前言:由于前一段时期需要从网站上扒一些图片下来,因为css,js都好扒,就是图片数量众多,需要代码实现,在网上找了一堆以实现的代码,要么没有用,要么功能不是自己想要的,干脆自己写一个,写的时候发现还挺简单的,而且不单单可以下载图片,只要是网站资源都可以,只不过需要针对单个网站去写代码,因为每个网站的html布局都不一样。
1.图片下载工具类:文件路径自己设置
package com.example.demo.util.netbug.downloadImage;/*** Descripition:image download util* Created by jin.tang on 2018/9/7......*/import lombok.extern.java.Log;import java.io.ByteArrayOutputStream;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;@Log
public class DownloadPicFromURL {private static String[] imgType = {".jpg", ".jpeg", ".bmp", ".png", ".tif", ".gif", ".fpx", ".svg", ".psd", ".pcx", ".tga", ".exif", "psd", "cdr", "ufo", "raw"};//bmp,jpg,png,tif,gif,pcx,tga,exif,fpx,svg,psd,cdr,pcd,dxf,ufo,eps,ai,raw,WMF,webppublic static void main(String[] args) {String url = "http://36.33.40.131:8200/uploadFile//userImg/1531368430530title.png";String path = "d:/html/img/";downloadPicture(url, path);}public static Boolean coverString(String url, String[] imgType) {Boolean flag = false;// 查找是否存在图片格式for (String type : imgType) {if (url.indexOf(type) != -1 || url.toUpperCase().indexOf(type.toUpperCase()) != -1) {flag = true;break;}}return flag;}//链接url下载图片public static void downloadPicture(String urlList, String path) {path = path + new SimpleDateFormat("yyyyMMdd").format(new Date()) + "_" + urlList.substring(urlList.lastIndexOf("/") + 1);if(!coverString(urlList, imgType)){path=path+".jpg";}URL url = null;try {url = new URL(urlList);DataInputStream dataInputStream = new DataInputStream(url.openStream());FileOutputStream fileOutputStream = new FileOutputStream(new File(path));ByteArrayOutputStream output = new ByteArrayOutputStream();byte[] buffer = new byte[1024];int length;while ((length = dataInputStream.read(buffer)) > 0) {output.write(buffer, 0, length);}fileOutputStream.write(output.toByteArray());dataInputStream.close();fileOutputStream.close();} catch (MalformedURLException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}log.info("img: " + urlList.substring(urlList.lastIndexOf("/") + 1) + " download " + path + " done.....");}
}
2、爬虫实现类
package com.example.demo.util.netbug.downloadImage;import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.*;
import lombok.extern.java.Log;import java.util.List;/*** Descripition:spider for image,batch get image url,then you can download ---just for 千库网* Created by jin.tang on 2018/9/7......*/
@Log
