批量爬取某图片网站的图片
声明:仅用于爬虫学习,禁止用于商业用途谋取利益
1、网页解析
-
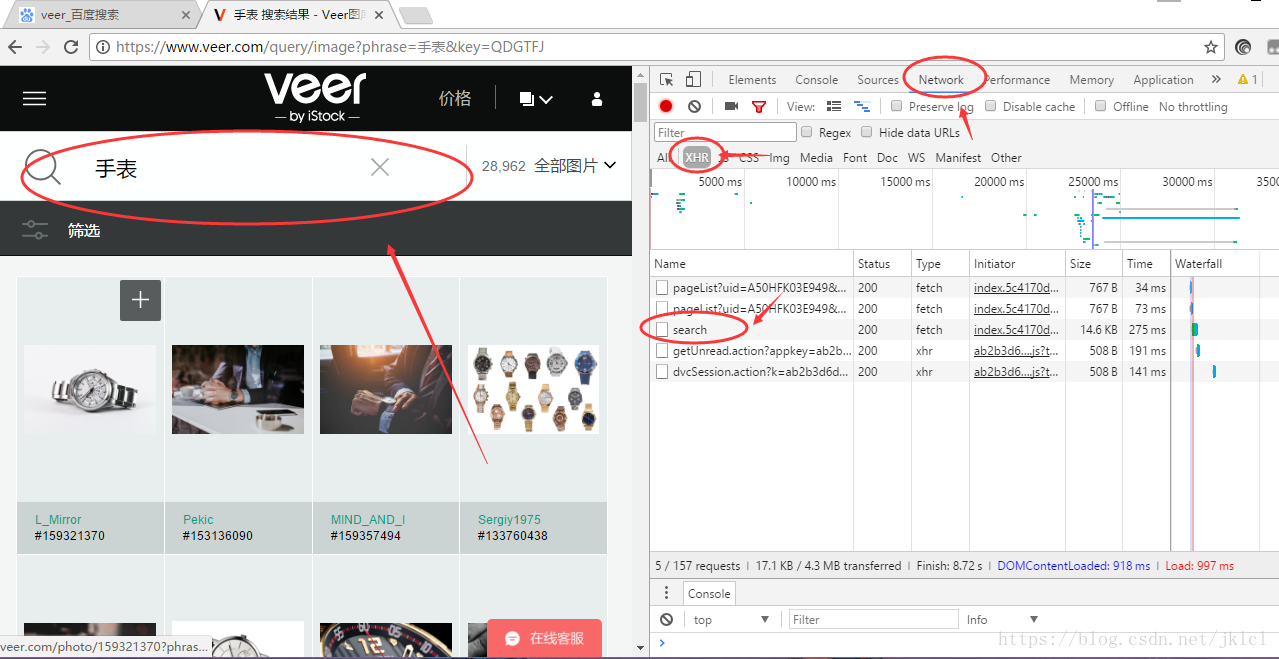
(1)打开veer首页,F12(谷歌浏览器),输入关键字,点击搜索,点击查看如图画圈位置
-
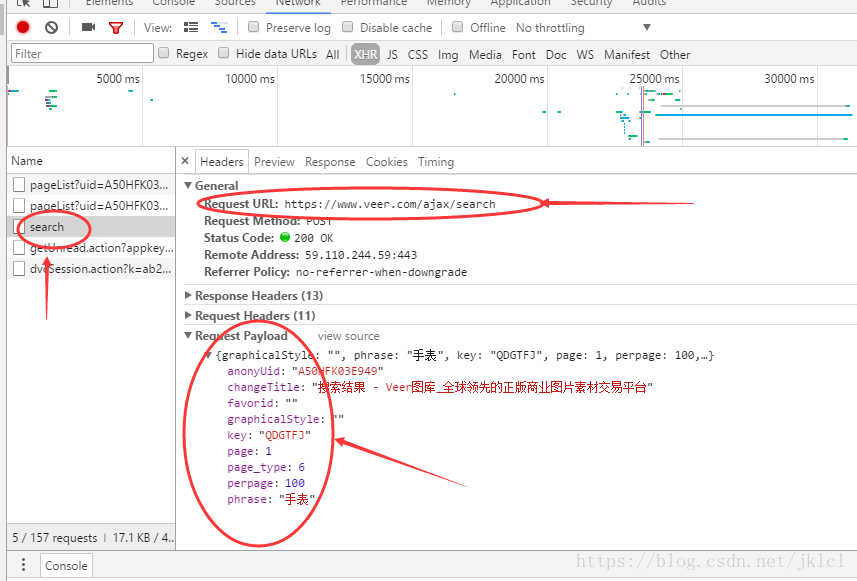
(2)查看search中的Headers,找到请求的URL和请求的payload,URL是请求的网址,payload是发送请求时的参数
对于各个详细的参数在代码部分会详细讲
-
(3)查看响应(请求发出后的返回的数据包),格式是字典格式也就是map,可以看到list中放的id
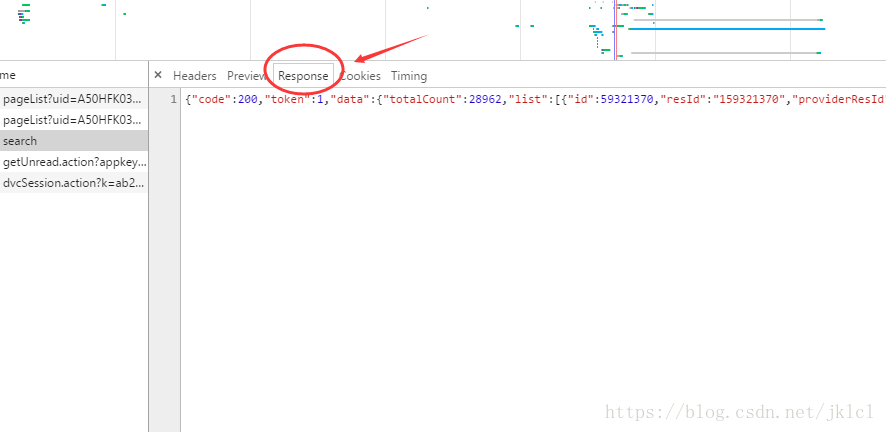
- (4)里边有对图片的中文描述
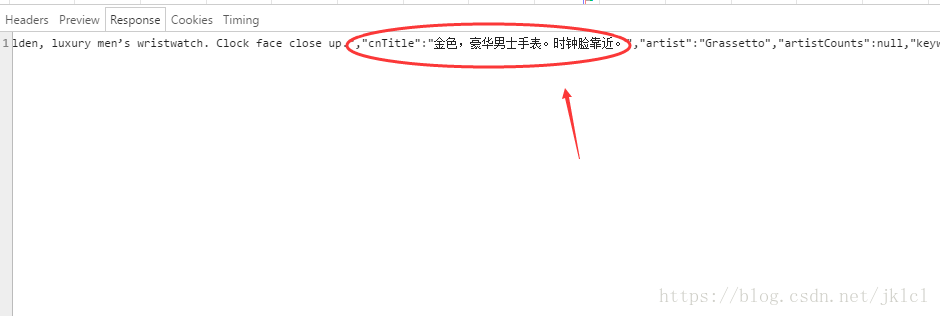
- (5)找到图片所在网页
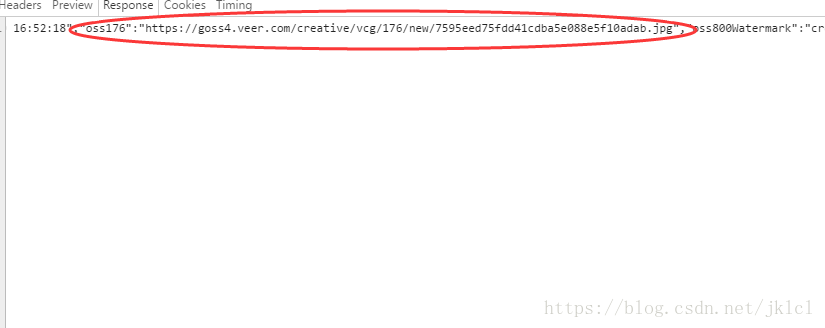
- (6)找到最大尺寸的图片网址
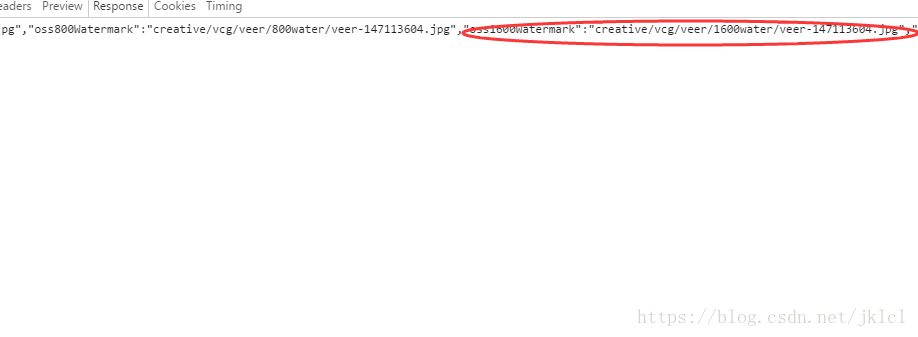
2、代码解析
#conding=utf-8import requests
