上篇中的程序实现了抓取0daydown最新的10页信息,输出是直接输出到控制台里面。再次改进代码时我准备把它们写入到一个TXT文档中。这是问题就出来了。
最初我的代码如下:
#-*- coding: utf-8 -*-
#-------------------------------------
#version: 0.1
#note:实现了查找0daydown最新发布的10页资源。
#-------------------------------------
#-------------------------------------
#version: 0.2
#note:在v0.1基础上输出内容到一个指定TXT文件中
#-------------------------------------import urllib.request
import sys
import localefrom bs4 import BeautifulSoupprint(locale.getdefaultlocale())old = sys.stdout #保存系统默认输出
fp = open("test1.txt",'w')
#fp = open("test1.txt",'w', encoding="utf-8") #以utf-8进行文件编码
sys.stdout = fp #输出重定向到一个文件中for i in range(1,11):url = "http://www.0daydown.com/page/" + str(i) #每一页的Url只需在后面加上整数就行page = urllib.request.urlopen(url)soup_packtpage = BeautifulSoup(page)page.close()num = " The Page of: " + str(i) #标注当前资源属于第几页print(num)print("#"*40)for article in soup_packtpage.find_all('article', class_="excerpt"): #使用find_all查找出当前页面发布的所有最新资源print("Category:".ljust(20), end=''), print(article.header.a.next) #categoryprint("Title:".ljust(20), end=''), print(article.h2.string) #title print("Pulished_time:".ljust(19), end=''), print(article.p.find('i', class_="icon-time icon12").next) #published_timeprint("Note:", end='')print(article.p.find_next_sibling().string) #noteprint('-'*50)fp.close()
sys.stdout = old #恢复系统默认输出
print("Done!")
input() #等待输入,为了不让控制台运行后立即结束。运行文件后报错:错误信息如下:
Traceback (most recent call last):File "E:\codefile\Soup\0daydown - 0.2.py", line 37, in <module>print(article.p.find_next_sibling().string) #note
UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 117: illegal multibyte sequence从文中可以看出是Unicode编码错误,说gbk不能编码\xa0这个字节。就字符编码这个问题我看了好多文章,查阅了好多资料。新手没办法,不过还好弄懂了。
最初的时候我根本毫无头绪,查看网上的一些文章开始模仿进行encode.decode的,根本没有用,输出仍然有问题,不抛出异常了,但是根本看不到汉字了,全是一些\x..这种替代了。
问题要追根朔源,我连基本的字符编码和字符集这些东西都没有搞清楚,怎么能解决问题呢?于是我搜索这方面相关文章,给出我觉得好的文章的链接如下:
字符编码详解 这篇文章虽然长,但是作者总结的太详细了,看了后收获很大。
于是我想为什么写入到文件中就会报错呢?而命令行输出就没有这个问题。难道文件有问题?文件的编码有问题?我顺着这个问题找到了一篇讲Python3的文件的文章,很好,链接如下:
