嗯,最近帮了一个网友做了下图片下载分类,这里记录下来分享一下:
首先了解下os模块的语法
判断文件是否存在
import os
os.path.exists(test_file.txt)
#Trueos.path.exists(no_exist_file.txt)
#False判断文件夹是否存在
import os
os.path.exists(test_dir)
#Trueos.path.exists(no_exist_dir)
#False其实这种方法还是有个问题,假设你想检查文件“test_data”是否存在,但是当前路径下有个叫“test_data”的文件夹,
这样就可能出现误判。为了避免这样的情况,可以这样:只检查文件import os
os.path.isfile("test-data")*******************************************************使用os.access()方法判断文件是否可进行读写操作。
语法:os.access(path, mode)path为文件路径,mode为操作模式,有这么几种:os.F_OK: 检查文件是否存在;os.R_OK: 检查文件是否可读;os.W_OK: 检查文件是否可以写入;os.X_OK: 检查文件是否可以执行该方法通过判断文件路径是否存在和各种访问模式的权限返回True或者False。import os
if os.access("/file/path/foo.txt", os.F_OK):print "Given file path is exist."if os.access("/file/path/foo.txt", os.R_OK):print "File is accessible to read"if os.access("/file/path/foo.txt", os.W_OK):print "File is accessible to write"if os.access("/file/path/foo.txt", os.X_OK):print "File is accessible to execute"******************************************
pathlib模块在Python3版本中是内建模块,但是在Python2中是需要单独安装三方模块。使用pathlib需要先使用文件路径来创建path对象。此路径可以是文件名或目录路径。检查路径是否存在
path = pathlib.Path("path/file")
path.exist()
检查路径是否是文件
path = pathlib.Path("path/file")
path.is_file()
#原文链接https://www.cnblogs.com/jhao/p/7243043.html首先看一个固定的类别图片下载:

import urllib.request
import os
import re
url=r'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1489133995309_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%BE%8E%E5%A5%B3'imgPath=r'E:\image_py'
imgHtml=urllib.request.urlopen(url).read().decode('utf-8')
urls=re.findall(r'"objURL":"(.*?)"',imgHtml)if not os.path.isdir(imgPath):os.mkdir(imgPath)index=1
for url in urls:print("下载:",url)#未能正确获得网页 就进行异常处理try:res=urllib.request.urlopen(url)if str(res.status)!='200':print('未下载成功:',url)continueexcept Exception as e:print('未下载成功:',url)filename=os.path.join(imgPath,str(index)+'.jpg')with open(filename,'wb') as f:f.write(res.read())print('下载完成\n')index+=1
print("下载结束,一共下载了 %s 张图片"% (index-1))
上面是针对网站的一个类别的下载,下面是针对多个类别的下载:
import requests
from lxml import etree
import os
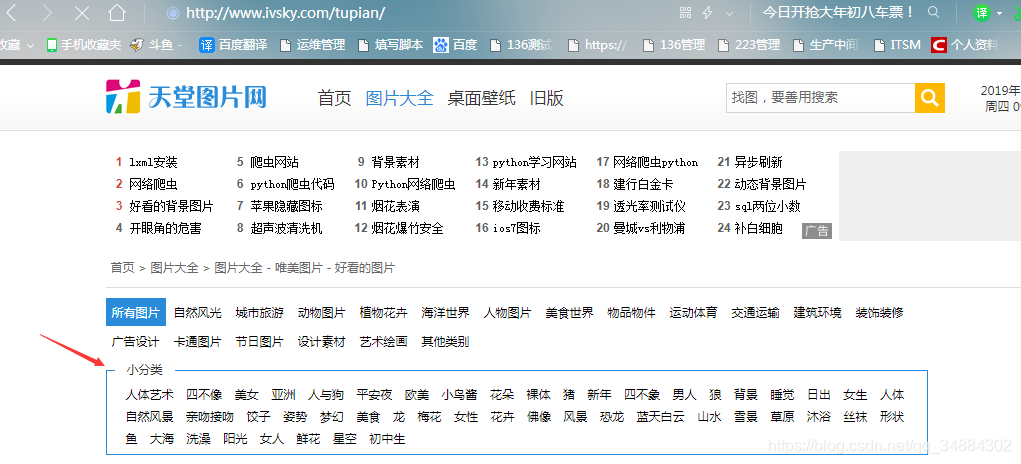
import urllib.requesturl = "http://www.ivsky.com/tupian/ziranfengguang/"
response=requests.get(url)
root=etree.HTML(response.content)
x_url=root.xpath("//ul[@class='tpmenu']/li")
for mu_url in x_url:m_url=mu_url.xpath("a/@href")[0]m_url="http://www.ivsky.com"+m_urlm_alt=mu_url.xpath("a/text()")[0]print(m_alt)os.mkdir(f"E:/python练习/爬取文件/分类存储/{m_alt}")# print(m_url)response=requests.get(m_url)root=etree.HTML(response.content)xiao_url=root.xpath("//div[@class='left']/div[@class='sline']/div/a")for x_url in xiao_url:big_name=x_url.xpath("text()")[0]os.mkdir(f"E:/python练习/爬取文件/分类存储/{m_alt}/{big_name}")big_href=x_url.xpath("@href")[0]bigx_href="http://www.ivsky.com"+big_hrefprint('一级分类'+big_name)# print(bigx_href)for x in range(1,4):bigs_href="http://www.ivsky.com"+big_href+"index_%s.html"%x# print(bigs_href)big_response=requests.get(bigs_href)big_root=etree.HTML(big_response.content)mubiao_jpg=big_root.xpath("//li/div[@class='il_img']/a")i=0for m_jpg in mubiao_jpg:i += 1m_src=m_jpg.xpath("img/@src")[0]m_name=m_jpg.xpath("img/@alt")[0]print(m_src,m_name,i)test_dir=f'E:/python练习/爬取文件/分类存储/{m_alt}/{big_name}/{m_name}'print(test_dir)if (os.path.exists(test_dir)):print('文件存在')else:os.mkdir(test_dir)print('文件创建')try:res=urllib.request.urlopen(m_src)if str(res.status)!='200':print('未下载成功:',m_src)continueexcept Exception as e:print('未下载成功:',m_src)filename=os.path.join(test_dir,str(i)+'.jpg')with open(filename,'wb') as f:f.write(res.read())print('下载完成\n')这里会遇到lxml缺失的问题,这里转载下别人的处理方式:python 安装lxml 问题与办法
无论是使用爬虫框架scrapy,还是简单的requests请求后解析。都不可避免的需要使用html解析库。
当然正则是可以代替一部分搜索。由于正则语法的晦涩,及其其他场景下,html解析是必不可少的。
网上推荐 lxml的比较多,优点:稳定,高效
但是lxml的安装很难一次成功
pip install lxml
如果没报错,那真是烧高香。。。
原文:https://blog.csdn.net/sinat_21302587/article/details/61935447
解决python “No module named pip”
python 升级后导致不能使用原来的pip命令
windows平台
cmd中敲命令:python -m ensurepip
得到pip的setuptools
然后就可以用:easy_install pip
下载相应版本的pip,最后就可以愉快的用pip命令了!