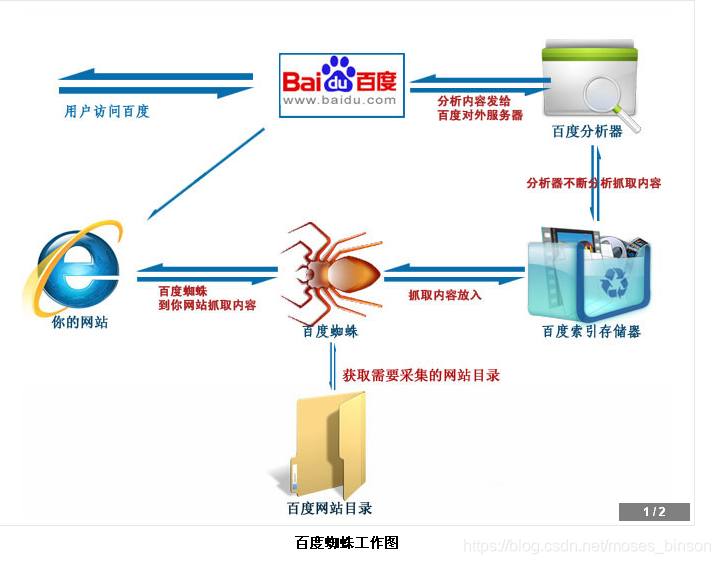
之前做过一个网站数据抓取的工作,让我充分感受到了计算机科学的生产力。之前为了抓取网站源数据的数据,我们公司只能依靠人多力量大的方式,一点一点从源网站抠,整整干了三天,干得头昏脑涨,听老板说以前有php人员抓取过数据,但是抓取的数据不理想,不能入库,只能换成人工的了。趁着学习这段时间,整了整这个项目,不负有心人。在研究源数据网站的数据传输方式以后,突然发现,原来获取这些数据如此简单:程序源码如下:
<?php
header("content-type:text/html;charset=utf-8");
ini_set('max_execution_time', 300);
function getScholar($start,$end){
$result = array();
for($i=$start;$i<$end;$i++){$url = "http://****.gov.cn*****";$post_data = array ("currentPage" => $i,//当前页"pageSize" =>7 ,);$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);// 我们在POST数据哦!curl_setopt($ch, CURLOPT_POST, 1);// 把post的变量加上curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data);$output = curl_exec($ch);$output_json = json_decode($output);curl_close($ch);//var_dump($output_json);//die();foreach($output_json->projectList as $k => $v){$result[$v->code][]=$v->code;$result[$v->code][]=$v->name;};
}
$end_end = $end-1;
$fp = fopen("output-{$start}-{$end_end}.csv",'w');//打开文件foreach ($result as $v){ob_clean();if(fputcsv($fp,$v)===false){//加数组数据放到csv文件中die("can't write csv line");}}
fclose($fp) or die("can't close scholar.csv");
if(count($result)!=($end-$start)*7){echo "数据出现错误";echo "<br/>";echo count($result);exit;
}echo "数据抓取完成,共抓取到".count($result)."条记录";
}
getScholar(3950,4000);//读取3950-4000页的数据这里主要用到了curl库,在刚开始用的时候,程序显示curl_init()不可用,但是这是已经将php的curl扩展打开了,后来百度知道,原来是在window目录下少了libeay32.dll、ssleay32.dll这两个文件,将这两个文件从php/ext 复制到windows 的system32目录下,然后重启Apache就可以了。


![交互设计[小插曲]--网站UI配色](https://img-blog.csdn.net/20140112154838859?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc3VueWluZ3l1YW4=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)