完整代码:
#爬取网页音频文件,格式为.mp3
#导入包
import time
import requests
import csv
from xpinyin import Pinyin
from bs4 import BeautifulSoup
url ="https://www.13400.com/"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36"}
#发送请求,获得响应对象
response =requests.get(url,headers=headers)
print(response.status_code)
#info,zhongwen用来保存标签内歌曲名字
info=[]
zhongwen = []
#判断是否请求正常
if(response.status_code)==200:#页面格式为lxml,创建bs对象bs=BeautifulSoup(response.content.decode("UTF-8"),"lxml")listContent = bs.find("div",attrs={"id":"tagcd8a824ad1a7c8b52ecdcbc4e2875538"})lis=listContent.find_all("li")# print(lis)for li in lis:#循环将歌名存入列表中方便使用name =li.text#存两份一份用来保存中文名info.append(name)zhongwen.append(name)pinyinname=[]pinyinname=infoprint(info)test=[]test = Pinyin()#用于将中文转换成英文for i in range(0,len(info)):pinyinname[i] = test.get_pinyin(info[i])pinyinname[i]=pinyinname[i].replace("-","")pinyinname[i]=pinyinname[i].replace(" ","-")#输出查看英文歌曲表,正常print(pinyinname)#输出查看中文歌曲表,正常print(zhongwen)#循环下载歌曲for i in range(0, len(pinyinname)):#歌曲下载地址经过查看为 "https://m3.8js.net:99/20210522/" + pinyinname[i] + ".mp3" 格式songUrl = "https://m3.8js.net:99/20210522/" + pinyinname[i] + ".mp3"songName = zhongwen[i]# 请求文件地址,获取文件资源,存数据data = requests.get(songUrl, headers=headers)# 将数据文件保存到指定目录with open(r"music/{}.mp3".format(songName), "ab") as file:file.write(data.content)print("正在下载第", i + 1, "首")time.sleep(0.5)
else:print("url解析失败!")我这里写的是相对路径,即在项目文件夹内
运行结果



完成!!