图像网站下载图片
文章目录
- 准备工作
- 方法一:
- 方法二:
准备工作
实现从百度图片中下载某一类型的图片
import requests
from selenium import webdriver
通过webdriver打开浏览器,如果遇到问题可以参考https://blog.csdn.net/weixin_49374896/article/details/113982517
browser=webdriver.Firefox()
browser.get('https://image.baidu.com/')
找到输入框元素,输入内容
kw_elem=browser.find_element_by_id('kw')
kw_elem.send_keys('猫')
点击搜索
s_newBtn_elem=browser.find_element_by_class_name('s_newBtn')
s_newBtn_elem.click()
这里已经是搜索结果(页面切换了,但没有产生新的窗口,后面将会说明产生新的窗口怎么办)
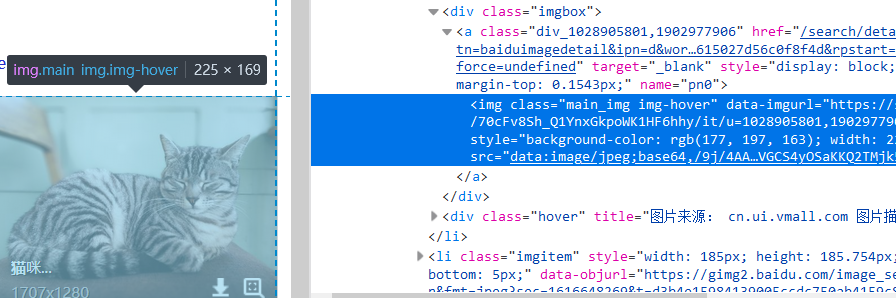
在页面右键->查看元素,进入调试。然后用元素选择器选中一张图片(注意里面前几个是广告,不要选广告图片)观察这个图像元素的找到合适的方法选中该元素(建议用find_element_by_xpath)
imgs_elem=browser.find_elements_by_xpath("//*[@class='imgbox']/a/img")
方法一:
获取链接,下载图片
new_url=imgs_elem.get_attribute(‘src’)获取到的信息用不了,只能用get_attribute(‘data-imgurl’)
n=len(imgs_elem)
for i in range(n):new_url=imgs_elem[i].get_attribute('data-imgurl')r = requests.get(new_url)# 将获取到的图片二进制流写入本地文件with open('猫_'+str(i)+'.png', 'wb') as f:f.write(r.content)
方法二:
上面那种方法是在搜索页面获得的,还可以点击图片进入详情下载
from selenium.webdriver. common.keys import Keys
new_img_elem=browser.find_element_by_xpath("//*[@class='imgbox']/a/img")
new_img_elem.click()
注意,这里由于点击搜索之后打开了一个新的窗口,而我们的browser还停留在原来的窗口。
print(browser.title)
猫_百度图片搜索

先保存原来的窗口,以便之后返回回来
mainWindow = browser.current_window_handle
print(mainWindow)
15
在这里进行页面切换,获取到当前所有的窗口,选中搜索的结果
for handle in browser.window_handles:browser.switch_to.window(handle)if '搜索结果' in browser.title:break
现在已经是在新的窗口啦
print(browser.title)
猫的搜索结果_百度图片搜索
进入搜索结果,进入之后可以通过键盘左右键切换图片
标签是 HTML 文件中的基本标签:HTML 文件的完整内容包含在和标签之内html_elem=browser.find_element_by_tag_name('html')
#下载多少张图片就循环多少次
for i in range(20):#获得图片元素img=browser.find_element_by_xpath("//*[@class='img-wrapper']/img")url=img.get_attribute('src')r = requests.get(new_url)# 将获取到的图片二进制流写入本地文件with open('猫2_'+str(i)+'.png', 'wb') as f:f.write(r.content) #通过模拟键盘右键切换图片html_elem.send_keys(Keys.RIGHT)
关闭当前窗口,回到原来的窗口(这一步可有可无)
browser.close()
browser.switch_to.window(mainWindow)
print(browser.title)
猫_百度图片搜索