public class SpiderForInternetImage {public static void doSearchResourceToQianku(HtmlPage htmlpage) {try {// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”//final HtmlForm form = htmlpage.getFormByName("f");// 同样道理,获取”百度一下“这个按钮//final HtmlSubmitInput button = form.getInputByValue("百度一下");// 得到搜索框//final HtmlTextInput textField = form.getInputByName("q1");// 最近周星驰比较火呀,我这里设置一下在搜索框内填入”周星驰“//textField.setValueAttribute("周星驰");// 输入好了,我们点一下这个按钮//final HtmlPage nextPage = button.click();// 我把结果转成String//String result = nextPage.asXml();//当前页的图片下载List<HtmlElement> a = htmlpage.getByXPath("//a[@class='db']");a.stream().forEach(href -> {//单个a标签内所有img的下载DomNodeList<HtmlElement> imgs = href.getElementsByTagName("img");doDownload(imgs);});//跳转下一页的页面图片下载List<HtmlAnchor> next = htmlpage.getByXPath("//a[@class='downPage']");HtmlPage nextPage_ = next.get(0).click();doSearchResourceToQianku(nextPage_);// for(HtmlAnchor ach:achList){
// System.out.println(ach.getHrefAttribute());
// ach.click();
// }//DomNodeList<HtmlElement> p = a.getElementsByTagName("p");//List<HtmlElement> byXPath = p.get(0).getByXPath("span");//DomNodeList<HtmlElement> imgs = byXPath.get(0).getElementsByTagName("img");} catch (Exception e) {log.info("error happen ->" + e.getMessage());e.printStackTrace();}}public static void doSearchResourceToMmonly(WebClient webclient, HtmlPage htmlpage) {try {//当前页的图片下载List<HtmlElement> divs = htmlpage.getByXPath("//div[@class='ABox']");divs.stream().forEach(div -> {//单个div标签内所有img的下载DomNodeList<HtmlElement> a = div.getElementsByTagName("a");//取第一个a标签,里面包含图片链接页面String currentPageUrl = a.get(0).getAttribute("href");//点击进入该页面try {HtmlPage currentHtmlpage = webclient.getPage(currentPageUrl);doDownloadCHildPage(currentHtmlpage, 1);} catch (Exception e) {e.printStackTrace();}});//跳转下一页的页面图片下载List<HtmlElement> div_jump = htmlpage.getByXPath("//div[@id='pageNum']");DomNodeList<HtmlElement> as=div_jump.get(0).getElementsByTagName("a");log.info(""+as.get(as.size()-2));HtmlElement nexta = as.get(as.size()-2);HtmlPage np=nexta.click();doSearchResourceToMmonly(webclient,np );} catch (Exception e) {log.info("error happen ->" + e.getMessage());e.printStackTrace();}}public static void doDownloadCHildPage(HtmlPage currentHtmlpage, int times) throws Exception {List<HtmlElement> div_2 = currentHtmlpage.getByXPath("//div[@class='big-pic']");HtmlElement bigDiv = div_2.get(0);//大图//每页只下一张大图DomNodeList<HtmlElement> imgs = bigDiv.getElementsByTagName("img");doDownloadToMmonly(imgs);//调到下一页的大图页面List<HtmlElement> li = currentHtmlpage.getByXPath("//li[@id='nl']");// DomNodeList<DomElement> li = currentHtmlpage.getElementsById("nl");DomNodeList<HtmlElement> a_ = li.get(0).getElementsByTagName("a");HtmlElement next_ = a_.get(0);//只下前8张图片,因为每套图数量不一样,不好统一if (times <=8) {HtmlPage nextPage_ = next_.click();doDownloadCHildPage(nextPage_, times + 1);}}//单个标签内子img标签的循环下载public static void doDownload(DomNodeList<HtmlElement> imgs) {// http://bpic.588ku.com/back_pic/03/72/92/6657b9a240d3d1f.jpg!