Python3的文件 其中里面写到了文件的编码,原来打开文件时是可以指定文件编码的,如果不指定,那么文件默认采用什么编码方式呢?这篇文章做出了详细的解释。
我的源代码中打开文件的方式是:fp = open("test1.txt",'w'),结果抛出异常,从上面抛出的异常可以说明默认打开文件,文件的编码方式是gbk,而GBK是不能编码\xa0这个字符的,查了下这个字符,原来是HTML中特有的空字符 。要爬取的网页默认的编码方式是utf-8,说明utf-8是能编码这个字符的。那么我们可以指定文件的编码方式不呢?答案是可以,原来open中还有个参数是encoding,用来指定编码方式,如果我们指定它为utf-8会怎样?下面是正确的代码,不同的只是把fp = open("test1.txt",'w')变为了fp = open("test1.txt",'w', encoding="utf-8")。代码如下:
#-*- coding: utf-8 -*-
#-------------------------------------
#version: 0.1
#note:实现了查找0daydown最新发布的10页资源。
#-------------------------------------
#-------------------------------------
#version: 0.2
#note:在v0.1基础上输出内容到一个指定TXT文件中
#-------------------------------------import urllib.request
import sysfrom bs4 import BeautifulSoupold = sys.stdout #保存系统默认输出
#fp = open("test1.txt",'w')
fp = open("test1.txt",'w', encoding="utf-8") #以utf-8进行文件编码
sys.stdout = fp #输出重定向到一个文件中for i in range(1,11):url = "http://www.0daydown.com/page/" + str(i) #每一页的Url只需在后面加上整数就行page = urllib.request.urlopen(url)soup_packtpage = BeautifulSoup(page)page.close()num = " The Page of: " + str(i) #标注当前资源属于第几页print(num)print("#"*40)for article in soup_packtpage.find_all('article', class_="excerpt"): #使用find_all查找出当前页面发布的所有最新资源print("Category:".ljust(20), end=''), print(article.header.a.next) #categoryprint("Title:".ljust(20), end=''), print(article.h2.string) #title print("Pulished_time:".ljust(19), end=''), print(article.p.find('i', class_="icon-time icon12").next) #published_timeprint("Note:", end='')print(article.p.find_next_sibling().string) #noteprint('-'*50)fp.close()
sys.stdout = old #恢复系统默认输出
print("Done!")
input() #等待输入,为了不让控制台运行后立即结束。运行后,无错误产生,成功写入文件,打开文件,显示如下:
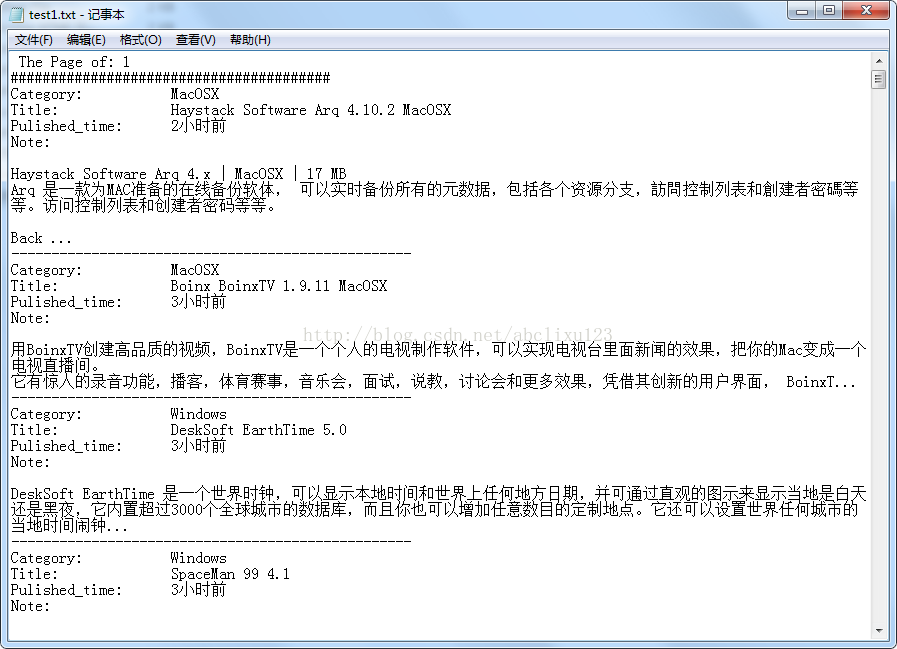
可以看出,输出结果与上一篇命令行输出的结果是一样的。圆满解决,OK!!另外,今天抽空学了下Github,早闻大名,看了下介绍,发现很强大,跟着官网教程Helloworld入了下门,注册了个帐号,准备以后代码都放在那上面了。













![[python]一个特别好的学习python网站](https://img-blog.csdn.net/2018051022244061?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3Rhbmtsb3ZlcmFpbmJvdw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
