适用网站:51XXX
本来想要全自动,奈何因为有各种验证防止爬虫很费时间,不想过多专研,不保证高效率,但至少很快让你得到自己想要的东西
网页可参考:
其中pageno表示第几页,coid表示公司编码展示![]() https://msearch.51job.com/co_all_job.php?pageno=1&coid=2881272
https://msearch.51job.com/co_all_job.php?pageno=1&coid=2881272
截图:
准备:
1.脚本目录下准备一个html.txt文件,里面就放我上面截图展示的东西(<div class="list">处右键以html编辑,全部复制)
2.脚本代码:
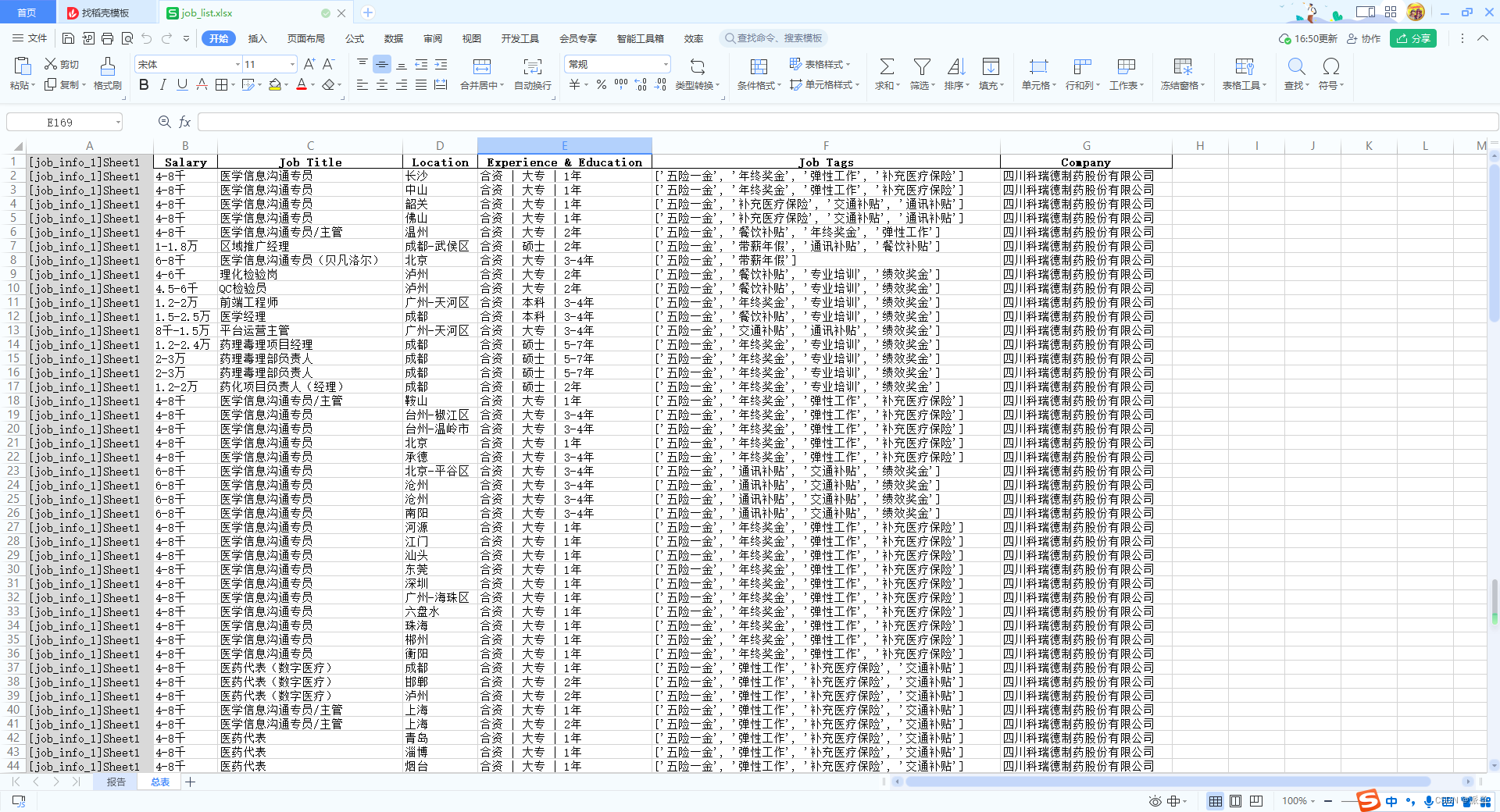
import pandas as pd
from bs4 import BeautifulSoupwith open('html.txt', 'r', encoding='utf-8') as f:html_code = f.read()soup = BeautifulSoup(html_code, 'html.parser')job_list = []
job_divs = soup.find_all('div', {'class': 'list'})
for job_div in job_divs:job_links = job_div.find_all('a', {'class': 'e'})for job_link in job_links:salary = job_link.find('i').textjob_title = job_link.find('strong').text.strip()job_location = job_link.find('em').textjob_exp_edu = job_link.find('p').textjob_tags = [tag.text for tag in job_link.find_all('span', {'class': 'fl'})]company = job_link.find('aside').text.strip()job_info = {'Salary': salary,'Job Title': job_title,'Location': job_location,'Experience & Education': job_exp_edu,'Job Tags': job_tags,'Company': company}job_list.append(job_info)df = pd.DataFrame(job_list)
df.to_excel('job_info.xlsx', index=False)
3.处理完一页就跳转下一页,重复上面步骤,最后用WPS合并表格数据即可