/fh/300/quality/90/unsharp/true/compress/trueSystem.out.println("总共" + imgs.size() + " 张图片 , 开始下载到本地 路径为 : ");// 遍历 下载图片到本地for (HtmlElement img : imgs) {if ("".equals(img.getAttribute("data-original")) || !img.getAttribute("data-original").contains("http")) {log.info("current image src ==> " + img.getAttribute("data-original") + " :is not right!");} else {log.info("current image src ==> " + img.getAttribute("data-original") + " :is right!");String imgUrl = img.getAttribute("data-original").substring(0, img.getAttribute("data-original").contains("!") ? img.getAttribute("data-original").lastIndexOf("!") : img.getAttribute("data-original").length());DownloadPicFromURL.downloadPicture(imgUrl, "d:/html/img/");}}}//单个标签内子img标签的循环下载public static void doDownloadToMmonly(DomNodeList<HtmlElement> imgs) {// http://bpic.588ku.com/back_pic/03/72/92/6657b9a240d3d1f.jpg!/fh/300/quality/90/unsharp/true/compress/trueSystem.out.println("总共" + imgs.size() + " 张图片 , 开始下载到本地 路径为 : ");// 遍历 下载图片到本地for (HtmlElement img : imgs) {if ("".equals(img.getAttribute("src")) || !img.getAttribute("src").contains("http")) {log.info("current image src ==> " + img.getAttribute("src") + " :is not right!");} else {log.info("current image src ==> " + img.getAttribute("src") + " :is right!");String imgUrl = img.getAttribute("src").substring(0, img.getAttribute("src").contains("!") ? img.getAttribute("src").lastIndexOf("!") : img.getAttribute("src").length());DownloadPicFromURL.downloadPicture(imgUrl, "d:/html/img/");}}}public static void main(String[] args) {try {// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了WebClient webclient = new WebClient();// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是webclient.getOptions().setCssEnabled(false);webclient.getOptions().setJavaScriptEnabled(false);//做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可HtmlPage htmlpage = webclient.getPage("http://588ku.com/beijing/0-0-pxnum-0-8-0-0-0-1/?hd=205");doSearchResourceToQianku(htmlpage);// HtmlPage htmlpage = webclient.getPage("http://www.mmonly.cc/mmtp/");
// doSearchResourceToMmonly(webclient, htmlpage);} catch (Exception e) {log.info("error happen ->" + e.getMessage());e.printStackTrace();}}
}
3、
<!-- https://mvnrepository.com/artifact/net.sourceforge.htmlunit/htmlunit -->
<dependency><groupId>net.sourceforge.htmlunit</groupId><artifactId>htmlunit</artifactId><version>2.32</version>
</dependency>
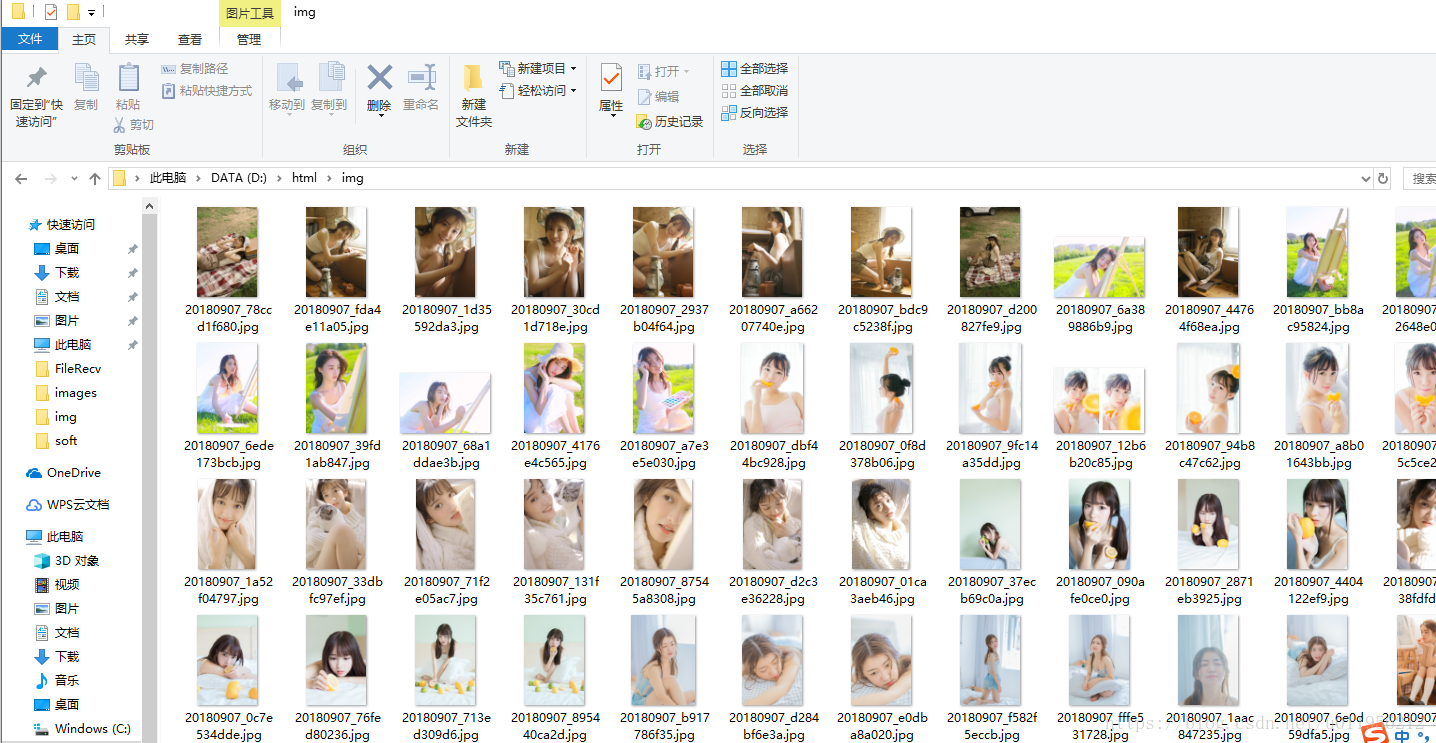
4、福利网站的下载结果: