目的:
实现在控制台输入小说的目录路径敲击回车,实现全本下载
分析:
1.目标网站的网页结构
2.网站的数据是否有用
需求分析:
1.目录路径:
2.章节路径
通过模拟浏览器进行两次请求:
1.第一次请求小说的目录的路径,通过这个请求分析标签找到章节的路径,并获取路径
2.第二次根据获取的章节路径发起第二次请求,获取小说文字内容
代码如下
import re
import requests
from bs4 import BeautifulSoup
import os#获取小说目录方法
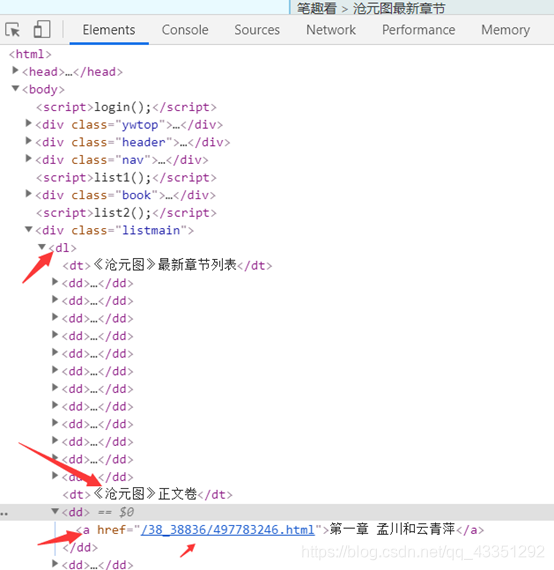
def get_xiaoshou_mulu(xiaoshuo_mulu,header):# 发起请求response = requests.get(url=xiaoshuo_mulu,headers=header)if response.status_code == 200:#设置编码,要爬取页面的编码response.encoding = 'gbk'#将请求的页面结构进行获取html = response.content#通过解析器将请求的结构进行解析soup = BeautifulSoup(html,'lxml')#分析页面标签tag_dl = soup.find('dl')print(tag_dl)start_flag = Falsefor tag_dd in tag_dl:#找到一个就换行if tag_dd == '\n':continueelif tag_dd.string == '《'+xiaoshuo_name+'》正文卷':start_flag = Trueelif start_flag:#获取路径进行下载print(tag_dd.a.string,':',url+tag_dd.a['href'],'------------下载完成!')content_name = tag_dd.a.stringcontent_src = url + tag_dd.a['href']get_xiaoshuo_mulu_content(content_name,content_src)else:print('访问的页面不可描述!')#通过章节路径获取小说
def get_xiaoshuo_mulu_content(content_name,content_src):#利用连个传来的参数 进行爬虫请求 并下载#再发一次请求response = requests.get(url=content_src, headers=header, verify=True)if response.status_code == 200:response.encoding = 'gbk'html = response.contentsoup = BeautifulSoup(html,'lxml')#获取标签中的内容div = soup.find(attrs={'id':'content','class':'showtxt'})# sub()正则的替换字符方法lines = re.sub('[\xa0]','\n\n',div.text)#储存 建立文件夹path = '笔趣小说\\'+xiaoshuo_nameif not os.path.exists(path):os.makedirs(path)print('创建成功!')#根据创建的路径写入file = open(path+'\\'+content_name+'.txt','w',encoding='utf-8',newline='')file.writelines(lines)file.close()else:print('访问不可描述')if __name__ == '__main__':print('====================小说下载助手===============')print('说明:1.输入小说的目录路径 2.输入小说的名字')header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}xiaoshuo_mulu = input('输入小说的目录路径:')#利用正则 路径验证 字符串是否符合路径的格式要求#url=xxxxxx.comurl = xiaoshuo_mulu[:re.search('.com',xiaoshuo_mulu).span()[1]]xiaoshuo_name = input('请输入小说的名字:')get_xiaoshou_mulu(xiaoshuo_mulu,header)分析
下面展示一些 内联代码片。
# 利用requests的请求 模拟浏览器header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}在Google开发者找到代理信息:按F12,刷新即可查看

#设置编码,要爬取页面的编码
response.encoding = 'gbk'

#分析页面标签tag_dl = soup.find('dl')print(tag_dl)start_flag = Falsefor tag_dd in tag_dl:#找到一个就换行if tag_dd == '\n':continueelif tag_dd.string == '《'+xiaoshuo_name+'》正文卷':start_flag = Trueelif start_flag:#获取路径进行下载print(tag_dd.a.string,':',url+tag_dd.a['href'],'------------下载完成!')content_name = tag_dd.a.stringcontent_src = url + tag_dd.a['href']get_xiaoshuo_mulu_content(content_name,content_src)