文章目录
- 1、项目描述
- 2、数据描述
- 3、代码实现
1、项目描述
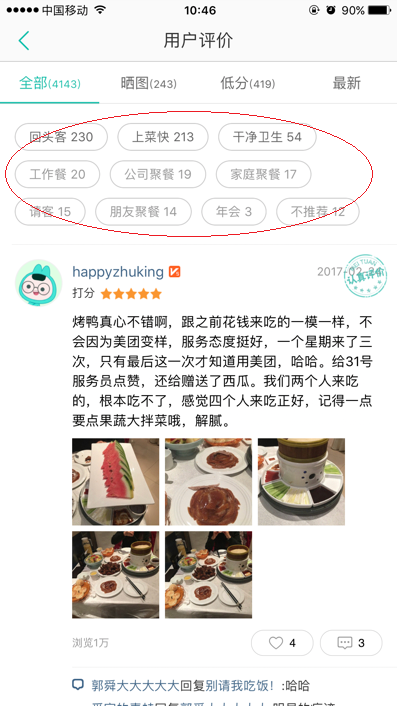
目前,越来越多的商家驻扎于购物网站中,每天都有大量的用户在不同的商家购物,然后进行评价,如图1,图2,图3所示。评论越多,说明该商品越火热,商家知名度也越高。因此,统计海量用户对不用商品的评论,然后进行分析。商家根据分析结果做出调整,这可以影响大众的消费趋势和消费心理。


2、数据描述
评价标签生成有很多方法:人工运营,机器抽取等,此处假定每条评价的标签已经生成完成。在业务上展示评价标签时,需要通过对该商家的所有用户的评价标签进行聚合,然后设置一定的策略进行展示,此处仅仅通过标签的频次进行聚合。评价标签存储为json格式,需要进行解析,此处解析使用java脚本。运行时请把temptags.txt文件上传到hdfs上,并修改scala脚本中的path路径。
-
数据格式
86913510 {“reviewPics”:null,“extInfoList”:null,“expenseList”:null,“reviewIndexes”:[2],“scoreList”:[{“score”:5,“title”:“口味”,“desc”:""},{“score”:5,“title”:“服务”,“desc”:""},{“score”:5,“title”:“环境”,“desc”:""}]}77287793 {“reviewPics”:null,“extInfoList”:null,“expenseList”:null,“reviewIndexes”:[1,2],“scoreList”:null}
说明:第一个字段86913510表示店家ID,字段以\t分隔。
3、代码实现
-
首先用SparkContext读取hdfs上的数据,然后我们以\t为分隔符切割数据,取第二个字段。数据具体分析流程如下:
val poi_taglist: RDD[(String, String)] = poi_tags.map(e => e.split("\t")).filter(e => e.length == 2)// 772897793 -> "回头客", "上菜快", "环境优雅", "性价比高", "菜品不错".map(e => e(0) -> ReviewTags.extractTags(e(1)))// 过滤评论串不为0.filter(e => e._2.length > 0)// 772897793 -> ["回头客", "上菜快", "环境优雅", "性价比高", "菜品不错"].map(e => e._1 -> e._2.split(","))// 772897793 -> "回头客", 772897793 -> "上菜快", 772897793 -> "环境优雅",// 772897793 -> "性价比高", 772897793 -> "菜品不错".flatMapValues(e => e)// (772897793,"回头客") -> 1, (772897793,"上菜快") -> 1, (772897793,"环境优雅") -> 1.map(e => (e._1, e._2) -> 1)// 聚合 (772897793,"回头客") -> 340, (772897793,"上菜快") -> 560.reduceByKey(_ + _)// 772897793 -> List("回头客",340), 772897793 -> List("上菜快",560).map(e => e._1._1 -> List((e._1._2, e._2))) // 元组不能聚合,列表可以聚合// 772897793 -> List(("回头客",340), ("上菜快",560), ...) 把key相同的都放在一个list里面.reduceByKey(_ ::: _) // ::: 表示列表累加.map(e => e._1 -> e._2.sortBy(_._2)// 772897793 -> List(("回头客", 780), ("上菜快", 560), ("环境优雅", 340), ...).reverse.take(10)// 772897793 -> List("回头客":780,"上菜快":560,"环境优雅":340), ...).map(a => a._1 + ":" + a._2.toString)// 772897793 -> "回头客":780,"上菜快":560,"环境优雅":340, ....mkString(",")) -
源码和数据
https://github.com/fengqijie001/shopTags希望可以帮到各位,不当之处,请多指教~?