import jsondef download(img_url, img_name):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101'}req = requests.get(img_url, headers=headers)path = r'F:\newimg'file_name = path + '\\' + img_name+img_url[-13:]#图片名为描述+图片的编号f = open(file_name, 'wb')f.write(req.content)#以字节流的形式读入文件f.closedef get_list(name, type):url = 'https://www.veer.com/ajax/search' #URLheader = {'content-type': 'application/json','Host': 'www.veer.com','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}payloadData = {'graphicalStyle': type, #类型:1.照片 2.插画 3.矢量图 Nan为全部'page': 1, #分页数量'page_type': 6, #分页的格式,这个不重要'perpage': 10000, #一页多少图片'phrase': name #搜索的关键字}# 分页数量为1,一页10000,是为了尽量只从一个页面上的到所有的listhtml = requests.post(url, data=json.dumps(payloadData), proxies={"http" : "http:// 115.225.74.53: 8118"}, headers=header).text #payloadData要求用josn来进行解析,代理ip自己去爬取,list = json.loads(html)#获取json解析的list,不然全是乱码data = list['data'] #封装成字典格式print("总共搜索到图片:",data['totalCount'], "张图片")id = data['list']for sid in id:print(sid['oss400'], sid['cnTitle'])#用的是400的,为了veer的利益,不采用1600尺寸的图片if sid['cnTitle']==None:#防止图片描述为空sid['cnTitle'] = "none"download(sid['oss400'], sid['cnTitle'])#进行下载if __name__ == '__main__':print("输入搜索图片名称:")name = input()print("选择图片类型1.照片 2.插画 3.矢量图 4.所有")type = input()if type>'3':type=""get_list(name, type)3、效果展示
-
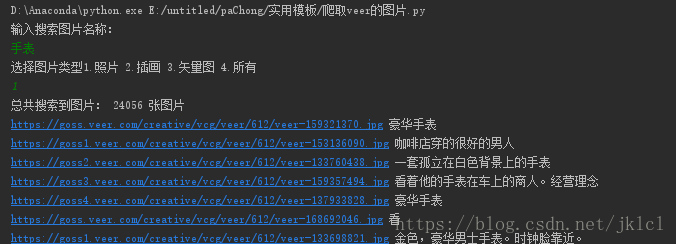
(1)程序运行界面
-
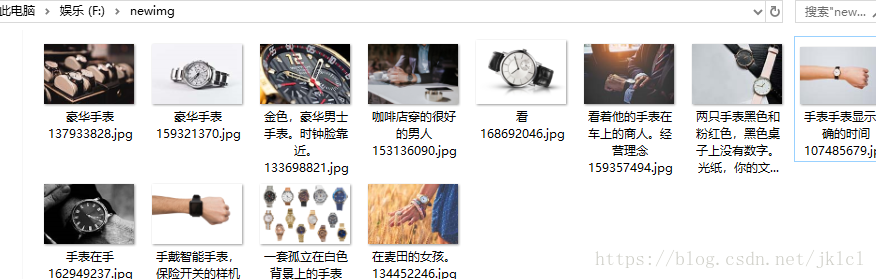
(2)文件储存界面